本章,我们来看下LogSegment的源码,LogSegment就是对 日志段 的抽象:
class LogSegment(val log: FileRecords,
val index: OffsetIndex,
val timeIndex: TimeIndex,
val baseOffset: Long,
val indexIntervalBytes: Int,
val rollJitterMs: Long,
time: Time) extends Logging {
}
可以看到,LogSegment类的声明包含了以下信息:
- FileRecords: 实际保存 Kafka 消息的对象;
- OffsetIndex: 位移索引;
- TimeIndex: 时间戳索引;
- baseOffset: 初始偏移量,在磁盘上看到的日志段文件名就是 baseOffset 的值
- indexIntervalBytes: Broker 端参数
log.index.interval.bytes值,控制了日志段对象新增索引项的频率,默认情况下,日志段至少新写入 4KB 的消息数据才会新增一条索引项; - rollJitterMs :日志段新增时的一个“扰动时间值”。Broker 可能会同时创建多个日志段文件,会增加磁盘 I/O 压力,有了 rollJitterMs 值的干扰,每个日志段文件在创建时会彼此岔开一小段时间,从而缓解磁盘的 I/O 负载瓶颈。
一、核心方法
我们再来看下LogSegment的核心方法,在《Broker:日志子系统——整体架构》中,我介绍过Broker端写日志的整体流程,其中就涉及LogSegment.append()方法写日志。LogSegment的核心方法一共有3个,我用下面这张图表示:
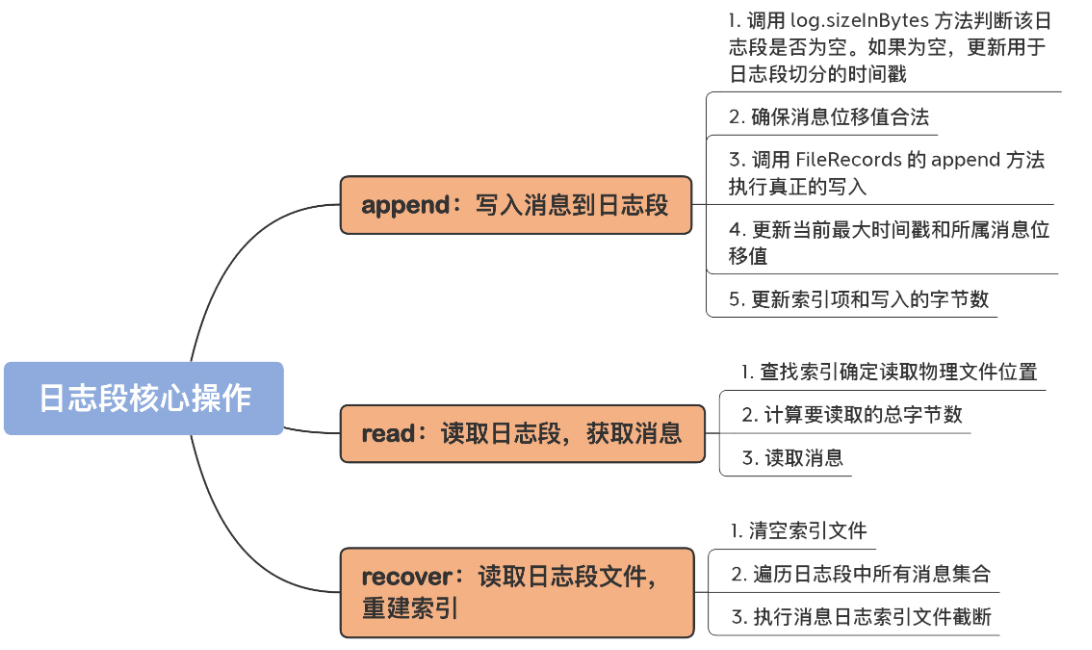
1.1 append写消息
我们先来看最重要的append方法,它接收 5 个参数:
- firstOffset:首位移值;
- largestOffset:最大位移值;
- largestTimestamp:最大时间戳;
- shallowOffsetOfMaxTimestamp:最大时间戳对应消息的位移;
- records:真正要写入的消息集合。
// LogSegment.scala
def append(firstOffset: Long, largestOffset: Long, largestTimestamp: Long,
shallowOffsetOfMaxTimestamp: Long, records: MemoryRecords) {
if (records.sizeInBytes > 0) {
val physicalPosition = log.sizeInBytes()
// 1.日志段大小为0,即为空,则记录要写入消息集合的最大时间戳,并将其作为后面新增日志段倒计时的依据
if (physicalPosition == 0)
rollingBasedTimestamp = Some(largestTimestamp)
require(canConvertToRelativeOffset(largestOffset), "largest offset in message set can not be safely converted to relative offset.")
