在前面持久化文章中(【死磕 Redis】--- 持久化)阐述了,单台服务器是如何保证数据安全性的,它保证了即使 Redis 服务器因为宕机而重启也不会丢失数据,因为他将内存中的数据持久化到硬盘中了,在重启的时候只需要重新加载即可,但是如果硬盘坏了呢?是不是就没救了,就算硬盘没坏,你去重启 Redis 应用,服务不可用得产生多发的负面影响?所以我们应该尽量避免这种因为单点故障而导致 Redis 服务不可用的情况。
Redis 单机部署一般存在如下几个问题:
- 机器故障,导致 Redis 不可用,数据丢失
- 容量瓶颈:容量不能水平扩展
- QPS 瓶颈:一台机器的处理能力、网络宽带总是有限的,如果能够划分一些流量到其他机器,可以有效解决 QPS 问题
Redis 提供的主从复制功能,实现了一份数据存在多个相同的副本,它是实现 Redis 高可用的基础,作用有如下几个:
- 数据冗余:主从复制实现了数据的热备份,是 Redis 持久化之外的一种数据冗余方式
- 故障恢复:当主节点出现故障时,可以将从节点晋升为主节点继续提供服务,实现快速的故障恢复
- 读写分离:主从复制可以实现读写分离,主节点写,从节点读,读写分离提高了服务器的负载能力
- 高可用的基石:主从复制是哨兵和集群能够实施的基础,因此说主从复制是 Redis 高可用的基础
配置主从复制
默认情况下,Redis 所有节点都是主节点,节点与节点之间互不干涉,而参与主从复制的节点则是划分了主节点(master)和从节点(slave),它具有如下几个特点:
- 主节点下有一个或者多个从节点
- 每一个从节点只能有一个主节点
- 数据的复制是单向的,只能由主节点复制到从节点,所以我们不能在从节点上面执行写的操作
配置主从复制,只需要一个命令 slaveof ip port 即可,可以有三种方式
- 配置在配置文件中添加
slaveof ip port - 在 redis-server 启动命令后增加
--slaveof ip port - 直接使用命令
slaveof ip port
注意使用在从节点上面执行,ip 对应的是 masterIP,port 对应的也是 masterPort。下面来分析下主从复制的过程。
准备环境如下:
| 角色 | IP | port |
|---|---|---|
| master | 127.0.0.1 | 6379 |
| slave | 127.0.0.1 | 6380 |
注:在生产环境中不推荐将主从服务器搭建在同一台服务器上面,这里是为了演示方便。
- 启动 6379 、 6380 两台服务器,在 6380 上面执行
slaveof 127.0.0.1 6379 - 在 master 节点,执行命令
set chenssy chenssy1 - 在 slave 节点,执行命令
get chenssy,得到的结果chenssy1,表名 master 数据已经同步到 slave 节点,主从部署完成。如下图

下面我们重点分析主节点、从节点的一些 INFO 信息。
分析 INFO 信息
