前言
- 习惯用
Json、XML数据存储格式的你们,相信大多都没听过Protocol Buffer Protocol Buffer其实 是Google出品的一种轻量 & 高效的结构化数据存储格式,性能比Json、XML真的强!太!多!
由于
Protocol Buffer已经具备足够的吸引力
- 今天,我将讲解
Protocol Buffer使用的源码分析,并解决以下两个问题:
a.Protocol Buffer序列化速度 & 反序列化速度为何如此快
b.Protocol Buffer的数据压缩效果为何如此好,即序列化后的数据量体积小
目录
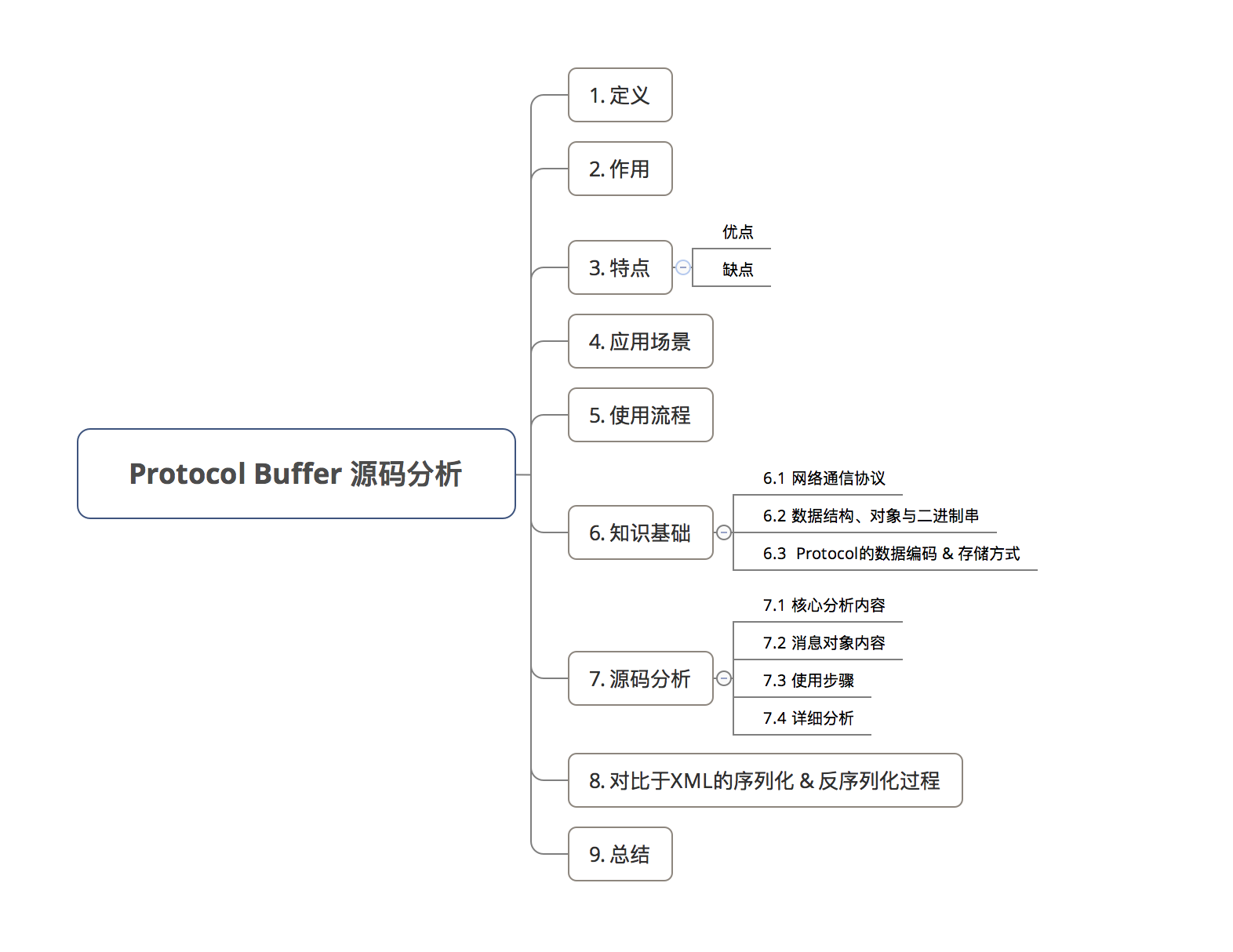
1. 定义
一种 结构化数据 的数据存储格式(类似于 XML、Json )
Protocol Buffer目前有两个版本:proto2和proto3- 因为
proto3还是beta 版,所以本次讲解是proto2
2. 作用
通过将 结构化的数据 进行 串行化( 序列化 ),从而实现 数据存储 / RPC 数据交换 的功能
- 序列化: 将 数据结构或对象 转换成 二进制串 的过程
- 反序列化:将在序列化过程中所生成的二进制串 转换成 数据结构或者对象 的过程
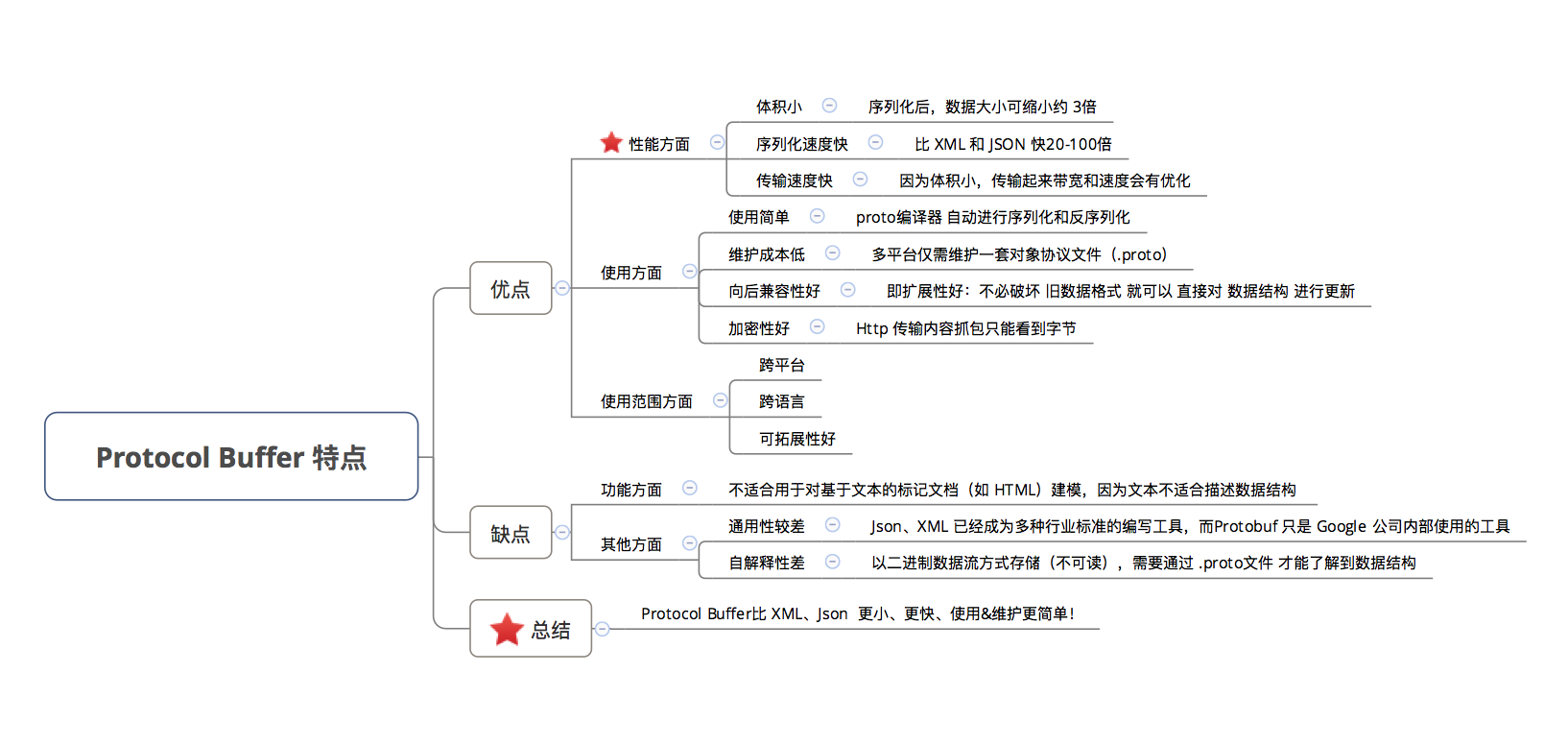
3. 特点
- 对比于 常见的
XML、Json数据存储格式,Protocol Buffer有如下特点:
4. 应用场景
传输数据量大 & 网络环境不稳定 的 数据存储、RPC 数据交换 的需求场景
如 即时IM (QQ、微信)的需求场景
总结
在 传输数据量较大 的需求场景下,Protocol Buffer比XML、Json 更小、更快、使用 & 维护更简单!
5. 使用流程
关于 Protocol Buffer 的使用流程,具体请看我写的文章:快来看看Google出品的Protocol Buffer,别只会用Json和XML了
6. 知识基础
6.1 网络通信协议
- 序列化 & 反序列化 属于通讯协议的一部分
- 通讯协议采用分层模型:
