1、不同应用中B+树索引的使用
在了解了B+树索引的本质和实现后,下一个需要考虑的问题是怎样正确地使用B+树索引,这不是一个简单的问题。这里所总结的可能并不适用于所有的应用场合。我所能做的只是概括一个大概的方向。在实际的生产环境使用中,每个DBA和开发人员,还是需要根据自己的具体生产环境来使用索引,并观察索引使用的情况,判断是否需要添加索引。不要盲从任何人给你的经验意见, Think different。
根据第1章的介绍,用户已经知道数据库中存在两种类型的应用,OLTP和OLAP应用。在OLTP应用中,查询操作只从数据库中取得一小部分数据,一般可能都在10条记录以下,甚至在很多时候只取1条记录,如根据主键值来取得用户信息,根据订单号取得订单的详细信息,这都是典型OLTP应用的查询语句。在这种情况下,B+树索引建立后,对该索引的使用应该只是通过该索引取得表中少部分的数据。这时建立B+树索引才是有意义的,否则即使建立了,优化器也可能选择不使用索引。
对于OLAP应用,情况可能就稍显复杂了。不过概括来说,在OLAP应用中,都需要访问表中大量的数据,根据这些数据来产生查询的结果,这些查询多是面向分析的查询,目的是为决策者提供支持。如这个月每个用户的消费情况,销售额同比、环比增长的情况。因此在OLAP中索引的添加根据的应该是宏观的信息,而不是微观,因为最终要得到的结果是提供给决策者的。例如不需要在OLAP中对姓名字段进行索引,因为很少需要对单个用户进行查询。但是对于OLAP中的复杂查询,要涉及多张表之间的联接操作,因此索引的添加依然是有意义的。但是,如果联接操作使用的是 Hash Join,那么索引可能又变得不是非常重要了,所以这需要DBA或开发人员认真并仔细地研究自己的应用。不过在OLAP应用中,通常会需要对时间字段进行索引,这是因为大多数统计需要根据时间维度来进行数据的筛选。
2、联合索引
联合索引是指对表上的多个列进行索引。前面讨论的情况都是只对表上的一个列进行索引。联合索引的创建方法与单个索引创建的方法一样,不同之处仅在于有多个索引列。
例如,以下代码创建了一张t表,并且索引idx_a_b是联合索引,联合的列为(a,b)。
CREATE TABLE t(
a INT,
b INT,
PRIMARY KEY (a),
KEY idx_a_b(a,b)
)ENGINE=INNODB;
那么何时需要使用联合索引呢?在讨论这个问题之前,先来看一下联合索引内部的结果。从本质上来说,联合索引也是一棵B+树,不同的是联合索引的键值的数量不是1,而是大于等于2。接着来讨论两个整型列组成的联合索引,假定两个键值的名称分别为a、b,如图所示。
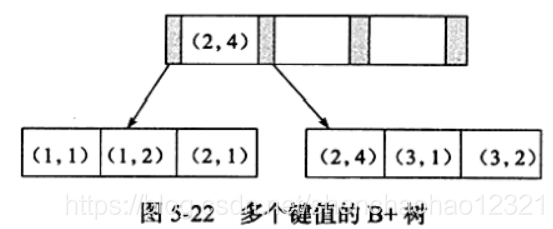
从图可以观察到多个键值的B+树情况。其实和之前讨论的单个键值的B+树并没有什么不同,键值都是排序的,通过叶子节点可以逻辑上顺序地读出所有数据,就上面的例子来说,即(1,1)、(1,2)、(2,1)、(2,4)、(3,1)、(3,2)。数据按(a,b)的顺序进行了存放。
因此,对于查询 SELECT * FROM TABLE WHERE a= xxx and b=xx,显然是可以使用(a,b)这个联合索引的。对于单个的a列查询 SELECT* FROM TABLE WHERE a=xxx,也可以使用这个(a,b)索引。但对于b列的查询 SELECT * FROM TABLE WhERE b=xxx,则不可以使用这棵B+树索引。可以发现叶子节点上的b值为1、2、1、4、1、2,显然不是排序的,因此对于b列的查询使用不到(a,b)的索引。
联合索引的第二个好处是已经对第二个键值进行了排序处理。例如,在很多情况下应用程序都需要查询某个用户的购物情况,并按照时间进行排序,最后取出最近三次的购买记录,这时使用联合索引可以避免多一次的排序操作,因为索引本身在叶子节点已经排序了。来看一个例子,首先根据如下代码来创建测试表 buy_log:
CREATE TABLE buy_log(
userid INT UNSIGNED NOT NULL,
buy_date DATE
)ENGINE=InnoDB;
INSERT INTO buy_log VALUES (1,'2009-01-01');
INSERT INTO buy_log VALUES (2,'2009-01-01');
INSERT INTO buy_log VALUES (3,'2009-01-01');
INSERT INTo buy_log VALUES (1,'2009-02-01');
INSERT INTo buy_log VALUEs (3,'2009-02-01');
InSERT INTO buy_log VALUEs (1,'2009-03-01');
INSERT INTo buy_log VALUEs (1,'2009-04-01');
ALTER TABLE buy_log ADD KEY (userid);
ALTER TABLE buy_log ADD KEY (userid,buy_date);
以上代码建立了两个索引来进行比较。两个索引都包含了 userid字段。如果只对于userid进行查询,如:
select * from buy_log where userid=2;
则优化器的选择为:
mysql> explain select * from buy_log where userid=2;
