redis 是内存数据库,可以通过 redis.conf 配置 maxmemory,限制 redis 内存使用量。当 redis 主库内存超出限制时,命令处理将会触发数据淘汰机制,淘汰(key-value)数据,直至当前内存使用量小于限制阈值。
1. 数据淘汰策略概述
redis.conf
| 配置 | 描述 |
|---|---|
| maxmemory | 将内存使用限制设置为指定的字节数。 |
redis 申请和回收内存基本上都是通过 zmalloc 接口统一管理的,可以通过接口统计 redis 的内存使用量。当 redis 超出了内存的使用限制 maxmemory,服务在处理命令时会触发 redis 内部的数据淘汰机制。淘汰目标数据一共有两种:
- 数据库所有(
key-value)数据。 - 数据库所有被设置了过期时间的(key-value)数据。
aof 缓存,主从同步的积压缓冲区这些数据是不会被淘汰的,也没有计算在 maxmemory 里面。
针对这两种目标数据,它有几种淘汰策略:
- 随机淘汰。
- 先淘汰到期或快到期数据。
- 近似 LRU 算法(最近最少使用)
- 近似 LFU 算法 (最近使用频率最少)
关于近似的 lru 和 lfu 淘汰策略,英文好的朋友,可以去看看 antirez 的这两篇文章: Using Redis as an LRU cache, Random notes on improving the Redis LRU algorithm ,redis.conf 也有不少阐述。再结合源码,基本能理解它们的实现思路。
maxmemory 核心数据淘汰策略在函数 freeMemoryIfNeeded 中,可以仔细阅读这个函数的源码。
2. 配置
当 redis.conf 配置了 maxmemory,可以根据配置采用相应的数据淘汰策略。volatile-xxx 这种类型配置,都是只淘汰设置了过期时间的数据,allkeys-xxx 淘汰数据库所有数据。如果 redis 在你的应用场景中,只是作为缓存,任何数据都可以淘汰,可以设置 allkeys-xxx。
| 配置 | 描述 |
|---|---|
| noeviction | 不要淘汰任何数据,大部分写操作会返回错误。 |
| volatile-random | 随机删除设置了过期时间的键。 |
| allkeys-random | 删除随机键,任何键。 |
| volatile-ttl | 删除最接近到期时间(较小的TTL)的键。 |
| volatile-lru | 使用近似的LRU淘汰数据,仅设置过期的键。 |
| allkeys-lru | 使用近似的LRU算法淘汰长时间没有使用的键。 |
| volatile-lfu | 在设置了过期时间的键中,使用近似的LFU算法淘汰使用频率比较低的键。 |
| allkeys-lfu | 使用近似的LFU算法淘汰整个数据库的键。 |
#define MAXMEMORY_FLAG_LRU (1<<0)
#define MAXMEMORY_FLAG_LFU (1<<1)
#define MAXMEMORY_FLAG_ALLKEYS (1<<2)
#define MAXMEMORY_VOLATILE_LRU ((0<<8)|MAXMEMORY_FLAG_LRU)
#define MAXMEMORY_VOLATILE_LFU ((1<<8)|MAXMEMORY_FLAG_LFU)
#define MAXMEMORY_VOLATILE_TTL (2<<8)
#define MAXMEMORY_VOLATILE_RANDOM (3<<8)
#define MAXMEMORY_ALLKEYS_LRU ((4<<8)|MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_ALLKEYS)
#define MAXMEMORY_ALLKEYS_LFU ((5<<8)|MAXMEMORY_FLAG_LFU|MAXMEMORY_FLAG_ALLKEYS)
#define MAXMEMORY_ALLKEYS_RANDOM ((6<<8)|MAXMEMORY_FLAG_ALLKEYS)
#define MAXMEMORY_NO_EVICTION (7<<8)
3. 数据淘汰时机
在事件循环处理命令时触发检查
int processCommand(client *c) {
...
if (server.maxmemory && !server.lua_timedout) {
int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
if (server.current_client == NULL) return C_ERR;
if (out_of_memory &&
(c->cmd->flags & CMD_DENYOOM ||
(c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand &&
c->cmd->proc != discardCommand)))
{
flagTransaction(c);
addReply(c, shared.oomerr);
return C_OK;
}
}
...
