这是《计算机网络》系列文章的第二篇文章
我们第一篇文章讲述了计算机网络的基本概念,互联网的基本名词,什么是协议以及几种接入网以及网络传输的物理媒体,那么本篇文章我们来探讨一下网络核心、交换网络、时延、丢包、吞吐量以及计算机网络的协议层次和网络攻击。
网络核心
网络的核心是由因特网端系统和链路构成的网状网络,下面这幅图正确的表达了这一点
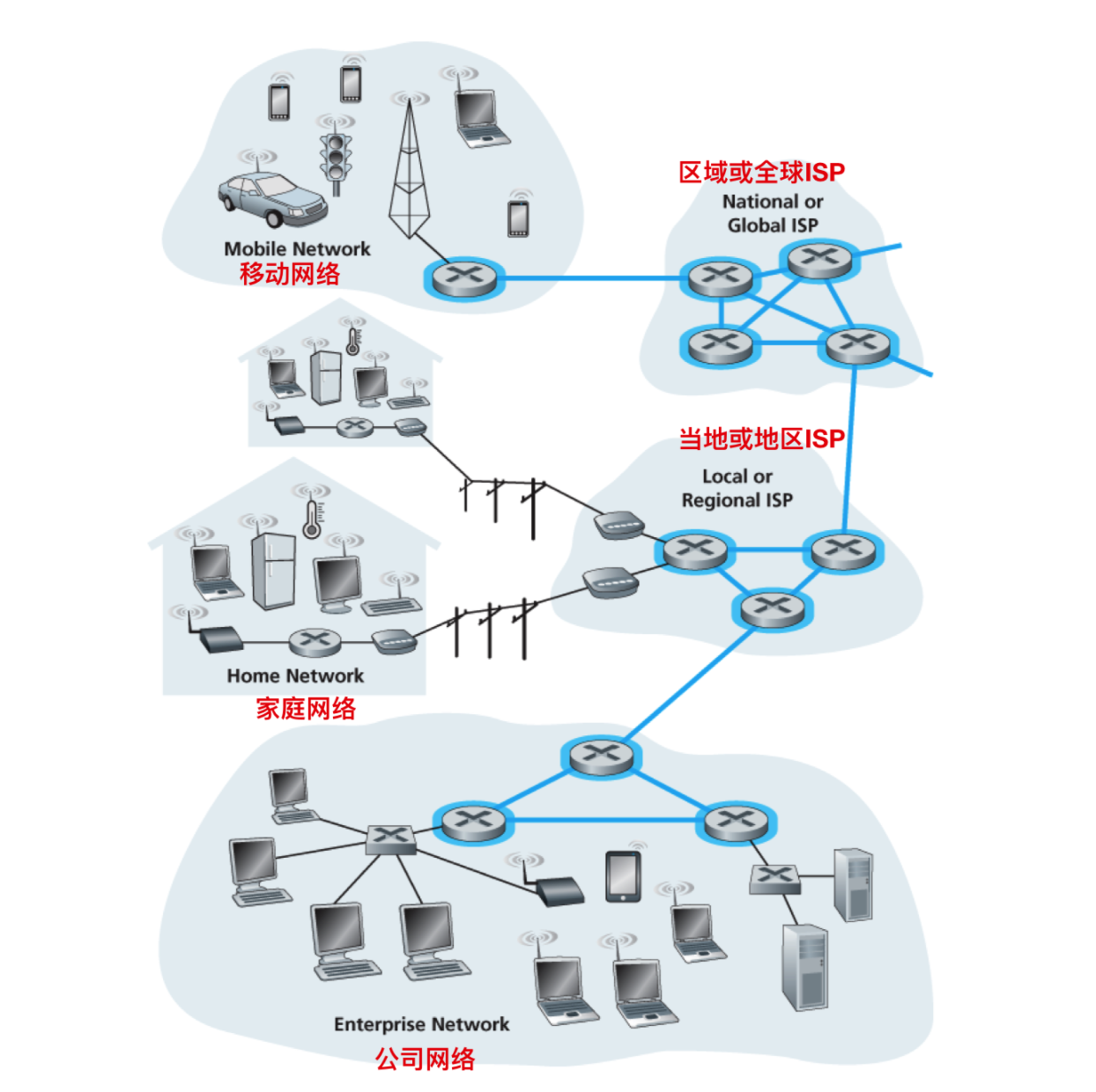
那么在不同的 ISP 和本地以及家庭网络是如何交换信息的呢?信息交换主要分为两种方式 分组交换 和 电路交互,下面我们就来一起认识一下。
分组交换
在互联网应用中,每个终端系统都可以彼此交换信息,这种信息也被称为 报文(Message),报文是一个集大成者,它可以包括你想要的任何东西,比如文字、数据、电子邮件、音频、视频等。为了从源目的地向端系统发送报文,需要把长报文切分为一个个小的数据块,这种数据块称为分组(Packets),也就是说,报文是由一个个小块的分组组成。在端系统和目的地之间,每个分组都要经过通信链路(communication links) 和分组交换机(switch packets) ,通信链路可以分为双绞铜线、同轴电缆和光纤。分组交换机又分为路由器和链路层交换机。(这块如果你不明白的话,还需要翻看我上一篇文章 你说你懂互联网,那这些你知道么?)分组要在端系统之间交互需要经过一定的时间,如果两个端系统之间需要交互的分组为 L 比特,链路的传输速率问 R 比特/秒,那么传输时间就是 L / R秒。