+----+-------------+---------+------------+------+-----------------+--------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------+--------+---------+-------+------+----------+-------+
| 1 | SIMPLE | buy_log | NULL | ref | userid,userid_2 | userid | 4 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+------+-----------------+--------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.01 sec)
可以发现, possible keys在这里有两个索引可供使用,分别是单个的userid索引和(userid, buy_date)的联合索引。但是优化器最终的选择是索引userid,因为该索引的叶子节点包含单个键值,所以理论上一个页能存放的记录应该更多。
接着假定要取出 userid为1的最近3次的购买记录,其SQL语句如下,执行计划。
mysql> explain select * from buy_log where userid=1 order by buy_date desc limit 3;
+----+-------------+---------+------------+------+-----------------+----------+---------+-------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------+----------+---------+-------+------+----------+--------------------------+
| 1 | SIMPLE | buy_log | NULL | ref | userid,userid_2 | userid_2 | 4 | const | 4 | 100.00 | Using where; Using index |
+----+-------------+---------+------------+------+-----------------+----------+---------+-------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
同样的,对于上述的SQL语句既可以使用 userid索引,也可以使用(userid,buy_date)索引。但是这次优化器使用了(userid, buy_date)的联合索引 userid2,因为在这个联合索引中 buy_date已经排序好了。根据该联合索引取出数据,无须再对 buy_date做一次额外的排序操作。若强制使用 userid索引,则执行计划如下所示。
mysql> explain select * from buy_log force index(userid) where userid=1 order by buy_date desc limit 3;
+----+-------------+---------+------------+------+---------------+--------+---------+-------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+--------+---------+-------+------+----------+---------------------------------------+
| 1 | SIMPLE | buy_log | NULL | ref | userid | userid | 4 | const | 4 | 100.00 | Using index condition; Using filesort |
+----+-------------+---------+------------+------+---------------+--------+---------+-------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.01 sec)
在Extra选项中可以看到 Using filesort,即需要额外的一次排序操作才能完成查询而这次显然需要对列 buy_date排序,因为索引 userid中的 buy_date是未排序的正如前面所介绍的那样,联合索引(a,b)其实是根据列a、b进行排序,因此下列语句可以直接使用联合索引得到结果:
SELECT .. FROM TABLE WHERE a=xxx ORDER by b
然而对于联合索引(a,b,c)来说,下列语句同样可以直接通过联合索引得到结果:
SELECT .. FROM TABLE WHERE a=xxx ORDER BY b
SELECT .. FROM TABLE WHERE a=xxx AND b=xxx ORDER BY c
但是对于下面的语句,联合索引不能直接得到结果,其还需要执行一次 filesort排序操作,因为索引(a,c)并未排序:
SELECT .. FROM TABLE WHERE a=xxx ORDER BY C
3、覆盖索引
InnoDB存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录。使用覆盖索引的一个好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作。
注意覆盖索引技术最早是在 InnoDB Plugin中完成并实现。这意味着对于InnoDB版本小于1.0的,或者 MySQL数据库版本为5.0或以下的, InnoDB存储引擎不支持覆盖索引特性。
对于 InnoDB存储引擎的辅助索引而言,由于其包含了主键信息,因此其叶子节点存放的数据为(primary key1, primary key2,...key1,key2,…)。例如,下列语句都可仅使用一次辅助联合索引来完成查询:
SELECT key2 FROM table Where key1=xxx:
SELECT primary key2, key 2 FROM table Where key1=xxx:
SELECT primary key1, key 2 FROM table Where key1=xxx:
SELECT primary key1,primary key2, key2 FROM table Where key1=xxx:
覆盖索引的另一个好处是对某些统计问题而言的。还是对于上一小节创建的表buy_log要进行如下查询:
select count(*) from buy_log;
InnoDB存储引擎并不会选择通过查询聚集索引来进行统计。由于 buy_log表上还有辅助索引,而辅助索引远小于聚集索引,选择辅助索引可以减少IO操作,故优化器的选择如下:
mysql> explain select count(*) from buy_log;
+----+-------------+---------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
| 1 | SIMPLE | buy_log | NULL | index | NULL | userid | 4 | NULL | 7 | 100.00 | Using index |
+----+-------------+---------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
可以看到, possible_keys列为NULL,但是实际执行时优化器却选择了userid索引,而列 Extra列的 Using index就是代表了优化器进行了覆盖索引操作。
此外,在通常情况下,诸如(a,b)的联合索引,一般是不可以选择列b中所谓的查询条件。但是如果是统计操作,并且是覆盖索引的,则优化器会进行选择,如下述语句:
mysql> explain SELECT COUNT(*) FROM buy_log Where buy_date>='2011-01-01' and buy_date< '2011-02-01';
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | buy_log | NULL | index | NULL | userid_2 | 8 | NULL | 7 | 14.29 | Using where; Using index |
+----+-------------+---------+------------+-------+---------------+----------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
表 buy_log有(userid, buy_date)的联合索引,这里只根据列buy_date进行条件查询,一般情况下是不能进行该联合索引的,但是这句SQL查询是统计操作,并且可以利用到覆盖索引的信息,因此优化器会选择该联合索引。
4、优化器选择不使用索引的情况
在某些情况下,当执行 EXPLAIN命令进行SQL语句的分析时,会发现优化器并没有选择索引去查找数据,而是通过扫描聚集索引,也就是直接进行全表的扫描来得到数据。这种情况多发生于范围查找、JOIN链接操作等情况下。例如:
SELECT FROM orderdetails Where orderid>10000 and orderid<102000;
上述这句SQL语句查找订单号大于10000的订单详情,通过命令 SHOW INDEX FROM orderdetails,可观察到的索引如图所示。

可以看到表 orderdetails有(OrderID, ProductID)的联合主键,此外还有对于列OrderID的单个索引。上述这句SQL显然是可以通过扫描 OrderID上的索引进行数据的查找。然而通过 EXPLAIN命令,用户会发现优化器并没有按照 OrderID上的索引来查找数据,如图所示。
在 possible_keys一列可以看到查询可以使用 PRIMARY、 OrderID、 OrdersOrder_Details三个索引,但是在最后的索引使用中,优化器选择了 PRIMARY聚集索引,也就是表扫描(table scan),而非 OrderID辅助索引扫描(index scan)。这是为什么呢?