}
int freeMemoryIfNeededAndSafe(void) {
if (server.lua_timedout || server.loading) return C_OK;
return freeMemoryIfNeeded();
}
4. 数据淘汰策略
下面从简单到复杂,说说这几种策略。
4.1. 不淘汰数据(noeviction)
超出内存限制,可以淘汰数据,当然也可以不使用淘汰策略淘汰数据,noeviction 配置允许我们这样做。服务允许读,但禁止大部分写命令,返回 oomerr 错误。只有少数写命令可以执行,例如删除命令 del,hdel,unlink 这些 能降低内存使用的写命令 。
- 32 位系统,如果没有设置 maxmemory,系统默认最大值是
3G,过期淘汰策略是:MAXMEMORY_NO_EVICTION
64 位系统不设置 maxmemory,是没有限制的,Linux 以及其它很多系统通过虚拟内存管理物理内存,进程可以使用超出物理内存大小的内存,只是那个时候,物理内存和磁盘间频繁地 swap,导致系统性能下降,对于 redis 这种高性能内存数据库,这不是一个友好的体验。
void initServer(void) {
...
if (server.arch_bits == 32 && server.maxmemory == 0) {
serverLog(LL_WARNING,"Warning: 32 bit instance detected but no memory limit set. Setting 3 GB maxmemory limit with 'noeviction' policy now.");
server.maxmemory = 3072LL*(1024*1024); /* 3 GB */
server.maxmemory_policy = MAXMEMORY_NO_EVICTION;
}
...
}
- 服务禁止大部分
写命令
int processCommand(client *c) {
...
if (server.maxmemory && !server.lua_timedout) {
// 当内存超出限制,进行回收处理。
int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
/* freeMemoryIfNeeded may flush slave output buffers. This may result
* into a slave, that may be the active client, to be freed. */
if (server.current_client == NULL) return C_ERR;
/* It was impossible to free enough memory, and the command the client
* is trying to execute is denied during OOM conditions or the client
* is in MULTI/EXEC context? Error. */
// 内存回收后,还是办法将内存减少到限制以下,那么大部分写命令将会被禁止执行。
if (out_of_memory &&
(c->cmd->flags & CMD_DENYOOM ||
(c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand &&
c->cmd->proc != discardCommand)))
{
flagTransaction(c);
addReply(c, shared.oomerr);
return C_OK;
}
}
...
}
int freeMemoryIfNeededAndSafe(void) {
if (server.lua_timedout || server.loading) return C_OK;
return freeMemoryIfNeeded();
}
int freeMemoryIfNeeded(void) {
...
if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)
goto cant_free; /* We need to free memory, but policy forbids. */
...
cant_free:
...
return C_ERR;
}
- CMD_DENYOOM 命令属性(use-memory)
int populateCommandTableParseFlags(struct redisCommand *c, char *strflags) {
...
for (int j = 0; j < argc; j++) {
...
else if (!strcasecmp(flag,"use-memory")) {
c->flags |= CMD_DENYOOM;
}
...
}
...
}
struct redisCommand redisCommandTable[] = {
...
{"get",getCommand,2,
"read-only fast @string",
0,NULL,1,1,1,0,0,0},
/* Note that we can't flag set as fast, since it may perform an
* implicit DEL of a large key. */
{"set",setCommand,-3,
"write use-memory @string",
0,NULL,1,1,1,0,0,0},
{"setnx",setnxCommand,3,
"write use-memory fast @string",
0,NULL,1,1,1,0,0,0},
...