TCP/IP模型(四层) &OSI模型 (七层)
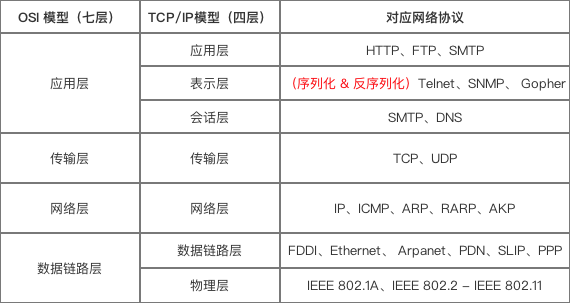
-
序列化 / 反序列化 属于
TCP/IP模型 应用层 和 OSI`模型 展示层的主要功能:- (序列化)把 应用层的对象 转换成 二进制串
- (反序列化)把 二进制串 转换成 应用层的对象
-
所以,
Protocol Buffer属于TCP/IP模型的应用层 &OSI模型的展示层
6.2 数据结构、对象与二进制串
不同的计算机语言中,数据结构,对象以及二进制串的表示方式并不相同。
a. 对于数据结构和对象
- 对于面向对象的语言(如
Java):对象 =Object= 类的实例化;在Java中最接近数据结构 即POJO(Plain Old Java Object),或Javabean(只有setter/getter方法的类) - 对于半面向对象的语言(如
C++),对象 =class,数据结构 =struct
b. 二进制串
- 对于
C++,因为具有内存操作符,所以 二进制串 容易理解:C++的字符串可以直接被传输层使用,因为其本质上就是以'\0'结尾的存储在内存中的二进制串 - 对于
Java,二进制串 = 字节数组 =byte[]
byte属于Java的八种基本数据类型- 二进制串 容易和
String混淆:String一种特殊对象(Object)。对于跨语言间的通讯,序列化后的数据当然不能是某种语言的特殊数据类型。
6.3 Protocol Buffer 的序列化原理 & 数据存储方式
Protocol Buffer的序列化原理主要在于 独特的编码方式 & 数据存储方式- 具体请看文章 Protocol Buffer 序列化原理大揭秘 - 为什么Protocol Buffer性能这么好?
7. 源码分析
7.1 核心分析内容
在下面的源码分析中,主要分析的是:
Protocol Buffer具体是如何进行序列化 & 反序列化 ?- 与
XML、Json相比,Protocol Buffer序列化 & 反序列化速度 为什么如此快 & 序列化后的数据体积这么小?
