从本章开始,我将讲解Kafka Broker的副本子系统(Replication Subsystem)。在 Kafka 中,副本是最重要的概念之一,副本机制是 Kafka 实现高可用的基础。Kafka会将同一个分区的多个副本分散在不同的 Broker 机器上,其中的某个副本会被指定为 Leader,负责响应客户端的读写请求,其它副本自动成为 Follower,向Leader副本发送读取请求,同步最新写入的数据。
那么接下来的几章,我就针对Kafka副本子系统的副本同步功能进行讲解,主要包括以下内容:
- Follower副本从Leader拉取数据的全流程;
- Leader副本的LEO和HW更新机制;
- ISR列表的更新机制。
本章,我先来讲解Kafka的Partition副本同步的整体流程,站在Follower的角度,整个流程可以用下面这张图表示:
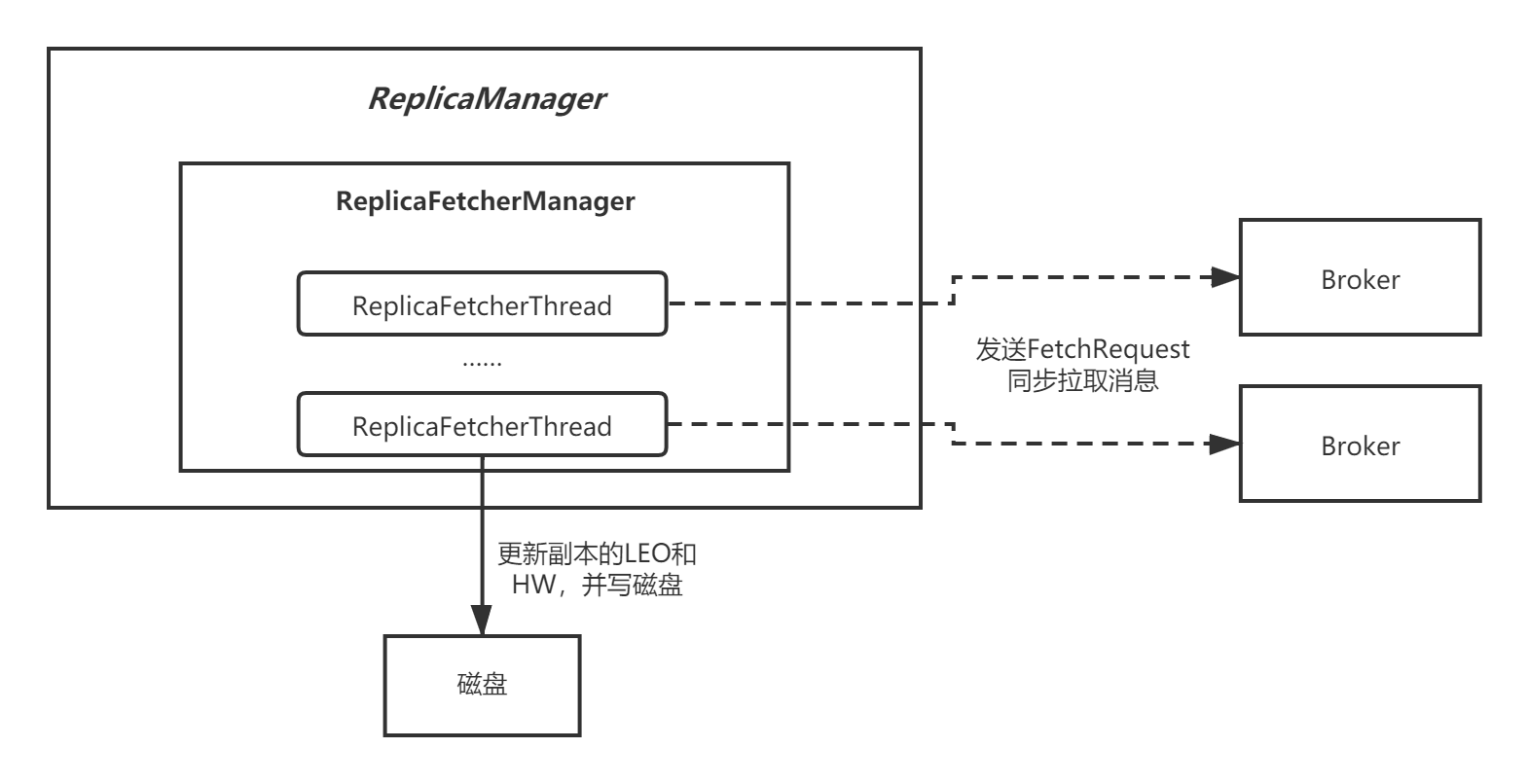
一、副本同步
在正式讲解副本的同步机制之前,我们先来回顾下Kafka中的HW、LEO、AR、ISR、OSR这几个概念:
- AR: 分区中的所有副本统称为 AR ;
- ISR: 与 Leader 副本保持同步状态的副本集合,Leader 副本本身也是ISR中的一员;
- OSR: 当 ISR 集合中的Follower副本滞后Leader副本的时间超过
replica.lag.time.max.ms参数值后,会被判定为同步失败,则将此 follower 副本剔除出 ISR 集合,加入到OSR; - LEO: 标识每个分区中最后一条消息的下一个位置,分区的每个副本都有自己的 LEO;
- HW: ISR 中最小的 LEO 即为 HW ,俗称高水位,消费者只能拉取到 HW 之前的消息。
1.1 ReplicaFetcherManager
每个Broker启动后,会创建 ReplicaManager ,而ReplicaManager在实例化过程中,内部会创建一个名为 ReplicaFetcherManager 的对象:
// ReplicaManager.scala
class ReplicaManager(val config: KafkaConfig,
metrics: Metrics,
time: Time,
val zkUtils: ZkUtils,
scheduler: Scheduler,
val logManager: LogManager,
val isShuttingDown: AtomicBoolean,
quotaManager: ReplicationQuotaManager,
