MySQL索引实现
上一篇我们详细了解了B+树的实现原理(传送门)。我们知道,MySQL内部索引是由不同的引擎实现的,主要包含InnoDB和MyISAM这两种,并且这两种引擎中的索引都是使用b+树的结构来存储的。
InnoDB引擎中的索引
Innodb中有2种索引:主键索引(也叫聚集索引)、辅助索引(也叫非聚集索引)。
主键索引: 每个表只有一个主键索引,b+树结构,叶子节点存储主键的值以及对应整条记录的数据,非叶子节点不存储记录的数据,只存储主键的值。
当表中未指定主键时,MySQL内部会自动给每条记录添加一个隐藏的rowid字段(默认4个字节)作为主键,用rowid构建聚集索引。聚集索引在MySQL中即主键索引。
辅助索引: 每个表可以有多个辅助索引,b+树结构,非聚集索引叶子节点存储字段(索引字段)的值以及对应记录主键的值,其他节点只存储字段的值(索引字段),这就是与聚集索引不同的地方。每个表可以有多个非聚集索引。
MySQL中非聚集索引进一步区分:
| 非聚集索引类型 | 说明 |
|---|---|
| 单列索引 | 一个索引只包含一个列 |
| 多列索引(复合索引) | 一个索引包含多个列 |
| 唯一索引 | 索引列的值必须唯一,允许有一个空值 |
MyISAM引擎中的索引
也是B+树结构,MyISM使用的是非聚簇索引,如下图,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,
辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。
由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
下图更形象说明这两种索引的区别,这边假设了一个存储4行数据的表。Id为主键索引,Name作为辅助索引,图中清晰的体现了聚簇索引和非聚簇索引的差异。

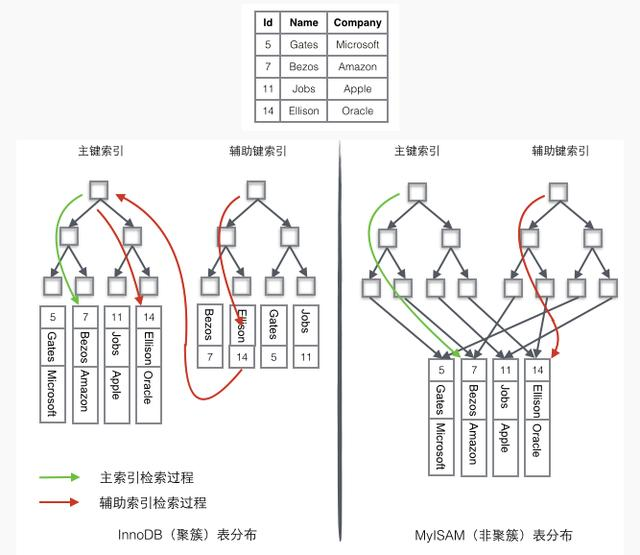

我们来分析一下图中数据检索过程:
InnoDB数据检索过程
上面的表中有2个索引:id作为主键索引,name作为辅助索引。
如果需要查询id=14的数据,只需要在左边的主键索引中检索就可以了。
如果需要搜索name='Ellison'的数据,需要2步:
1、先在辅助索引中检索到name='Ellison'的数据,获取id为14
2、再到主键索引中检索id为14的记录
辅助索引这个查询过程在mysql中叫做回表,相对于主键索引多了第二步操作。
MyISAM数据检索过程
1、在索引中找到对应的关键字,获取关键字对应的记录的地址
2、通过记录的地址查找到对应的数据记录
对比发现:innodb中最好是采用主键查询,这样只需要一次索引,如果使用辅助索引检索,涉及多一步的回表操作,比主键查询要耗时一些。
而innodb中辅助索引区别于myisam的是:
表中的数据发生变更的时候,会影响其他记录地址的变化,如果辅助索引中记录数据的地址,此时会受影响,而主键的值一般是很少更新的,当页中的记录发生地址变更的时候,对辅助索引是没有影响的。
索引管理和使用
数据准备
请参考第21篇(MySQL全面瓦解21(番外):一次深夜优化亿级数据分页的奇妙经历)中模拟的千万数据,我们以这个数据为测试数据。
创建索引
create 方式:
1 create [unique] index index_name on t_name(c_name[(length)]);
alter表 方式:
1 alter t_name add [unique] index index_name on (cname[(length)]);
这边需注意的是:
index_name 代表索引名称、t_name代表 表名称、c_name代表字段名称。
[] 中括号的内容是可以省略的,也就是说 unique 和 length 可以不写。如果加上了unique,表示创建唯一索引。
如果字段是char、varchar类型,length可以小于字段实际长度,如果是blog、text等长文本类型,必须指定length。
如果tname后面只写一个字段,就是单列索引,如果需要写多个字段,可以使用逗号隔开,这种叫做复合索引。
删除索引
1 drop index index_name on t_name;
查看索引
1 show index from t_name;
索引修改
即先删除索引,再重建索引:drop +create。
示例
emp表中有500W数据 我们用emp来做测试
1 mysql> select count(*) from emp;
2 +----------+
3 | count(*) |
