Broker接受到Follower发送过来的Fetch请求后,会由Broker的Kafka API层处理,然后由各个Leader分区进行处理:
// KafkaApis.scala
class KafkaApis(val requestChannel: RequestChannel,
val replicaManager: ReplicaManager,
val adminManager: AdminManager,
val coordinator: GroupCoordinator,
val controller: KafkaController,
val zkUtils: ZkUtils,
val brokerId: Int,
val config: KafkaConfig,
val metadataCache: MetadataCache,
val metrics: Metrics,
val authorizer: Option[Authorizer],
val quotas: QuotaManagers,
val clusterId: String,
time: Time) extends Logging {
def handle(request: RequestChannel.Request) {
try {
ApiKeys.forId(request.requestId) match {
case ApiKeys.PRODUCE => handleProducerRequest(request)
// 处理Fetch请求
case ApiKeys.FETCH => handleFetchRequest(request)
//...
}
//...
}
本章,我们就来看看Leader分区对Fetch请求的处理流程,包括:
- Leader分区从本地磁盘读取指定offset之后数据的流程;
- Leader分区的HW和LEO更新机制;
- Leader分区对ISR列表的维护机制;
- Leader分区采用时间轮机制延迟执行Fetch。
一、消息读取
我们来看下KafkaApis的 handleFetchRequest 方法,消息读取的本质最终还是调用了ReplicaManager.fetchMessages():
// KafkaApis.scala
def handleFetchRequest(request: RequestChannel.Request) {
//...
if (authorizedRequestInfo.isEmpty)
sendResponseCallback(Seq.empty)
else {
// call the replica manager to fetch messages from the local replica
replicaManager.fetchMessages(
fetchRequest.maxWait.toLong,
fetchRequest.replicaId,
fetchRequest.minBytes,
fetchRequest.maxBytes,
versionId <= 2,
authorizedRequestInfo,
replicationQuota(fetchRequest),
sendResponseCallback)
}
}
整个流程可以用下面这张图概述:
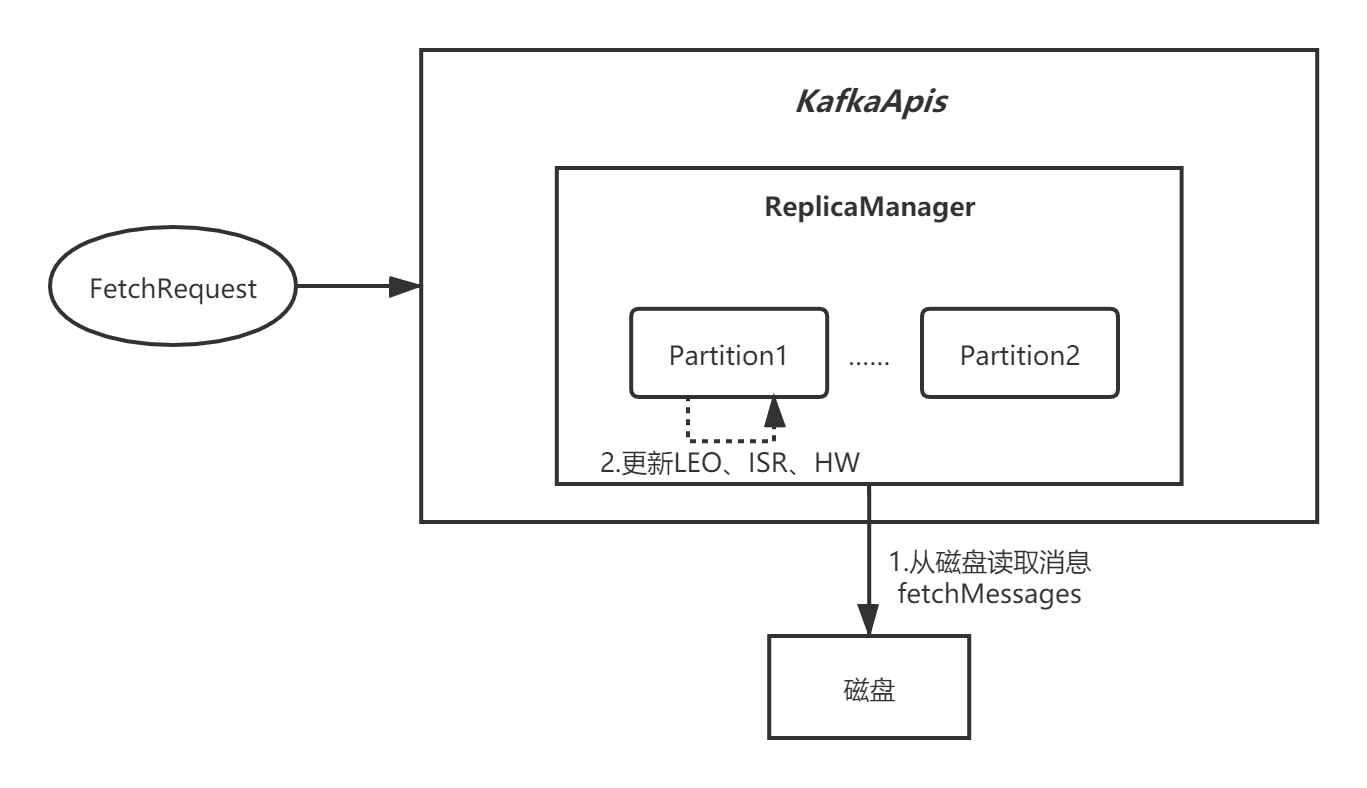
1.1 LogSegment
ReplicaManager.fetchMessages()读取消息的流程我不赘述了,顺着源码一层层往下读就是了。我在日志子系统中已经讲过,日志最终由LogSegment进行读写,所以最关键的是下面的代码:
// LogSement.scala
def read(startOffset: Long, maxOffset: Option[Long], maxSize: Int, maxPosition: Long = size,
minOneMessage: Boolean = false): FetchDataInfo = {
if (maxSize < 0)
throw new IllegalArgumentException("Invalid max size for log read (%d)".format(maxSize))
val logSize = log.sizeInBytes // this may change, need to save a consistent copy
// 关键是这个translateOffset方法,根据稀疏索引,定位要读的消息的起始物理位置
val startOffsetAndSize = translateOffset(startOffset)
// if the start position is already off the end of the log, return null
if (startOffsetAndSize == null)
return null
val startPosition = startOffsetAndSize.position.toInt
val offsetMetadata = new LogOffsetMetadata(startOffset, this.baseOffset, startPosition)
val adjustedMaxSize =
if (minOneMessage) math.max(maxSize, startOffsetAndSize.size)
else maxSize
// return a log segment but with zero size in the case below
if (adjustedMaxSize == 0)
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY)
// calculate the length of the message set to read based on whether or not they gave us a maxOffset
val length = maxOffset match {
case None =>
// no max offset, just read until the max position