{"del",delCommand,-2,
"write @keyspace",
0,NULL,1,-1,1,0,0,0},
{"unlink",unlinkCommand,-2,
"write fast @keyspace",
0,NULL,1,-1,1,0,0,0},
...
};
4.2. 随机淘汰
volatile-random,allkeys-random 这两个随机淘汰机制相对比较简单,也比较暴力,随机从库中挑选数据进行淘汰。
int freeMemoryIfNeeded(void) {
...
/* volatile-random and allkeys-random policy */
else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM)
{
/* When evicting a random key, we try to evict a key for
* each DB, so we use the static 'next_db' variable to
* incrementally visit all DBs. */
for (i = 0; i < server.dbnum; i++) {
j = (++next_db) % server.dbnum;
db = server.db+j;
dict = (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM) ?
db->dict : db->expires;
if (dictSize(dict) != 0) {
de = dictGetRandomKey(dict);
bestkey = dictGetKey(de);
bestdbid = j;
break;
}
}
}
...
}
4.3. 采样淘汰
redis 作为一个数据库,里面保存了大量数据,可以根据到期时间(ttl),lru 或 lfu 进行数据淘汰,严格来说,需要维护一些数据结构才能准确筛选出目标数据,但是 maxmemory 触发的概率比较低,小系统有可能永远不会触发。为了一个概率低的场景去维护一些数据结构,这显然不是一个聪明的做法。所以 redis 通过采样的方法,近似的数据淘汰策略。
采样方法:遍历数据库,每个数据库随机采集maxmemory_samples个样本,放进一个样本池中(数组)。样本池中的样本 idle 值从低到高排序(数组从左到右存储),数据淘汰策略将会每次淘汰 idle 最高的那个数据。因为样本池大小是有限制的(EVPOOL_SIZE),所以采集的样本要根据自己的 idle 值大小或池中是否有空位来确定是否能成功插入到样本池中。如果池中没有空位或被插入样本的idle 值都小于池子中的数据,那插入将会失败。 所以池子中一直存储着idle最大,最大几率被淘汰的那些数据样本 。
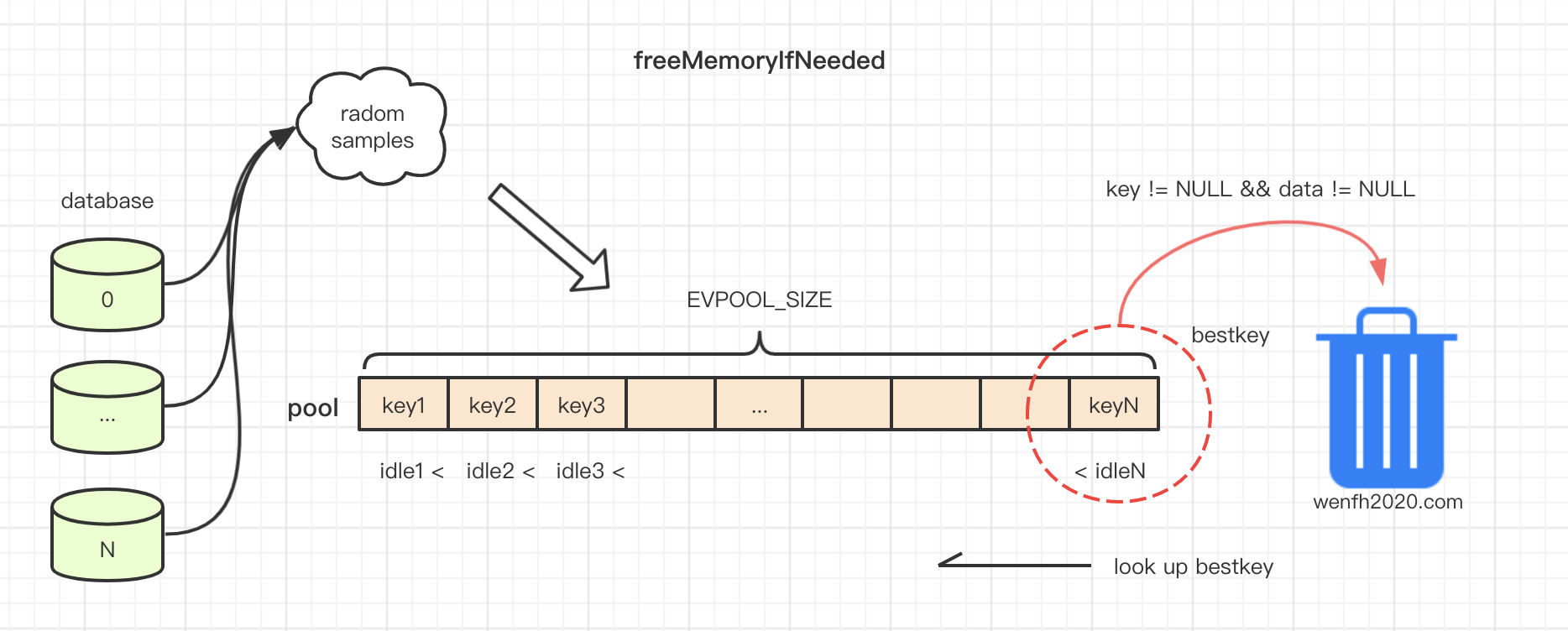
对于样本,显然是采样越多,筛选目标数据就越精确。redis 作者根据实践经验,maxmemory_samples 默认每次采样 5 个已经比较高效了,10 个就非常接近 LRU 算法效果。例如下图近似 lru 算法:
图 1 是正常的 LRU 算法。
- 浅灰色表示已经删除的键。
- 深灰色表示没有被删除的键。
- 绿色表示新加入的键。

- 样本数据池
#define EVPOOL_SIZE 16
#define EVPOOL_CACHED_SDS_SIZE 255
struct evictionPoolEntry {
unsigned long long idle; /* Object idle time (inverse frequency for LFU) */
sds key; /* Key name. */