4 +----------+
5 | 5000000 |
6 +----------+
7 1 row in set
查看和创建索引
记得我们之前在emp表上做过索引,所以先看一下这个表目前所有的索引
可以看到,目前主键字段id和depno字段上都有建立索引
1 mysql> desc emp;
2 +----------+-----------------------+------+-----+---------+----------------+
3 | Field | Type | Null | Key | Default | Extra |
4 +----------+-----------------------+------+-----+---------+----------------+
5 | id | int(10) unsigned | NO | PRI | NULL | auto_increment |
6 | empno | mediumint(8) unsigned | NO | | 0 | |
7 | empname | varchar(20) | NO | | | |
8 | job | varchar(9) | NO | | | |
9 | mgr | mediumint(8) unsigned | NO | | 0 | |
10 | hiredate | datetime | NO | | NULL | |
11 | sal | decimal(7,2) | NO | | NULL | |
12 | comn | decimal(7,2) | NO | | NULL | |
13 | depno | mediumint(8) unsigned | NO | MUL | 0 | |
14 +----------+-----------------------+------+-----+---------+----------------+
15 9 rows in set
16
17 mysql> show index from emp;
18 +-------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
19 | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
20 +-------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
21 | emp | 0 | PRIMARY | 1 | id | A | 4952492 | NULL | NULL | | BTREE | | |
22 | emp | 1 | idx_emp_id | 1 | id | A | 4952492 | NULL | NULL | | BTREE | | |
23 | emp | 1 | idx_emp_depno | 1 | depno | A | 18 | NULL | NULL | | BTREE | | |
24 +-------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
25 3 rows in set
我们在没有做索引的字段上做一下查询看看,在500W数据中查询一个名叫LsHfFJA的员工,消耗 2.239S
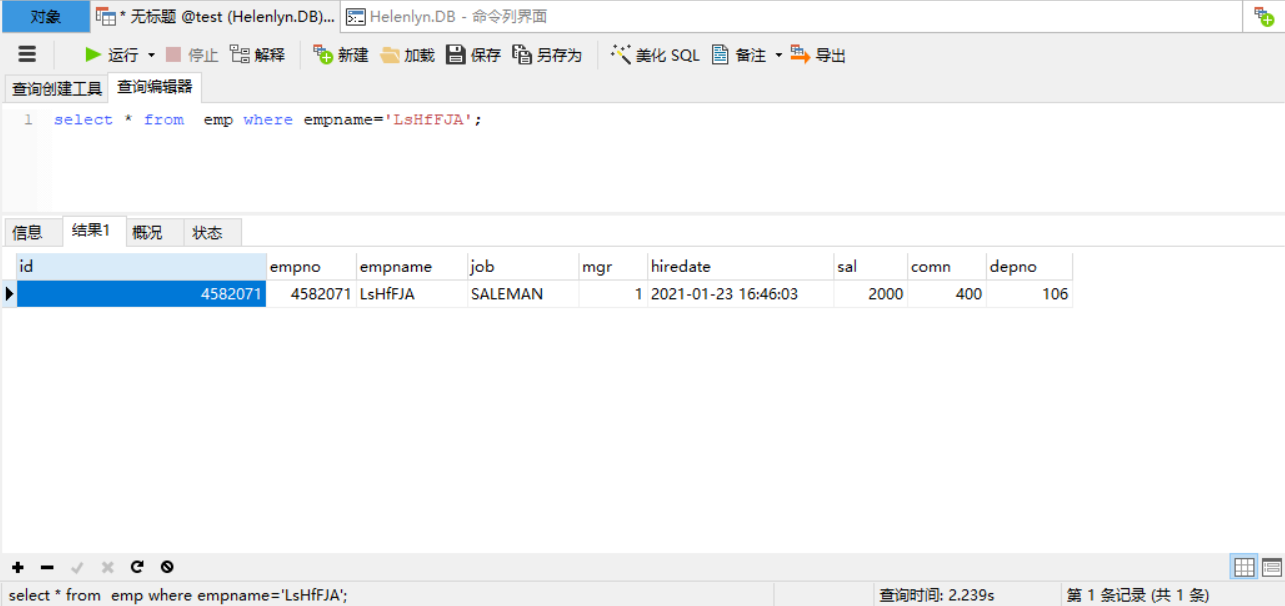
再看看他的执行过程,扫描了4952492 条数据才找到该行数据:
1 mysql> explain select * from emp where empname='LsHfFJA';
2 +----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
3 | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
4 +----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
5 | 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 4952492 | Using where |
6 +----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
7 1 row in set
我们在empname这个字段上建立索引
1 mysql> create index idx_emp_empname on emp(empname);
