本篇文章参考了大量文章,文档以及论文,但是这块东西真的很繁杂,我的水平有限,可能理解的也不到位,如有异议欢迎留言提出。 本系列会不断更新,结合大家的问题以及这里的错误和疏漏,欢迎大家留言
如果你喜欢单篇版,请访问:全网最硬核 Java 新内存模型解析与实验单篇版(不断更新QA中)
如果你喜欢这个拆分的版本,这里是目录:
- 全网最硬核 Java 新内存模型解析与实验 - 1. 什么是 Java 内存模型
- 全网最硬核 Java 新内存模型解析与实验 - 2. 原子访问与字分裂
- 全网最硬核 Java 新内存模型解析与实验 - 3. 硬核理解内存屏障(CPU+编译器)
- 全网最硬核 Java 新内存模型解析与实验 - 4. Java 新内存访问方式与实验
- 全网最硬核 Java 新内存模型解析与实验 - 5. JVM 底层内存屏障源码分析
JMM 相关文档:- Java Language Specification Chapter 17
- The JSR-133 Cookbook for Compiler Writers - Doug Lea’s
- Using JDK 9 Memory Order Modes - Doug Lea’s
内存屏障,CPU 与内存模型相关:
x86 CPU 相关资料:
ARM CPU 相关资料:
各种一致性的理解:
Aleskey 大神的 JMM 讲解:
相信很多 Java 开发,都使用了 Java 的各种并发同步机制,例如 volatile,synchronized 以及 Lock 等等。也有很多人读过 JSR 第十七章 Threads and Locks(地址:https://docs.oracle.com/javase/specs/jls/se17/html/jls-17.html),其中包括同步、Wait/Notify、Sleep & Yield 以及内存模型等等做了很多规范讲解。但是也相信大多数人和我一样,第一次读的时候,感觉就是在看热闹,看完了只是知道他是这么规定的,但是为啥要这么规定,不这么规定会怎么样,并没有很清晰的认识。同时,结合 Hotspot 的实现,以及针对 Hotspot 的源码的解读,我们甚至还会发现,由于 javac 的静态代码编译优化以及 C1、C2 的 JIT 编译优化,导致最后代码的表现与我们的从规范上理解出代码可能的表现是不太一致的。并且,这种不一致,导致我们在学习 Java 内存模型(JMM,Java Memory Model),理解 Java 内存模型设计的时候,如果想通过实际的代码去试,结果是与自己本来可能正确的理解被带偏了,导致误解。
我本人也是不断地尝试理解 Java 内存模型,重读 JLS 以及各路大神的分析。这个系列,会梳理我个人在阅读这些规范以及分析还有通过 jcstress 做的一些实验而得出的一些理解,希望对于大家对 Java 9 之后的 Java 内存模型以及 API 抽象的理解有所帮助。但是,还是强调一点,内存模型的设计,出发点是让大家可以不用关心底层而抽象出来的一些设计,涉及的东西很多,我的水平有限,可能理解的也不到位,我会尽量把每一个论点的论据以及参考都摆出来, 请大家不要完全相信这里的所有观点,如果有任何异议欢迎带着具体的实例反驳并留言 。
5. 内存屏障
5.1. 为何需要内存屏障
内存屏障(Memory Barrier),也有叫内存栅栏(Memory Fence),还有的资料直接为了简便,就叫 membar,这些其实意思是一样的。内存屏障主要为了解决指令乱序带来了结果与预期不一致的问题,通过加入内存屏障防止指令乱序(或者称为重排序,reordering)。
那么为什么会有指令乱序呢?主要是因为 CPU 乱序(CPU乱序还包括 CPU 内存乱序以及 CPU 指令乱序)以及编译器乱序 。内存屏障可以用于防止这些乱序。如果内存屏障对于编译器和 CPU 都生效,那么一般称为硬件内存屏障,如果只对编译器生效,那么一般被称为软件内存屏障。我们这里主要关注 CPU 带来的乱序,对于编译器的重排序我们会在最后简要介绍下。
5.2. CPU 内存乱序相关