现在我们来模拟一下这个分组交换的过程,一个端系统需要经过交换机给其他端系统发送分组,当分组到达交换机时,交换机就能够直接进行转发吗?不是的,交换机可没有这么无私,你想让我帮你转发分组?好,首先你需要先把整个分组数据都给我,我再考虑给你发送的问题,这就是存储转发传输
存储转发传输
存储转发传输指的就是交换机再转发分组的第一个比特前,必须要接受到整个分组,下面是一个存储转发传输的示意图,可以从图中窥出端倪
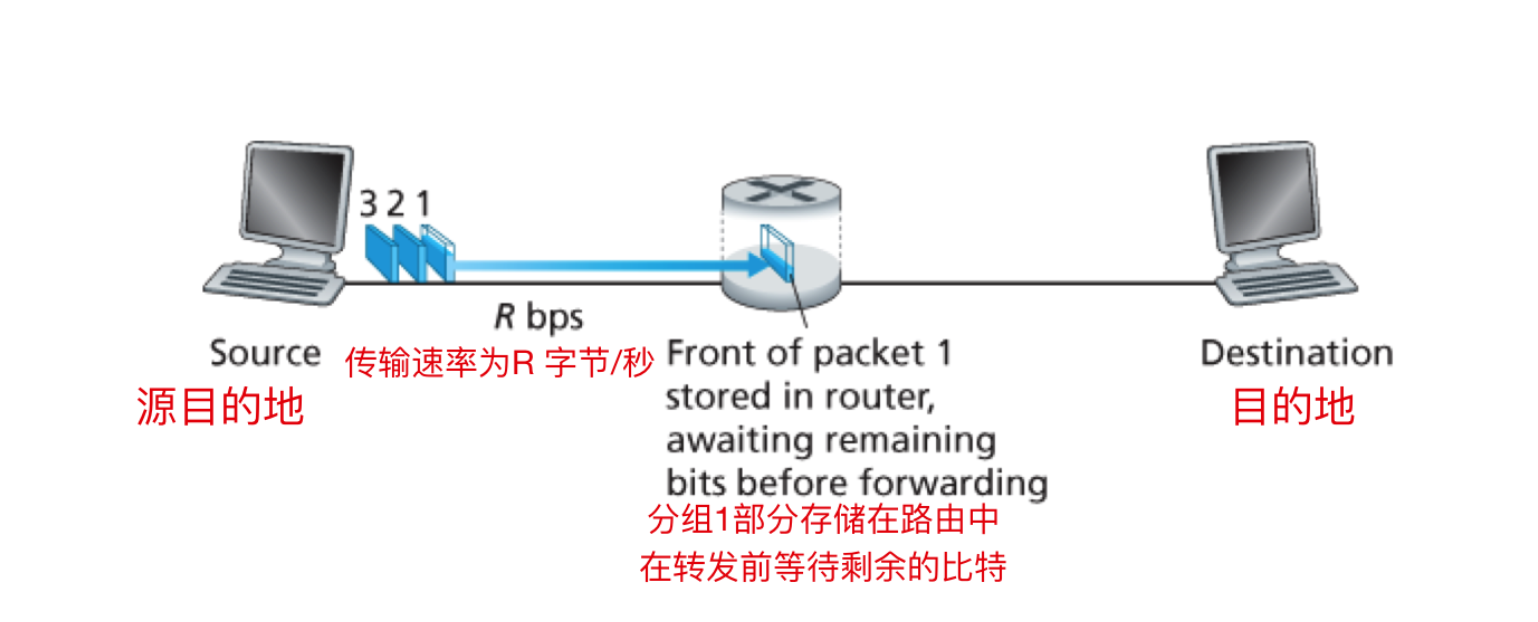
由图可以看出,分组 1、2、3 在以 R bps 的速率向交换器进行分组传输,并且交换机已经收到了分组1 发送的比特,此时交换机会直接进行转发吗?答案是不会的,交换机会把你的分组先缓存在本地。这就和考试作弊一样,一个学霸要经过学渣 A 给学渣 B 传答案,学渣 A 说,学渣 A 在收到答案后,它可能直接把卷子传过去吗?学渣A 说,等我先把答案抄完(保存功能)后再把卷子给你。
排队时延和分组丢失
什么?你认为交换机只能和一条通信链路进行相连?那你就大错特错了,这可是交换机啊,怎么可能只有一条通信链路呢?