2 Query OK, 0 rows affected
3 Records: 0 Duplicates: 0 Warnings: 0
4
5 mysql> show index from emp;
6 +-------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
7 | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
8 +-------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
9 | emp | 0 | PRIMARY | 1 | id | A | 4952492 | NULL | NULL | | BTREE | | |
10 | emp | 1 | idx_emp_id | 1 | id | A | 4952492 | NULL | NULL | | BTREE | | |
11 | emp | 1 | idx_emp_depno | 1 | depno | A | 18 | NULL | NULL | | BTREE | | |
12 | emp | 1 | idx_emp_empname | 1 | empname | A | 1650830 | NULL | NULL | | BTREE | | |
13 +-------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
14 4 rows in set
再看一下这个执行效率,就会发现有质的飞跃:0.001S,就是这么神奇,学过之前那篇的B+ Tree就知道,它不用从头开始扫表核对,而是很小次数的io读取
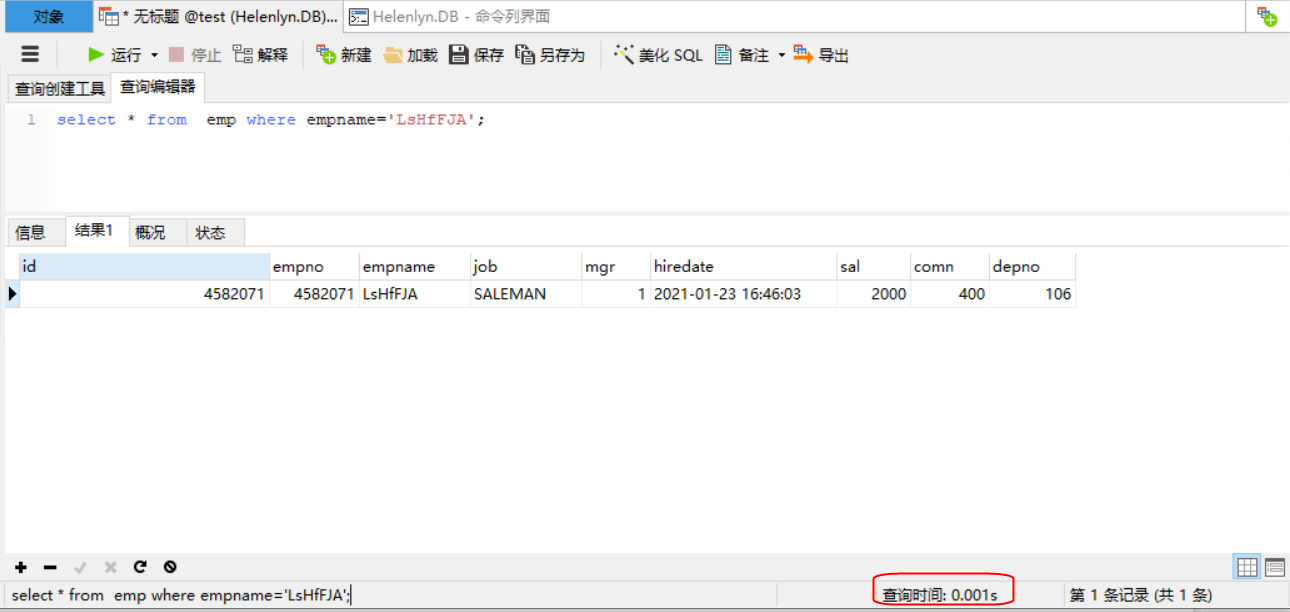
再看看他的执行过程,一次定位到该条数据:
1 mysql> explain select * from emp where empname='LsHfFJA';
2 +----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-----------------------+
3 | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
4 +----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-----------------------+
5 | 1 | SIMPLE | emp | ref | idx_emp_empname | idx_emp_empname | 22 | const | 1 | Using index condition |
6 +----+-------------+-------+------+-----------------+-----------------+---------+-------+------+-----------------------+
7 1 row in set
设置合适的索引长度
根据我们之前的了解,每个磁盘块(disk)存储的内容是有限的,如果一个页中可以存储的索引记录越多,那么查询效率就会提高,所以我们可以指定索引的字段长度。
但并不是越短越好,要保证字符类型字段查询有足够高的区分度,如果只设置了一个长度,反而导致查询的相似匹配度不高。
长度的原则是要恰到好处,太长索引文件就会变大,因此要在区分度和长度上做一个平衡。
如果在我们搜索的内容中,最后的内容是一致的或者高度一致的,那我们就可以省略,比如在用户的email字段上做索引,几乎前10个字符是不一样的,结尾限定在 @****,那么通过前面10个字符就可以定位一个email地址了。
我们在该字段创建索引的时候就可以指定长度为10,这样相对于整个email字段更短些,查询效果确却基本一样,这样一个页中也可以存储更多的索引记录。
像我们上面的那个 empname 字段,基本都是6位数的,只是小部分是超过6位数,而且后缀基本一致,所以6位数之后的区分度差不多。
有一个判断 高区分度以及合适长度索引 的通用算法,如下:
1 select count(distinct left(`c_name`,calcul_len))/count(*) from t_name;
下面是对 empname 做的分析,匹配度越高搜索效率越高:
1 mysql> select count(distinct left(`empname`,3))/count(*) from emp;