我们从 CPU 高速缓存以及缓存一致性协议出发,开始分析为何 CPU 中会有乱序。我们这里假设 一种简易的 CPU 模型 , 请大家一定记住,实际的 CPU 要比这里列举的简易 CPU 模型复杂的多
5.2.1. 简易 CPU 模型 - CPU 高速缓存的出发点 - 减少 CPU Stall
我们在这里会看到,现代的 CPU 的很多设计,一切以减少 CPU Stall 出发。什么是 CPU Stall 呢?举一个简单的例子,假设 CPU 需要直接读取内存中的数据(忽略其他的结构,例如 CPU 缓存,总线与总线事件等等):
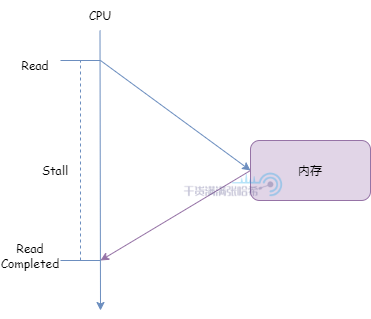
CPU 发出读取请求,在内存响应之前,CPU 需要一直等待,无法处理其他的事情。这一段 CPU 就是 处于 Stall 状态 。如果 CPU 一直直接从内存中读取,CPU 直接访问内存消耗时间很长,可能需要 几百个指令周期 ,也就是每次访问都会有几百个指令周期内 CPU 处于 Stall 状态什么也干不了,这样效率会很低。一般需要引入 若干个高速缓存 (Cache)来减少 Stall:高速缓存即与处理器紧挨着的小型存储器,位于处理器和内存之间。
我们这里 不关心多级高速缓存,以及是否存在多个 CPU 共用某一缓存的情况 ,我们就简单认为是下面这个架构:
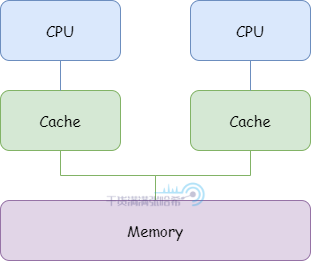
当需要读取一个地址的值时,访问高速缓存看是否存在:存在代表 命中 (hit),直接读取。不存在被称为 缺失 (miss)。同样的,如果需要写一个值到一个地址,这个地址在缓存中存在也就不需要访问内存了。大部分程序都表现出较高的 局部性 (locality):
- 如果处理器读或写一个内存地址,那么它很可能很快还会读或写同一个地址 。
- 如果处理器读或写一个内存地址,那么它很可能很快还会读或写附近的地址 。
针对局部性,高速缓存一般会一次操作不止一个字,而是 一组临近的字 ,称为 缓存行 。
但是呢,由于告诉缓存的存在,就给更新内存带来了麻烦:当一个 CPU 需要更新一块缓存行对应内存的时候,它需要将其他 CPU 缓存中这块内存的缓存行也置为失效。为了维持每个 CPU 的缓存数据一致性,引入了缓存一致性协议(Cache Coherence Protocols)
5.2.2. 简易 CPU 模型 - 一种简单的缓存一致性协议(实际的 CPU 用的要比这个复杂) - MESI
现代的缓存一致性的协议以及算法非常复杂,缓存行可能会有数十种不同的状态。这里我们并不需要研究这种复杂的算法,我们这里引入一个最经典最简单的缓存一致性协议即 4 状态 MESI 协议( 再次强调,实际的 CPU 用的协议要比这个复杂,MESI 其实本身有些问题解决不了 ),MESI 其实指的就是缓存行的四个状态:
- Modified :缓存行被修改,最终一定会被写回入主存,在此之前其他处理器不能再缓存这个缓存行。
- Exclusive :缓存行还未被修改,但是其他的处理器不能将这个缓存行载入缓存
- Shared :缓存行未被修改,其他处理器可以加载这个缓存行到缓存
- Invalid :缓存行中没有有意义的数据
根据我们前面的 CPU 缓存结构图中所示,假设所有 CPU 都共用在同一个总线上,则会有如下这些信息在总线上发送:
- Read :这个事件包含要读取的缓存行的物理地址。
- Read Response :包含前面的读取事件请求的数据,数据来源可能是 内存或者是其他高速缓存 ,例如,如果请求的数据在其他缓存处于 modified 状态的话,那么必须从这个缓存读取缓存行数据作为 Read Response
- Invalidate :这个事件包含要过期掉的缓存行的物理地址。其他的高速缓存必须移除这个缓存行并且响应 Invalidate Acknowledge 消息。
- Invalidate Acknowledge :收到 Invalidate 消息移除掉对应的缓存行之后,回复 Invalidate Acknowledge 消息。