原因在于用户要选取的数据是整行信息,而 OrderID索引不能覆盖到我们要査询的信息,因此在对 OrderID索引查询到指定数据后,还需要一次书签访问来查找整行数据的信息。虽然 OrderID索引中数据是顺序存放的,但是再一次进行书签查找的数据则是无序的,因此变为了磁盘上的离散读操作。如果要求访问的数据量很小,则优化器还是会选择辅助索引,但是当访问的数据占整个表中数据的蛮大一部分时(一般是20%左右),优化器会选择通过聚集索引来查找数据。因为之前已经提到过,顺序读要远远快于离散读。因此对于不能进行索引覆盖的情况,优化器选择辅助索引的情况是,通过辅助索引查找的数据是少量的。这是由当前传统机械硬盘的特性所决定的,即利用顺序读来替换随机读的查找。若用户使用的磁盘是固态硬盘,随机读操作非常快,同时有足够的自信来确认使用辅助索引可以带来更好的性能,那么可以使用关键字 FORCE INDEX来强制使用某个索引,如:
SELECt FROM orderdetails FORCE INDEX(OrderID) Where orderid>10000 and orderid<102000;
这时的执行计划如图所示。

5、索引提示
MySQL数据库支持索引提示(INDEX HINT),显式地告诉优化器使用哪个索引。
个人总结以下两种情况可能需要用到 INDEX HINT:
- MySQL数据库的优化器错误地选择了某个索引,导致SQL语句运行的很慢。这种情况在最新的 MySQL数据库版本中非常非常的少见。优化器在绝大部分情况下工作得都非常有效和正确。这时有经验的DBA或开发人员可以强制优化器使用某个索引,以此来提高SQL运行的速度。
- 某SQL语句可以选择的索引非常多,这时优化器选择执行计划时间的开销可能会大于SQL语句本身。例如,优化器分析 Range查询本身就是比较耗时的操作。这时DBA或开发人员分析最优的索引选择,通过 Index hint来强制使优化器不进行各个执行路径的成本分析,直接选择指定的索引来完成查询。
在 MySQL数据库中 Index hint的语法如下

接着来看一个例子,首先根据如下代码创建测试表t,并填充相应数据
mysql> create table t( a int, b int, key(a), key(b) )engine=innodb;
Query OK, 0 rows affected (0.03 sec)
mysql> insert into t values(1,1),(1,2),(2,3),(2,4),(1,2);
Query OK, 5 rows affected (0.01 sec)
Records: 5 Duplicates: 0 Warnings: 0
然后执行如下的SQL语句:
SELECT * FROM t Where a=1 AND b =2;
通过 EXPLAIN命令得到如下所示的执行计划。
mysql> explain select * from t where a=1 and b=2;
+----+-------------+-------+------------+-------------+---------------+------+---------+------+------+----------+------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------------+---------------+------+---------+------+------+----------+------------------------------------------------+
| 1 | SIMPLE | t | NULL | index_merge | a,b | b,a | 5,5 | NULL | 1 | 100.00 | Using intersect(b,a); Using where; Using index |
+----+-------------+-------+------------+-------------+---------------+------+---------+------+------+----------+------------------------------------------------+
1 row in set, 1 warning (0.01 sec)
结果中的列 possible_keys显示了上述SQL语句可使用的索引为a,b,而实际使用的索引为列key所示,同样为a,b。也就是 MySQL数据库使用a,b两个索引来完成这一个查询。列 Extra提示的 Using intersect(b,a)表示根据两个索引得到的结果进行求交的数学运算,最后得到结果。
如果我们使用 USE INDEX的索引提示来使用a这个索引,如:
select * from t use index(a) where a=1 and b=2;
那么得到的结果如下所示。
mysql> explain select * from t use index(a) where a=1 and b=2;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ALL | a | NULL | NULL | NULL | 5 | 20.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