min((maxPosition - startPosition).toInt, adjustedMaxSize)
case Some(offset) =>
if (offset < startOffset)
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY, firstEntryIncomplete = false)
val mapping = translateOffset(offset, startPosition)
val endPosition =
if (mapping == null)
logSize // the max offset is off the end of the log, use the end of the file
else
mapping.position
min(min(maxPosition, endPosition) - startPosition, adjustedMaxSize).toInt
}
FetchDataInfo(offsetMetadata, log.read(startPosition, length),
firstEntryIncomplete = adjustedMaxSize < startOffsetAndSize.size)
}
LogSegment.translateOffset()方法就是根据二分查找算法去稀疏索引里找数据的物理位置:
// LogSegment.scala
private[log] def translateOffset(offset: Long, startingFilePosition: Int = 0): LogEntryPosition = {
val mapping = index.lookup(offset)
log.searchForOffsetWithSize(offset, max(mapping.position, startingFilePosition))
}
位移索引OffsetIndex中的lookup方法:
// OffsetIndex.scala
def lookup(targetOffset: Long): OffsetPosition = {
maybeLock(lock) {
val idx = mmap.duplicate
val slot = indexSlotFor(idx, targetOffset, IndexSearchType.KEY)
if(slot == -1)
OffsetPosition(baseOffset, 0)
else
parseEntry(idx, slot).asInstanceOf[OffsetPosition]
}
}
1.2 响应
读取完消息后,最终还是由KafkaApis将响应发送到RequestChannel的responseQueue中,然后调用回调函数将结果响应给发送者:
// KafkaApis.scala
def fetchResponseCallback(delayTimeMs: Int) {
trace(s"Sending fetch response to client $clientId of " +
s"${convertedPartitionData.map { case (_, v) => v.records.sizeInBytes }.sum} bytes")
val fetchResponse = if (delayTimeMs > 0) new FetchResponse(versionId, fetchedPartitionData, delayTimeMs) else response
// 将响应交给RequestChannel处理
requestChannel.sendResponse(new RequestChannel.Response(request, fetchResponse))
}
二、维护LEO
每次Follower发送一个Fetch请求时,都会带上自己的LEO,所以Leader分区会在本地维护所有Follower的LEO。然后,Leader会判断各个Follower的LEO是否都超出了当前的HW了,如果是的话,就把自己的HW向后推移,推移了Leader HW之后,就可以返回最新的HW给Follower,进一步推动Follower的HW发送变化。
我们来看具体的代码实现,就是在ReplicaManager的fetchMessages方法中:
// ReplicaManager.scala
def fetchMessages(timeout: Long,
replicaId: Int,
fetchMinBytes: Int,
fetchMaxBytes: Int,
hardMaxBytesLimit: Boolean,
fetchInfos: Seq[(TopicPartition, PartitionData)],
quota: ReplicaQuota = UnboundedQuota,
responseCallback: Seq[(TopicPartition, FetchPartitionData)] => Unit) {
val isFromFollower = replicaId >= 0
val fetchOnlyFromLeader: Boolean = replicaId != Request.DebuggingConsumerId
val fetchOnlyCommitted: Boolean = !Request.isValidBrokerId(replicaId)
// 读取消息
val logReadResults = readFromLocalLog(
replicaId = replicaId,
fetchOnlyFromLeader = fetchOnlyFromLeader,
readOnlyCommitted = fetchOnlyCommitted,
fetchMaxBytes = fetchMaxBytes,
hardMaxBytesLimit = hardMaxBytesLimit,
readPartitionInfo = fetchInfos,
quota = quota)
// 关键是这里,更新本地维护的各个Follower的LEO
if (Request.isValidBrokerId(replicaId))
