前言
- 习惯用
Json、XML数据存储格式的你们,相信大多都没听过Protocol Buffer Protocol Buffer其实 是Google出品的一种轻量 & 高效的结构化数据存储格式,性能比Json、XML真的强!太!多!
由于
Protocol Buffer已经具备足够的吸引力
- 今天,我将讲解为什么
Protocol Buffer的性能如此的好:
a. 序列化速度 & 反序列化速度快
b. 数据压缩效果好,即序列化后的数据量体积小
目录

1. 定义
一种 结构化数据 的数据存储格式(类似于 XML、Json )
Protocol Buffer目前有两个版本:proto2和proto3- 因为
proto3还是beta 版,所以本次讲解是proto2
2. 作用
通过将 结构化的数据 进行 串行化( 序列化 ),从而实现 数据存储 / RPC 数据交换 的功能
- 序列化: 将 数据结构或对象 转换成 二进制串 的过程
- 反序列化:将在序列化过程中所生成的二进制串 转换成 数据结构或者对象 的过程
3. 特点
- 对比于 常见的
XML、Json数据存储格式,Protocol Buffer有如下特点:

4. 应用场景
传输数据量大 & 网络环境不稳定 的 数据存储、RPC 数据交换 的需求场景
如 即时IM (QQ、微信)的需求场景
总结
在 传输数据量较大 的需求场景下,Protocol Buffer比XML、Json 更小、更快、使用 & 维护更简单!
5. 使用流程
关于 Protocol Buffer 的使用流程,具体请看我写的文章:快来看看Google出品的Protocol Buffer,别只会用Json和XML了
6. 知识基础
6.1 网络通信协议
- 序列化 & 反序列化 属于通讯协议的一部分
- 通讯协议采用分层模型:
TCP/IP模型(四层) &OSI模型 (七层)

-
序列化 / 反序列化 属于
TCP/IP模型 应用层 和 OSI`模型 展示层的主要功能:- (序列化)把 应用层的对象 转换成 二进制串
- (反序列化)把 二进制串 转换成 应用层的对象
-
所以,
Protocol Buffer属于TCP/IP模型的应用层 &OSI模型的展示层
6.2 数据结构、对象与二进制串
不同的计算机语言中,数据结构,对象以及二进制串的表示方式并不相同。
a. 对于数据结构和对象
- 对于面向对象的语言(如
Java):对象 =Object= 类的实例化;在Java中最接近数据结构 即POJO(Plain Old Java Object),或Javabean(只有setter/getter方法的类) - 对于半面向对象的语言(如
C++),对象 =class,数据结构 =struct
b. 二进制串
- 对于
C++,因为具有内存操作符,所以 二进制串 容易理解:C++的字符串可以直接被传输层使用,因为其本质上就是以'\0'结尾的存储在内存中的二进制串 - 对于
Java,二进制串 = 字节数组 =byte[]
byte属于Java的八种基本数据类型- 二进制串 容易和
String混淆:String一种特殊对象(Object)。对于跨语言间的通讯,序列化后的数据当然不能是某种语言的特殊数据类型。
6.3 T - L - V 的数据存储方式
- 定义
即Tag - Length - Value, 标识 - 长度 - 字段值 存储方式 - 作用
以 标识 - 长度 - 字段值 表示单个数据,最终将所有数据拼接成一个 字节流 ,从而 实现 数据存储 的功能
其中
Length可选存储,如 储存Varint编码数据就不需要存储Length
- 示意图

-
优点
从上图可知,T - L - V存储方式的优点是- 不需要 分隔符 就能 分隔开 字段 ,减少了 分隔符 的使用
- 各字段 存储得非常紧凑,存储空间利用率非常高
- 若 字段没有被设置字段值,那么该字段在序列化时的数据中是完全不存在的,即不需要编码
相应字段在解码时才会被设置为默认值
7. 序列化原理解析
请记住Protocol Buffer的 三个关于数据存储 的重要结论:
- 结论1:
Protocol Buffer将 消息里的每个字段 进行编码后,再利用T - L - V存储方式 进行数据的存储,最终得到的是一个 二进制字节流
序列化 = 对数据进行编码 + 存储
-
结论2:
Protocol Buffer对于不同数据类型 采用不同的 序列化方式(编码方式 & 数据存储方式),如下图:
从上表可以看出:
- 对于存储
Varint编码数据,就不需要存储字节长度Length,所以实际上Protocol Buffer的存储方式是T - V; - 若
Protocol Buffer采用其他编码方式(如LENGTH_DELIMITED)则采用T - L - V
- 结论3:因为
Protocol Buffer对于数据字段值的 独特编码方式 &T - L - V数据存储方式 ,使得Protocol Buffer序列化后数据量体积如此小
下面,我将对不同的编码方式 & 数据存储方式进行逐一讲解。
7.1 Wire Type = 0时的编码 & 数据存储方式