本文主要讲解
Protocol Buffer在Android平台上的应用,即Java
平台
7.2 实例的消息对象内容
Demo.proto
package protocobuff_Demo;
option java_package = "com.carson.proto";
option java_outer_classname = "Demo";
// 生成 Person 消息对象
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}
再次强调:看源码分析前,请务必先看我写的文章:快来看看Google出品的Protocol Buffer,别只会用Json和XML了
7.3 使用步骤
- 源码分析的路径会依据
Protocol Buffer的使用步骤进行 - 具体使用步骤如下:(看注释)
// 步骤1:通过 消息类的内部类Builder类 构造 消息类的消息构造器
Demo.Person.Builder personBuilder = Demo.Person.newBuilder();
// 步骤2:设置你想要设置的字段为你选择的值
personBuilder.setName("Carson");
personBuilder.setEmail("carson.ho@foxmail.com");
personBuilder.setId(123);
Demo.Person.PhoneNumber.Builder phoneNumber = Demo.Person.PhoneNumber.newBuilder();
phoneNumber.setType( Demo.Person.PhoneType.HOME);
phoneNumber.setNumber("0157-23443276");
// 步骤3:通过 消息构造器 创建 消息类 对象
Demo.Person person = personBuilder.build();
// 步骤4:序列化和反序列化消息(两种方式)
/*方式1:直接 序列化 和 反序列化 消息 */
// a.序列化
byte[] byteArray1 = person.toByteArray();
// 把 person消息类对象 序列化为 byte[]字节数组
System.out.println(Arrays.toString(byteArray1));
// 查看序列化后的字节流
// b.反序列化
try {
Demo.Person person_Request = Demo.Person.parseFrom(byteArray1);
// 当接收到字节数组byte[] 反序列化为 person消息类对象
System.out.println(person_Request.getName());
System.out.println(person_Request.getId());
System.out.println(person_Request.getEmail());
// 输出反序列化后的消息
} catch (IOException e) {
e.printStackTrace();
}
/*方式2:通过输入/ 输出流(如网络输出流) 序列化和反序列化消息 */
// a.序列化
ByteArrayOutputStream output = new ByteArrayOutputStream();
try {
person.writeTo(output);
// 将消息序列化 并写入 输出流(此处用 ByteArrayOutputStream 代替)
} catch (IOException e) {
e.printStackTrace();
}
byte[] byteArray = output.toByteArray();
// 通过 输出流 转化成二进制字节流
// b. 反序列化
ByteArrayInputStream input = new ByteArrayInputStream(byteArray);
// 通过 输入流 接收消息流(此处用 ByteArrayInputStream 代替)
try {
Demo.Person person_Request = Demo.Person.parseFrom(input);
// 通过输入流 反序列化 消息
System.out.println(person_Request.getName());
System.out.println(person_Request.getId());
System.out.println(person_Request.getEmail());
// 输出消息
} catch (IOException e) {
e.printStackTrace();
}
7.4 详细分析
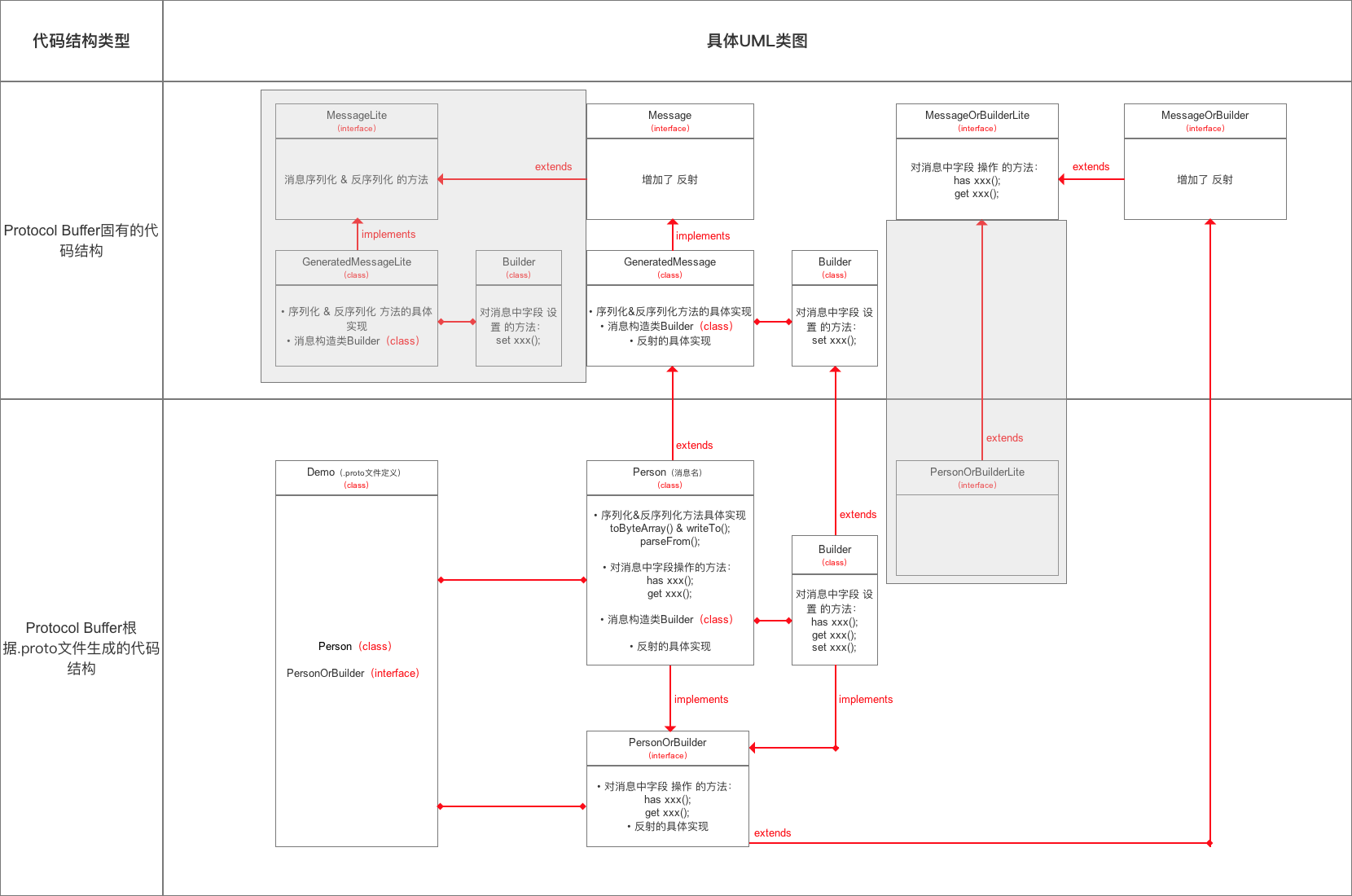
- 详细分析前,先看下
Protocol Buffer的主要类结构:
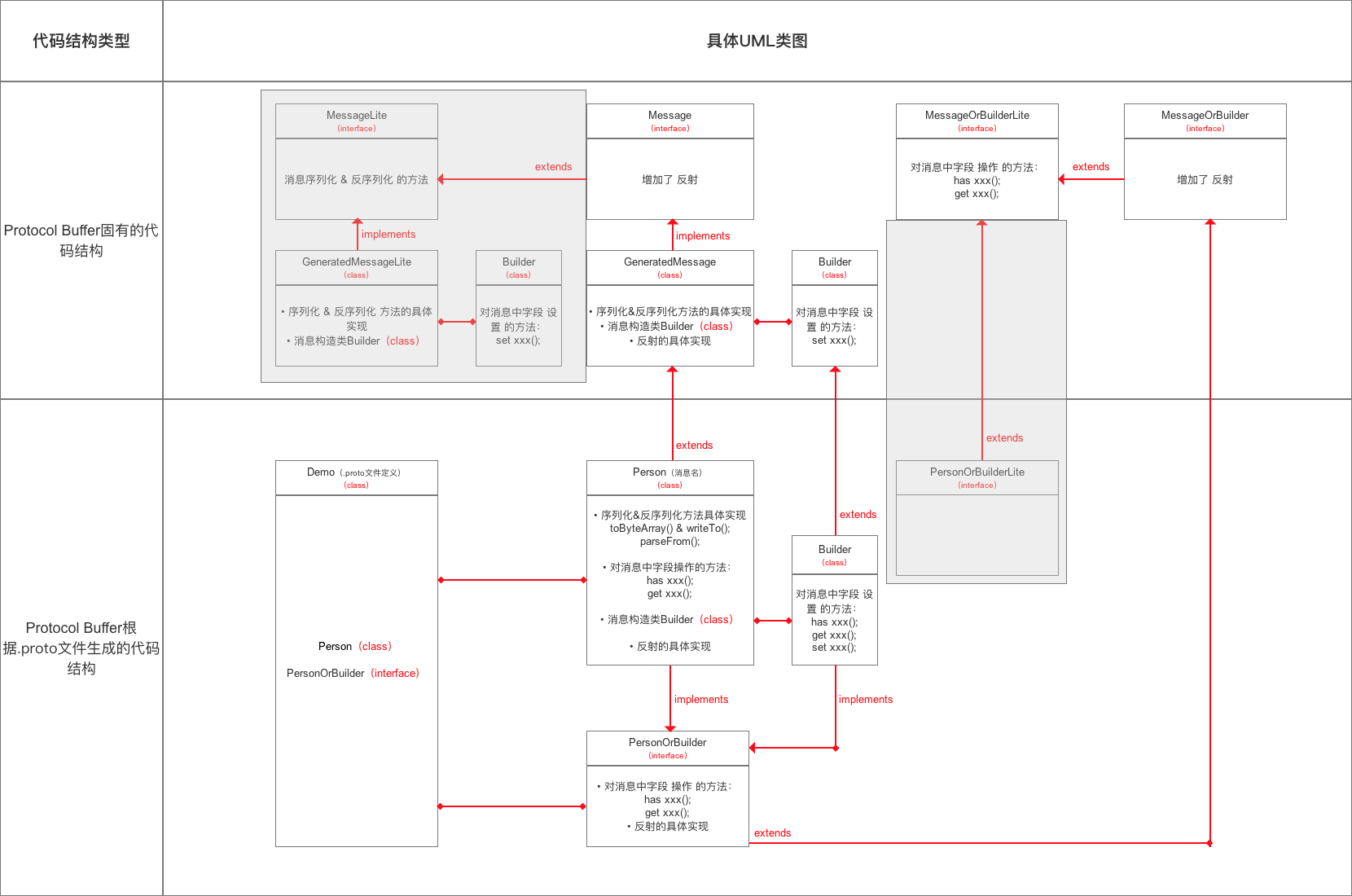
下面先讲解 Protocol Buffer 的固有代码结构
a. MessageLite接口 & Message接口
- 作用:定义了消息 序列化 & 反序列化 的方法
- 二者关系:
MessageLite接口是Message的父接口 - 二者区别:
Message接口中增加了Protocol Buffer对反射(reflection) & 描述符 (descriptor) 功能的支持
- 在其实现类
GeneratedMessage中给予了最小功能的实现Message接口更加灵活 & 具备扩展性;但编码效率低,占用资源高