所以我相信你一定能想到这个问题,多个端系统同时给交换器发送分组,一定存在顺序到达和排队的问题。事实上,对于每条相连的链路,该分组交换机会有一个输出缓存(output buffer) 和 输出队列(output queue) 与之对应,它用于存储路由器准备发往每条链路的分组。如果到达的分组发现路由器正在接收其他分组,那么新到达的分组就会在输出队列中进行排队,这种等待分组转发所耗费的时间也被称为 排队时延,上面提到分组交换器在转发分组时会进行等待,这种等待被称为 存储转发时延,所以我们现在了解到的有两种时延,但是其实是有四种时延。这些时延不是一成不变的,其变化程序取决于网络的拥塞程度。
因为队列是有容量限制的,当多条链路同时发送分组导致输出缓存无法接受超额的分组后,这些分组会丢失,这种情况被称为 丢包(packet loss),到达的分组或者已排队的分组将会被丢弃。
下图说明了一个简单的分组交换网络

在上图中,分组由三位数据平板展示,平板的宽度表示着分组数据的大小。所有的分组都有相同的宽度,因此也就有相同的数据包大小。 下面来一个情景模拟: 假定主机 A 和 主机 B 要向主机 E 发送分组,主机 A 和 B 首先通过100 Mbps以太网链路将其数据包发送到第一台路由器,然后路由器将这些数据包定向到15 Mbps的链路。如果在较短的时间间隔内,数据包到达路由器的速率(转换为每秒比特数)超过15 Mbps,则在数据包在链路输出缓冲区中排队之前,路由器上会发生拥塞,然后再传输到链路上。例如,如果主机 A 和主机 B 背靠背同时发了5包数据,那么这些数据包中的大多数将花费一些时间在队列中等待。实际上,这种情况与许多普通情况完全相似,例如,当我们排队等候银行出纳员或在收费站前等候时。
转发表和路由器选择协议
我们刚刚讲过,路由器和多个通信线路进行相连,如果每条通信链路同时发送分组的话,可能会造成排队和丢包的情况,然后分组在队列中等待发送,现在我就有一个问题问你,队列中的分组发向哪里?这是由什么机制决定的?
换个角度想问题,路由的作用是什么? 把不同端系统中的数据包进行存储和转发 。在因特网中,每个端系统都会有一个 IP 地址,当原主机发送一个分组时,在分组的首部都会加上原主机的 IP 地址。每一台路由器都会有一个 转发表(forwarding table),当一个分组到达路由器后,路由器会检查分组的目的地址的一部分,并用目的地址搜索转发表,以找出适当的传送链路,然后映射成为输出链路进行转发。
那么问题来了,路由器内部是怎样设置转发表的呢?详细的我们后面会讲到,这里只是说个大概,路由器内部也是具有路由选择协议的,用于自动设置转发表。
电路交换
