1、在循环中提交
开发人员非常喜欢在循环中进行事务的提交,下面是他们可能常写的一个存储过程:
CREATE PROCEDURE load1(count INT UNSIGNED)
BEGIN
DECLARE s INT UNSIGNED DEFAULT 1;
DECLARE c CHAR(80) DEFAULT REPEAT('a',80);
WHILE s < count DO
INSERT INTO t1 SELECT NULL,C;
COMMIT;
SET s =s+1;
END WHILE;
END;
其实,在上述的例子中,是否加上提交命令 COMMIT并不关键。因为 InnoDB存储引擎默认为自动提交,所以在上述的存储过程中去掉 COMMIT,结果其实是完全一样的。这也是另一个容易被开发人员忽视的问题:
CREATE PROCEDURE load2(count INT UNSIGNED)
BEGIN
DECLARE s INT UNSIGNED DEFAULT 1;
DECLARE c CHAR(80) DEFAULT REPEAT('a',80);
WHILE s < count DO
INSERT INTO t1 SELECT NULL,C;
SET s =s+1;
END WHILE;
END;
不论上面哪个存储过程都存在一个问题,当发生错误时,数据库会停留在一个未知的位置。例如,用户需要插入10000条记录,但是在插入5000条时,发生了错误,这时前5000条记录已经存放在数据库中,那应该怎么处理呢?另一个问题是性能问题,上面两个存储过程都不会比下面的存储过程load3快,因为下面的存储过程将所有的INSERT都放在一个事务中:
CREATE PROCEDURE load3(count INT UNSIGNED)
BEGIN
DECLARE s INT UNSIGNED DEFAULT 1;
DECLARE c CHAR(80) DEFAULT REPEAT('a',80);
START TRANSACTION;
WHILE s < count DO
INSERT INTO t1 SELECT NULL,C;
SET s =s+1;
END WHILE;
COMMIT;
END;
比较这3个存储过程的执行时间:
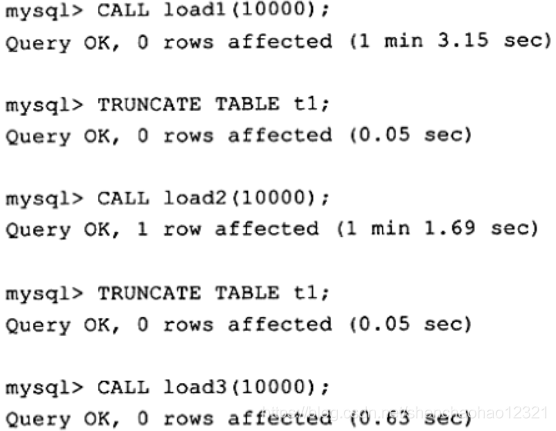
显然,第三种方法要快得多!这是因为每一次提交都要写一次重做日志,存储过程load1和load2实际写了10000次重做日志文件,而对于存储过程load3来说,实际只写了1次。
大多数程序员会使用第一种或第二种方法,有人可能不知道 InnoDB存储引擎自动提交的情况,另外有些人可能持有以下两种观点:首先,在他们曾经使用过的数据库中,对事务的要求总是尽快地进行释放,不能有长时间的事务;其次,他们可能担心存在 Oracle数据库中由于没有足够undo产生的 Snapshot Too old的经典问题。 MySQL的InnoDB存储引擎没有上述两个问题,因此程序员不论从何种角度出发,都不应该在一个循环中反复进行提交操作,不论是显式的提交还是隐式的提交。
2、使用自动提交
自动提交并不是一个好的习惯,因为这会使初级DBA容易犯错,另外还可能使一些开发人员产生错误的理解,如我们在前一小节中提到的循环提交问题。 MySQL数据库默认设置使用自动提交(autocommit),可以使用如下语句来改变当前自动提交的方式:
mysql> SET autocommit=0;
Query OK, 0 rows affected (0.00 sec)
也可以使用 START TRANSACTION,BEGN来显式地开启一个事务。在显式开启事务后,在默认设置下(即参数completion_type等于0), MySQL会自动地执行SET AUTOCOMMIT=0的命令,并在 COMMIT或 ROLLBACK结束一个事务后执行SET AUTOCOMMIT=1。