public interface Message extends MessageLite {
...
// 定义了消息 序列化 & 反序列化 的方法
...
// Builders消息构造器 设置字段的方法
// 下面会详细说明
}
- 设置:
// 通过在.proto文件 添加option选项 选择 MessageLite接口
option optimize_for = LITE_RUNTIME;
// 不设置则默认 使用 Message接口
// 选择标准:一般来说,反射 & 描述符 的功能都不会使用到,所以为了避免占用资源多、试用包大,选择MessageLite接口会更好
// 此处就采用Message接口进行讲解
b. GeneratedMessageLite类 & GeneratedMessage类
- 定义:是
.proto文件生成的所有Java类的父类
分别是
MessageLite接口 &Message接口的实现类
- 作用:定义了 序列化 & 反序列化 的方法的具体实现
- 二者区别:同上
c. MessageOrBuilder 接口 & MessageOrBuilderLite 接口
- 作用:定义了一系列对 消息中字段操作的方法
- 如初始化、错误设置等
- 关于对消息对象中字段的设置、修改等是通过
<消息名>OrBuilder接口 继承该接口进行功能的扩展
- 二者关系:
MessageOrBuilderLite接口是MessageOrBuilder的父接口
public interface MessageOrBuilder extends MessageLiteOrBuilder {
...
// 定义了一系列对 消息中字段操作的方法
// 下面会详细说明
}
下面,我将按照Protocol Buffer的使用步骤逐步进行源码分析,即分析Protocol Buffer根据 .proto文件生成的代码结构
再次贴出
Protocol Buffer的主要类结构:
步骤1:通过 消息类的内部类Builder类 构造 消息类的消息构造器
Demo.Person.Builder personBuilder = Demo.Person.newBuilder();
// Demo类:.proto文件的option java_outer_classname = "Demo";
// Person类:消息对象类
// Builder类:消息构造器类
// 下面会逐一说明
下面我先介绍三个比较重要的类:Demo类、Person类、Builder类。
**a. Demo类 **
Protocol Buffer编译器会为每个.proto文件生成一个Protocol Buffer类
类名 取决于.proto文件的语句
option java_outer_classname = "Demo"
- 类里包含了消息对象类 / 接口 & 消息构造器类
public final class Demo {
// 消息对象类 接口
public interface PersonOrBuilder extends com.google.protobuf.MessageOrBuilder {
...
}
// 消息对象 类
// Protocol Buffer类的内部类
public static final class Person extends
com.google.protobuf.GeneratedMessage implements PersonOrBuilder {
...
// 消息构造器类
// 消息对象类的内部类
public static final class Builder extends
com.google.protobuf.GeneratedMessage.Builder<Builder> implements
com.carson.proto.Demo.PersonOrBuilder {
..
}
}
**b. Person类 **
Protocol Buffer编译器为 每个消息对象 生成一个 消息对象类
类名 = 消息对象 名
- 作用:定义了消息 序列化 & 反序列化的方法 & 消息字段的获取方法
// 消息类被声明为final类,即不可以在被继承(自泪花)
// Google 官方文档中给予了明确的说明:因为子类化将会破坏序列化和反序列化的过程
public static final class Person extends
com.google.protobuf.GeneratedMessage implements PersonOrBuilder {
// 1. 继承自GeneratedMessage类
// 2. 实现了PersonOrBuilder接口 ->>关注1
// Person类的构造方法
private Person(com.google.protobuf.GeneratedMessage.Builder<?> builder) {
super(builder);
this.unknownFields = builder.getUnknownFields();
}
private Person(boolean noInit) { this.unknownFields = com.google.protobuf.UnknownFieldSet.getDefaultInstance(); }
// 特别注意
// 由于Person类里的构造方法都是 私有属性(Private),所以创建实例对象时只能通过内部类Builder类进行创建,而不能独自创建
// 下面会详细说明
...