在计算机网络中,另一种通过网络链路和路由进行数据传输的另外一种方式就是 电路交换(circuit switching)。电路交换在资源预留上与分组交换不同,什么意思呢?就是分组交换不会预留每次端系统之间交互分组的缓存和链路传输速率,所以每次都会进行排队传输;而电路交换会预留这些信息。一个简单的例子帮助你理解:这就好比有两家餐馆,餐馆 A 需要预定而餐馆 B 不需要预定,对于可以预定的餐馆 A,我们必须先提前与其进行联系,但是当我们到达目的地时,我们能够立刻入座并选菜。而对于不需要预定的那家餐馆来说,你可能不需要提前联系,但是你必须承受到达目的地后需要排队的风险。
下面显示了一个电路交换网络
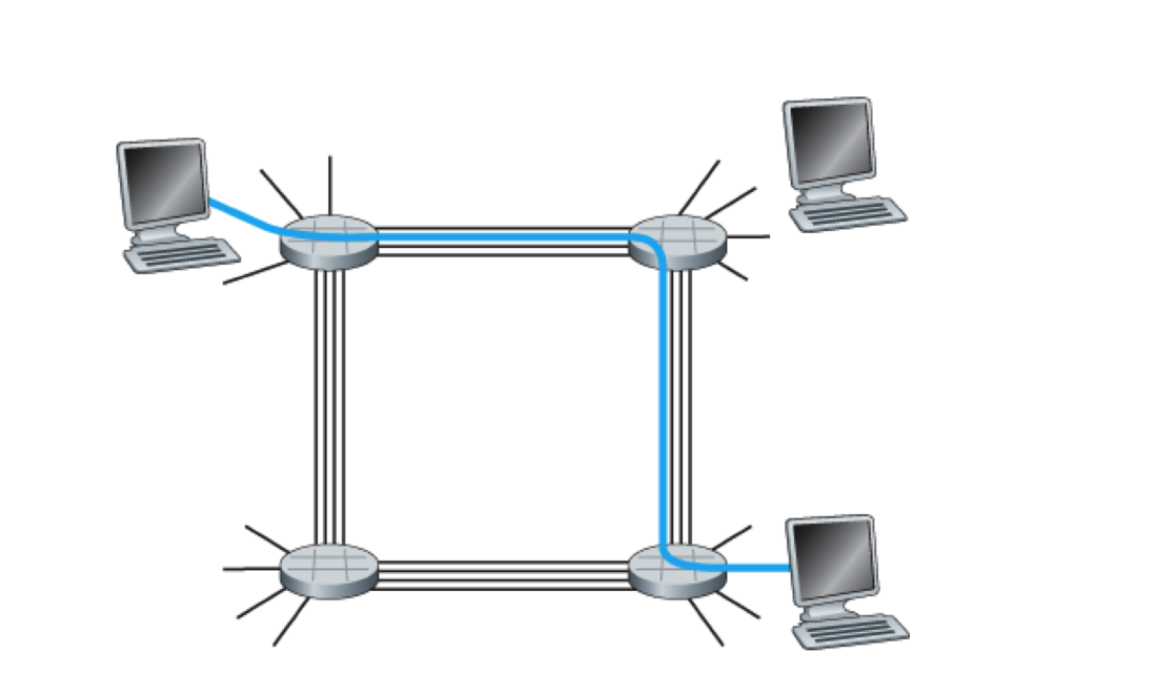
在这个网络中,4条链路用于4台电路交换机。这些链路中的每一条都有4条电路,因此每条链路能支持4条并行的链接。每台主机都与一台交换机直接相连,当两台主机需要通信时,该网络在两台主机之间创建一条专用的 端到端的链接(end-to-end connection)。
分组交换和电路交换的对比
分组交换的支持者经常说分组交换不适合实时服务,因为它的端到端时延时不可预测的。而分组交换的支持者却认为分组交换提供了比电路交换更好的带宽共享;它比电路交换更加简单、更有效,实现成本更低。但是现在的趋势更多的是朝着分组交换的方向发展。
分组交换网的时延、丢包和吞吐量
因特网可以看成是一种基础设施,该基础设施为运行在端系统上的分布式应用提供服务。我们希望在计算机网络中任意两个端系统之间传递数据都不会造成数据丢失,然而这是一个极高的目标,实践中难以达到。所以,在实践中必须要限制端系统之间的 吞吐量 用来控制数据丢失。如果在端系统之间引入时延,也不能保证不会丢失分组问题。所以我们从时延、丢包和吞吐量三个层面来看一下计算机网络
分组交换中的时延
计算机网络中的分组从一台主机(源)出发,经过一系列路由器传输,在另一个端系统中结束它的历程。在这整个传输历程中,分组会涉及到四种最主要的时延: 节点处理时延(nodal processing delay)、排队时延(queuing delay)、传输时延(total nodal delay)和传播时延(propagation delay) 。这四种时延加起来就是 节点总时延(total nodal delay)。
如果用 dproc dqueue dtrans dpop 分别表示处理时延、排队时延、传输时延和传播时延,则节点的总时延由以下公式决定: dnodal = dproc + dqueue + dtrans + dpop。
时延的类型
下面是一副典型的时延分布图,让我们从图中进行分析一下不同的时延类型
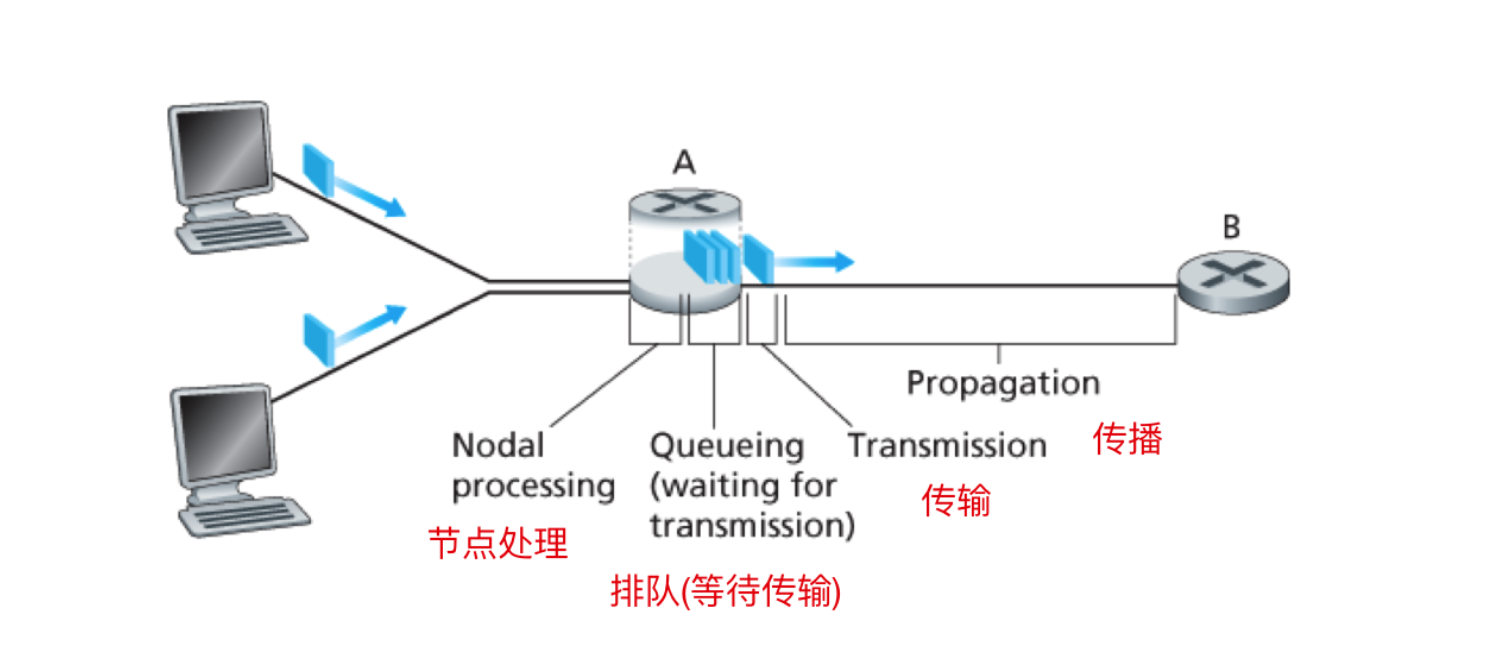
分组由端系统经过通信链路传输到路由器 A,路由器A 检查分组头部以映射出适当的传输链路,并将分组送入该链路。仅当该链路没有其他分组正在传输并且没有其他分组排在该该分组前面时,才能在这条链路上自由的传输该分组。如果该链路当前繁忙或者已经有其他分组排在该分组前面时,新到达的分组将会加入排队。下面我们分开讨论一下这四种时延
节点处理时延