- Read Invalidate :是 Read 消息还有 Invalidate 消息的组合,包含要读取的缓存行的物理地址。既读取这个缓存行并且需要 Read Response 消息响应,同时发给其他的高速缓存,移除这个缓存行并且响应 Invalidate Acknowledge 消息。
- Writeback :这个消息包含要更新的内存地址以及数据。同时,这个消息也允许状态为 modified 的缓存行被剔除,以给其他数据腾出空间。
缓存行状态转移与事件 的关系:
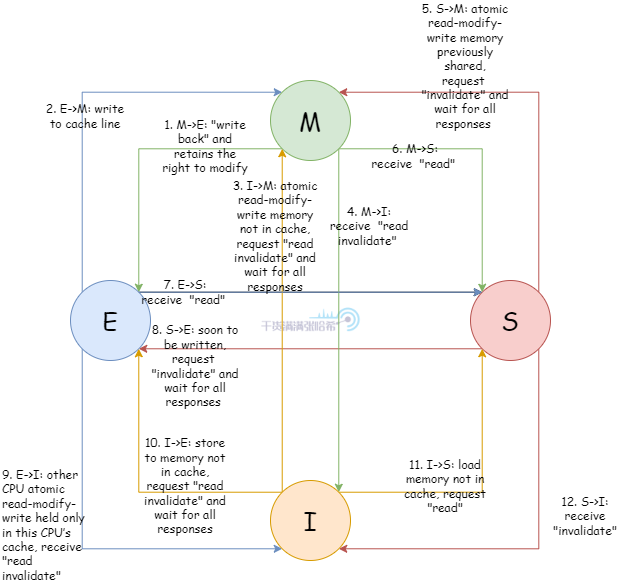
这里只是列出这个图, 我们不会深入去讲的,因为 MESI 是一个非常精简的协议,具体实现的时候会有很多额外的问题 MESI 无法解决 ,如果详细的去讲,会把读者绕进去,读者会思考在某个极限情况下这个协议要怎么做才能保证正确,但是 MESI 实际上解决不了这些。在 实际的实现中,CPU 一致性协议要比 MESI 复杂的多得多,但是一般都是基于 MESI 扩展的 。
举一个简单的 MESI 的例子:
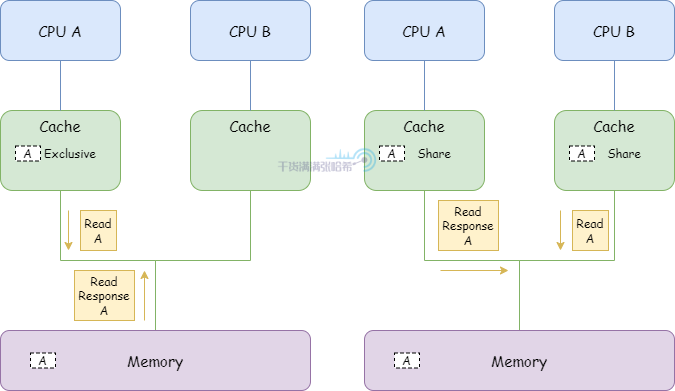
1.CPU A 发送 Read 从地址 a 读取数据,收到 Read Response 将数据存入他的高速缓存并将对应的缓存行置为 Exclusive
2.CPU B 发送 Read 从地址 a 读取数据,CPU A 检测到地址冲突,CPU A 响应 Read Response 返回缓存中包含 a 地址的缓存行数据,之后,地址 a 的数据对应的缓存行被 A 和 B 以 Shared 状态装入缓存
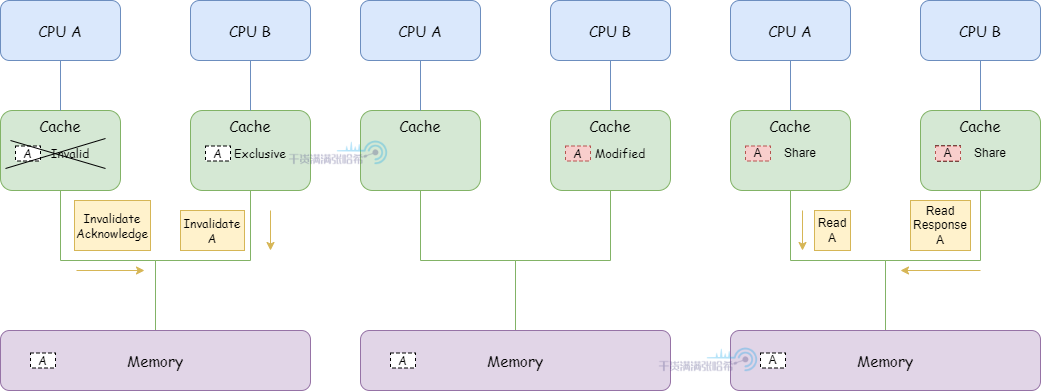
3.CPU B 对于 a 马上要进行写操作,发送 Invalidate ,等待 CPU A 的 Invalidate Acknowledge 响应之后,状态修改为 Exclusive 。CPU A 收到 Invalidate 之后,将 a 所在的缓存行状态置为 Invalid 失效
4.CPU B 修改数据存储到包含地址 a 的缓存行上,缓存行状态置为 modified
5.这时候 CPU A 又需要 a 数据,发送 Read 从地址 a 读取数据,CPU B 检测到地址冲突,CPU B 响应 Read Response 返回缓存中包含 a 地址的缓存行数据,之后,地址 a 的数据对应的缓存行被 A 和 B 以 Shared 状态装入缓存
我们这里可以看到,MESI 协议中,发送 Invalidate 消息需要当前 CPU 等待其他 CPU 的 Invalidate Acknowledge ,也就是 这里有 CPU Stall 。为了避免这个 Stall,引入了 Store Buffer
5.2.3. 简易 CPU 模型 - 避免等待 Invalidate Response 的 Stall - Store Buffer
为了避免这种 Stall,在 CPU 与 CPU 缓存之间添加 Store Buffer,如下图所示:
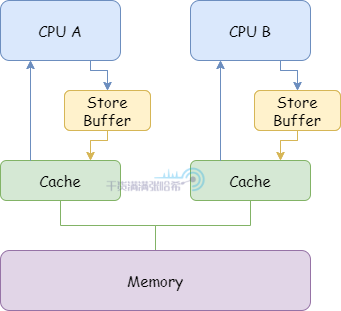
有了 Store Buffer,CPU 在发送 Invalidate 消息的时候,不用等待 Invalidate Acknowledge 的返回,将修改的数据直接放入 Store Buffer。如果收到了所有的 Invalidate Acknowledge 再从 Store Buffer 放入 CPU 的高速缓存的对应缓存行中。但是加入的这个 Store Buffer 又带来了新的问题:
假设有两个变量 a 和 b,不会处于同一个缓存行,初始都是 0,a 现在位于 CPU A 的缓存行中,b 现在位于 CPU B 的缓存行中:
假设 CPU B 要执行下面的代码:

我们肯定是期望最后 b 会等于 2 的。但是真的会如我们所愿么?我们来详细看下下面这个运行步骤:
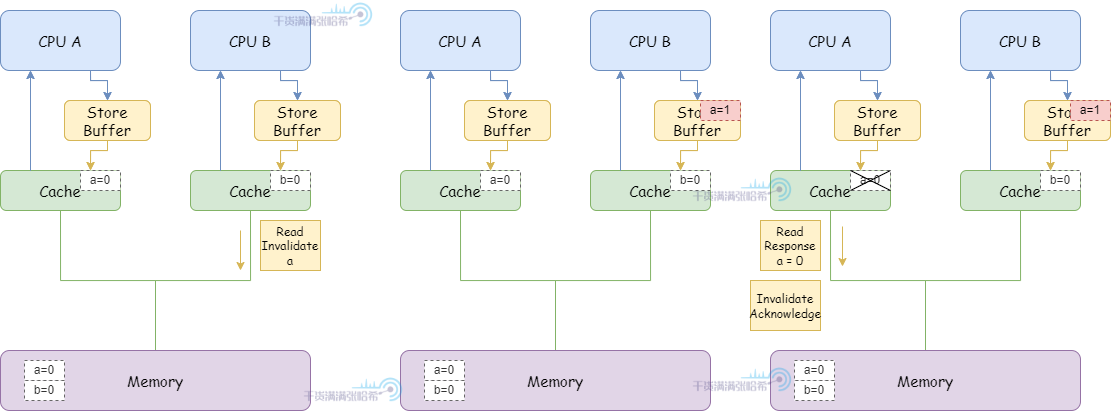