sds cached; /* Cached SDS object for key name. */
int dbid; /* Key DB number. */
};
static struct evictionPoolEntry *EvictionPoolLRU;
void evictionPoolAlloc(void) {
struct evictionPoolEntry *ep;
int j;
ep = zmalloc(sizeof(*ep)*EVPOOL_SIZE);
for (j = 0; j < EVPOOL_SIZE; j++) {
ep[j].idle = 0;
ep[j].key = NULL;
ep[j].cached = sdsnewlen(NULL,EVPOOL_CACHED_SDS_SIZE);
ep[j].dbid = 0;
}
EvictionPoolLRU = ep;
}
- 采样淘汰机制实现,扫描数据库,从样本池中取出淘汰键
bestkey进行淘汰。
int freeMemoryIfNeeded(void) {
...
while (mem_freed < mem_tofree) {
...
// 采样,从样本中选出一个合适的键,进行数据淘汰。
if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL)
{
struct evictionPoolEntry *pool = EvictionPoolLRU;
while(bestkey == NULL) {
unsigned long total_keys = 0, keys;
// 将采集的键放进 pool 中。
for (i = 0; i < server.dbnum; i++) {
db = server.db+i;
// 从过期键中扫描,还是全局键扫描抽样。
dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ?
db->dict : db->expires;
if ((keys = dictSize(dict)) != 0) {
// 采样到样本池中
evictionPoolPopulate(i, dict, db->dict, pool);
total_keys += keys;
}
}
if (!total_keys) break; /* No keys to evict. */
// 从数组高到低,查找键进行数据淘汰
for (k = EVPOOL_SIZE-1; k >= 0; k--) {
if (pool[k].key == NULL) continue;
bestdbid = pool[k].dbid;
if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) {
de = dictFind(server.db[pool[k].dbid].dict,
pool[k].key);
} else {
de = dictFind(server.db[pool[k].dbid].expires,
pool[k].key);
}
/* Remove the entry from the pool. */
if (pool[k].key != pool[k].cached)
sdsfree(pool[k].key);
pool[k].key = NULL;
pool[k].idle = 0;
/* If the key exists, is our pick. Otherwise it is
* a ghost and we need to try the next element. */
if (de) {
bestkey = dictGetKey(de);
break;
} else {
/* Ghost... Iterate again. */
}
}
}
}
...