updateFollowerLogReadResults(replicaId, logReadResults)
}
private def updateFollowerLogReadResults(replicaId: Int, readResults: Seq[(TopicPartition, LogReadResult)]) {
readResults.foreach { case (topicPartition, readResult) =>
getPartition(topicPartition) match {
case Some(partition) =>
// 更新各个分区的LEO
partition.updateReplicaLogReadResult(replicaId, readResult)
tryCompleteDelayedProduce(new TopicPartitionOperationKey(topicPartition))
case None =>
warn("While recording the replica LEO, the partition %s hasn't been created.".format(topicPartition))
}
}
}
可以看到最终是调用了Partition的updateReplicaLogReadResult方法:
// Partition.scala
def updateReplicaLogReadResult(replicaId: Int, logReadResult: LogReadResult) {
getReplica(replicaId) match {
case Some(replica) =>
// 更新副本的LEO
replica.updateLogReadResult(logReadResult)
// 判断是否要伸缩ISR
maybeExpandIsr(replicaId, logReadResult)
case None =>
//...
}
}
层层调用......所以说,讲源码系列的专栏真是的很难写......最终又调用了Replica.updateLogReadResult()`:
// Replica.scala
def updateLogReadResult(logReadResult : LogReadResult) {
// 更新LEO
if (logReadResult.info.fetchOffsetMetadata.messageOffset >= logReadResult.leaderLogEndOffset)
_lastCaughtUpTimeMs = math.max(_lastCaughtUpTimeMs, logReadResult.fetchTimeMs)
else if (logReadResult.info.fetchOffsetMetadata.messageOffset >= lastFetchLeaderLogEndOffset)
_lastCaughtUpTimeMs = math.max(_lastCaughtUpTimeMs, lastFetchTimeMs)
logEndOffset = logReadResult.info.fetchOffsetMetadata
lastFetchLeaderLogEndOffset = logReadResult.leaderLogEndOffset
lastFetchTimeMs = logReadResult.fetchTimeMs
}
三、维护ISR和HW
ReplicaManager启动后会创建两个定时调度任务,用来维护ISR列表:
// ReplicaManager.scala
def startup() {
// 周期检测ISR列表,默认5s
scheduler.schedule("isr-expiration", maybeShrinkIsr, period = config.replicaLagTimeMaxMs / 2, unit = TimeUnit.MILLISECONDS)
scheduler.schedule("isr-change-propagation", maybePropagateIsrChanges, period = 2500L, unit = TimeUnit.MILLISECONDS)
}
关键来看第一个maybeShrinkIsr任务,内部调用了Partition的maybeShrinkIsr方法:
private def maybeShrinkIsr(): Unit = {
trace("Evaluating ISR list of partitions to see which replicas can be removed from the ISR")
allPartitions.values.foreach(partition => partition.maybeShrinkIsr(config.replicaLagTimeMaxMs))
}
3.1 踢出ISR
我们先来看什么情况下副本会被踢出ISR列表,Partition.maybeShrinkIsr方法的代码如下,一般有两种情况会导致副本失效,从ISR剔除 :
- Follower 副本进程卡住,在一段时间内根本没有向 Leader 副本发起同步请求,比如频繁的 Full GC ;
- Follower 副本进程同步过慢,在一段时间内(默认10s)都无法追赶上 Leader 副本,比如I/O开销过大。
// Partition.scala
def maybeShrinkIsr(replicaMaxLagTimeMs: Long) {
val leaderHWIncremented = inWriteLock(leaderIsrUpdateLock) {
leaderReplicaIfLocal match {
case Some(leaderReplica) =>
// OSR列表
val outOfSyncReplicas = getOutOfSyncReplicas(leaderReplica, replicaMaxLagTimeMs)
if(outOfSyncReplicas.nonEmpty) {
// 新ISR列表
val newInSyncReplicas = inSyncReplicas -- outOfSyncReplicas