// 序列化 & 反序列化方法(两种方式)
<-- 方式1:直接序列化和反序列化 消息 -->
public byte[] toByteArray();
// 序列化消息
public Person parseFrom(byte[] data);
// 反序列化
<-- 方式2:通过输入/ 输出流(如网络输出流) 序列化和反序列化消息 -->
public OutputStream writeTo(OutputStream output);
public byte[] toByteArray();
// 序列化消息
public Person parseFrom(InputStream input);
// 反序列化
// 下面会对序列化 & 反序列化进行更加的详细说明
// 获取 消息字段的方法
// 只含包含字段的getters方法
// required string name = 1;
public boolean hasName();// 如果字段被设置,则返回true
public java.lang.String getName();
// required int32 id = 2;
public boolean hasId();
public int getId();
// optional string email = 3;
public boolean hasEmail();
public String getEmail();
// repeated .tutorial.Person.PhoneNumber phone = 4;
// 重复(repeated)字段有一些额外方法
public List<PhoneNumber> getPhoneList();
public int getPhoneCount();
// 列表大小的速记
// 作用:通过索引获取和设置列表的特定元素的getters和setters
}
<-- 关注1:PersonOrBuilder接口 -->
// Protocol Buffer编译器为 每个消息对象 生成一个<消息名>OrBuilder 接口
// 作用:定义了 消息中所有字段的 get方法(用于获取字段值) & has<field>方法(用以判断字段是否设值)
// 使用了设计模式中的建造者模式:通过 对应的Builder接口 完成对 所有消息字段 的修改操作
public interface PersonOrBuilder extends
com.google.protobuf.MessageOrBuilder {
// 继承自 MessageOrBuilder 接口 或 MessageOrBuilderLite 接口
/**
* <code>required string name = 1;</code>
*/
boolean hasName();
java.lang.String getName();
com.google.protobuf.ByteString
getNameBytes();
/**
* <code>required int32 id = 2;</code>
*/
boolean hasId();
int getId();
/**
* <code>optional string email = 3;</code>
*/
boolean hasEmail();
java.lang.String getEmail();
com.google.protobuf.ByteString
getEmailBytes();
/**
* <code>repeated .protocobuff_Demo.Person.PhoneNumber phone = 4;</code>
*/
java.util.List<com.carson.proto.Demo.Person.PhoneNumber>
getPhoneList();
com.carson.proto.Demo.Person.PhoneNumber getPhone(int index);
int getPhoneCount();
java.util.List<? extends com.carson.proto.Demo.Person.PhoneNumberOrBuilder>
getPhoneOrBuilderList();
com.carson.proto.Demo.Person.PhoneNumberOrBuilder getPhoneOrBuilder(
int index);
}
// 由于Person类实现了该接口,所以也能获取消息中的字段值
**c. Builder类 **
Protocol Buffer编译器为 每个消息对象 在消息类内部生成一个 消息构造器类(Builder类)- 作用:定义了 消息中所有字段的
get方法(用于获取字段值) &has<field>方法(用以判断字段是否设值) 和set方法(用于设置字段值)
与 消息类
Person类作用类似,但多了set方法(用于设置字段值)
public static final class Builder extends
com.google.protobuf.GeneratedMessage.Builder<Builder> implements
com.carson.proto.Demo.PersonOrBuilder {
...
// 定义了 消息中所有字段的 `get`方法(用于获取字段值) & `has<field>`方法(用以判断字段是否设值) 和 `set`方法(用于设置字段值)
// 下面会进行更加详细的说明
}
看完Demo类、Person类、Builder类 三个类后,终于可以开始分析
- 具体使用
// 通过 消息类的内部类Builder类 构造 消息类的消息构造器
Demo.Person.Builder personBuilder = Demo.Person.newBuilder();
- 源码分析
public static final class Builder extends
com.google.protobuf.GeneratedMessage.Builder<Builder> implements
com.carson.proto.Demo.PersonOrBuilder {
// 该静态方法是 Builder类 的建造者模式方法
// 通过建造者模式 创建 Builder类 的 实例,即消息构造器的实例
public static Builder newBuilder() {
return Builder.create(); --> 关注1
}
<--Builder.create() -->
private static Builder create() {
return new Builder();
// 创建并返回一个消息构造器的实例
}
}
步骤2:通过 消息构造器设置 消息中字段的值
- 具体使用
// 步骤2:通过 消息构造器设置 消息中字段的值
personBuilder.setName("Carson");// 在定义.proto文件时,该字段的字段修饰符是required,所以必须赋值
personBuilder.setEmail("carson.ho@foxmail.com");// 在定义.proto文件时,该字段的字段修饰符是required,所以必须赋值
personBuilder.setId(123); // 在定义.proto文件时,该字段的字段修饰符是optional,所以可赋值 / 不赋值(不赋值时将使用默认值)
- 源码分析
public static final class Builder extends
com.google.protobuf.GeneratedMessage.Builder<Builder> implements
com.carson.proto.Demo.PersonOrBuilder {
// Builder定义了大量对消息中字段操作的方法
// 1. Builder类中修改消息字段的方法
// 标准的JavaBeans风格:含getters和setters
// required string name = 1;
public boolean hasName();// 如果字段被设置,则返回true
public java.lang.String getName();
public Builder setName(String value);
public Builder clearName(); // 将字段设置回它的空状态
// required int32 id = 2;
public boolean hasId();
public int getId();
public Builder setId(int value);
public Builder clearId();
// optional string email = 3;
public boolean hasEmail();
public String getEmail();
public Builder setEmail(String value);
public Builder clearEmail();
// repeated .tutorial.Person.PhoneNumber phone = 4;
// 重复(repeated)字段有一些额外方法
public List<PhoneNumber> getPhoneList();
public int getPhoneCount();
// 列表大小的速记
// 作用:通过索引获取和设置列表的特定元素的getters和setters
// 用Name字段为例详细分析这一系列方法
// a. 判断是否设置了Name字段值
// 设置了则返回true
/**
* <code>required string Name = 1;</code>
*/
public boolean hasName() {
return ((bitField0_ & 0x00000001) == 0x00000001);
}
// b. 获得字段的值
public java.lang.String getName() {
java.lang.Object ref = number_;
if (!(ref instanceof java.lang.String)) {
com.google.protobuf.ByteString bs =
(com.google.protobuf.ByteString) ref;