}
}
- 采样到样本池中
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
int j, k, count;
dictEntry *samples[server.maxmemory_samples];
// 随机采样多个数据。
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
for (j = 0; j < count; j++) {
...
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
// lru 近似算法,淘汰长时间没有使用的数据。
idle = estimateObjectIdleTime(o);
} else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
// 淘汰使用频率比较小的数据。
idle = 255-LFUDecrAndReturn(o);
} else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
// 淘汰最快过期数据。
idle = ULLONG_MAX - (long)dictGetVal(de);
} else {
serverPanic("Unknown eviction policy in evictionPoolPopulate()");
}
// 将采集的 key,填充到 pool 数组中去。
// 在 pool 数组中,寻找合适到位置。pool[k].key == NULL 或者 idle < pool[k].idle
k = 0;
while (k < EVPOOL_SIZE &&
pool[k].key &&
pool[k].idle < idle) k++;
if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) {
// pool 已满,当前采样没能找到合适位置插入。
continue;
} else if (k < EVPOOL_SIZE && pool[k].key == NULL) {
// 找到合适位置插入,不需要移动数组其它元素。
} else {
// 找到数组中间位置,需要移动数据。
if (pool[EVPOOL_SIZE-1].key == NULL) {
// 数组还有空间,数据从插入位置向右移动。
sds cached = pool[EVPOOL_SIZE-1].cached;
memmove(pool+k+1,pool+k,
sizeof(pool[0])*(EVPOOL_SIZE-k-1));
pool[k].cached = cached;
} else {
// 数组右边已经没有空间,那么删除 idle 最小的元素。
k--;
sds cached = pool[0].cached;
if (pool[0].key != pool[0].cached) sdsfree(pool[0].key);
memmove(pool,pool+1,sizeof(pool[0])*k);
pool[k].cached = cached;
}
}
// 内存的分配和销毁开销大,pool 缓存空间比较小的 key,方便内存重复使用。
int klen = sdslen(key);
if (klen > EVPOOL_CACHED_SDS_SIZE) {
pool[k].key = sdsdup(key);
} else {
memcpy(pool[k].cached,key,klen+1);
sdssetlen(pool[k].cached,klen);
pool[k].key = pool[k].cached;
}
pool[k].idle = idle;
pool[k].dbid = dbid;
}
}
4.3.1. 淘汰快到期数据(volatile-ttl)
- 数据库
redisDb用expires字典保存了 key 对应的过期时间。
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
...
} redisDb;
volatile-ttl淘汰那些设置了过期时间且最快到期的数据。随机采样放进样本池,从样本池中先淘汰 idle 值最大数据。
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
...
else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) {
// (long)dictGetVal(de) 时间越小,越快到期;idle 越大,越容易从样本池中淘汰。
idle = ULLONG_MAX - (long)dictGetVal(de);
}
...