节点处理时延分为两部分,第一部分是路由器会检查分组的首部信息;第二部分是决定将分组传输到哪条通信链路所需要的时间。一般高速网络的节点处理时延都在微妙级和更低的数量级。在这种处理时延完成后,分组会发往路由器的转发队列中
排队时延
在队列排队转发过程中,分组需要在队列中等待发送,分组在等待发送过程中消耗的时间被称为排队时延。排队时延的长短取决于先于该分组到达正在队列中排队的分组数量。如果该队列是空的,并且当前没有正在传输的分组,那么该分组的排队时延就是 0。如果处于网络高发时段,那么链路中传输的分组比较多,那么分组的排队时延将延长。实际的排队时延也可以到达微秒级。
传输时延
队列 是路由器所用的主要的数据结构。队列的特征就是先进先出,先到达食堂的先打饭。传输时延是理论情况下单位时间内的传输比特所消耗的时间。比如分组的长度是 L 比特,R 表示从路由器 A 到路由器 B 的传输速率。那么传输时延就是 L / R 。这是将所有分组推向该链路所需要的时间。正是情况下传输时延通常也在毫秒到微妙级
传播时延
从链路的起点到路由器 B 传播所需要的时间就是 传播时延。该比特以该链路的传播速率传播。该传播速率取决于链路的物理介质(双绞线、同轴电缆、光纤)。如果用公式来计算一下的话,该传播时延等于两台路由器之间的距离 / 传播速率。即传播速率是 d/s ,其中 d 是路由器 A 和 路由器 B 之间的距离,s 是该链路的传播速率。
传输时延和传播时延的比较
计算机网络中的传输时延和传播时延有时候难以区分,在这里解释一下,传输时延是路由器推出分组所需要的时间,它是分组长度和链路传输速率的函数,而与两台路由器之间的距离无关。而传播时延是一个比特从一台路由器传播到另一台路由器所需要的时间,它是两台路由器之间距离的倒数,而与分组长度和链路传输速率无关。从公式也可以看出来,传输时延是 L/R,也就是分组的长度 / 路由器之间传输速率。传播时延的公式是 d/s,也就是路由器之间的距离 / 传播速率。
排队时延
在这四种时延中,人们最感兴趣的时延或许就是排队时延了 dqueue。与其他三种时延(dproc、dtrans、dpop)不同的是,排队时延对不同的分组可能是不同的。例如,如果10个分组同时到达某个队列,第一个到达队列的分组没有排队时延,而最后到达的分组却要经受最大的排队时延(需要等待其他九个时延被传输)。
那么如何表征排队时延呢?或许可以从三个方面来考虑: 流量到达队列的速率、链路的传输速率和到达流量的性质 。即流量是周期性到达还是突发性到达,如果用 a 表示分组到达队列的平均速率( a 的单位是分组/秒,即 pkt/s)前面说过 R 表示的是传输速率,所以能够从队列中推出比特的速率(以 bps 即 b/s 位单位)。假设所有的分组都是由 L 比特组成的,那么比特到达队列的平均速率是 La bps。那么比率 La/R 被称为流量强度(traffic intensity),如果 La/R > 1,则比特到达队列的平均速率超过从队列传输出去的速率,这种情况下队列趋向于无限增加。所以, 设计系统时流量强度不能大于1 。