java.lang.String s = bs.toStringUtf8();
if (bs.isValidUtf8()) {
number_ = s;
}
return s;
} else {
return (java.lang.String) ref;
}
// c. 设置Number字段
// 该函数调用后hasName函数将返回true
public Builder setName(
java.lang.String value) {
if (value == null) {
throw new NullPointerException();
}
bitField0_ |= 0x00000001;
number_ = value;
onChanged();
return this;
}
// 返回值为Builder对象,这样就可以让调用者在一条代码中方便的连续设置多个字段
// 如:Message.setID(100).setName("MyName");
// 2. 清空当前对象中的所有设置
// 调用该函数后,所有字段的 has*字段名*()都会返回false。
public Builder clear() {
super.clear();
number_ = "";
bitField0_ = (bitField0_ & ~0x00000001);
type_ = com.carson.proto.Demo.Person.PhoneType.HOME;
bitField0_ = (bitField0_ & ~0x00000002);
return this;
}
// 3. 其他可能会用到的方法
// 由于使用频率较低,此处不展开分析,仅作定性分析
public Builder isInitialized()
// 检查所有 required 字段 是否都已经被设置
public Builder toString() :
// 返回一个人类可读的消息表示(用于调试)
public Builder mergeFrom(Message other)
// 将 其他内容 合并到这个消息中,覆写单数的字段,附接重复的。
public Builder clear()
// 清空所有的元素为空状态。
}
步骤3:通过 消息构造器 创建 消息类 对象
- 具体使用
// 通过 消息构造器 创建 消息类 对象
Demo.Person person = personBuilder.build();
- 源码分析
public static final class Builder extends
com.google.protobuf.GeneratedMessage.Builder<Builder> implements
com.carson.proto.Demo.PersonOrBuilder {
public com.carson.proto.Demo.Person build() {
com.carson.proto.Demo.Person result = buildPartial();
// 创建消息类对象 ->>关注1
if (!result.isInitialized()) {
// 判断是否初始化
// 标准是:required字段是否被赋值,如果没有则抛出异常
throw newUninitializedMessageException(result);
}
return result;
}
<-- buildPartial()方法 -->
public com.carson.proto.Demo.Person buildPartial() {
com.carson.proto.Demo.Person result = new com.carson.proto.Demo.Person(this);
// 在消息构造器Builder类里创建消息类的对象
// 下面是对字段的标识号进行判断 & 赋值
int from_bitField0_ = bitField0_;
int to_bitField0_ = 0;
if (((from_bitField0_ & 0x00000001) == 0x00000001)) {
to_bitField0_ |= 0x00000001;
}
result.name_ = name_;
if (((from_bitField0_ & 0x00000002) == 0x00000002)) {
to_bitField0_ |= 0x00000002;
}
result.id_ = id_;
if (((from_bitField0_ & 0x00000004) == 0x00000004)) {
to_bitField0_ |= 0x00000004;
}
result.email_ = email_;
if (phoneBuilder_ == null) {
if (((bitField0_ & 0x00000008) == 0x00000008)) {
phone_ = java.util.Collections.unmodifiableList(phone_);
bitField0_ = (bitField0_ & ~0x00000008);
}
result.phone_ = phone_;
} else {
result.phone_ = phoneBuilder_.build();
}
result.bitField0_ = to_bitField0_;
onBuilt();
return result;
// 最终返回一个已经赋值标识号的消息类对象
}
再次说明:由于消息类Person类里的构造方法都是 私有属性(Private),所以创建实例对象时只能通过内部类Builder类进行创建而不能独自创建。
步骤4:序列化和反序列化消息(两种方式)
- 终于来到
Protocol Buffer的重头戏了:序列化和反序列化消息 - 此处会着重说明序列化 & 反序列化的原理,从而解释为什么
Protocol Buffer的性能如此地好(序列化速度快 & 序列化后数据量小) - 具体使用
// 步骤4:序列化和反序列化消息(两种方式)
/*方式1:直接 序列化 和 反序列化 消息 */
// a.序列化
byte[] byteArray1 = person.toByteArray();
// b.反序列化
Demo.Person person = Demo.Person.parseFrom(byteArray1);
/*方式2:通过输入/ 输出流(如网络输出流) 序列化和反序列化消息 */
// a.序列化
ByteArrayOutputStream output = new ByteArrayOutputStream();
person.writeTo(output);
// 将消息写入 输出流(此处用 ByteArrayOutputStream 代替)
byte[] byteArray = output.toByteArray();
// 通过 输出流 序列化消息
// b. 反序列化
ByteArrayInputStream input = new ByteArrayInputStream(byteArray);
// 通过 输入流 接收消息流(此处用 ByteArrayInputStream 代替)
Demo.Person person_Request = Demo.Person.parseFrom(input);
// 通过输入流 反序列化 消息
下面将分析介绍 两种序列化 & 反序列化方式 的源码分析
- 方式1的源码分析
/*方式1:直接 序列化 和 反序列化 消息 */
// a.序列化(返回一个字节数组)
byte[] byteArray1 = person.toByteArray();
// b.反序列化(从一个字节数据进行反序列化)
Demo.Person person = Demo.Person.parseFrom(byteArray1);
a. 序列化分析:person.toByteArray()
// 仅贴出关键代码
public static final class Person extends
com.google.protobuf.GeneratedMessage implements PersonOrBuilder {
// 直接进行序列化成二进制字节流
public byte[] toByteArray() {
try {
final byte[] result = new byte[getSerializedSize()];
// 创建一个字节数组
final CodedOutputStream output = CodedOutputStream.newInstance(result);
// 创建一个输出流
writeTo(output);
// 将 消息类对象 序列化到输出流里 -->关注1
}
<-- writeTo()分析-->
// 以下便是真正序列化的过程
public void writeTo(com.google.protobuf.CodedOutputStream output)
throws java.io.IOException {
// 计算出序列化后的二进制流长度,分配该长度的空间,以备以后将每个字段填充到该空间
getSerializedSize();
// 判断每个字段是否有设置值
// 有才会进行写操作(编码)
if (((bitField0_ & 0x00000001) == 0x00000001)) {
output.writeBytes(1, getNameBytes()); // ->>关注2
// 根据 字段标识号 将已经赋值的 字段标识号和字段值 通过不同的编码方式进行编码
// 最终写入到输出流
}
if (((bitField0_ & 0x00000002) == 0x00000002)) {
output.writeInt32(2, id_); // ->>关注3
}
if (((bitField0_ & 0x00000004) == 0x00000004)) {
output.writeBytes(3, getEmailBytes());
}
// NumberPhone为嵌套的message
// 通过递归进行里面每个字段的序列化
for (int i = 0; i < phone_.size(); i++) {
output.writeMessage(4, phone_.get(i)); // ->>关注4