2 +--------------------------------------------+
3 | count(distinct left(`empname`,3))/count(*) |
4 +--------------------------------------------+
5 | 0.0012 |
6 +--------------------------------------------+
7 1 row in set
8
9 mysql> select count(distinct left(`empname`,4))/count(*) from emp;
10 +--------------------------------------------+
11 | count(distinct left(`empname`,4))/count(*) |
12 +--------------------------------------------+
13 | 0.0076 |
14 +--------------------------------------------+
15 1 row in set
16
17 mysql> select count(distinct left(`empname`,6))/count(*) from emp;
18 +--------------------------------------------+
19 | count(distinct left(`empname`,6))/count(*) |
20 +--------------------------------------------+
21 | 0.1713 |
22 +--------------------------------------------+
23 1 row in set
24
25 mysql> select count(distinct left(`empname`,7))/count(*) from emp;
26 +--------------------------------------------+
27 | count(distinct left(`empname`,7))/count(*) |
28 +--------------------------------------------+
29 | 0.1713 |
30 +--------------------------------------------+
31 1 row in set
删除索引
1 mysql> drop index idx_emp_empname on emp;
2 Query OK, 0 rows affected
3 Records: 0 Duplicates: 0 Warnings: 0
4
5 mysql> show index from emp;
6 +-------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
7 | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
8 +-------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
9 | emp | 0 | PRIMARY | 1 | id | A | 4952492 | NULL | NULL | | BTREE | | |
10 | emp | 1 | idx_emp_id | 1 | id | A | 4952492 | NULL | NULL | | BTREE | | |
11 | emp | 1 | idx_emp_depno | 1 | depno | A | 18 | NULL | NULL | | BTREE | | |
12 +-------+------------+---------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
13 3 rows in set
执行完删除命令再查看,发现索引已经没了
小结
本文只是理解索引的基本用法,后面会认真讲一讲索引的性能分析和优化策略。
总之,理想的索引应该符合以下特征:
1、相对低频的写操作,以及高频的查询的表和字段上建立索引
2、字段区分度高
3、长度小(合适的长度,不是越小越好)
4、尽量能够覆盖常用字段
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