}
4.3.2. lru
缓存目的是缓存活跃数据,volatile-ttl 淘汰最快到期的数据,存在缺陷:有可能把活跃的数据先淘汰了,可以采用 allkeys-lru 和 volatile-lru 策略,根据当前时间与上一次访问的时间间隔,间隔越小说明越活跃。通过采样,用近似 lru 算法淘汰那些很久没有使用的数据。
简单的 lru 实现可以看看我这个帖子 lru c++ 实现
redisObject成员lru保存了一个 24 bit 的系统访问数据时间戳。保存 lru 时间精度是秒,LRU_CLOCK_MAX时间范围大概 194 天。
#define LRU_BITS 24
#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value of obj->lru */
#define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
- 访问对应数据时,更新 lru 时间。
/* Low level key lookup API, not actually called directly from commands
* implementations that should instead rely on lookupKeyRead(),
* lookupKeyWrite() and lookupKeyReadWithFlags(). */
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
/* Update the access time for the ageing algorithm.
* Don't do it if we have a saving child, as this will trigger
* a copy on write madness. */
// 当主进程 fork 子进程处理数据时,不要更新。
// 否则父子进程 `copy-on-write` 模式将被破坏,产生大量新增内存。
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
// 更新 lru 时间
val->lru = LRU_CLOCK();
}
}
return val;
} else {
return NULL;
}
}
- 近似 lru 淘汰长时间没使用数据。
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
...
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
// lru 近似算法,淘汰长时间没有使用的数据。
idle = estimateObjectIdleTime(o);
}
...
}
- 返回当前时间与上一次访问时间间距。间隔越小,说明越活跃。(时间精度毫秒)
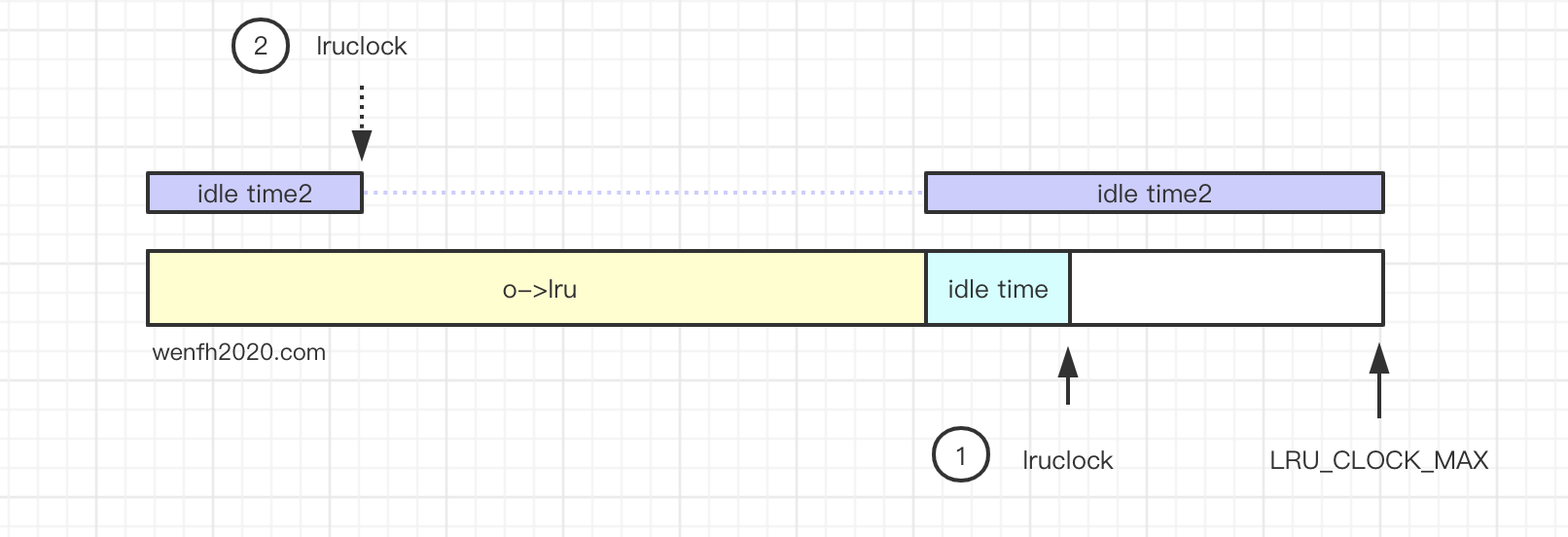
unsigned long long estimateObjectIdleTime(robj *o) {
unsigned long long lruclock = LRU_CLOCK();
if (lruclock >= o->lru) {
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
} else {
return (lruclock + (LRU_CLOCK_MAX - o->lru)) *
LRU_CLOCK_RESOLUTION;
}
}
4.3.3. lfu
近似 lru 淘汰策略,似乎要比前面讲的策略都要先进,但是它也是有缺陷的。因为根据当前时间与上一次访问时间两个时间点间隔来判断数据是否活跃。也只能反映两个时间点的活跃度。对于一段时间内的活跃度是很难反映出来的。
在同一个时间段内,B 的访问频率明显要比 A 高,显然 B 要比 A 热度更高。然而 lru 算法会把 B 数据淘汰掉。
~~~~~A~~~~~A~~~~~A~~~~A~~~~~A~~~~A~A~|
~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~~B~|
所以 redis 作者又引入了一种新的算法,近似 lfu 算法,反映数值访问频率,也就是数据访问热度。它重复利用了 redisObject 结构 lru 成员。
typedef struct redisObject {
...
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