threadNamePrefix: Option[String] = None) extends Logging with KafkaMetricsGroup {
val replicaFetcherManager = new ReplicaFetcherManager(config, this, metrics, time, threadNamePrefix,
quotaManager)
//...
}
ReplicaFetcherManager本身非常简单,它是 AbstractFetcherManager 的子类,可以创建 副本同步线程 ,向Leader分区所在的Broker拉取数据进行同步:
// ReplicaFetcherManager.scala
class ReplicaFetcherManager(brokerConfig: KafkaConfig, replicaMgr: ReplicaManager, metrics: Metrics, time: Time, threadNamePrefix: Option[String] = None, quotaManager: ReplicationQuotaManager)
extends AbstractFetcherManager("ReplicaFetcherManager on broker " + brokerConfig.brokerId,
"Replica", brokerConfig.numReplicaFetchers) {
override def createFetcherThread(fetcherId: Int, sourceBroker: BrokerEndPoint): AbstractFetcherThread = {
val threadName = threadNamePrefix match {
case None =>
"ReplicaFetcherThread-%d-%d".format(fetcherId, sourceBroker.id)
case Some(p) =>
"%s:ReplicaFetcherThread-%d-%d".format(p, fetcherId, sourceBroker.id)
}
// 创建副本同步线程
new ReplicaFetcherThread(threadName, fetcherId, sourceBroker, brokerConfig,
replicaMgr, metrics, time, quotaManager)
}
//...
}
我们重点关注下ReplicaFetcherManager的父类AbstractFetcherManager,它的内部保存了一个fetcherThreadMap,以Borker为维度。什么意思呢?