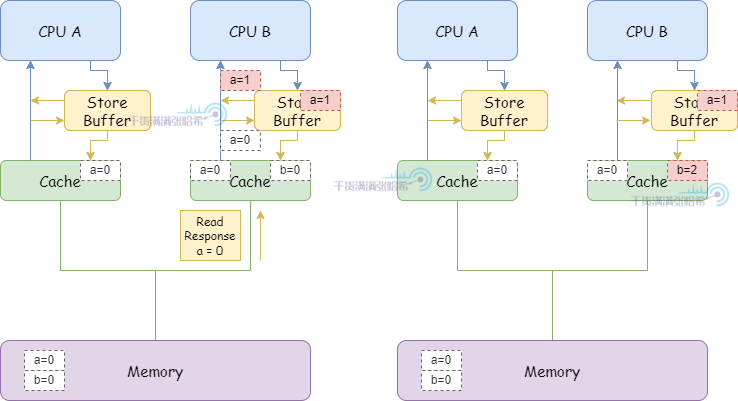
1.CPU B 执行 a = 1:
(1)由于 CPU B 缓存中没有 a,并且要修改,所以发布 Read Invalidate 消息(因为是要先把包含 a 的整个缓存行读取后才能更新,所以发的是 Read Invalidate ,而不只是 Invalidate)。
(2)CPU B 将 a 的修改(a=1)放入 Storage Buffer
(3)CPU A 收到 Read Invalidate 消息,将 a 所在的缓存行标记为 Invalid 并清除出缓存,并响应 Read Response (a=0) 和 Invalidate Acknowlegde 。
2.CPU B 执行 b = a + 1:
(1)CPU B 收到来自于 CPU A 的 Read Response ,这时候这里面 a 还是等于 0。
(2)CPU B 将 a + 1 的结果(0+1=1)存入缓存中已经包含的 b。
3.CPU B 执行 assert(b == 2) 失败
这个错误的原因主要是我们在加载到缓存的时候没考虑从 store buffer 最新的值,所以我们可以加上一步,在加载到缓存的时候从 store buffer 读取最新的值。这样,就能保证上面我们看到的结果 b 最后是 2:
5.2.4. 简易 CPU 模型 - 避免 Store Buffer 带来的乱序执行 - 内存屏障
我们下面再来看一个示例:假设有两个变量 a 和 b,不会处于同一个缓存行,初始都是 0。假设 CPU A (缓存行里面包含 b,这个缓存行状态是 Exclusive)执行:

假设 CPU B 执行:

如果一切按照程序顺序预期执行,那么我们期望 CPU B 执行 assert(a == 1) 是成功的,但是我们来看下面这种执行流程:
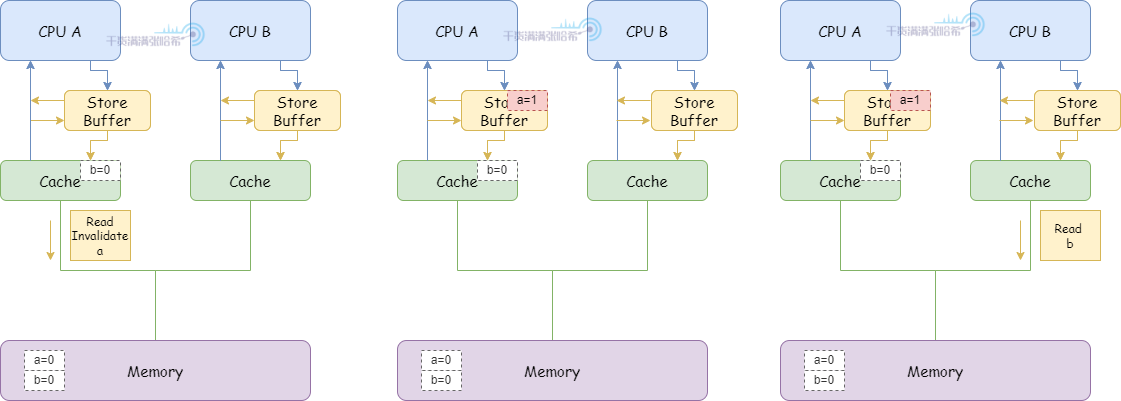
1.CPU A 执行 a = 1:
(1)CPU A 缓存里面没有 a,并且要修改,所以发布 Read Invalidate 消息。
(2)CPU A 将 a 的修改(a=1)放入 Storage Buffer
2.CPU B 执行 while (b == 0) continue:
(1)CPU B 缓存里面没有 b,发布 Read 消息。
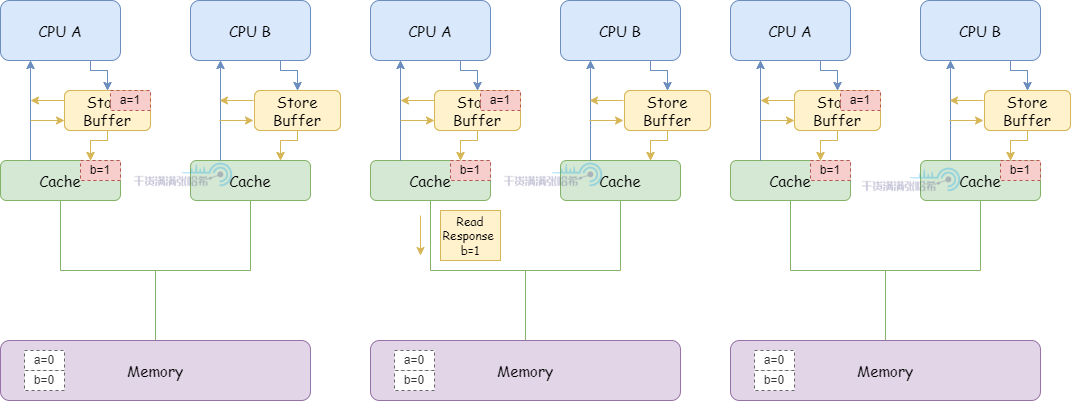
3.CPU A 执行 b = 1:
(1)CPU A 缓存行里面有 b,并且状态是 Exclusive,直接更新缓存行。
(2)之后,CPU A 收到了来自于 CPU B 的关于 b 的 Read 消息。
(3)CPU A 响应缓存中的 b = 1,发送 Read Response 消息,并且缓存行状态修改为 Shared
(4)CPU B 收到 Read Response 消息,将 b 放入缓存
(5)CPU B 代码可以退出循环了,因为 CPU B 看到 b 此时为 1
4.CPU B 执行 assert(a == 1),但是由于 a 的更改还没更新,所以失败了。
像这种乱序,CPU 一般是无法自动控制的,但是一般会提供内存屏障指令,告诉 CPU 防止乱序 ,例如:

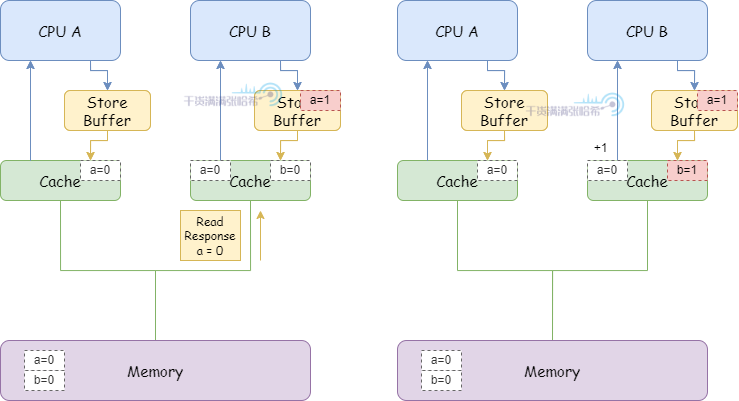
smp_mb() 会让 CPU 将 Store Buffer 中的内容刷入缓存。加入这个内存屏障指令后,执行流程变成:
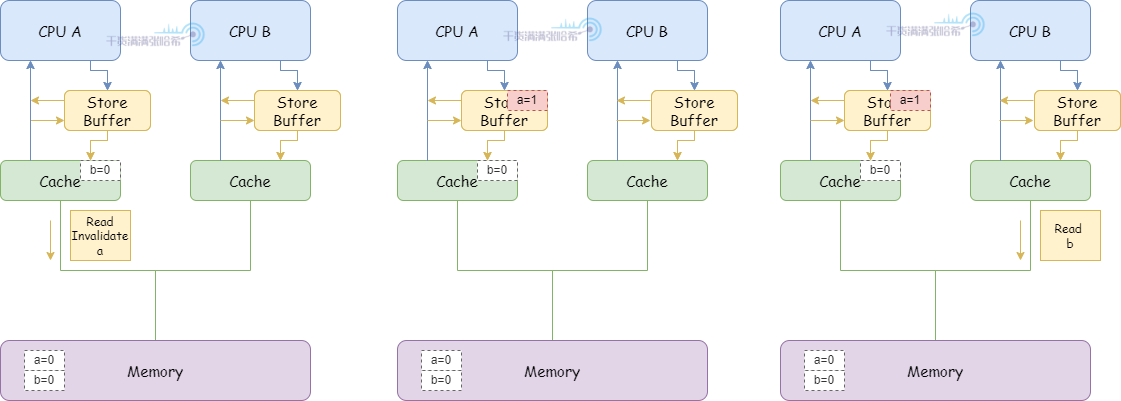
1.CPU A 执行 a = 1:
(1)CPU A 缓存里面没有 a,并且要修改,所以发布 Read Invalidate 消息。
(2)CPU A 将 a 的修改(a=1)放入 Storage Buffer
2.CPU B 执行 while (b == 0) continue:
(1)CPU B 缓存里面没有 b,发布 Read 消息。
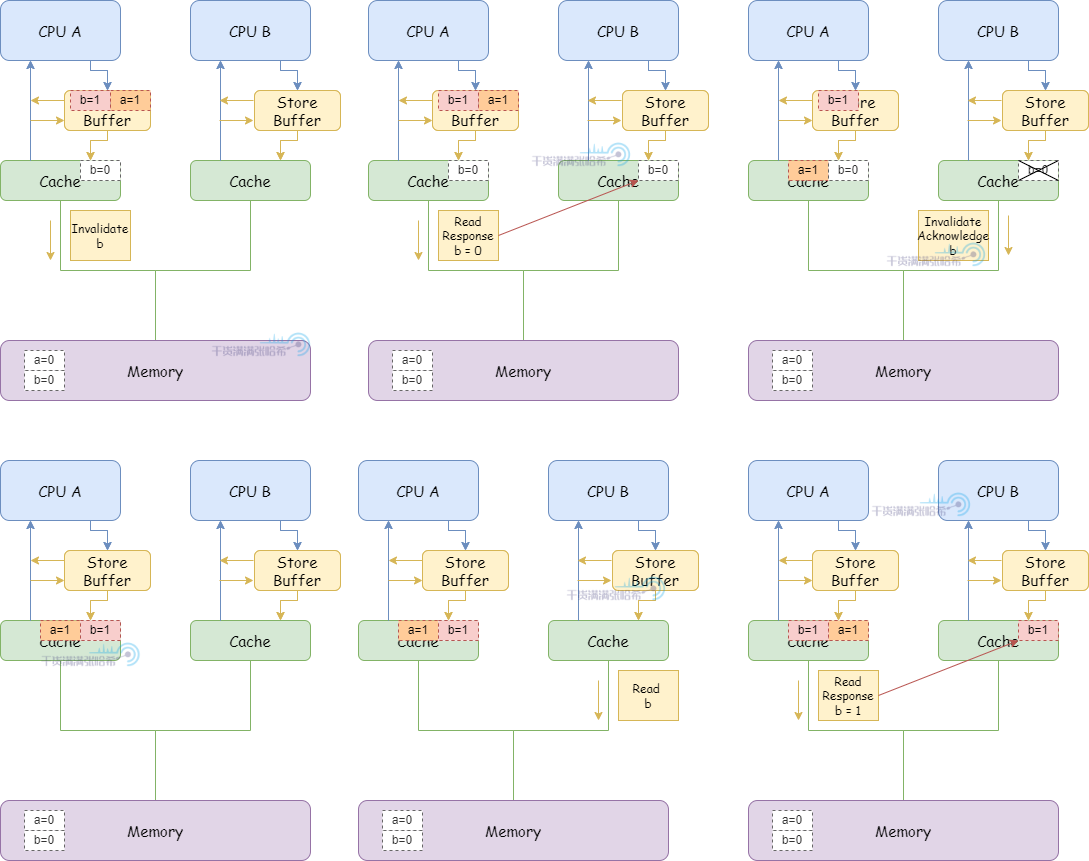