另外,对于不同语言的API,自动提交是不同的。 MySQL C API默认的提交方式是自动提交,而 MySQL Python API则会自动执行 SET AUTOCOMMIT=0,以禁用自动提交。因此在选用不同的语言来编写数据库应用程序前,应该对连接 MySQL的API做好研究。
我认为,在编写应用程序开发时,最好把事务的控制权限交给开发人员,即在程序端进行事务的开始和结束。同时,开发人员必须了解自动提交可能带来的问题。我曾经见过很多开发人员没有意识到自动提交这个特性,等到出现错误时应用就会遇到大麻烦。
3、使用自动回滚
InnoDB存储引擎支持通过定义一个 HANDLER来进行自动事务的回滚操作,如在一个存储过程中发生了错误会自动对其进行回滚操作。因此我发现很多开发人员喜欢在应用程序的存储过程中使用自动回滚操作,例如下面所示的一个存储过程:
CREATE PROCEDURE sp_auto_rollback_demo (
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION ROLLBACK;
START TRANSACTION;
INSERT INTO b SELECT 1;
INSERT INTO b SELECT 2;
INSERT INTO b SELECT 1;
INSERT INTO b SELECT 3;
COMMIT;
END;
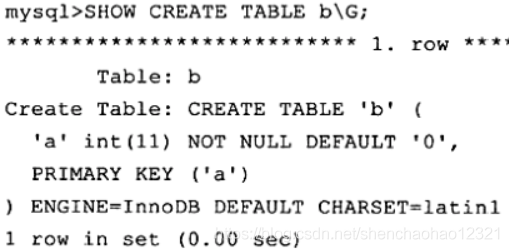
存储过程 sp_auto_rollback_demo首先定义了一个exit类型的 HANDLER捕获倒错误时进行回滚。结构如下:
因此插入第二个记录1时会发生错误,但是因为启用了自动回滚的操作,因此这个存储过程的执行结果如下:
mysql>CALL sp_auto_rollback_demo;
Query OK,0 rows affected (0.06 sec)
mysql>SELECT * FROM b;
Empty set (0.00 sec)
看起来运行没有问题,非常正常。但是,执行sp_auto_rollback_demo这个存储过程的结果到底是正确的还是错误的?对于同样的存储过程sp_auto_rollback_demo,为了得到执行正确与否的结果,开发人员可能会进行这样的处理:
CREATE PROCEDURE sp_auto_rollback_demo (
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION BEGIN ROLLBACK; SELECT -1; END;
START TRANSACTION;
INSERT INTO b SELECT 1;
INSERT INTO b SELECT 2;
INSERT INTO b SELECT 1;
INSERT INTO b SELECT 3;
COMMIT;
SELECT 1;
END;
当发生错误时,先回滚然后返回-1,表示运行有错误。运行正常返回值1。因此这次运行的结果就会变成:

看起来用户可以得到运行是否准确的信息。但问题还没有最终解决,对于开发人员来说,重要的不仅是知道发生了错误,而是发生了什么样的错误。因此自动回滚存在这样的一个问题。
习惯使用自动回滚的人大多是以前使用 Microsoft SQL Server数据库的开发人员。在Microsoft SQL Server数据库中,可以使用 SET XABORT ON来自动回滚一个事务。但是 Microsoft SQL Server数据库不仅会自动回滚当前的事务,还会抛出异常,开发人员可以捕获到这个异常。因此, Microsoft SQL Server数据库和 MySQL数据库在这方面是有所不同的。
就像之前小节中所讲到的,对事务的 BEGIN、 COMMIT和 ROLLBACK操作应该交给程序端来完成,存储过程需要完成的只是一个逻辑的操作,即对逻辑进行封装。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