// 2.调用FileRecords.append方法执行真正的写入,将内存中的消息对象写入到操作系统的页缓存
val appendedBytes = log.append(records)
// 3.更新日志段的最大时间戳以及最大时间戳所属消息的位移值属性
if (largestTimestamp > maxTimestampSoFar) {
maxTimestampSoFar = largestTimestamp
offsetOfMaxTimestamp = shallowOffsetOfMaxTimestamp
}
// 4.更新索引项和写入的字节数,日志段每写入4KB数据就要写入一个索引项
if(bytesSinceLastIndexEntry > indexIntervalBytes) {
index.append(firstOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestamp)
bytesSinceLastIndexEntry = 0
}
bytesSinceLastIndexEntry += records.sizeInBytes
}
}
下面这张图展示了 上述append 方法的完整执行流程:
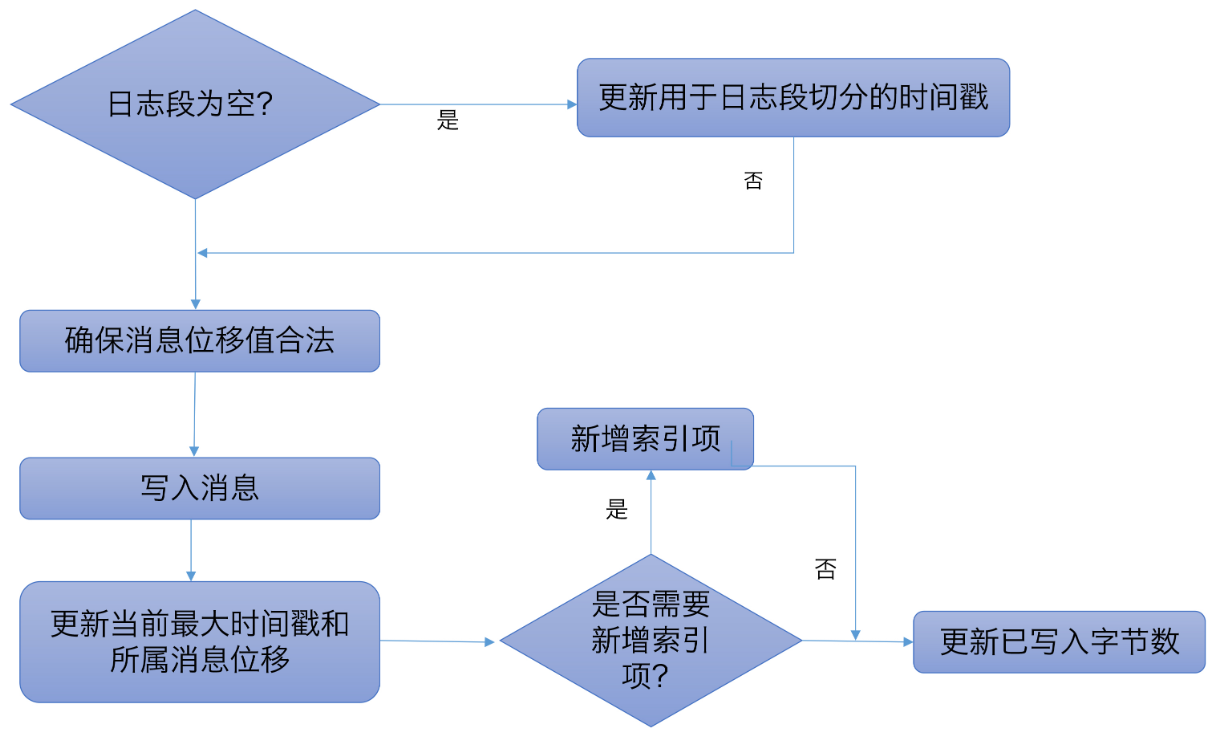
1.2 read读消息
LogSegment的read方法用来读消息,方法接收 4 个输入参数:
- startOffset:要读取的第一条消息的位移;
- maxSize:能读取的最大字节数;
- maxPosition :能读到的最大文件位置;
- minOneMessage:是否允许在消息体过大时至少返回第一条消息。
注意下第 4 个参数,当这个参数为 true 时,即使出现消息体字节数超过了 maxSize 的情形,read 方法依然会返回至少一条消息,这样可以确保不出现Consumer饥饿的情况:
// LogSegment.scala
def read(startOffset: Long, maxOffset: Option[Long], maxSize: Int, maxPosition: Long = size,
minOneMessage: Boolean = false): FetchDataInfo = {
if (maxSize < 0)
throw new IllegalArgumentException("Invalid max size for log read (%d)".format(maxSize))
// 1.定位要读取的起始文件位置, startOffset仅仅是位移值,Kafka 需要根据索引信息找到对应的物理文件位置才能开始读取消息
val logSize = log.sizeInBytes // this may change, need to save a consistent copy
val startOffsetAndSize = translateOffset(startOffset)
if (startOffsetAndSize == null)
return null
val startPosition = startOffsetAndSize.position.toInt
val offsetMetadata = new LogOffsetMetadata(startOffset, this.baseOffset, startPosition)
val adjustedMaxSize =
if (minOneMessage) math.max(maxSize, startOffsetAndSize.size)
else maxSize
// return a log segment but with zero size in the case below
if (adjustedMaxSize == 0)
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY)
// 2.计算要读取的总字节数
val length = maxOffset match {
case None =>
min((maxPosition - startPosition).toInt, adjustedMaxSize)
case Some(offset) =>
if (offset < startOffset)
