回收器和对象池
回收器,就是来回收对象的,对象池,就是来存储对象复用的。为了跟对象池配合,使得对象池只是作为一个获取对象的实体,只要接受对象创建器即可,其他的不用管,而且将对象池如何存取的实现剥离到了回收器里,如果要改变具体存取方案,只要更换回收器即可,其实也是一种代理,设计很灵活。
ObjectPool
这个一看就知道是对象池,netty自己设计了一套对象池和回收器的机制,可以多线程回收,尽量避免线程竞争问题。我们先来看看他的对象池是怎么设计的。
get获得对象
是个抽象方法,就是获取T类型的对象。
public abstract T get();
Handle回收处理器接口
又定义了一个接口,也就是处理器。里面有个回收方法,就是将要回收的对象传进去。
public interface Handle<T> {
//回收
void recycle(T self);
}
ObjectCreator
对象创建接口,有个传入处理器的创建方法。
public interface ObjectCreator<T> {
//创建一个新的T类型的对象,传入处理器作为参数
T newObject(Handle<T> handle);
}
通过对象创建接口和处理器关联,以便于创建的的对象内部可以调用处理器的方法,用来回收对象。
RecyclerObjectPool
回收器对象池,实现了get方法,内部就是通过一个回收器来获得。同时构造方法传入一个对象创建实例,
private static final class RecyclerObjectPool<T> extends ObjectPool<T> {
private final Recycler<T> recycler;//回收器
RecyclerObjectPool(final ObjectCreator<T> creator) {
recycler = new Recycler<T>() {
@Override
protected T newObject(Handle<T> handle) {
return creator.newObject(handle);
}
};
}
@Override
public T get() {
return recycler.get();
}
}
newPool
这个才是提供给我们使用的方法,只需要传入一个对象创建器即可。
public static <T> ObjectPool<T> newPool(final ObjectCreator<T> creator) {
return new RecyclerObjectPool<T>(ObjectUtil.checkNotNull(creator, "creator"));
