对于一个能够支撑超高并发的大型分布式系统来说,像Redis这类分布式缓存是必不可少。Redis在单机部署的模式下,QPS几乎不可能超过10万+,除非机器配置特别好且Redis操作不太复杂。
我们知道,对于数据库来说,如果想要提升读写性能,最简单的方式就是做 一主多从+读写分离 。对于分布式缓存也是一样的道理,因为缓存一般都是用来支撑读请求的高并发,写请求相对较少(一般也就每秒一两千写请求),所以非常适合读写分离的架构。
关于Redis的复制原理,我在进阶篇的《分布式框架之高性能:Redis主从同步》已经详细讲解过了,不熟悉的读者可以先去了解下。
一、主从架构搭建
在生产环境下,我们必须要将Master节点的持久化功能打开,否则万一Master宕机后重启,此时Slave连上Master后,会触发一次全量复制,master就会将空的数据集同步到slave上去,导致Slave中的数据也被清空。
我们先来搭建一个一主二从的Redis构架,我首先在ressmix-dsf02这个节点上安装单机版本的Redis。具体的安装步骤不再赘述,读者可以参考我在《Redis持久化实战》中讲解的搭建步骤。
1.1 配置步骤
搭建完Redis节点后,我们按照以下步骤进行读写分离的配置,ressmix-dsf01作为Master,ressmix-dsf02和ressmix-dsf03作为Slave。(我这里只操作ressmix-dsf02,ressmix-dsf03读者可以自行操作)
- 修改Slave节点的配置文件,配置
replicaof ressmix-dsf01 6379,这样ressmix-dsf01节点就作为了ressmix-dsf02的Master节点; - 强制读写分离:修改Slave节点的配置文件,配置
replica-read-only yes,这样Slave节点会拒绝所有的写操作(Redis 2.6以后Slave节点默认就是只读的,所以这个版本以后的Redis默认可以不设置); - 集群安全认证:修改Slave节点的配置文件,配置
masterauth ressmix,其中ressmix是我设置的认证密码; - 停止Master节点,然后修改Master节点的配置文件,配置
requirepass ressmix; - 主从节点均配置
appendonly yes,开启AOF持久化; - 绑定节点IP:修改Slave节点的配置文件,配置
bind 192.168.0.109,其中192.168.0.109为ressmix-dsf02的IP,同理也把Master节点的这个配置修改下。另外,为了以防外一,每个节点都执行下iptables -A INPUT -ptcp --dport 6379 -j ACCEPT,用于放开6379端口,然后清理下防火墙:sudo iptables -F。
上述操作全部配置完成后,我们通过以下命令启动主节点,然后以相同方式启动从节点ressmix-dsf02。
cd /etc/init.d
./redis_6379 start
节点启动后,我们可以先在Master节点中写入一条记录:
redis-cli -h 192.168.0.107 -a ressmix
set k1 v1

然后在ressmix-dsf02节点可以查看到同步过来的数据:

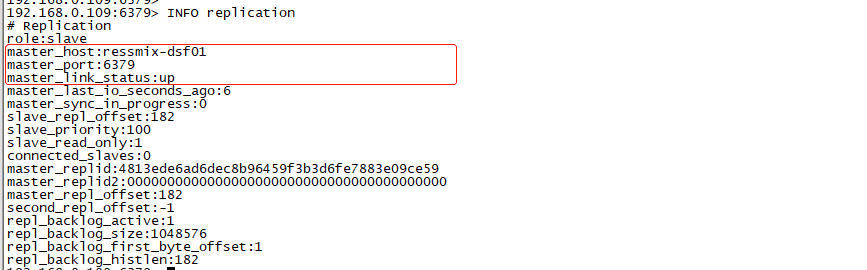
我们可以通过执行info replication查看主从复制的状态:
二、性能压测
搭建完Redis的主从架构后,可以对其做一个基准压测,测一下Redis的性能和QPS。Redis自身提供了redis-benchmark压测工具,可以用于一些简单场景下性能测试。
压测工具位于redis安装包的src目录下:
./redis-benchmark -h 192.168.0.107
常用参数如下:
-c <clients> Number of parallel connections (default 50)
-n <requests> Total number of requests (default 100000)
-d <size> Data size of SET/GET value in bytes (default 2)
我们可以根据自己系统高峰期的业务量来设置参数,比如在高峰期,瞬时最大用户量会达到10万,总请求数为1000万,每条数据的大小为50字节,则可以像下面这样模拟请求:
./redis-benchmark -h 192.168.0.107 -c 100000 -n 10000000 -d 50
压测的结果可能像下面这样,显示了不同操作的每秒请求数:
====== PING_INLINE ======
100000 requests completed in 1.28 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.78% <= 1 milliseconds
99.93% <= 2 milliseconds
99.97% <= 3 milliseconds
100.00% <= 3 milliseconds
78308.54 requests per second
====== PING_BULK ======
100000 requests completed in 1.30 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.87% <= 1 milliseconds
100.00% <= 1 milliseconds
76804.91 requests per second
====== SET ======
100000 requests completed in 2.50 seconds
50 parallel clients
3 bytes payload
keep alive: 1
5.95% <= 1 milliseconds
99.63% <= 2 milliseconds
99.93% <= 3 milliseconds
99.99% <= 4 milliseconds
100.00% <= 4 milliseconds
40032.03 requests per second
====== GET ======
100000 requests completed in 1.30 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.73% <= 1 milliseconds
100.00% <= 2 milliseconds
100.00% <= 2 milliseconds
76628.35 requests per second
====== INCR ======
100000 requests completed in 1.90 seconds
50 parallel clients
3 bytes payload
keep alive: 1
80.92% <= 1 milliseconds
99.81% <= 2 milliseconds
99.95% <= 3 milliseconds
99.96% <= 4 milliseconds
99.97% <= 5 milliseconds
100.00% <= 6 milliseconds
52548.61 requests per second
====== LPUSH ======
100000 requests completed in 2.58 seconds
50 parallel clients
3 bytes payload
keep alive: 1
3.76% <= 1 milliseconds
99.61% <= 2 milliseconds
99.93% <= 3 milliseconds
100.00% <= 3 milliseconds
38684.72 requests per second