现在考虑 La / R <= 1 时的情况。流量到达的性质将影响排队时延。如果流量是周期性到达的,即每 L / R 秒到达一个分组,则每个分组将到达一个空队列中,不会有排队时延。如果流量是 突发性 到达的,则可能会有很大的平均排队时延。一般可以用下面这幅图表示平均排队时延与流量强度的关系
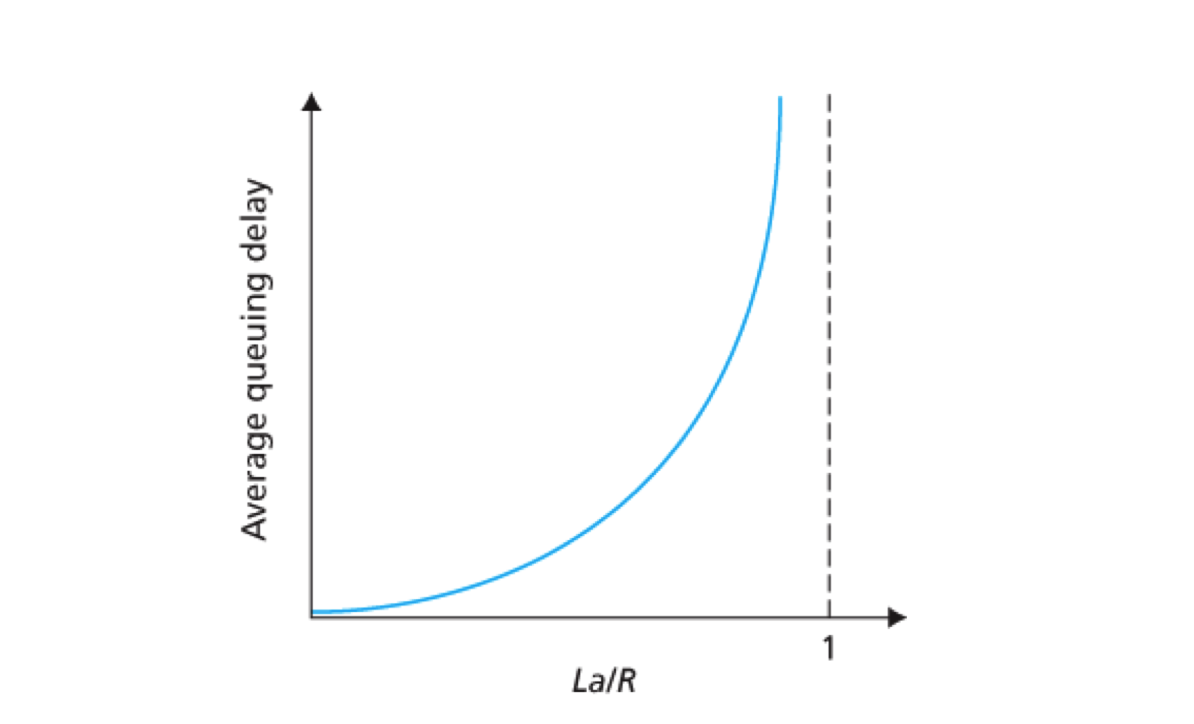
横轴是 La/R 流量强度,纵轴是平均排队时延。
丢包
我们在上述的讨论过程中描绘了一个公式那就是 La/R 不能大于1,如果 La/R 大于1,那么到达的排队将会无穷大,而且路由器中的排队队列所容纳的分组是有限的,所以等到路由器队列堆满后,新到达的分组就无法被容纳,导致路由器 丢弃(drop) 该分组,即分组会 丢失(lost)。
计算机网络中的吞吐量
除了丢包和时延外,衡量计算机另一个至关重要的性能测度是端到端的吞吐量。假如从主机 A 向主机 B 传送一个大文件,那么在任何时刻主机 B 接收到该文件的速率就是 瞬时吞吐量(instantaneous throughput)。如果该文件由 F 比特组成,主机 B 接收到所有 F 比特用去 T 秒,则文件的传送平均吞吐量(average throughput) 是 F / T bps。
协议层次以及服务模型
因特网是一个复杂的系统,不仅包括大量的应用程序、端系统、通信链路、分组交换机等,还有各种各样的协议组成,那么现在我们就来聊一下因特网中的协议层次
协议分层
为了给网络协议的设计提供一个结构,网络设计者以分层(layer)的方式组织协议,每个协议属于层次模型之一。每一层都是向它的上一层提供服务(service),即所谓的服务模型(service model)。每个分层中所有的协议称为 协议栈(protocol stack)。因特网的协议栈由五个部分组成:物理层、链路层、网络层、运输层和应用层。我们采用自上而下的方法研究其原理,也就是应用层 -> 物理层的方式。
应用层
应用层是网络应用程序和网络协议存放的分层,因特网的应用层包括许多协议,例如我们学 web 离不开的 HTTP,电子邮件传送协议 SMTP、端系统文件上传协议 FTP、还有为我们进行域名解析的 DNS 协议。应用层协议分布在多个端系统上,一个端系统应用程序与另外一个端系统应用程序交换信息分组,我们把位于应用层的信息分组称为 报文(message)。
运输层
因特网的运输层在应用程序断点之间传送应用程序报文,在这一层主要有两种传输协议 TCP和 UDP,利用这两者中的任何一个都能够传输报文,不过这两种协议有巨大的不同。
TCP 向它的应用程序提供了面向连接的服务,它能够控制并确认报文是否到达,并提供了拥塞机制来控制网络传输,因此当网络拥塞时,会抑制其传输速率。
UDP 协议向它的应用程序提供了无连接服务。它不具备可靠性的特征,没有流量控制,也没有拥塞控制。我们把运输层的分组称为 报文段(segment)