7.1.1 编码方式: Varint & Zigzag
A. Varint编码方式介绍
i. 简介
- 定义:一种变长的编码方式
- 原理:用字节 表示 数字: 值越小的数字,使用越少的字节数表示
- 作用:通过减少 表示数字 的字节数 从而进行数据压缩
如:
- 对于
int32类型的数字,一般需要 4个字节 表示;
- 若采用
Varint编码,对于很小的int32类型 数字,则可以用 1个字节 来表示- 虽然大的数字会需要 5 个 字节 来表示,但大多数情况下,消息都不会有很大的数字,所以采用
Varint方法总是可以用更少的字节数来表示数字
ii. 原理介绍
- 源码分析
private void writeVarint32(int n) {
int idx = 0;
while (true) {
if ((n & ~0x7F) == 0) {
i32buf[idx++] = (byte)n;
break;
} else {
i32buf[idx++] = (byte)((n & 0x7F) | 0x80);
// 步骤1:取出字节串末7位
// 对于上述取出的7位:在最高位添加1构成一个字节
// 如果是最后一次取出,则在最高位添加0构成1个字节
n >>>= 7;
// 步骤2:通过将字节串整体往右移7位,继续从字节串的末尾选取7位,直到取完为止。
}
}
trans_.write(i32buf, 0, idx);
// 步骤3: 将上述形成的每个字节 按序拼接 成一个字节串
// 即该字节串就是经过Varint编码后的字节
}
从上面可看出:Varint 中每个 字节 的最高位 都有特殊含义:
- 如果是 1,表示后续的 字节 也是该数字的一部分
- 如果是 0,表示这是最后一个字节,且剩余 7位 都用来表示数字
所以,当使用
Varint解码时时,只要读取到最高位为0的字节时,就表示已经是Varint的最后一个字节
因此:
- 小于 128 的数字 都可以用 1个字节 表示;
- 大于 128 的数字,比如 300,会用两个字节来表示:10101100 00000010
下面,我将用两个个例子来说明Varint编码方式的使用
- 目的:对 数据类型为Int32 的 字段值为296 和字段值为104 进行
Varint编码 - 以下是编码过程

从上面可以看出:
- 对于 int32 类型的数字,一般需要 4 个字节 来表示;
- 但采用
Varint方法,对于很小的Int32类型 数字(小于256),则可以用 1个字节 来表示;
以此类推,比如300也只需要2个字节
- 虽然大的数字会需要 5 个字节 来表示,但大多数情况下,消息都不会有很大的数字
- 所以采用
Varint方法总是可以用更少的字节数来表示数字,从而更好地实现数据压缩
下面继续看如何解析经过Varint 编码的字节

Varint 编码方式的不足
- 背景:在计算机内,负数一般会被表示为很大的整数
因为计算机定义负数的符号位为数字的最高位
-
问题:如果采用
Varint编码方式 表示一个负数,那么一定需要 5 个 byte(因为负数的最高位是1,会被当做很大的整数去处理) -
解决方案:
Protocol Buffer定义了sint32 / sint64类型表示负数,通过先采用Zigzag编码(将 有符号数 转换成 无符号数),再采用Varint编码,从而用于减少编码后的字节数
- 对于
int32 / int64类型的字段值(正数),Protocol Buffer直接采用Varint编码- 对于
sint32 / sint64类型的字段值(负数),Protocol Buffer会先采用Zigzag编码,再采用Varint编码
- 总结:为了更好地减少 表示负数时 的字节数,
Protocol Buffer在Varint编码上又增加了Zigzag编码方式进行编码 - 下面将详细介绍
Zigzag编码方式
B. Zigzag编码方式详解
i. 简介
- 定义:一种变长的编码方式
- 原理:使用 无符号数 来表示 有符号数字;
- 作用:使得绝对值小的数字都可以采用较少 字节 来表示;
特别是对 表示负数的数据 能更好地进行数据压缩
b. 原理
- 源码分析
public int int_to_zigzag(int n)
// 传入的参数n = 传入字段值的二进制表示(此处以负数为例)
// 负数的二进制 = 符号位为1,剩余的位数为 该数绝对值的原码按位取反;然后整个二进制数+1
{
return (n <<1) ^ (n >>31);
// 对于sint 32 数据类型,使用Zigzag编码过程如下:
// 1. 将二进制表示数 左移1位(左移 = 整个二进制左移,低位补0)
// 2. 将二进制表示数 右移31位
// 对于右移:
// 首位是1的二进制(有符号数),是算数右移,即右移后左边补1
// 首位是0的二进制(无符号数),是逻辑左移,即右移后左边补0
// 3. 将上述二者进行异或
// 对于sint 64 数据类型 则为: return (n << 1> ^ (n >> 63) ;
}
// 附:将Zigzag值解码为整型值
public int zigzag_to_int(int n)
{
return(n >>> 1) ^ -(n & 1);
// 右移时,需要用不带符号的移动,否则如果第一位数据位是1的话,就会补1
}
- 实例说明:将
-2进行Zigzag编码:

Zigzag编码 是补充Varint编码在 表示负数 的不足,从而更好的帮助Protocol Buffer进行数据的压缩- 所以, 如果提前预知字段值是可能取负数的时候,记得采用
sint32 / sint64数据类型
总结
Protocol Buffer 通过Varint和Zigzag编码后大大减少了字段值占用字节数。
7.1.2 存储方式:T - V
- 消息字段的标识号、数据类型 & 字段值经过
Protocol Buffer采用Varint&Zigzag编码后,以T - V方式进行数据存储
对于
Varint&Zigzag编码,省略了T - L - V中的字节长度Length

下面将详细介绍T - V 存储方式中的存储细节:Tag & Value
1. Tag
- 定义:经过
Protocol Buffer采用Varint&Zigzag编码后 的消息字段 标识号 & 数据类型 的值 - 作用:标识 字段
- 存储了字段的标识号(
field_number)和 数据类型(wire_type),即Tag= 字段数据类型(wire_type) + 标识号(field_number)- 占用 一个字节 的长度(如果标识号超过了16,则占用多一个字节的位置)
- 解包时,
Protocol Buffer根据Tag将Value对应于消息中的 字段
- 具体使用
// Tag 的具体表达式如下
Tag = (field_number << 3) | wire_type
// 参数说明:
// field_number:对应于 .proto文件中消息字段的标识号,表示这是消息里的第几个字段
// field_number << 3:表示 field_number = 将 Tag的二进制表示 右移三位 后的值
// field_num左移3位不会导致数据丢失,因为表示范围还是足够大地去表示消息里的字段数目
// wire_type:表示 字段 的数据类型
// wire_type = Tag的二进制表示 的最低三位值
// wire_type的取值
enum WireType {
WIRETYPE_VARINT = 0,
WIRETYPE_FIXED64 = 1,
WIRETYPE_LENGTH_DELIMITED = 2,
WIRETYPE_START_GROUP = 3,
WIRETYPE_END_GROUP = 4,
WIRETYPE_FIXED32 = 5
};
// 从上面可以看出,`wire_type`最多占用 3位 的内存空间(因为 3位 足以表示 0-5 的二进制)
// 以下是 wire_type 对应的 数据类型 表

- 实例说明
// 消息对象
message person
{
required int32 id = 1;
// wire type = 0,field_number =1
required string name = 2;
// wire type = 2,field_number =2
}
// 如果一个Tag的二进制 = 0001 0010
标识号 = field_number = field_number << 3 =右移3位 = 0000 0010 = 2
数据类型 = wire_type = 最低三位表示 = 010 = 2
2. Value
经过 Protocol Buffer采用Varint & Zigzag编码后 的消息字段的值
7.1.3 实例说明
下面通过一个实例进行整个编码过程的说明:
- 消息说明
message Test
{
required int32 id1 = 1;
required int32 id2 = 2;
}
// 在代码中给id1 附上1个字段值:296
// 在代码中给id2 附上1个字段值:296
Test.setId1(300);
Test.setId2(296);
// 编码结果为:二进制字节流 = [8,-84,2,16, -88, 2]
- 整个编码过程如下

7.2 Wire Type = 1& 5时的编码&数据存储方式

64(32)-bit编码方式较简单:编码后的数据具备固定大小 = 64位(8字节) / 32位(4字节)
两种情况下,都是高位在后,低位在前
- 采用
T - V方式进行数据存储,同上。
7.3 Wire Type = 2时的 编码 & 数据存储方式