assert(newInSyncReplicas.nonEmpty)
// update ISR in zk and in cache
updateIsr(newInSyncReplicas)
// we may need to increment high watermark since ISR could be down to 1
replicaManager.isrShrinkRate.mark()
// 更新HW
maybeIncrementLeaderHW(leaderReplica)
} else {
false
}
case None => false // do nothing if no longer leader
}
}
// some delayed operations may be unblocked after HW changed
if (leaderHWIncremented)
tryCompleteDelayedRequests()
}
// 获取OSR列表
def getOutOfSyncReplicas(leaderReplica: Replica, maxLagMs: Long): Set[Replica] = {
val candidateReplicas = inSyncReplicas - leaderReplica
// 过滤落后的副本
val laggingReplicas = candidateReplicas.filter(r => (time.milliseconds - r.lastCaughtUpTimeMs) > maxLagMs)
if (laggingReplicas.nonEmpty)
debug("Lagging replicas for partition %s are %s".format(topicPartition, laggingReplicas.map(_.brokerId).mkString(",")))
laggingReplicas
}
3.2 加入ISR
再来看Follower重新加入ISR的情况,核心就是 判断副本的LEO是否大于Leader的HW ,大于的话就重新加入:
// // Partition.scala
def maybeExpandIsr(replicaId: Int, logReadResult: LogReadResult) {
val leaderHWIncremented = inWriteLock(leaderIsrUpdateLock) {
// check if this replica needs to be added to the ISR
leaderReplicaIfLocal match {
case Some(leaderReplica) =>
val replica = getReplica(replicaId).get
val leaderHW = leaderReplica.highWatermark
if(!inSyncReplicas.contains(replica) &&
assignedReplicas.map(_.brokerId).contains(replicaId) &&
// 核心就是这里的判断,副本的LEO是否大于Leader的HW
replica.logEndOffset.offsetDiff(leaderHW) >= 0) {
val newInSyncReplicas = inSyncReplicas + replica
updateIsr(newInSyncReplicas)
replicaManager.isrExpandRate.mark()
}
// 增加Leader的HW
maybeIncrementLeaderHW(leaderReplica, logReadResult.fetchTimeMs)
case None => false // nothing to do if no longer leader
}
}
// some delayed operations may be unblocked after HW changed
if (leaderHWIncremented)
tryCompleteDelayedRequests()
}
3.3 维护HW
如果ISR列表发生变化或任何一个Follower的LEO发生变化,那么Leader的HW也可能随之变化,算法很简单,就是取ISR中的所有副本的LEO的最小值:
// Partition.scala
private def maybeIncrementLeaderHW(leaderReplica: Replica, curTime: Long = time.milliseconds): Boolean = {
// 获取ISR中所有副本的LEO
val allLogEndOffsets = assignedReplicas.filter { replica =>
curTime - replica.lastCaughtUpTimeMs <= replicaManager.config.replicaLagTimeMaxMs || inSyncReplicas.contains(replica)
}.map(_.logEndOffset)
// 取各个副本的LEO最小值作为HW
val newHighWatermark = allLogEndOffsets.min(new LogOffsetMetadata.OffsetOrdering)
val oldHighWatermark = leaderReplica.highWatermark
if (oldHighWatermark.messageOffset < newHighWatermark.messageOffset || oldHighWatermark.onOlderSegment(newHighWatermark)) {
leaderReplica.highWatermark = newHighWatermark
true
} else {
false
}
}
五、总结
本章,我对Leader侧的副本同步的整体流程进行了讲解,主要涉及以下几个核心要点:
- Leader侧的消息读取流程;
- Leader侧的LEO和HW维护;
- Leader侧的ISR列表维护;
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