可以看到,虽然我们指定使用a索引,但是优化器实际选择的是通过表扫描的方式。
因此, USE INDEX只是告诉优化器可以选择该索引,实际上优化器还是会再根据自己的判断进行选择。而如果使用 FORCE INDEX的索引提示,如:
mysql> explain select * from t force index(a) where a=1 and b=2;
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | t | NULL | ref | a | a | 5 | const | 3 | 20.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
可以看到,这时优化器的最终选择和用户指定的索引是一致的。因此,如果用户确定指定某个索引来完成査询,那么最可靠的是使用 FORCEⅠNDEX,而不是USE INDEX。
6、Multi-Range Read优化
MySQL5.6版本开始支持 Multi-Range Read(MRR)优化。 Multi-Range Read优化的目的就是为了减少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问,这对于IO-bound类型的SQL查询语句可带来性能极大的提升。 Multi-Range Read优化可适用于range,ref, eq ref类型的查询。
MRR优化有以下几个好处:
- MRR使数据访问变得较为顺序。在查询辅助索引时,首先根据得到的查询结果,按照主键进行排序,并按照主键排序的顺序进行书签查找
- 减少缓冲池中页被替换的次数
- 批量处理对键值的查询操作。
对于 InnoDB和 MyISAM存储引擎的范围查询和JOIN查询操作,MRR的工作方式如下:
- 将查询得到的辅助索引键值存放于一个缓存中,这时缓存中的数据是根据辅助索引键值排序的。
- 将缓存中的键值根据 RowID进行排序。
- 根据 RowID的排序顺序来访问实际的数据文件。
此外,若 InnoDB存储引擎或者 MyISAM存储引擎的缓冲池不是足够大,即不能存放下一张表中的所有数据,此时频繁的离散读操作还会导致缓存中的页被替换出缓冲池,然后又不断地被读入缓冲池。若是按照主键顺序进行访问,则可以将此重复行为降为最低。如下面这句SQL语句
SELECT FROM salaries Where salary>10000 AND salary<40000;
salary上有一个辅助索引idx_s,因此除了通过辅助索引查找键值外,还需要通过书签查找来进行对整行数据的查询。当不启用 Multi-Range Read特性时,看到的执行计划如图所示。

若启用 Mulit-Range Read特性,则除了会在列 Extra看到 Using index condition外,还会看见 Using MRR选项,如图所示。

而在实际的执行中会体会到两个的执行时间差别非常巨大,如下表所示。
| 执行时间(秒) | |
|---|---|
| 执行时间(秒) | |
| 不使用Multi-RangeRead | 43.213 |
| 使用Multi-RangeRead | 4.212 |
在我的笔记本电脑上,上述两句语句的执行时间相差10倍之多。可见 Multi-Range Read将访问数据转化为顺序后查询性能得到提高。
注意上述测试都是在 MySQL数据库启动后直接执行SQL查询语句,此时需确保缓冲池中没有被预热,以及需要查询的数据并不包含在缓冲池中。
此外, Multi-Range Read还可以将某些范围查询,拆分为键值对,以此来进行批量的数据查询。这样做的好处是可以在拆分过程中,直接过滤一些不符合查询条件的数据,例如
SELECT FROM t Where key_part1 >=1000 and key_part1 <2000 and key_part2 =10000;
表t有(key_part1, key_par2)的联合索引,因此索引根据 key_part1,key_part2的位置关系进行排序。若没有 Multi-Read Range,此时查询类型为 Range,SQL优化器会先将 key_part1大于1000小于2000的数据都取出,即使 key_part2不等于1000,待取出行数据后再根据 key_part2的条件进行过滤。这会导致无用数据被取出。如果有大量的数据且其 key_part2不等于100,则启用 Mulit-Range Read优化会使性能有巨大的提升。
倘若启用了 Multi-Range Read优化,优化器会先将查询条件进行拆分,然后再进行数据查询。就上述查询语句而言,优化器会将查询条件拆分为(1000,1000),(1001,1000),(1002,1000),…,(1999,1000),最后再根据这些拆分出的条件进行数据的查询。
可以来看一个实际的例子,查询如下:
SELECT * FROM salaries Where (from_date between '1986-01-01' AND '1995-01-01') AND (salary between 38000 and 40000);