主节点
在 master 节点执行命令 info replication,得到下图:
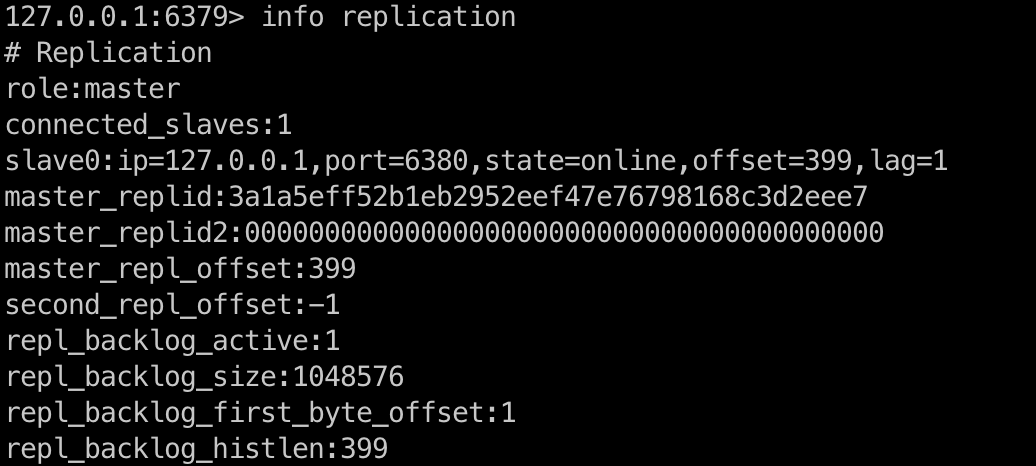
role:master:角色, master 表示当前节点为 master 节点connected-slaves:表示该主节点下面有几个从节点slave0:ip=127.0.0.1,port=6380,state=online,offset=399,lag=1:从节点的信息,包括 IP、port、state 状态,offset 偏移量master-replid:3a1a5eff52b1eb2952eef47e76798168c3d2eee7:主节点的复制 ID,是一个 40 为 16 进制的字符串,注意他和 Redis 的 runid 没有直接关系master_replid2:0000000000000000000000000000000000000000:复制 ID2,默认全为 0,用于存储上次主实例的replid1master_repl_offset:399:主节点数据的偏移量,他和 slave 之间的差值就表示两者之间同步的数据差异repl_*:存储的是复制缓存相关的信息repl_backlog_active:1:是否开启复制缓冲区,1 表示已开启repl_backlog_size:1048576:复制缓冲区的最大长度repl_backlog_first_byte_offset:1:起始偏移量,用于计算当前缓冲区可用范围repl_backlog_histlen:399:已保存数据的有效长度
从节点
在 slave 节点执行命令 info replication,得到下图:
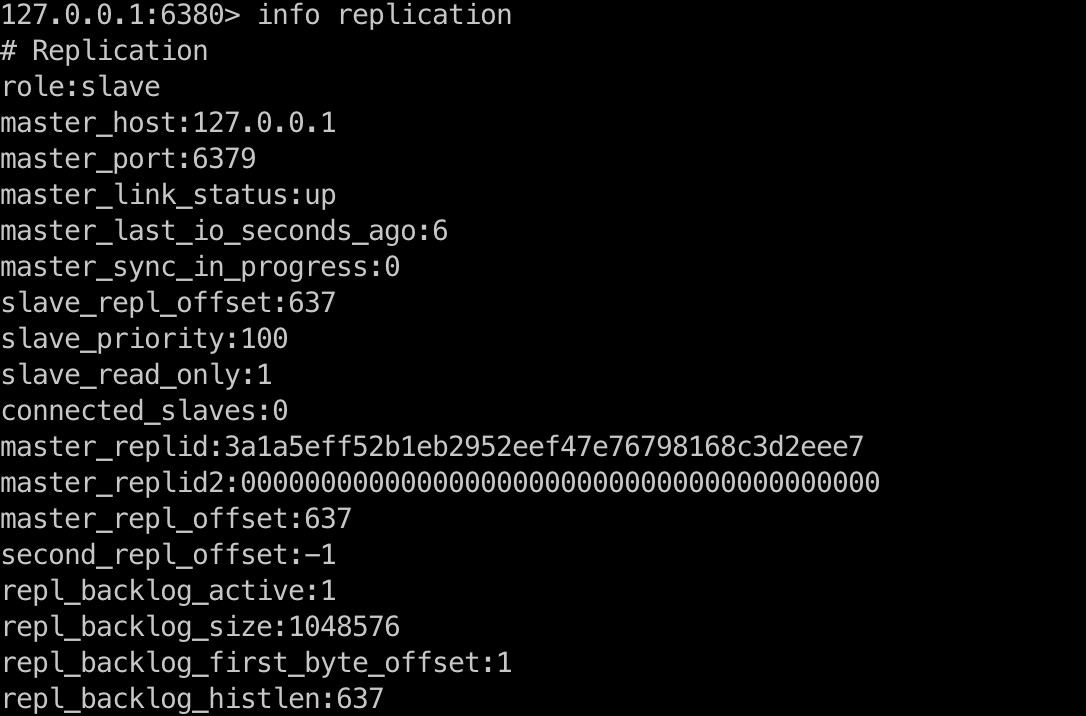
role:slave:角色为 slave 节点master-*:master 节点相关的信息master_host:127.0.0.1:master 节点 IPmaster_port:6379:master 节点 portmaster_link_status:up:master 是否在线状态master_last_io_seconds_ago:6:master_sync_in_progress:0:数据同步状态,0 表示没有在进行数据同步master_replid:3a1a5eff52b1eb2952eef47e76798168c3d2eee7:主节点的复制 IDmaster_replid2:0000000000000000000000000000000000000000:复制 ID2master_repl_offset:637:主节点数据的偏移量
slave_repl_offset:637:从节点同步数据的偏移量slave_read_only::从节点是否只读。从节点默认是只读,我们知道复制是单向的只能有主节点到从节点,如果从节点修改了值,主节点是不会有感知的,会导致主从节点数据不一致现象,所以不推荐修改该值。
原理
Redis 主从复制大体可以分为三个阶段:
- 建立连接阶段
- 数据同步阶段
- 命令传播阶段
下面我们就重点分析这三个阶段
建立连接阶段
该阶段的主要作用就是主从节点建立连接,为数据同步做准备。
1. 保存主节点信息
当从节点执行 slaveof masterIp masterPort 命令后,就会将主节点的IP、port 信息保存下来,这里需要注意的是 slaveof 是异步命令,它在保存主节点信息后立刻返回,实际的建立连接阶段是之后进行的。在这个节点我们可以在从节点的日志看到如下信息:
61098:S 15 May 2019 21:45:16.905 * REPLICAOF 127.0.0.1:6379 enabled (user request from 'id=3 addr=127.0.0.1:65227 fd=8 name= age=10 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=42 qbuf-free=32726 obl=0 oll=0 omem=0 events=r cmd=slaveof')
2. 建立 socket 连接
从节点内部通过定时任务(每秒执行一次)维护着复制相关的逻辑,如果发现有了新的主节点,便会根据主节点的 IP 和 PORT ,创建 socket 连接,如果连接成功,则:
- 从节点:为该socket建立一个专门处理复制工作的文件事件处理器,负责后续的复制工作。
从节点连接成功后,会打印如下日志:
61098:S 15 May 2019 21:45:17.759 * Connecting to MASTER 127.0.0.1:6379
61098:S 15 May 2019 21:45:17.760 * MASTER <-> REPLICA sync started
如果从节点无法建立连接,则定时任务会不断地重连直到成功或者执行 slaveof no one 取消主从复制。
3、发送 ping 命令
当主从节点建立连接后,从节点则就变成了主节点的一个客户端,这时从节点就会向主节点发送 PING 命令,发送该命令的目的有两个:
- 验证 socket 连接是否可用
- 判断主节点是否可以处理请求
从节点发送 ping 命令后,它可能会收到三个类型的回复:
- PONG:说明当前 socket 连接可用,且主节点可以处理请求,复制进程继续
- 超时:说明当前 socket 不可用,从节点则断开连接,重连
- 其他命令:如果主节点返回其他结果,说明主节点无法处理命令,当前可能正在处理其他超时运行的脚本,则从节点断开连接,重连
当从节点接受 PONG 结果后,会打印如下日志:
61098:S 15 May 2019 21:45:17.760 * Non blocking connect for SYNC fired the event.
61098:S 15 May 2019 21:45:17.761 * Master replied to PING, replication can continue...