...
} robj;
# 16 bits 8 bits
# +----------------+--------+
# + Last decr time | LOG_C |
# +----------------+--------+
前 16 bits 用来存储上一个访问衰减时间(ldt),后 8 bits 用来存储衰减计数频率(counter)。那衰减时间和计数到底有什么用呢? 其实是在一个时间段内,访问频率越高,计数就越大(计数最大值为 255)。我们通过计数的大小判断数据的热度。
- 近似 lfu 淘汰使用频率比较低的数据。
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) {
...
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) {
// 淘汰使用频率比较小的数据。
idle = 255-LFUDecrAndReturn(o);
}
...
}
- 当前时间与上次访问的时间间隔,时间精度是分钟。
unsigned long LFUTimeElapsed(unsigned long ldt) {
unsigned long now = LFUGetTimeInMinutes();
if (now >= ldt) return now-ldt;
return 65535-ldt+now;
}
unsigned long LFUGetTimeInMinutes(void) {
return (server.unixtime/60) & 65535;
}
-
衰减计数
LFUTimeElapsed 值越大,counter 就越小。也就是说,两次访问的时间间隔越大,计数的递减就越厉害。这个递减速度会受到衰减时间因子(
lfu_decay_time)影响。可以在配置文件中调节,一般默认为 1。
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8;
unsigned long counter = o->lru & 255;
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
- 访问触发频率更新,更新 lfu 数据
robj *lookupKey(redisDb *db, robj *key, int flags) {
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
robj *val = dictGetVal(de);
if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
// 更新频率
updateLFU(val);
} else {
val->lru = LRU_CLOCK();
}
}
return val;
} else {
return NULL;
}
}
// 更新 lfu 数据
void updateLFU(robj *val) {
// LFUDecrAndReturn 的时间精度是分钟,所以只会每分钟更新一次 counter.
unsigned long counter = LFUDecrAndReturn(val);
// 实时更新当前 counter
counter = LFULogIncr(counter);
// 保存 lfu 数据。
val->lru = (LFUGetTimeInMinutes()<<8) | counter;
}
-
计数器统计访问频率
这其实是一个概率计算,当数据被访问次数越多,那么随机数落在某个数据段的概率就越大。计数增加的可能性就越高。 redis 作者添加了控制因子 lfu_log_factor,当因子越大,那计数增长速度就越缓慢。
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
double r = (double)rand()/RAND_MAX;
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
return counter;
}
- 数据库新增数据默认计数为
LFU_INIT_VAL,这样不至于刚添加进来就被淘汰了。
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
...
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
}
...