若启用了 Multi-Range Read优化,则执行计划如图所示。

表 salaries上有对于 salary的索引idxs,在执行上述SQL语句时,因为启用了Mult-Range Read优化,所以会对查询条件进行拆分,这样在列Extra中可以看到 Using MRR选项。
是否启用 Multi-Range Read优化可以通过参数 optimizer_switch中的标记(flag)来控制。当mrr为on时,表示启用 Multi-Range Read优化。 mrr_cost_based标记表示是否通过 cost based的方式来选择是否启用mrr。若将mrr设为on, mrr_cost_based设为off,则总是启用 Multi-Range Read优化。例如,下述语句可以将 Multi-Range Read优化总是设为开启状态:
mysql> SET optimizer_switch='mrr=on,mrr_cost_based=off';
Query OK, 0 rows affected (0.00 sec)
参数 read_rnd_buffer_size用来控制键值的缓冲区大小,当大于该值时,则执行器对已经缓存的数据根据 RowID进行排序,并通过RowID来取得行数据。该值默认为256K:
mysql> select @@read_rnd_buffer_size;
+------------------------+
| @@read_rnd_buffer_size |
+------------------------+
| 262144 |
+------------------------+
1 row in set (0.00 sec)
7、Index Condition Pushdown(ICP)优化
和 Multi-Range Read一样, Index Condition Pushdown同样是 MySQL5.6开始支持的种根据索引进行查询的优化方式。之前的 MySQL数据库版本不支持 Index Condition Pushdown,当进行索引查询时,首先根据索引来查找记录,然后再根据 WHERE条件来过滤记录。在支持 Index Condition Pushdown后, MySQL数据库会在取出索引的同时,判断是否可以进行 WHERE条件的过滤,也就是将 WHERE的部分过滤操作放在了存储引擎层。在某些查询下,可以大大减少上层SQL层对记录的索取(fetch),从而提高数据库的整体性能。
Index Condition pushdown优化支持 range、ref、 eq ref、 ref or null类型的查询,当前支持 MyISAM和 InnoDB存储引擎。当优化器选择 Index Condition Pushdown优化时,可在执行计划的列 Extra看到 Using index condition提示。
注意 NDB Cluster存储引擎支持 Engine Condition Pushdown优化。不仅可以进行“ Index”的 Condition pushdown,也可以支持非索引的 Condition Pushdown,不过这是由其引擎本身的特性所决定的。另外在 MySQL5.1版本中 NDB Cluster存储引擎就开始支持 Engine Condition Pushdown优化。
假设某张表有联合索引( zip code, last name, firset name),并且查询语句如下:
SELECT * FROM people WHERE zipcode=95054 AND lastname like '%etruria% and address like '%Main street%';
对于上述语句, MySQL数据库可以通过索引来定位 zipcode等于95054的记录,但是索引对 WHERE条件的 lastname LIKE %etruria%' AND address LIKE %Main Street%'没有任何帮助。若不支持 Index Condition Pushdown优化,则数据库需要先通过索引取出所有 zipcode等于95054的记录,然后再过滤 WHERE之后的两个条件。
若支持 Index Condition pushdown优化,则在索引取出时,就会进行WHERE条的过滤,然后再去获取记录。这将极大地提高查询的效率。当然, WHERE可以过滤的条件是要该索引可以覆盖到的范围。来看下面的SQL语句:
SELECT * FROM salaries Where (from_date between '1986-01-01' AND ' 1995-01-01' AND (salary between 38000 and 40000);
若不启用 Multi-Range Read优化,则其执行计划如图所示。

可以看到列 Extra有 Using index condition的提示。但是为什么这里的idx_s索引会使用 Index Condition Pushdown优化呢?因为这张表的主键是(emp_no, from_date)的联合索引,所以idx_s索引中包含了from_date的数据,故可使用此优化方式。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