}
创建对象池
创建对象池很方便,比如下面的对象池,仅仅需要实现一个对象的创建方法即可,其他不用管。
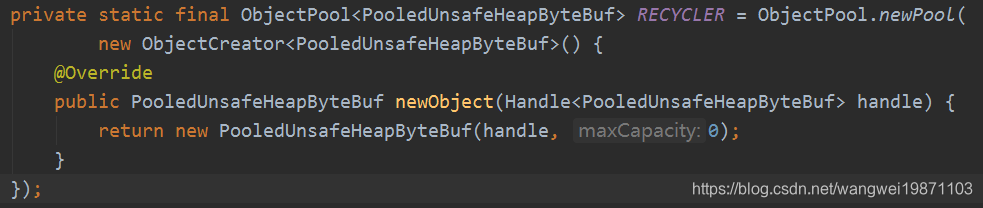
使用的时候只要:

回收的时候有个处理器Handle,这个交给回收器去创建了,不用管:

Recycler预备知识
主要还是回收器,我们来看看他做了什么。因为里面还是比较复杂的,所以先做点预备知识铺垫。
每个线程独立存取数据
多线程中每个线程都可能会有创建对象,释放对象,当他们创建的时候,首先会从当前线程本地变量中获取,这样做避免了多线程之间的竞争问题。每个线程都拥有一个特殊的栈Stack,一般情况下就是从Stack中获取,回收也是放这个里面回收,Stack内部是一个数组,用索引记录,存取非常快。

另一个就是一个Map,具体类型是WeakHashMap<Stack<?>, WeakOrderQueue>,他的键是弱引用,而且他是以键的引用地址来判断是不是同一个键。他将Stack和WeakOrderQueue对应起来了。
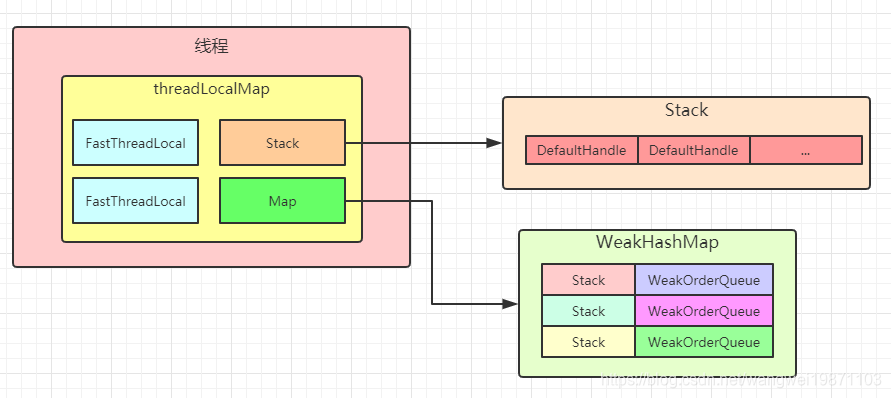
那什么是WeakOrderQueue呢,简单来说就是一个队列,这个队列里面也可以放回收的对象,前面不是已经有了Stack了么,干嘛要这个呢。因为涉及到多线程,为了不出现多线程同时去存取操作Stack而产生的竞争情况,就区分了当前线程是不是Stack的拥有线程,如果是,就直接放回到Stack中,如果不是,就放入对应的WeakOrderQueue中,前面说了Stack和WeakOrderQueue有对应关系。而且多个线程中都可能有同一个Stack的不同WeakOrderQueue。他们之间是用单链表连起来的。大致关系就像这样:
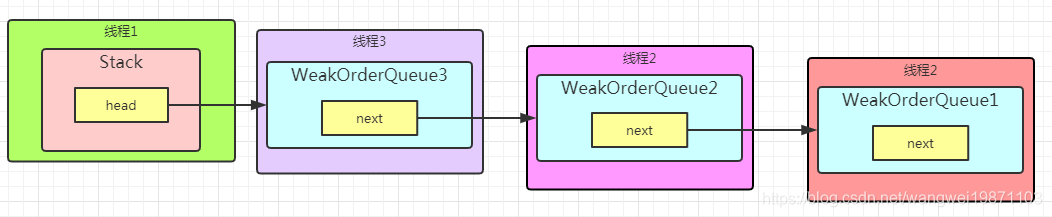
WeakOrderQueue大致结构
而WeakOrderQueue内部使用Link类型的链表连接起来的,Link内部也是数组。
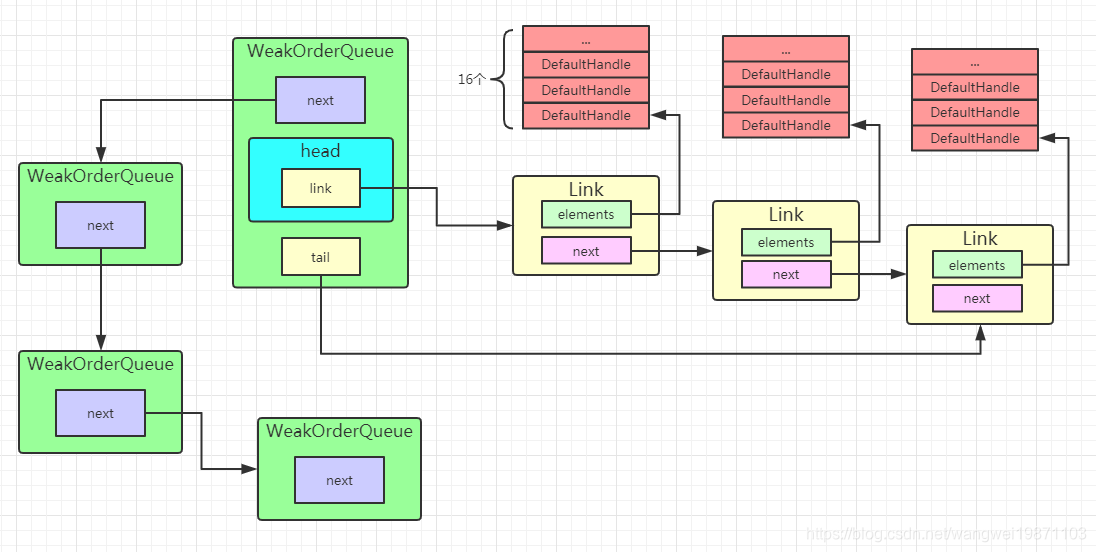
Stack大致结构
其实结构都还挺清晰的,主要的还是数组,单链表。
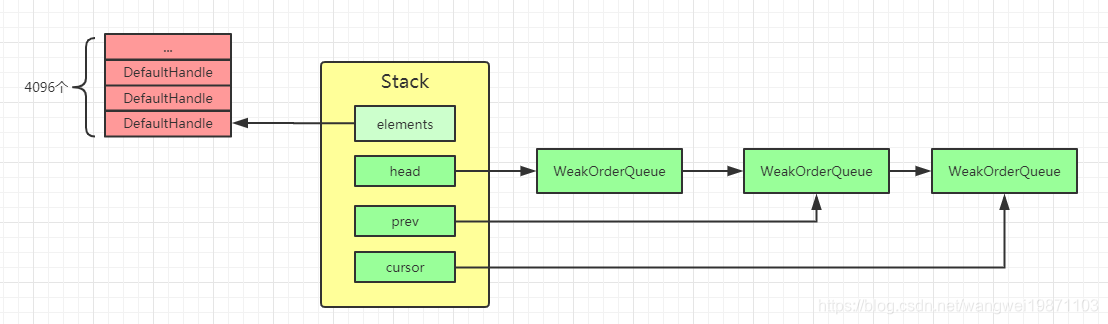
DefaultHandle
这个就是处理器,实现了Handle接口,主要是处理回收的,主要的方法就是recycle,主要的代码贴出来了,其实就是入栈:
@Override
public void recycle(Object object) {
...