return FetchDataInfo(offsetMetadata, MemoryRecords.EMPTY, firstEntryIncomplete = false)
val mapping = translateOffset(offset, startPosition)
val endPosition =
if (mapping == null)
logSize // the max offset is off the end of the log, use the end of the file
else
mapping.position
min(min(maxPosition, endPosition) - startPosition, adjustedMaxSize).toInt
}
// 3.从指定位置读取指定大小的消息集合
FetchDataInfo(offsetMetadata, log.read(startPosition, length),
firstEntryIncomplete = adjustedMaxSize < startOffsetAndSize.size)
}
1.3 recover恢复日志段
最后来看LogSegment的recover方法,这方法用于 恢复日志段 。Broker在启动时会从磁盘上加载所有日志段文件的信息到内存中,并创建对应的 LogSegment 对象,这个过程就是 recover :
// LogSegment.scala
def recover(maxMessageSize: Int): Int = {
// 1.清空所有的索引文件
index.truncate()
index.resize(index.maxIndexSize)
timeIndex.truncate()
timeIndex.resize(timeIndex.maxIndexSize)
var validBytes = 0
var lastIndexEntry = 0
maxTimestampSoFar = Record.NO_TIMESTAMP
try {
// 2.遍历日志段中的所有消息集合
for (entry <- log.shallowEntries(maxMessageSize).asScala) {
val record = entry.record
record.ensureValid()
if (record.timestamp > maxTimestampSoFar) {
maxTimestampSoFar = record.timestamp
offsetOfMaxTimestamp = entry.offset
}
// Build offset index
if(validBytes - lastIndexEntry > indexIntervalBytes) {
val startOffset = entry.firstOffset
index.append(startOffset, validBytes)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestamp)
lastIndexEntry = validBytes
}
validBytes += entry.sizeInBytes()
}
} catch {
case e: CorruptRecordException =>
logger.warn("Found invalid messages in log segment %s at byte offset %d: %s."
.format(log.file.getAbsolutePath, validBytes, e.getMessage))
}
val truncated = log.sizeInBytes - validBytes
log.truncateTo(validBytes)
index.trimToValidSize()
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestamp, skipFullCheck = true)
timeIndex.trimToValidSize()
truncated
}
二、总结
本章,我对LogSegment这个分段日志对象进行了讲解,我们需要重点关注它的append方法,也就是写日志的方法。LogSegment会判断每写入4KB消息,就写入一个稀疏索引。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