3.CPU B 执行 smp_mb():
(1)CPU B 将当前 Store Buffer 的所有条目打上标记(目前这里只有 a,就是对 a 打上标记)
4.CPU A 执行 b = 1:
(1)CPU A 缓存行里面有 b,并且状态是 Exclusive,但是由于 Store Buffer 中有标记的条目 a,不直接更新缓存行,而是放入 Store Buffer(与 a 不同,没有标记)。并发出 Invalidate 消息。
(2)之后,CPU A 收到了来自于 CPU B 的关于 b 的 Read 消息。
(3)CPU A 响应缓存中的 b = 0,发送 Read Response 消息,并且缓存行状态修改为 Shared
(4)CPU B 收到 Read Response 消息,将 b 放入缓存
(5)CPU B 代码不断循环,因为 CPU B 看到 b 还是 0
(6)CPU A 收到前面对于 a 的 “Read Invalidate” 相关的消息响应,将 Store Buffer 中打好标记的 a 条目刷入缓存,这个缓存行状态为 modified。
(7)CPU B 收到 CPU A 发的 Invalidate b 的消息,将 b 的缓存行失效,回复 Invalidate Acknowledge
(8)CPU A 收到 Invalidate Acknowledge ,将 b 从 Store Buffer 刷入缓存。
(9)由于 CPU B 不断读取 b,但是 b 已经不在缓存中了,所以发送 Read 消息。
(10)CPU A 收到 CPU B 的 Read 消息,设置 b 的缓存行状态为 shared,返回缓存中 b = 1 的 Read Response
(11)CPU B 收到 Read Response ,得知 b = 1,放入缓存行,状态为 shared
5.CPU B 得知 b = 1,退出 while (b == 0) continue 循环
6.CPU B 执行 assert(a == 1)(这个比较简单,就不画图了):
(1)CPU B 缓存中没有 a,发出 Read 消息。
(2)CPU A 从缓存中读取 a = 1,响应 Read Response
(3)CPU B 执行 assert(a == 1) 成功
Store Buffer 一般都会比较小,如果 Store Buffer 满了,那么还是会发生 Stall 的问题。我们期望 Store Buffer 能比较快的刷入 CPU 缓存,这是在收到对应的 Invalidate Acknowledge 之后进行的。但是,其他的 CPU 可能在忙,没发很快应对收到的 Invalidate 消息并响应 Invalidate Acknowledge ,这样可能造成 Store Buffer 满了导致 CPU Stall 的发生。所以,可以引入每个 CPU 的 Invalidate queue 来缓存要处理的 Invalidate 消息。
5.2.5. 简易 CPU 模型 - 解耦 CPU 的 Invalidate 与 Store Buffer - Invalidate Queues
加入 Invalidate Queues 之后,CPU 结构如下所示:
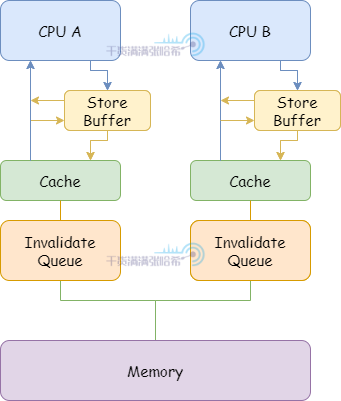
有了 Invalidate Queue,CPU 可以将 Invalidate 放入这个队列之后立刻将 Store Buffer 中的对应数据刷入 CPU 缓存。同时,CPU 在想主动发某个缓存行的 Invalidate 消息之前,必须检查自己的 Invalidate Queue 中是否有相同的缓存行的 Invalidate 消息。如果有,必须等处理完自己的 Invalidate Queue 中的对应消息再发。
同样的,Invalidate Queue 也带来了乱序执行。
5.2.6. 简易 CPU 模型 - 由于 Invalidate Queues 带来的进一步乱序 - 需要内存屏障