- 对于编码方式:
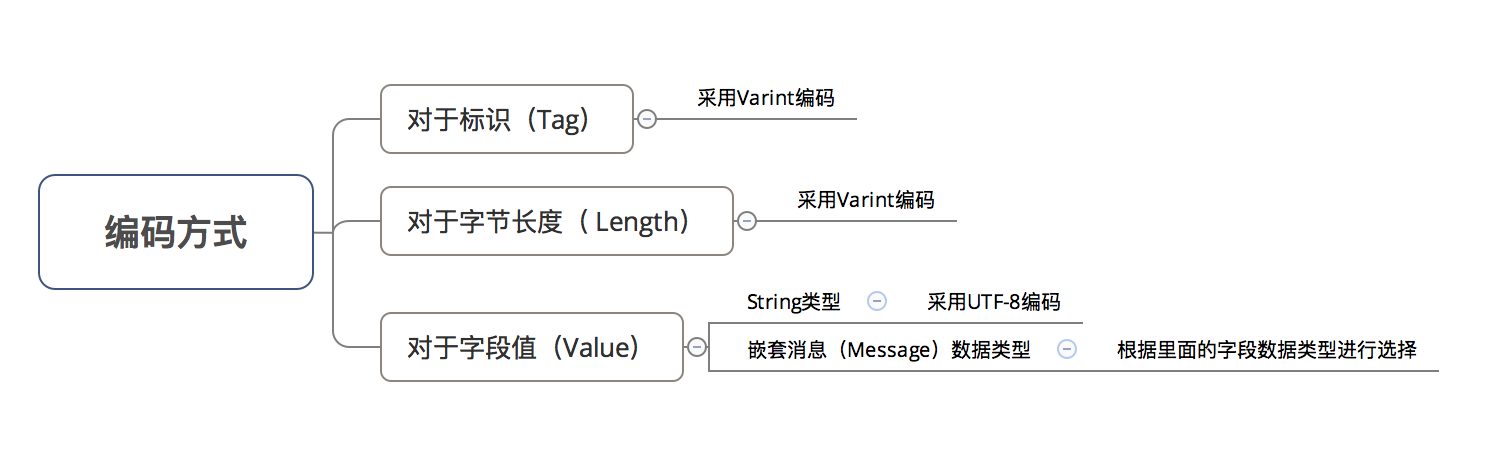
- 数据存储方式:
T - L - V

此处主要讲解三种数据类型:
String类型- 嵌套消息类型(
Message) - 通过
packed修饰的repeat字段(即packed repeated fields)
1. String类型
字段值(即V) 采用UTF-8编码

- 例子:
message Test2
{
required string str = 2;
}
// 将str设置为:testing
Test2.setStr(“testing”)
// 经过protobuf编码序列化后的数据以二进制的方式输出
// 输出为:18, 7, 116, 101, 115, 116, 105, 110, 103

2. 嵌套消息类型(Message)
- 存储方式:
T - L - V
- 外部消息的
V即为 嵌套消息的字段- 在
T - L -V里嵌套了一系列的T - L -V
- 编码方式:字段值(即
V) 根据字段的数据类型采用不同编码方式

- 实例
定义如下嵌套消息:
message Test2
{
required string str = 1;
required int32 id1 = 2;
}
message Test3 {
required Test2 c = 1;
}
// 将Test2中的字段str设置为:testing
// 将Test2中的字段id1设置为:296
// 编码后的字节为:10 ,12 ,18,7,116, 101, 115, 116, 105, 110, 103,16,-88,2
编码 & 存储方式如下

3. 通过packed修饰的 repeat 字段
repeated 修饰的字段有两种表达方式:
message Test
{
repeated int32 Car = 4 ;
// 表达方式1:不带packed=true
repeated int32 Car = 4 [packed=true];
// 表达方式2:带packed=true
// proto 2.1 开始可使用
// 区别在于:是否连续存储repeated类型数据
}
// 在代码中给`repeated int32 Car`附上3个字段值:3、270、86942
Test.setCar(3);
Test.setCar(270);
Test.setCar(86942);
- 背景:对于同一个
repeated字段、多个字段值来说,他们的Tag都是相同的,即数据类型 & 标识号都相同
repeated类型可以看成是数组
- 问题:若以传统的多个 T - V对存储(不带
packed=true),则会导致Tag的冗余,即相同的Tag存储多次;

- 解决方案:采用带
packed=true的repeated字段存储方式,即将相同的Tag只存储一次、添加repeated字段下所有字段值的长度Length、连续存储repeated字段值,组成一个大的Tag - Length - Value -Value -Value对,即T - L - V - V - V对。