4、身份认证
如果主节点设置了 requirepass 参数,则从节点必须要向主节点进行身份认证,只有当两个节点的 masterauth 一致(一致是指都存在且密码相同),则身份验证通过,复制进程继续,否则从节点断开 socket 连接并重新发起连接。
从节点进行身份验证是通过向主节点发送 auth 命令进行的,auth 命令的参数即为配置文件中的 masterauth 的值。
数据同步阶段
当从节点发送 ping 命令收到 pong 回复后,主从节点就建立了连接,这时他们便可以进行数据同步了,具体的执行方式是:从节点向主节点发送 psync 命令,主节点根据当前状态的不同进行不同的复制流程。流程分为:全量复制和部分复制,下篇文章会专门介绍这两种复制方式,这里不再详述。
这里需要注意的两点:
- 一、主从首次建立连接时是进行全量复制,当主从断开连接,从节点重新连接时,则需要根据偏移量来判断是进行全量复制还是部分复制。
- 二、在数据同步前,从节点是主节点的客服端,主节点不是从节点的客户度,但是到了这个阶段以后,主从节点互为客户端,这是因为在这个阶段后,主节点会主动向从节点发送命令。
命令传播阶段
当主节点完成数据同步节点后,主节点已经将当前数据同步给从节点了,但是主节点还是在不断地接受命令,为了保证主从数据一致性,主节点需要持续不断地将写命令发送给从节点,需要注意的是,这个过程异步过程,即主节点发送写命令后并不会等待从节点的回复,因此主从节点之间的数据延迟是难免的,所以主从节点保证的是最终一致性。同时,主从之间的延迟与他们两者之间的网络状况、主节点写命令的执行频率、以及主节点中的 repl-disable-tcp-nodelay 配置等有关。
拓扑结构
Redis 的拓扑结果有如下三种:
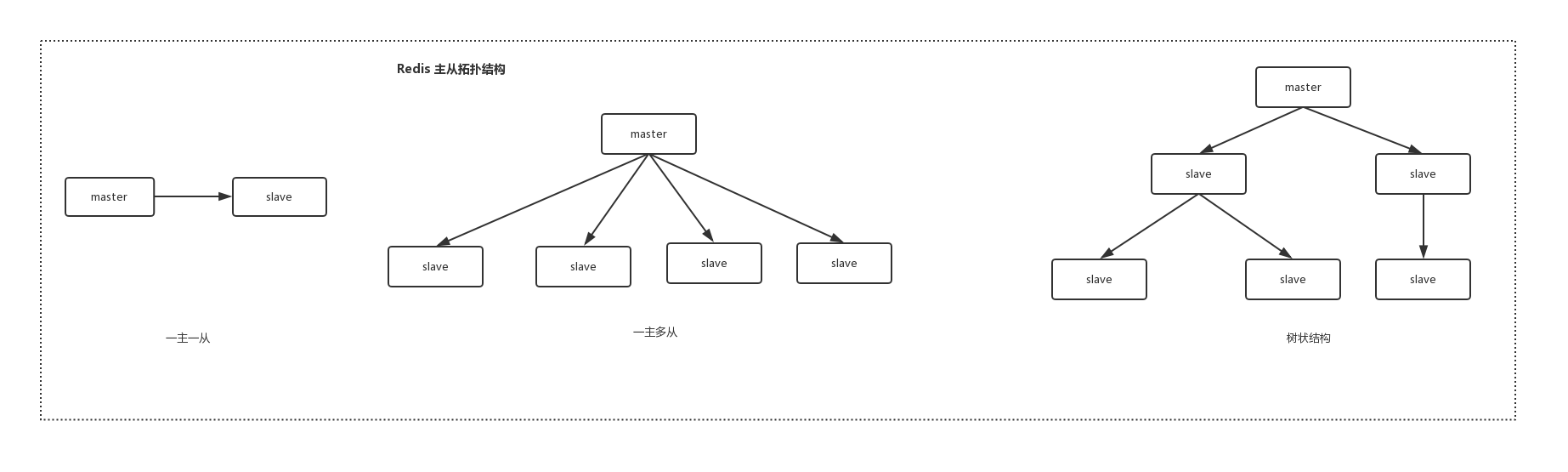
- 一主一从:最简单的拓扑结构,一般适用于没有太大的并发场景。当 master 宕机时,slave 提供故障转移支持
- 一主多从:适用于并发量较大的场景,一般都是读多写少,客户端可以将读命令发送到 salve 节点分担 master 节点压力。实现读写分离架构,当然也保证了高可用。但是该架构需要避免复制风暴。
- 树状结构:slave 节点除了在 master 复制数据,也可以在其他 slave 节点复制数据。主要是通过引用复制中间层,降低 master 节点的负载和需要传送给从节点的数据量,这种架构可以避免复制风暴,但是延长了数据一致性。
参考资料
- 付磊:《Redis 开发与运维》
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