假设有两个变量 a 和 b,不会处于同一个缓存行,初始都是 0。假设 CPU A (缓存行里面包含 a(shared), b(Exclusive))执行:

CPU B(缓存行里面包含 a(shared))执行:

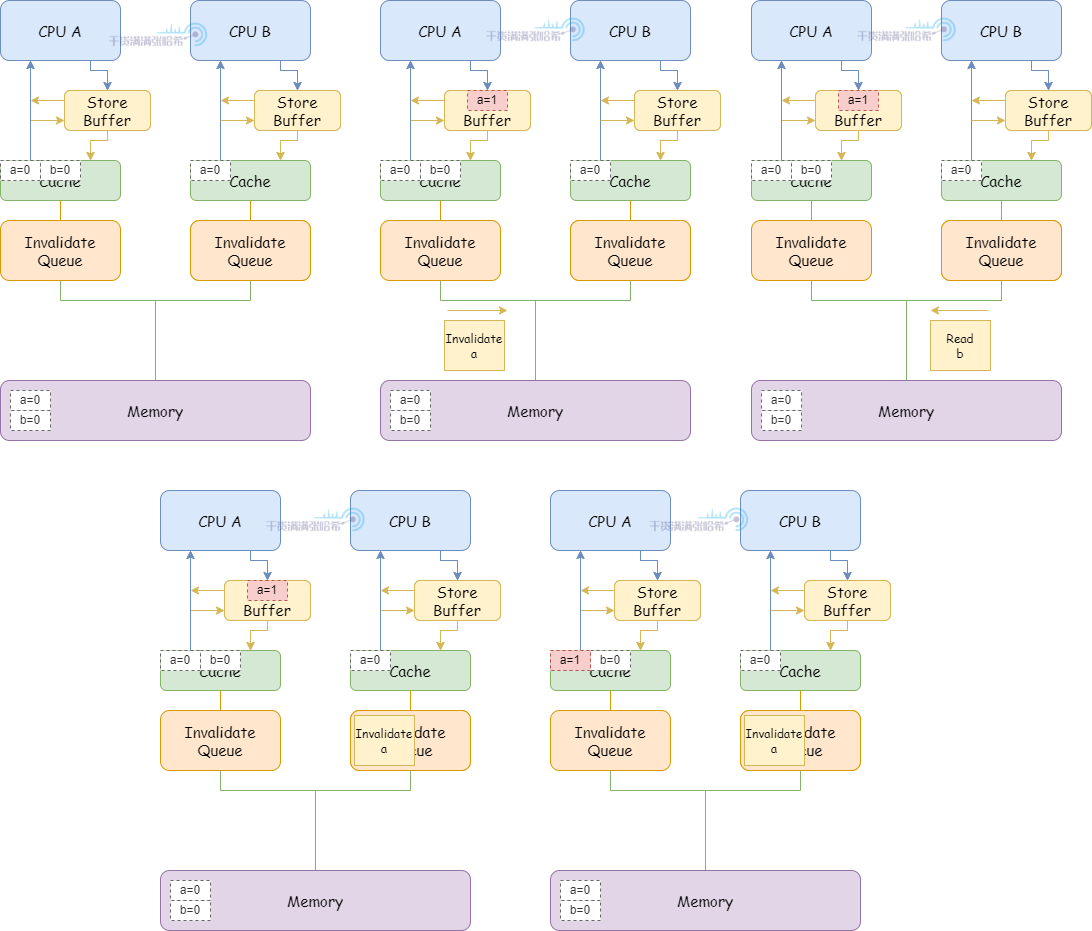
1.CPU A 执行 a = 1:
(1)CPU A 缓存里面有 a(shared),CPU A 将 a 的修改(a=1)放入 Store Buffer,发送 Invalidate 消息。
2.CPU B 执行 while (b == 0) continue:
(1)CPU B 缓存里面没有 b,发布 Read 消息。
(2)CPU B 收到 CPU A 的 Invalidate 消息,放入 Invalidate Queue 之后立刻返回。
(3)CPU A 收到 Invalidate 消息的响应,将 Store Buffer 中的缓存行刷入 CPU 缓存
3.CPU A 执行 smp_mb():
(1)因为 CPU A 已经把 Store Buffer 中的缓存行刷入 CPU 缓存,所以这里直接通过
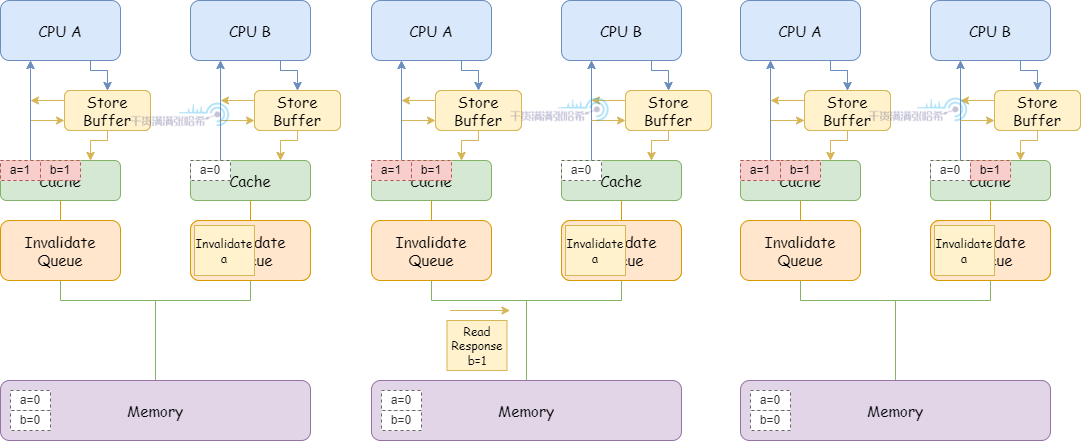
4.CPU A 执行 b = 1:
(1)因为 CPU A 本身包含 b 的缓存行 (Exclusive),直接更新缓存行即可。
(2)CPU A 收到 CPU B 之前发的 Read 消息,将 b 的缓存行状态更新为 Shared,之后发送 Read Response 包含 b 的最新值
(3)CPU B 收到 Read Response , b 的值为 1
5.CPU B 退出循环,开始执行 assert(a == 1)
(1)由于目前关于 a 的 Invalidate 消息还在 Invalidate queue 中没有处理,所以 CPU B 看到的还是 a = 0,assert 失败
所以,我们针对这种乱序,在 CPU B 执行的代码中也加入内存屏障,这里内存屏障不仅等待 CPU 刷完所有的 Store Buffer,还要等待 CPU 的 Invalidate Queue 全部处理完。加入内存屏障,CPU B 执行的代码是:

这样,在前面的第 5 步,CPU B 退出循环,执行 assert(a == 1) 之前需要等待 Invalidate queue 处理完:
(1)处理 Invalidate 消息,将 b 置为 Invalid
(2)继续代码,执行 assert(a == 1),这时候缓存内不存在 b,需要发 Read 消息,这样就能看到 b 的最新值 1 了,assert 成功。
5.2.7. 简易 CPU 模型 - 更细粒度的内存屏障
我们前面提到,在我们前面提到的 CPU 模型中,smp_mb() 这个内存屏障指令,做了两件事:等待 CPU 刷完所有的 Store Buffer,等待 CPU 的 Invalidate Queue 全部处理完。但是,对于我们这里 CPU A 与 CPU B 执行的代码中的内存屏障,并不是每次都要这两个操作同时存在:
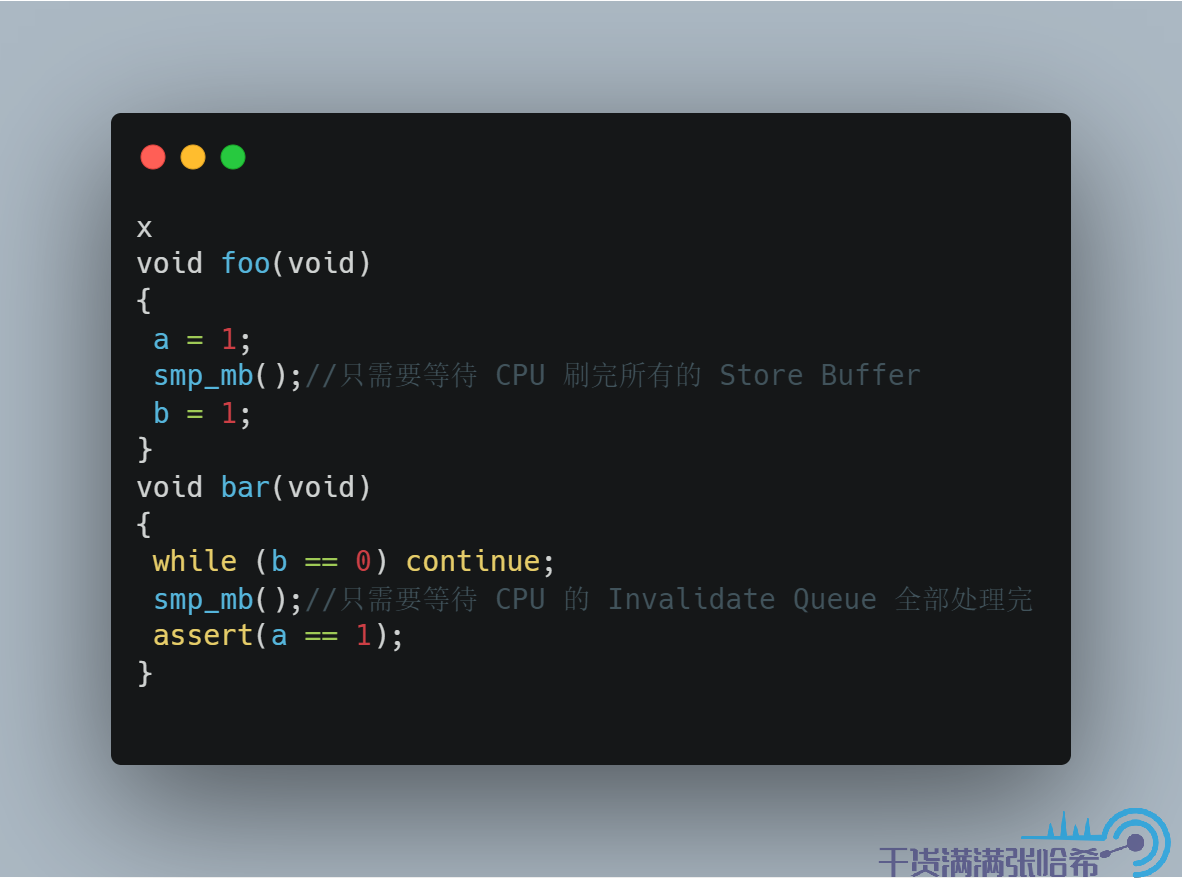
所以,一般 CPU 还会抽象出更细粒度的内存屏障指令,我们这里管等待 CPU 刷完所有的 Store Buffer 的指令叫做 写内存屏障 (Write Memory Buffer),等待 CPU 的 Invalidate Queue 全部处理完的指令叫做 读内存屏障 (Read Memory Buffer)。
5.2.8. 简易 CPU 模型 - 总结
我们这里通过一个简单的 CPU 架构出发,层层递进,讲述了一些简易的 CPU 结构以及为何会需要内存屏障,可以总结为下面这个简单思路流程图:
- CPU 每次直接访问内存太慢,会让 CPU 一直处于 Stall 等待。 为了减少 CPU Stall,加入了 CPU 缓存 。
- CPU 缓存带来了多 CPU 间的缓存不一致性,所以 通过 MESI 这种简易的 CPU 缓存一致性协议协调不同 CPU 之间的缓存一致性