就是说,ReplicaFetcherManager最终会遍历当前Broker上的所有Follower分区,把那些Leader分区在同一个Broker节点上的Follower分区归为一类,并为它们创建一个ReplicaFetcherThread线程。这样一来,一个ReplicaFetcherThread线程就负责为一批Follower分区向同一个Broker节点同步消息,节省了网络开销:
abstract class AbstractFetcherManager(protected val name: String, clientId: String, numFetchers: Int = 1)
extends Logging with KafkaMetricsGroup {
// fetcher线程集合
private val fetcherThreadMap = new mutable.HashMap[BrokerAndFetcherId, AbstractFetcherThread]
// 为Leader分区在同一个Broker上的所有Follower分区创建一个fetcher线程
def addFetcherForPartitions(partitionAndOffsets: Map[TopicPartition, BrokerAndInitialOffset]) {
mapLock synchronized {
val partitionsPerFetcher = partitionAndOffsets.groupBy { case(topicPartition, brokerAndInitialOffset) =>
BrokerAndFetcherId(brokerAndInitialOffset.broker, getFetcherId(topicPartition.topic, topicPartition.partition))}
for ((brokerAndFetcherId, partitionAndOffsets) <- partitionsPerFetcher) {
var fetcherThread: AbstractFetcherThread = null
fetcherThreadMap.get(brokerAndFetcherId) match {
case Some(f) => fetcherThread = f
case None =>
fetcherThread = createFetcherThread(brokerAndFetcherId.fetcherId, brokerAndFetcherId.broker)
// 按照Broker维度,缓存线程
fetcherThreadMap.put(brokerAndFetcherId, fetcherThread)
// 启动线程
fetcherThread.start
}
fetcherThreadMap(brokerAndFetcherId).addPartitions(partitionAndOffsets.map { case (tp, brokerAndInitOffset) =>
tp -> brokerAndInitOffset.initOffset
})
}
}
}
}
1.2 ReplicaFetcherThread
再来看下ReplicaFetcherThread这个副本同步线程,它继承自AbstractFetcherThread,很多处理流程直接委托给父类完成:
// ReplicaFetcherThread.scala
class ReplicaFetcherThread(name: String,
fetcherId: Int,
sourceBroker: BrokerEndPoint,
brokerConfig: KafkaConfig,
replicaMgr: ReplicaManager,
metrics: Metrics,
time: Time,
quota: ReplicationQuotaManager)
extends AbstractFetcherThread(name = name,
clientId = name,
sourceBroker = sourceBroker,
fetchBackOffMs = brokerConfig.replicaFetchBackoffMs,
isInterruptible = false) {
override def run(): Unit = {
info("Starting ")
try{
while(isRunning.get()){
// 调用父类方法,完成副本数据同步
doWork()
}
} catch{
case e: Throwable =>
if(isRunning.get())
error("Error due to ", e)
}
shutdownLatch.countDown()
info("Stopped ")
}
}
我们重点来看上面的AbstractFetcherThread.doWork()方法,就是创建一个FetchRequest对象,然后向指定的Broker发起请求进行副本数据同步:
// AbstractFetcherThread.scala
abstract class AbstractFetcherThread(
name: String, // 线程名称
clientId: String, // Client Id,用于日志输出
val sourceBroker: BrokerEndPoint, // 数据源Broker地址
failedPartitions: FailedPartitions, // 处理过程中出现失败的分区
fetchBackOffMs: Int = 0, // 获取操作重试间隔
isInterruptible: Boolean = true, // 线程是否允许被中断
val brokerTopicStats: BrokerTopicStats) // Broker端主题监控指标
extends ShutdownableThread(name, isInterruptible) {
// 定义FetchData类型表示获取的消息数据
type FetchData = FetchResponse.PartitionData[Records]
// 定义EpochData类型表示Leader Epoch数据
type EpochData = OffsetsForLeaderEpochRequest.PartitionData
private val partitionStates = new PartitionStates[PartitionFetchState]
//...
override def doWork() {
val fetchRequest = inLock(partitionMapLock) {
// 针对Leader都在同一个Broker上的一批Follower分区,创建一个FetchRequest
val fetchRequest = buildFetchRequest(partitionStates.partitionStates.asScala.map { state =>
state.topicPartition -> state.value
})
// 没有需要同步的分区,等待一段时间
if (fetchRequest.isEmpty) {
partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS)
}
fetchRequest
}
if (!fetchRequest.isEmpty)
// 发送请求进行副本数据同步
processFetchRequest(fetchRequest)
}
}
这里重点看下一个FetchRequest这个请求,我们必须要理解: 一个Broker上有许多Follower分区,这些分区的Leader可能分布同一个Broker上,那么对于同一个Broker的所有Follower分区,只要组装一个FetchRequest请求就可以了 :
// ReplicaFetcherThread.scala
protected def buildFetchRequest(partitionMap: Seq[(TopicPartition, PartitionFetchState)]): FetchRequest = {
val requestMap = new util.LinkedHashMap[TopicPartition, JFetchRequest.PartitionData]
// 遍历分区集合,组装FetchRequest
partitionMap.foreach { case (topicPartition, partitionFetchState) =>
if (partitionFetchState.isActive && !shouldFollowerThrottle(quota, topicPartition))
requestMap.put(topicPartition, new JFetchRequest.PartitionData(partitionFetchState.offset, fetchSize))
}
// 请求的数据包含:拉取的数据大小、最长等待时间、拉取的offset等等
val requestBuilder = new JFetchRequest.Builder(maxWait, minBytes, requestMap).