}
getUnknownFields().writeTo(output);
}
<-- 关注2:String字段类型的编码方式:LENGTH_DELIMITED-->
public void writeBytes(final int fieldNumber, final ByteString value)
throws IOException {
writeTag(fieldNumber, WireFormat.WIRETYPE_LENGTH_DELIMITED);
// 将字段的标识号和字段类型按照Tag = (field_number << 3) | wire_type组成Tag
writeBytesNoTag(value);
// 对字段值进行编码
}
public void writeBytesNoTag(final ByteString value) throws IOException {
writeRawVarint32(value.size());
// 对于String字段类型的字段长度采用了Varint的编码方式
writeRawBytes(value);
// 对于String字段类型的字段值采用了utf-8的编码方式
}
<-- 关注3:Int32字段类型的编码方式:VARINT-->
public void writeInt32(final int fieldNumber, final int value)
throws IOException {
writeTag(fieldNumber, WireFormat.WIRETYPE_VARINT);
// 将字段的标识号和字段类型按照Tag = (field_number << 3) | wire_type组成Tag
writeInt32NoTag(value);
// 对字段值采用了Varint的编码方式
}
<-- 关注4:Message字段类型的编码方式:LENGTH_DELIMITED-->
public void writeMessage(final int fieldNumber, final MessageLite value)
throws IOException {
writeTag(fieldNumber, WireFormat.WIRETYPE_LENGTH_DELIMITED);
writeMessageNoTag(value);
}
}
-
序列化过程描述:
- 创建一个输出流
- 计算出序列化后的二进制流长度,分配该长度的空间,以备以后将每个字段填充到该空间
- 判断每个字段是否有设置值,有值才会进行编码
若
optional或repeated字段没有被设置字段值,那么该字段在序列化时的数据中是完全不存在的,即不进行序列化(少编码一个字段);在解码时,相应的字段才会被设置为默认值
- 根据 字段标识号&数据类型 将 字段值 通过不同的编码方式进行编码
以下是 不同字段数据类型 对应的编码方式
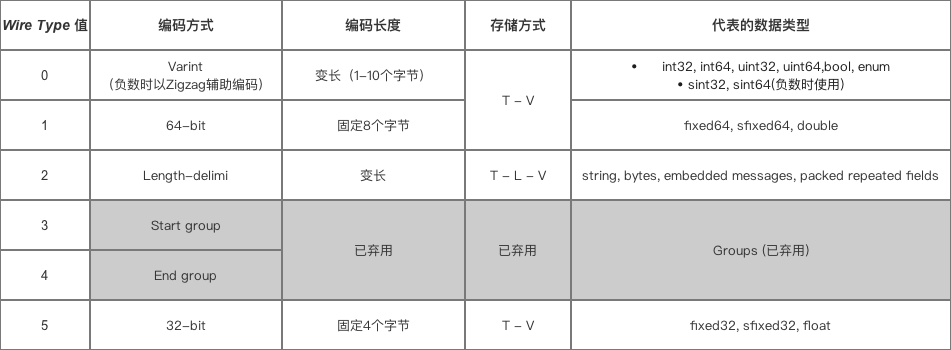
- 将已经编码成功的字节写入到 输出流,即数据存储,最终等待输出
- 从上面可以看出:序列化 主要是经过了 编码 & 数据存储 两个过程
- 关于
Protocol Buffer的序列化原理(编码 & 数据存储方式)详细,请看文章Protocol Buffer 序列化原理大揭秘 - 为什么Protocol Buffer性能这么好?
b. 反序列化Demo.Person person = Demo.Person.parseFrom(byteArray1);
// 仅贴出关键代码
public static final class Person extends
com.google.protobuf.GeneratedMessage implements PersonOrBuilder {
public static com.carson.proto.Demo.Person parseFrom(byte[] data)
throws com.google.protobuf.InvalidProtocolBufferException {
return PARSER.parseFrom(data); // ->>关注1
}
<-- 关注1-->
public MessageType parseFrom(byte[] data)
throws InvalidProtocolBufferException {
return parseFrom(data, EMPTY_REGISTRY);// ->>关注2
}
<-- 关注2-->
public MessageType parseFrom(byte[] data,
ExtensionRegistryLite extensionRegistry)
throws InvalidProtocolBufferException {
return parseFrom(data, 0, data.length, extensionRegistry); // ->>关注3
}
<-- 关注3-->
public MessageType parseFrom(byte[] data, int off, int len,
ExtensionRegistryLite extensionRegistry)
throws InvalidProtocolBufferException {
return checkMessageInitialized(
parsePartialFrom(data, off, len, extensionRegistry));// ->>关注4
}
<-- 关注4 -->
public MessageType parsePartialFrom(byte[] data, int off, int len,
ExtensionRegistryLite extensionRegistry)
throws InvalidProtocolBufferException {
try {
CodedInputStream input = CodedInputStream.newInstance(data, off, len);
// 创建一个输入流
MessageType message = parsePartialFrom(input, extensionRegistry);
// ->>关注5
try {
input.checkLastTagWas(0);
return message;
}
}
<-- 关注5 -->
public Person parsePartialFrom(
com.google.protobuf.CodedInputStream input,
com.google.protobuf.ExtensionRegistryLite extensionRegistry)
throws com.google.protobuf.InvalidProtocolBufferException {
return new Person(input, extensionRegistry);
// 最终创建并返回了一个消息类Person的对象
// 创建时会调用Person 带有该两个参数的构造方法 ->>关注6
}
};
<-- 关注6:调用的构造方法 -->
// 作用:反序列化消息
private Person(
com.google.protobuf.CodedInputStream input,
com.google.protobuf.ExtensionRegistryLite extensionRegistry)
throws com.google.protobuf.InvalidProtocolBufferException {
initFields();
int mutable_bitField0_ = 0;
com.google.protobuf.UnknownFieldSet.Builder unknownFields =
com.google.protobuf.UnknownFieldSet.newBuilder();
try {
boolean done = false;
while (!done) {
int tag = input.readTag();
// 通过While循环 从 输入流 依次读tag值
// 根据从tag值解析出来的标识号,通过case分支读取对应字段类型的数据并通过反编码对字段进行解析 & 赋值
// 字段越多,case分支越多
switch (tag) {
case 0:
done = true;
break;
default: {
if (!parseUnknownField(input, unknownFields,
extensionRegistry, tag)) {
done = true;
}
break;
}
case 10: {
com.google.protobuf.ByteString bs = input.readBytes();
bitField0_ |= 0x00000001;
name_ = bs;
break;
}
case 16: {
bitField0_ |= 0x00000002;
id_ = input.readInt32();
break;
}
case 26: {
com.google.protobuf.ByteString bs = input.readBytes();
bitField0_ |= 0x00000004;
email_ = bs;
break;
}
case 34: {
if (!((mutable_bitField0_ & 0x00000008) == 0x00000008)) {
phone_ = new java.util.ArrayList<com.carson.proto.Demo.Person.PhoneNumber>();
mutable_bitField0_ |= 0x00000008;
}
phone_.add(input.readMessage(com.carson.proto.Demo.Person.PhoneNumber.PARSER, extensionRegistry));
break;
}
}
}
// 最终是返回了一个 消息类 对象
- 关于
Protocol Buffer的反序列化原理(编码 & 数据存储方式)详细,请看文章Protocol Buffer 序列化原理大揭秘 - 为什么Protocol Buffer性能这么好?