网络层
因特网的网络层负责将称为 数据报(datagram) 的网络分层从一台主机移动到另一台主机。网络层一个非常重要的协议是 IP 协议,所有具有网络层的因特网组件都必须运行 IP 协议,IP 协议是一种网际协议,除了 IP 协议外,网络层还包括一些其他网际协议和路由选择协议,一般把网络层就称为 IP 层,由此可知 IP 协议的重要性。
链路层
现在我们有应用程序通信的协议,有了给应用程序提供运输的协议,还有了用于约定发送位置的 IP 协议,那么如何才能真正的发送数据呢?为了将分组从一个节点(主机或路由器)运输到另一个节点,网络层必须依靠链路层提供服务。链路层的例子包括以太网、WiFi 和电缆接入的 DOCSIS 协议,因为数据从源目的地传送通常需要经过几条链路,一个数据包可能被沿途不同的链路层协议处理,我们把链路层的分组称为 帧(frame)
物理层
虽然链路层的作用是将帧从一个端系统运输到另一个端系统,而物理层的作用是将帧中的一个个 比特 从一个节点运输到另一个节点,物理层的协议仍然使用链路层协议,这些协议与实际的物理传输介质有关,例如,以太网有很多物理层协议:关于双绞铜线、关于同轴电缆、关于光纤等等。
五层网络协议的示意图如下
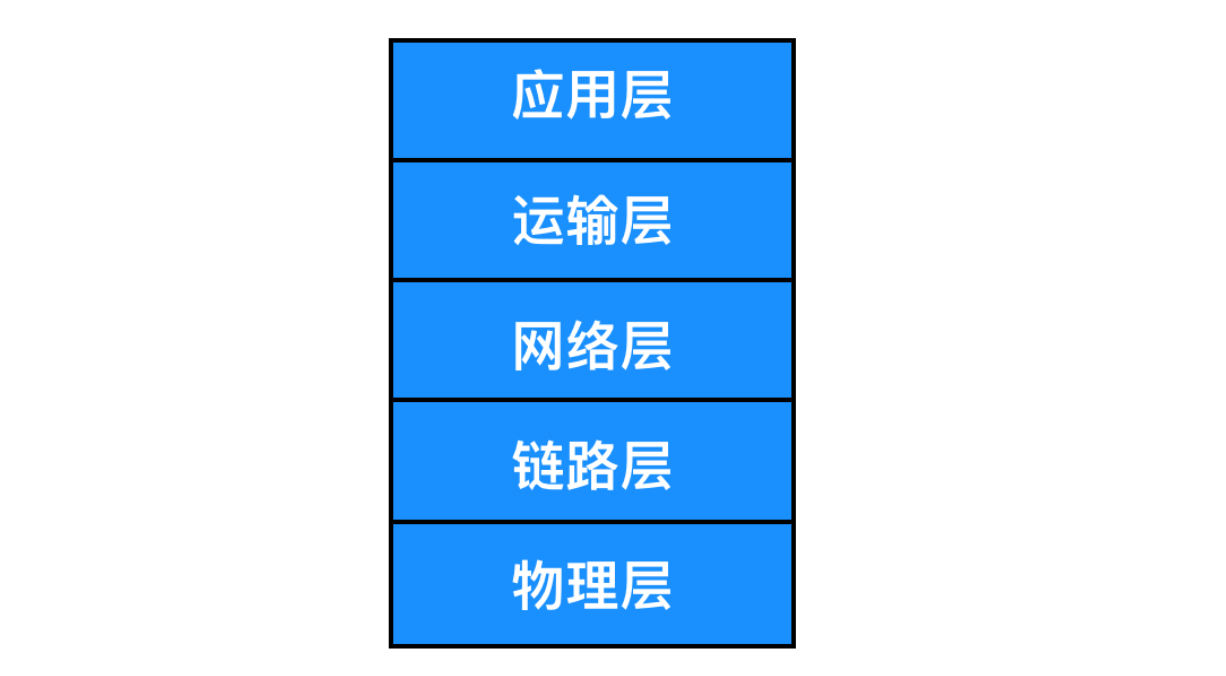
OSI 模型
我们上面讨论的计算网络协议模型不是唯一的 协议栈,ISO(国际标准化组织)提出来计算机网络应该按照7层来组织,那么7层网络协议栈与5层的区别在哪里?
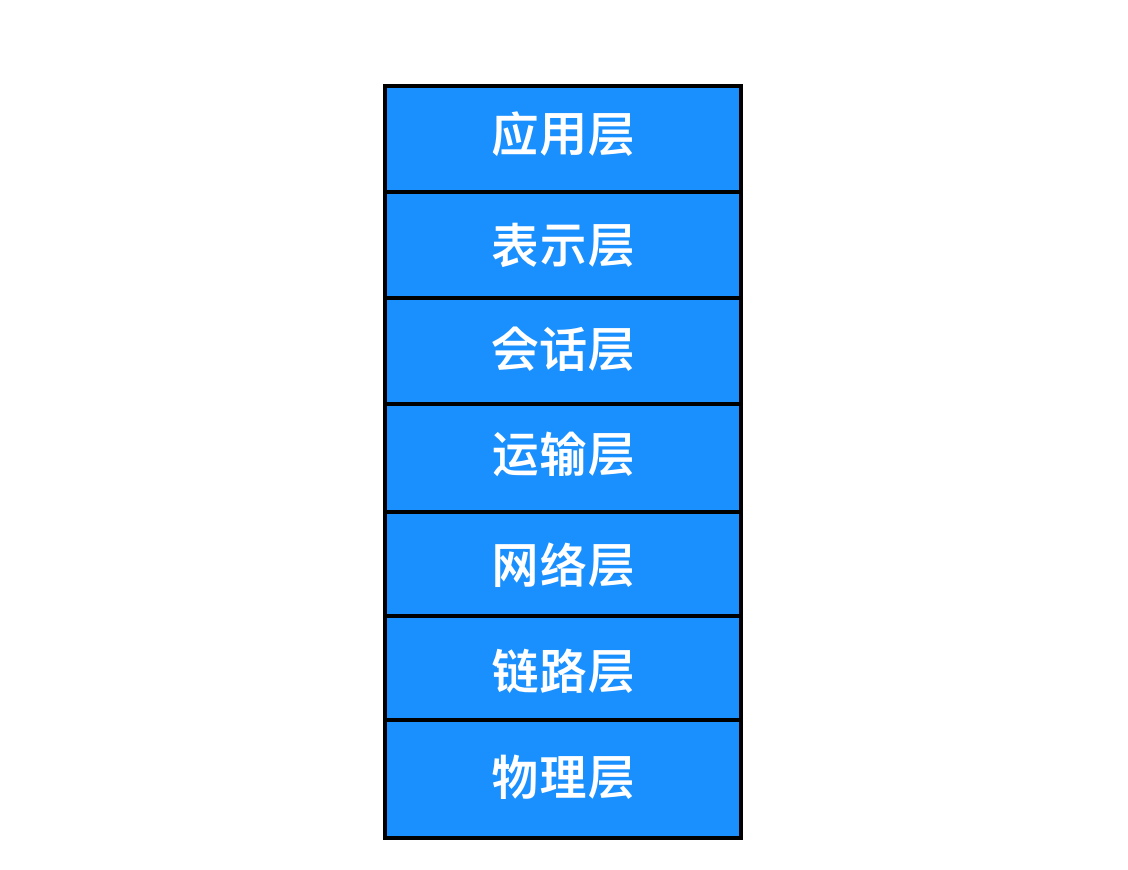
从图中可以一眼看出,OSI 要比上面的网络模型多了 表示层 和 会话层,其他层基本一致。表示层主要包括数据压缩和数据加密以及数据描述,数据描述使得应用程序不必担心计算机内部存储格式的问题,而会话层提供了数据交换的定界和同步功能,包括建立检查点和恢复方案。
网络攻击
在计算机高速发展的 21世纪,我们已经越来越离不开计算机网络,计算机网络在为我们带来诸多便利的同时,我们也会遭受一些网络攻击,下面我们就一起来认识一下网络中的攻击有哪些
植入有害程序
因为我们要从因特网接收/发送 数据,所以我们将设备与因特网相连,我们可以使用各种互联网应用例如微信、微博、上网浏览网页、流式音乐、多媒体会议等,网络攻击很可能在这时不知不觉的发生,通过在这些软件中植入有害程序来入侵我们的计算机,包括删除我们的文件,进行活动监视,侵犯隐私等。我们的受害主机也可能成为众多类似受害设备网络中的一员,它们被统称为 僵尸网络(botnet),这些攻击者会利用僵尸网络控制并有效的对目标主机开展垃圾邮件分发和分布式拒绝服务攻击