- 对于 MESI 协议中的一些机制进行优化,进一步减少 CPU Stall:
- 通过将更新放入 Store Buffer,让更新发出的 Invalidate 消息不用 CPU Stall 等待 Invalidate Response。
- Store Buffer 带来了指令(代码)乱序,需要内存屏障指令,强制当前 CPU Stall 等待刷完所有 Store Buffer 中的内容。这个内存屏障指令一般称为写屏障。
- 为了加快 Store Buffer 刷入缓存,增加 Invalidate Queue,
5.3. CPU 指令乱序相关
CPU 指令的执行,也可能会乱序,我们这里只说一种比较常见的 - 指令并行化。
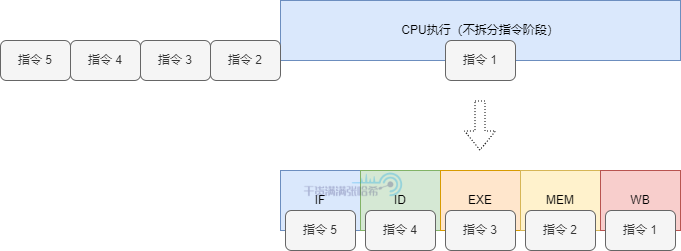
5.3.1. 增加 CPU 执行效率 - CPU 流水线模式(CPU Pipeline)
现代 CPU 在执行指令时,是以指令流水线的模式来运行的。因为 CPU 内部也有不同的组件,我们可以将执行一条指令分成不同阶段,不同的阶段涉及的组件不同,这样伪解耦可以让每个组件独立的执行,不用等待一个指令完全执行完再处理下一个指令。
一般分为如下几个阶段: 取指 (Instrcution Fetch,IF)、 译码 (Instruction Decode,ID)、 执行 (Execute,EXE)、 存取 (Memory,MEM)、 写回 (Write-Back, WB)
5.3.2. 进一步降低 CPU Stall - CPU 乱序流水线(Out of order execution Pipeline)
由于指令的数据是否就绪也是不确定的,比如下面这个例子:

倘若数据 a 没有就绪,还没有载入到寄存器,那么我们其实没必要 Stall 等待加载 a,可以先执行 c = 1; 由此,我们可以将程序中,可以并行的指令提取出来同时安排执行,CPU 乱序流水线(Out of order execution Pipeline)就是基于这种思路:
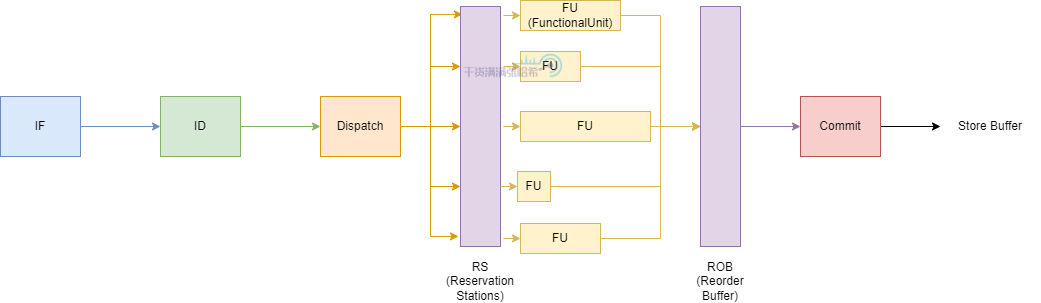
如图所示,CPU 的执行阶段分为:
- Instructions Fetch:批量拉取一批指令,进行指令分析,分析其中的循环以及依赖,分支预测等等
- Instruction Decode:指令译码,与前面的流水线模式大同小异
- Reservation stations:需要操作数输入的指令,如果输入就绪,就进入 Functoinal Unit (FU) 处理,如果没有没有就绪就监听 Bypass network,数据就绪发回信号到 Reservation stations,让指令进图 FU 处理。
- Functional Unit:处理指令
- Reorder Buffer:会将指令按照原有程序的顺序保存,这些指令会在被 dispatched 后添加到列表的一端,而当他们完成执行后,从列表的另一端移除。通过这种方式,指令会按他们 dispatch 的顺序完成。
这样的结构设计下,可以保证写入 Store Buffer 的顺序,与原始的指令顺序一样。但是加载数据,以及计算,是并行执行的。前面我们已经知道了在我们的简易 CPU 架构里面,有着多 CPU 缓存 MESI, Store Buffer 以及 Invalidate Queue 导致读取不到最新的值,这里的乱序并行加载以及处理更加剧了这一点。并且,结构设计下,仅能保证检测出同一个线程下的指令之间的互相依赖,保证这样的互相依赖之间的指令执行顺序是对的,但是多线程程序之间的指令依赖,CPU 批量取指令以及分支预测是无法感知的。 所以还是会有乱序。这种乱序,同样可以通过前面的内存屏障避免 。
5.4. 实际的 CPU
实际的 CPU 多种多样,有着不同的 CPU 结构设计以及不同的 CPU 缓存一致性协议,就会有 不同种类的乱序 ,如果每种单独来看,就太复杂了。所以,大家通过一种标准来抽象描述不同的 CPU 的乱序现象(即第一个操作为 M,第二个操作为 N,这两个操作是否会乱序,是不是很像 Doug Lea 对于 JMM 的描述,其实 Java 内存模型也是参考这个设计的),参考下面这个表格:
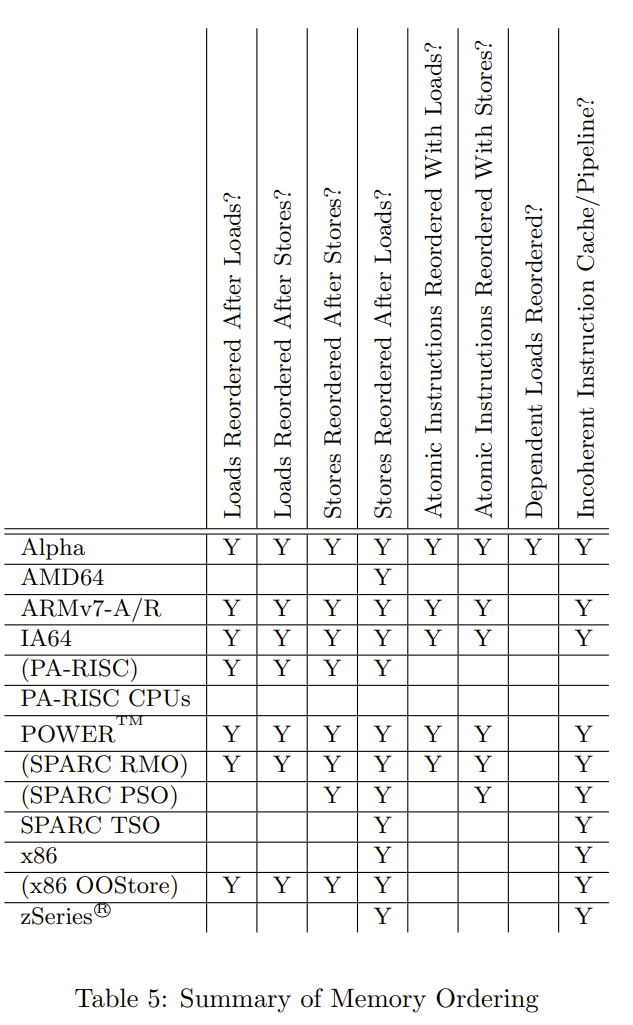
我们先来说一下每一列的意思:
- Loads Reordered After Loads:第一个操作是读取,第二个也是读取,是否会乱序。
- Loads Reordered After Stores:第一个操作是读取,第二个是写入,是否会乱序。
- Stores Reordered After Stores:第一个操作是写入,第二个也是写入,是否会乱序。
- Stores Reordered After Loads:第一个操作是写入,第二个是读取,是否会乱序。
- Atomic Instructions Reordered With Loads:两个操作是原子操作(一组操作,同时发生,例如同时修改两个字这种指令)与读取,这两个互相是否会乱序。
- Atomic Instructions Reordered With Stores:两个操作是原子操作(一组操作,同时发生,例如同时修改两个字这种指令)与写入,这两个互相是否会乱序。
- Dependent Loads Reordered:如果一个读取依赖另一个读取的结果,是否会乱序。
- Incoherent Instruction Cache/Pipeline:是否会有指令乱序执行。
举一个例子来看即我们自己的 PC 上面常用的 x86 结构,在这种结构下,仅仅会发生 Stores Reordered After Loads 以及 Incoherent Instruction Cache/Pipeline。其实后面要提到的 LoadLoad,LoadStore,StoreLoad,StoreStore 这四个 Java 中的内存屏障,为啥在 x86 的环境下其实只需要实现 StoreLoad,其实就是这个原因。
5.5. 编译器乱序
除了 CPU 乱序以外,在软件层面还有编译器优化重排序导致的,其实编译器优化的一些思路与上面说的 CPU 的指令流水线优化其实有些类似。比如编译器也会分析你的代码,对相互不依赖的语句进行优化。对于相互没有依赖的语句,就可以随意的进行重排了。但是同样的,编译器也是只能从单线程的角度去考虑以及分析,并不知道你程序在多线程环境下的依赖以及联系。再举一个简单的例子,假设没有任何 CPU 乱序的环境下,有两个变量 x = 0,y = 0,线程 1 执行:

线程 2 执行:

那么线程 2 是可能 assert 失败的,因为编译器可能会让 x = 1 与 y = 1 之间乱序。
编译器乱序,可以通过增加不同操作系统上的编译器屏障语句进行避免。例如线程一执行:

这样就不会出现 x = 1 与 y = 1 之间乱序的情况。
同时,我们在实际使用的时候,一般内存屏障指的是硬件内存屏障,即通过硬件 CPU 指令实现的内存屏障, 这种硬件内存屏障一般也会隐式地带上编译器屏障 。编译器屏障一般被称为软件内存屏障,仅仅是控制编译器软件层面的屏障,举一个例子即 C++ 中的 volaile,它与 Java 中的 volatile 不一样, C++ 中的 volatile 仅仅是禁止编译器重排即有编译器屏障,但是无法避免 CPU 乱序。
以上,我们就基本搞清楚了乱序的来源,以及内存屏障的作用。接下来,我们即将步入正题,开始我们的 Java 9+ 内存模型之旅。在这之前,再说一件需要注意的事情:为什么最好不要自己写代码验证 JMM 的一些结论,而是使用专业的框架去测试
微信搜索“我的编程喵”关注公众号,加作者微信,每日一刷,轻松提升技术,斩获各种offer :
我会经常发一些很好的各种框架的官方社区的新闻视频资料并加上个人翻译字幕到如下地址(也包括上面的公众号),欢迎关注:
- 知乎:https://www.zhihu.com/people/zhxhash
- B 站:https://space.bilibili.com/31359187

Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