}
下面是 redis 作者压力测试得出的 factor 和 counter 测试数据。因子越大,counter 增长越缓慢。
测试数据来自 redis.conf
# +--------+------------+------------+------------+------------+------------+
# | factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits |
# +--------+------------+------------+------------+------------+------------+
# | 0 | 104 | 255 | 255 | 255 | 255 |
# +--------+------------+------------+------------+------------+------------+
# | 1 | 18 | 49 | 255 | 255 | 255 |
# +--------+------------+------------+------------+------------+------------+
# | 10 | 10 | 18 | 142 | 255 | 255 |
# +--------+------------+------------+------------+------------+------------+
# | 100 | 8 | 11 | 49 | 143 | 255 |
# +--------+------------+------------+------------+------------+------------+
#
# NOTE: The above table was obtained by running the following commands:
#
# redis-benchmark -n 1000000 incr foo
# redis-cli object freq foo
5. 总结
-
maxmemory 淘汰数据机制,主要淘汰两种目标数据:整个数据库数据和设置了过期时间的数据。
-
maxmemory 淘汰策略,有:不使用淘汰策略淘汰数据,随机淘汰数据,采样的近似算法
ttl,lru,lfu。 -
redis 版本从 2.x 到 6.x,一直不停地改进迭代,redis 作者精益求精的精神值得我们学习。
-
采样近似淘汰策略,巧妙避免了维护额外的数据结构,达到差不多的效果,这个思路独具匠心。
-
采样算法,根据样本的 idle 值进行数据淘汰,所以当我们采用一种采样算法时,不要密集地设置大量相似的 idle 数据,否则效率也是很低的。
-
maxmemory 设置其实是一个学问,到底应该设置多少,才比较合理。很多人建议是物理内存大小的一半,原因如下:
- 主从复制,全量复制场景,slave 从 master 接收 rdb 文件进行加载,在这个操作前 slave 可能会异步释放原有内存数据,所以 slave 有可能同时存在两份数据。
- 数据持久化过程中,redis 会 fork 子进程,在 linux 系统中虽然父子进程有 ‘copy-on-write’ 模式,redis 也尽量避免子进程工作过程中修改数据,子进程部分操作会使用内存,例如写 rdb 文件。
- maxmemory 限制的内存并不包括
aof缓存和主从同步积压缓冲区部分内存。 - 我们的机器很多时候不是只跑 redis 进程的,系统其它进程也要使用内存。
-
maxmemory 虽然有众多的处理策略,然而超过阈值运行,这是不健康的,生产环境应该实时监控程序运行的健康状况。
-
redis 经常作为缓存使用,其实它也有持久化,可以存储数据。redis 作为缓存和数据库一般都是交叉使用,没有明确的界限,所以不建议设置
allkeys-xxx全局淘汰数据的策略。 -
当redis 内存到达 maxmemory,触发了数据淘汰,但是一顿操作后,内存始终无法成功降到阈值以下,那么 redis 主进程将会进入睡眠等待。这种问题是隐性的,很难查出来。新手很容易犯错误,经常把 redis 当做数据库使用,并发量高的系统,一段时间就跑满内存了,没经验的运维肯定第一时间想到切换到好点的机器解决问题。
int freeMemoryIfNeeded(void) {
...
cant_free:
// 如果已经没有合适的键进行回收了,而且内存还没降到 maxmemory 以下,
// 那么需要看看回收线程中是否还有数据需要进行回收,通过 sleep 主线程等待回收线程处理。
while(bioPendingJobsOfType(BIO_LAZY_FREE)) {
if (((mem_reported - zmalloc_used_memory()) + mem_freed) >= mem_tofree)
break;
usleep(1000);
}
return C_ERR;
}
6. 参考
- [redis 源码走读] 字典(dict)
- Using Redis as an LRU cache
- Random notes on improving the Redis LRU algorithm
- Redis的缓存淘汰策略LRU与LFU
- redis 过期策略及内存回收机制
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