通过采用带packed=true 的 repeated 字段存储方式,从而更好地压缩序列化后的数据长度。
特别注意
Protocol Buffer的packed修饰只用于repeated字段 或 基本类型的repeated字段- 用在其他字段,编译
.proto文件时会报错
8. 特别注意
- 注意1:若
required字段没有被设置字段值,那么在IsInitialized()进行初始化检查会报错并提示失败
所以
required字段必须要被设置字段值
- 注意2:序列化顺序 是根据
Tag标识号 从小到大 进行编码
和
.proto文件内 字段定义的数据无关
- 注意3:
T - V的数据存储方式保证了Protobuf的版本兼容:高<->低 或 低<->高都可以适配
若新版本 增加了
required字段, 旧版本 在数据解码时会认为IsInitialized()失败,所以慎用required字段
9. 使用建议
根据上面的序列化原理分析,我总结出以下Protocol Buffer的使用建议
通过下面建议能有效降低序列化后数据量的大小
- 建议1:多用
optional或repeated修饰符
因为若optional或repeated字段没有被设置字段值,那么该字段在序列化时的数据中是完全不存在的,即不需要进行编码
相应的字段在解码时才会被设置为默认值
- 建议2:字段标识号(
Field_Number)尽量只使用 1-15,且不要跳动使用
因为Tag里的Field_Number是需要占字节空间的。如果Field_Number>16时,Field_Number的编码就会占用2个字节,那么Tag在编码时也就会占用更多的字节;如果将字段标识号定义为连续递增的数值,将获得更好的编码和解码性能 - 建议3:若需要使用的字段值出现负数,请使用
sint32 / sint64,不要使用int32 / int64
因为采用sint32 / sint64数据类型表示负数时,会先采用Zigzag编码再采用Varint编码,从而更加有效压缩数据 - 建议4:对于
repeated字段,尽量增加packed=true修饰
因为加了packed=true修饰repeated字段采用连续数据存储方式,即T - L - V - V -V方式
10. 序列化 & 反序列化过程
Protocol Buffer除了序列化 & 反序列化后的数据体积小,序列化 & 反序列化的速度也非常快- 下面我将讲解序列化 & 反序列化的序列化过程
10.1 Protocol Buffer的序列化 & 反序列化过程
序列化过程如下:
- 判断每个字段是否有设置值,有值才进行编码
- 根据 字段标识号&数据类型 将 字段值 通过不同的编码方式进行编码
由于:
a. 编码方式简单(只需要简单的数学运算 = 位移等等)
b. 采用 Protocol Buffer 自身的框架代码 和 编译器 共同完成
所以Protocol Buffer的序列化速度非常快。
反序列化过程如下:
- 调用 消息类的
parseFrom(input)解析从输入流读入的二进制字节数据流
从上面可知,
Protocol Buffer解析过程只需要通过简单的解码方式即可完成,无需复杂的词法语法分析,因此 解析速度非常快。
- 将解析出来的数据 按照指定的格式读取到
Java、C++、Phyton对应的结构类型中
由于:
a. 解码方式简单(只需要简单的数学运算 = 位移等等)
b. 采用 Protocol Buffer 自身的框架代码 和 编译器 共同完成
所以Protocol Buffer的反序列化速度非常快。
10.2 对比于XML 的序列化 & 反序列化过程
XML的反序列化过程如下:
- 从文件中读取出字符串
- 将字符串转换为
XML文档对象结构模型 - 从
XML文档对象结构模型中读取指定节点的字符串 - 将该字符串转换成指定类型的变量
上述过程非常复杂,其中,将 XML 文件转换为文档对象结构模型的过程通常需要完成词法文法分析等大量消耗 CPU 的复杂计算。
因为序列化 & 反序列化过程简单,所以序列化 & 反序列化过程速度非常快,这也是 Protocol Buffer效率高的原因
11.总结
Protocol Buffer的序列化 & 反序列化简单 & 速度快的原因是:
a. 编码 / 解码 方式简单(只需要简单的数学运算 = 位移等等)
b. 采用Protocol Buffer自身的框架代码 和 编译器 共同完成Protocol Buffer的数据压缩效果好(即序列化后的数据量体积小)的原因是:
a. 采用了独特的编码方式,如Varint、Zigzag编码方式等等
b. 采用T - L - V的数据存储方式:减少了分隔符的使用 & 数据存储得紧凑
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