setReplicaId(replicaId).setMaxBytes(maxBytes)
requestBuilder.setVersion(fetchRequestVersion)
new FetchRequest(requestBuilder)
}
最后,来看下发送请求和对结果处理的操作,本质就是通过底层NetworkClient组件执行请求发送,发送时会带上Follower的LEO,获得响应后会更新自己的LEO和HW:
// AbstractFetcherThread.scala
private def processFetchRequest(fetchRequest: REQ) {
val partitionsWithError = mutable.Set[TopicPartition]()
def updatePartitionsWithError(partition: TopicPartition): Unit = {
partitionsWithError += partition
partitionStates.moveToEnd(partition)
}
var responseData: Seq[(TopicPartition, PD)] = Seq.empty
try {
// 1.执行拉取,底层通过NIO组件NetworkClient完成
responseData = fetch(fetchRequest)
} catch {
//...
}
fetcherStats.requestRate.mark()
// 对响应进行处理
if (responseData.nonEmpty) {
inLock(partitionMapLock) {
responseData.foreach { case (topicPartition, partitionData) =>
val topic = topicPartition.topic
val partitionId = topicPartition.partition
Option(partitionStates.stateValue(topicPartition)).foreach(currentPartitionFetchState =>
if (fetchRequest.offset(topicPartition) == currentPartitionFetchState.offset) {
Errors.forCode(partitionData.errorCode) match {
case Errors.NONE =>
try {
val records = partitionData.toRecords
val newOffset = records.shallowEntries.asScala.lastOption.map(_.nextOffset).getOrElse(
currentPartitionFetchState.offset)
fetcherLagStats.getAndMaybePut(topic, partitionId).lag = Math.max(0L, partitionData.highWatermark - newOffset)
// 处理分区数据
processPartitionData(topicPartition, currentPartitionFetchState.offset, partitionData)
val validBytes = records.validBytes
if (validBytes > 0) {
partitionStates.updateAndMoveToEnd(topicPartition, new PartitionFetchState(newOffset))
fetcherStats.byteRate.mark(validBytes)
}
} catch {
//...
}
//...
}
})
}
}
}
//...
}
// ReplicaFetcherThread.scala
// 处理响应结果
def processPartitionData(topicPartition: TopicPartition, fetchOffset: Long, partitionData: PartitionData) {
try {
val replica = replicaMgr.getReplica(topicPartition).get
val records = partitionData.toRecords
maybeWarnIfOversizedRecords(records, topicPartition)
if (fetchOffset != replica.logEndOffset.messageOffset)
throw new RuntimeException("Offset mismatch for partition %s: fetched offset = %d, log end offset = %d.".format(topicPartition, fetchOffset, replica.logEndOffset.messageOffset))
if (logger.isTraceEnabled)
// 1.将消息写入磁盘
replica.log.get.append(records, assignOffsets = false)
if (logger.isTraceEnabled)
// 2.更新副本的高水位HW
val followerHighWatermark = replica.logEndOffset.messageOffset.min(partitionData.highWatermark)
replica.highWatermark = new LogOffsetMetadata(followerHighWatermark)
//...
} catch {
case e: KafkaStorageException =>
fatal(s"Disk error while replicating data for $topicPartition", e)
Runtime.getRuntime.halt(1)
}
}
二、总结
本章,我站在Follower副本的角度对副本同步的整个流程进行了讲解。重点如下:
- Broker启动后,会在创建多个后台线程—— ReplicaFetcherThread ,负责副本的同步。ReplicaFetcherThread是按照Broker维度创建的,一批Leader分区在同一个Broker上的Follower分区共用一个ReplicaFetcherThread;
- ReplicaFetcherThread拉取消息时,本质还是作为Producer发送请求,走的还是Kafka自定义的一套NIO通信框架;
- Follower拉取到消息后,按照 日志子系统 那套流程完成消息的磁盘写入,并会更新自己的LEO和HW。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