总结
反序列化的过程总结如下:
- 从 输入流 依次读 字段的标签值(即
Tag值) - 根据从标签值(即
Tag值)值解析出来的标识号(Field_Number),判断对应的数据类型(wire_type) - 调用对应的解码方法 解析 对应字段值
下图用实例来看看 Protocol Buffer 如何解析经过Varint 编码的字节
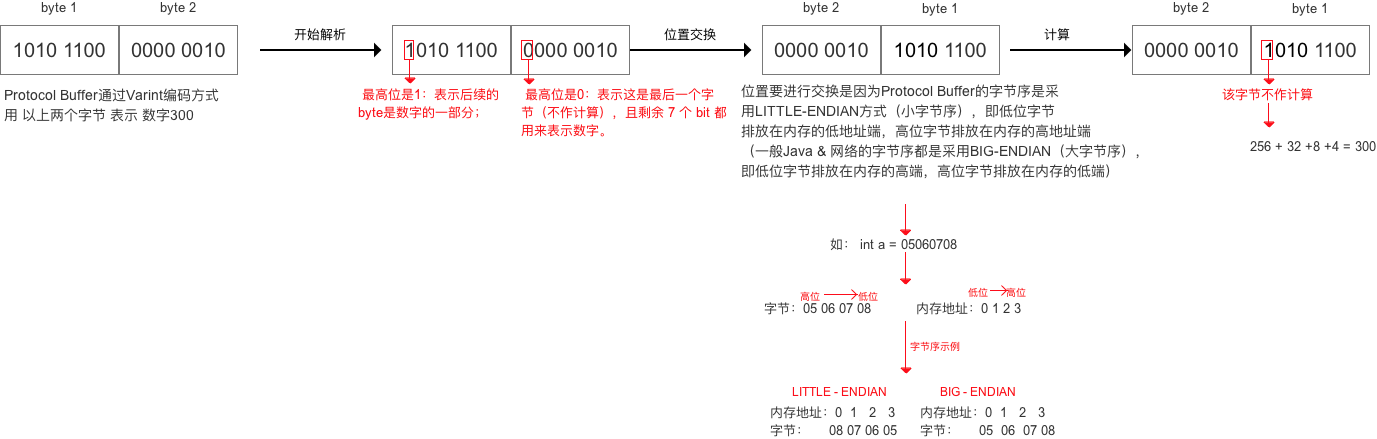
- 方式2 进行序列化 & 反序列化 的源码分析
/*方式2:通过输入/ 输出流(如网络输出流) 序列化和反序列化消息 */
// a.序列化
ByteArrayOutputStream output = new ByteArrayOutputStream();
person.writeTo(output);
// 将消息 序列化后 写入到输出流(此处用 ByteArrayOutputStream 代替)
byte[] byteArray = output.toByteArray();
// 将 输出流 转换成 二进制字节流
// b. 反序列化
ByteArrayInputStream input = new ByteArrayInputStream(byteArray);
// 通过 输入流 接收消息流(此处用 ByteArrayInputStream 代替)
Demo.Person person_Request = Demo.Person.parseFrom(input);
// 通过输入流 反序列化 消息
// 关于其源码分析与方式1类似
// 关于序列化:方式1虽然采用了person.toByteArray(),但内部还是采用了writeTo(),此处就不作过多描述
// 关于反序列化:均采用了Demo.Person.parseFrom(byteArray1);
序列化 & 反序列化过程 总结
a. 序列化的过程如下:
- 创建一个输出流
- 计算出序列化后的二进制流长度,分配该长度的空间,以备以后将每个字段填充到该空间
- 判断每个字段是否有设置值,有值才会进行编码
若
optional或repeated字段没有被设置字段值,那么该字段在序列化时的数据中是完全不存在的,即不进行序列化(少编码一个字段);在解码时,相应的字段才会被设置为默认值
- 根据 字段标识号&数据类型 将 字段值 通过不同的编码方式进行编码
以下是 不同字段数据类型 对应的编码方式
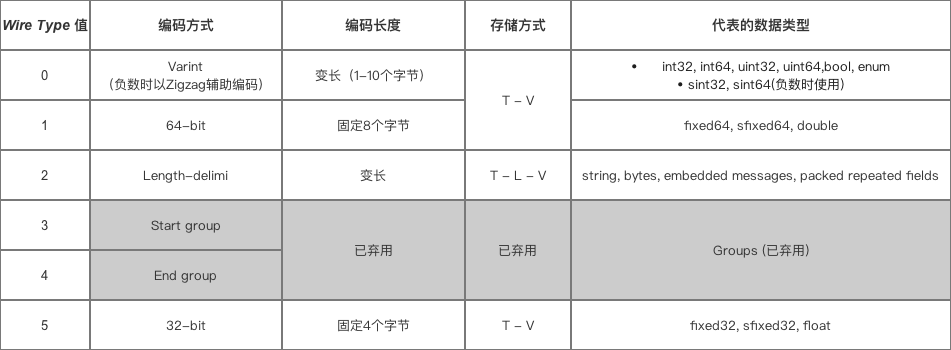
- 将已经编码成功的字节写入到 输出流,即数据存储,最终等待输出
b. 反序列化的过程如下:
- 从 输入流 依次读 字段的标签值(即
Tag值) - 根据从标签值(即
Tag值)值解析出来的标识号(Field_Number),判断对应的数据类型(wire_type) - 调用对应的解码方法 解析 对应字段值
整个序列化 & 反序列化过程简单、速度快,且主要由 Protocol Buffer 自身的框架代码 和 编译器 共同完成
8. 对比于XML 的序列化 & 反序列化过程
-
XML的反序列化过程如下:
- 从文件中读取出字符串
- 将字符串转换为
XML文档对象结构模型 - 从
XML文档对象结构模型中读取指定节点的字符串 - 将该字符串转换成指定类型的变量
上述过程非常复杂。其中,将 XML 文件转换为文档对象结构模型的过程通常需要完成词法文法分析等大量消耗 CPU 的复杂计算。
- 同
Json、XML相比,Protocol Buffer因为序列化 & 反序列化过程简单,所以序列化 & 反序列化过程速度非常快,这也是Protocol Buffer效率高的原因。
9. 总结
Protocol Buffer的序列化 & 反序列化简单 & 速度快的原因是:
a. 编码 / 解码 方式简单(只需要简单的数学运算 = 位移等等)
b. 采用Protocol Buffer自身的框架代码 和 编译器 共同完成Protocol Buffer的数据压缩效果好(即序列化后的数据量体积小)的原因是:
a. 采用了独特的编码方式,如Varint、Zigzag编码方式等等
b. 采用T - L - V的数据存储方式:减少了分隔符的使用 & 数据存储得紧凑
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