====== RPUSH ======
100000 requests completed in 2.47 seconds
50 parallel clients
3 bytes payload
keep alive: 1
6.87% <= 1 milliseconds
99.69% <= 2 milliseconds
99.87% <= 3 milliseconds
99.99% <= 4 milliseconds
100.00% <= 4 milliseconds
40469.45 requests per second
====== LPOP ======
100000 requests completed in 2.26 seconds
50 parallel clients
3 bytes payload
keep alive: 1
28.39% <= 1 milliseconds
99.83% <= 2 milliseconds
100.00% <= 2 milliseconds
44306.60 requests per second
====== RPOP ======
100000 requests completed in 2.18 seconds
50 parallel clients
3 bytes payload
keep alive: 1
36.08% <= 1 milliseconds
99.75% <= 2 milliseconds
100.00% <= 2 milliseconds
45871.56 requests per second
====== SADD ======
100000 requests completed in 1.23 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.94% <= 1 milliseconds
100.00% <= 2 milliseconds
100.00% <= 2 milliseconds
81168.83 requests per second
====== SPOP ======
100000 requests completed in 1.28 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.80% <= 1 milliseconds
99.96% <= 2 milliseconds
99.96% <= 3 milliseconds
99.97% <= 5 milliseconds
100.00% <= 5 milliseconds
78369.91 requests per second
====== LPUSH (needed to benchmark LRANGE) ======
100000 requests completed in 2.47 seconds
50 parallel clients
3 bytes payload
keep alive: 1
15.29% <= 1 milliseconds
99.64% <= 2 milliseconds
99.94% <= 3 milliseconds
100.00% <= 3 milliseconds
40420.37 requests per second
====== LRANGE_100 (first 100 elements) ======
100000 requests completed in 3.69 seconds
50 parallel clients
3 bytes payload
keep alive: 1
30.86% <= 1 milliseconds
96.99% <= 2 milliseconds
99.94% <= 3 milliseconds
99.99% <= 4 milliseconds
100.00% <= 4 milliseconds
27085.59 requests per second
====== LRANGE_300 (first 300 elements) ======
100000 requests completed in 10.22 seconds
50 parallel clients
3 bytes payload
keep alive: 1
0.03% <= 1 milliseconds
5.90% <= 2 milliseconds
90.68% <= 3 milliseconds
95.46% <= 4 milliseconds
97.67% <= 5 milliseconds
99.12% <= 6 milliseconds
99.98% <= 7 milliseconds
100.00% <= 7 milliseconds
9784.74 requests per second
====== LRANGE_500 (first 450 elements) ======
100000 requests completed in 14.71 seconds
50 parallel clients
3 bytes payload
keep alive: 1
0.00% <= 1 milliseconds
0.07% <= 2 milliseconds
1.59% <= 3 milliseconds
89.26% <= 4 milliseconds
97.90% <= 5 milliseconds
99.24% <= 6 milliseconds
99.73% <= 7 milliseconds
99.89% <= 8 milliseconds
99.96% <= 9 milliseconds
99.99% <= 10 milliseconds
100.00% <= 10 milliseconds
6799.48 requests per second
====== LRANGE_600 (first 600 elements) ======
100000 requests completed in 18.56 seconds
50 parallel clients
3 bytes payload
keep alive: 1
0.00% <= 2 milliseconds
0.23% <= 3 milliseconds
1.75% <= 4 milliseconds
91.17% <= 5 milliseconds
98.16% <= 6 milliseconds
99.04% <= 7 milliseconds
99.83% <= 8 milliseconds
99.95% <= 9 milliseconds
99.98% <= 10 milliseconds
100.00% <= 10 milliseconds
5387.35 requests per second
====== MSET (10 keys) ======
100000 requests completed in 4.02 seconds
50 parallel clients
3 bytes payload
keep alive: 1
0.01% <= 1 milliseconds
53.22% <= 2 milliseconds
99.12% <= 3 milliseconds
99.55% <= 4 milliseconds
99.70% <= 5 milliseconds
99.90% <= 6 milliseconds
99.95% <= 7 milliseconds
100.00% <= 8 milliseconds
24869.44 requests per second
三、总结
本章,我重点讲解了如何进行生产环境的Redis读写分离部署,读者可以自己尝试在虚拟机中动手进行节点部署,以加深印象。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