大多数有害程序都具有自我复制(self-replicating)的功能,传播性非常强,一旦它感染了一台主机,就会从这台感染的主机上寻找进入因特网的其他主机,从而感染新的主机。有害应用程序主要分为两种:病毒(virus) 和 蠕虫(worm),病毒是一种需要某种形式的用户交互来感染用户的计算机,比如包含了病毒的电子邮件附件。如果用户接收并打开感染病毒的电子邮件的话,就会以某种方式破坏你的计算机;而蠕虫是一种不需要用户交互就能进入计算机的恶意软件,比如你运行了一个攻击者想要攻击的应用程序,某些情况下不需要用户干预,应用程序就可能通过互联网接收恶意软件并运行,从而生成蠕虫,然后再进行扩散。
攻击服务器和网络基础设施
另一种影响较大的网络攻击称为拒绝服务攻击(Denial-of-Service Dos),这种网络攻击使得网络、主机、服务器、基础网络设施不能常规使用。Web 服务器、电子邮件服务器、DNS 服务器都能成为 Dos 的攻击目标。大多数因特网 Dos 攻击分为以下三类
弱点攻击。这涉及向一台目标主机上运行的易受攻击的应用程序或操作系统发送制作精细的报文,如果适当顺序的多个分组发送给一个易受攻击的应用程序或操作系统,该服务器可能停止运行。带宽洪泛。攻击者通过网络向主机或服务器发送大量的分组,分组数量太多使得目标接入链路变得拥塞,使得合法分组无法到达服务器。连接洪泛。和上面的带宽洪范攻击性质相似,只不过这次换成了通过创建大量的 TCP 连接进行攻击。因为 TCP 连接数量太多导致有效的 TCP 连接无法到达服务器。
互联网中攻击最多的就属于带宽洪泛攻击了,可以回顾一下我们上面讨论的时延和丢包问题,如果某服务器的接入速率为 R bps,那么攻击者则需要向服务器发送大于 R bps 的速率来产生危害。如果 R 非常大的话,单一攻击源可能无法产生足够大的流量来伤害服务器,所以还需要产生多个数据源,这就是屡见不鲜的 分布式Dos(Distributed Dos,DDos) 。攻击者通过控制多个数据源并让每个数据源发送大量的分组来致使服务器瘫痪。如下图所示

嗅探分组
今天许多用户通过无线设备接入因特网。例如 WiFi 连接的计算机或者使用蜂窝因特网连接的手持设备。在带来便利的同时也会成为易受攻击的目标。在无线传输设备的附近放置一台被动的接收机,该接收机就能够得到传输的每个分组的副本!这些分组中包含了各种敏感信息,例如口令、密码等,记录每个流经分组副本的接收机被称为分组嗅探器(packet sniffer)。分组嗅探也能够应用于有线环境中,可以用 Wireshark 实验来进行模拟
IP 伪装
生成具有任意源地址、分组内容和目的地址的分组,然后将这个分组传输到互联网中。这种将虚假源地址的分组注入因特网的能力被称为 IP 哄骗(IP spoofing)。为了解决这个问题,我们需要采用 端点鉴别,它是一种使我们能够确信真正源目的地的机制。我们后面会再探讨这些机制。
文章参考:
《计算机网络:自顶向下方法》
http://zahid-stanikzai.com/types-of-delay/
如果大家认可我,请帮我点个赞,谢谢各位了。我们下篇技术文章见。

Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