Stack<?> stack = this.stack;
...
stack.push(this);//入栈
}
一些基本操作
收回操作
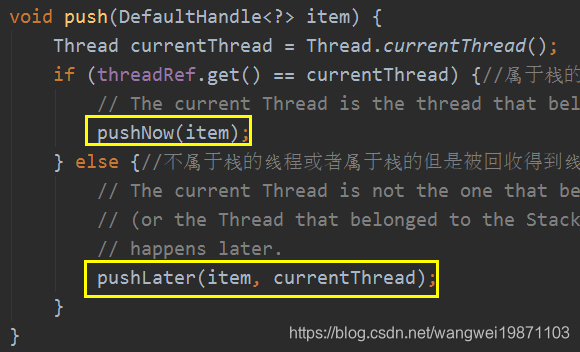
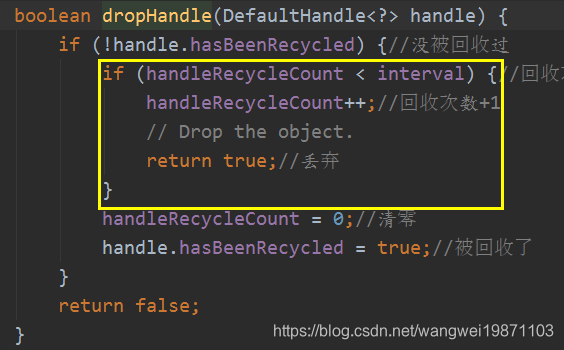
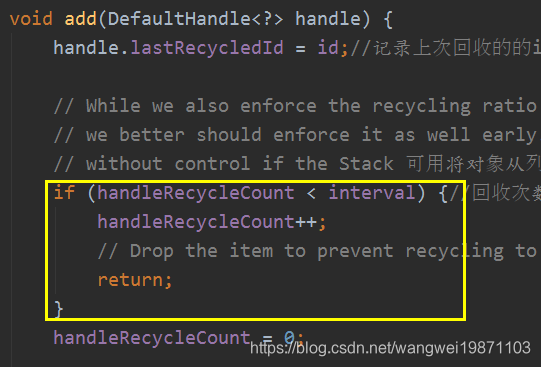
回收操作分成当前线程是否是Stack所属线程,如果是,就放入elements数组中。否则就放入另一个线程的本地变量WeakHashMap中,以创建<Stack<?>, WeakOrderQueue>键值对,主要还是创建WeakOrderQueue,然后将WeakOrderQueue加入Stack的单链表中,这样使得多个其他线程的WeakOrderQueue和所属线程的Stack有关联。WeakOrderQueue里面创建Link链接对象,将回收对象放入Link对象的elements数组中。而且数组的操作全部使用额外的索引,只需要移动索引进行操作,不需要因为增加删除元素而移动数组元素,所以性能非常高,而且无论Stack还是WeakOrderQueue内部还有间隔回收的限制,不是说放进来就要的,有一定个数间隔的,默认间隔是8,也就是除了第一次直接回收,后面每来9个,回收1个,比如来了10个,只有第1个和第10个被回收,中间8个全部不管,等着GC去回收了。
Stack的:
WeakOrderQueue的:
获取操作
这个是单线程的操作,每个线程都会从自己的线程本地变量Stack中获取,如果elements数组中有,就从这里取,如果没有,就尝试从Stack连接的WeakOrderQueue取,每次取一个Link,但是可能就回收2个,因为回收有间隔,就算一个Link中的16个对象都拿出来,也就2个能被回收。其中涉及到的细节后面一篇会说到。
为什么要用WeakOrderQueue而不是直接存到Stack
如果将对象直接存到不是所属线程的Stack的话,就可能会出现一个线程不停的创建对象,一个线程不停的回收对象,没有任何复用的地方,因为两个Stack不同,所以中间使用了WeakOrderQueue,暂时存这里,所属Stack没有的时候,从其他线程中关联的WeakOrderQueue中拿。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
