一、LinkedTransferQueue简介
LinkedTransferQueue是在JDK1.7时,J.U.C包新增的一种比较特殊的阻塞队列,它除了具备阻塞队列的常用功能外,还有一个比较特殊的transfer方法。
我们知道,在普通阻塞队列中,当队列为空时,消费者线程(调用 take 或 poll 方法的线程)一般会阻塞等待生产者线程往队列中存入元素。而 LinkedTransferQueue 的 transfer 方法则比较特殊:
- 当有消费者线程阻塞等待时,调用transfer方法的生产者线程不会将元素存入队列,而是直接将元素传递给消费者;
- 如果调用transfer方法的生产者线程发现没有正在等待的消费者线程,则会将元素入队,然后会阻塞等待,直到有一个消费者线程来获取该元素。

TransferQueue接口
可以看到,LinkedTransferQueue实现了一个名为TransferQueue的接口,TransferQueue也是JDK1.7时J.U.C包新增的接口,正是该接口提供了上述的transfer方法:

除了transfer方法外,TransferQueue还提供了两个变种方法:tryTransfer(E e)、tryTransfer(E e, long timeout, TimeUnit unit)。
tryTransfer(E e)
当生产者线程调用tryTransfer方法时,如果没有消费者等待接收元素,则会立即返回false。该方法和transfer方法的区别就是tryTransfer方法无论消费者是否接收,方法立即返回,而transfer方法必须等到消费者消费后才返回。
tryTransfer(E e, long timeout, TimeUnit unit)
tryTransfer(E e,long timeout,TimeUnit unit)方法则是加上了限时等待功能,如果没有消费者消费该元素,则等待指定的时间再返回;如果超时还没消费元素,则返回false,如果在超时时间内消费了元素,则返回true。
TransferQueue接口定义:

LinkedTransferQueue的特点简要概括如下:
- LinkedTransferQueue是一种无界阻塞队列,底层基于单链表实现;
- LinkedTransferQueue中的结点有两种类型:数据结点、请求结点;
- LinkedTransferQueue基于无锁算法实现。
二、LinkedTransferQueue原理
2.1 内部结构
LinkedTransferQueue提供了两种构造器,也没有参数设置队列初始容量,所以是一种 无界队列 :
/**
* 队列结点定义.
*/
static final class Node {
final boolean isData; // true: 数据结点; false: 请求结点
volatile Object item; // 结点值
volatile Node next; // 后驱结点指针
volatile Thread waiter; // 等待线程
// 设置当前结点的后驱结点为val
final boolean casNext(Node cmp, Node val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// 设置当前结点的值为val
final boolean casItem(Object cmp, Object val) {
// assert cmp == null || cmp.getClass() != Node.class;
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
Node(Object item, boolean isData) {
UNSAFE.putObject(this, itemOffset, item); // relaxed write
this.isData = isData;
}
// 设置当前结点的后驱结点为自身
final void forgetNext() {
UNSAFE.putObject(this, nextOffset, this);
}
/**
* 设置当前结点的值为自身.
* 设置当前结点的等待线程为null.
*/
final void forgetContents() {
UNSAFE.putObject(this, itemOffset, this);
UNSAFE.putObject(this, waiterOffset, null);
}
/**
* 判断当前结点是否匹配成功.
* Node.item == this || (Node.isData == true && Node.item == null)
*/
final boolean isMatched() {
Object x = item;
return (x == this) || ((x == null) == isData);
}
/**
* 判断是否为未匹配的请求结点.
* Node.isData == false && Node.item == null
*/
final boolean isUnmatchedRequest() {
return !isData && item == null;
}
/**
* 当该结点(havaData)是未匹配结点, 且与当前的结点类型不同时, 返回true.
*/
final boolean cannotPrecede(boolean haveData) {
boolean d = isData;
Object x;
return d != haveData && (x = item) != this && (x != null) == d;
}
/**
* 尝试匹配数据结点.
*/
final boolean tryMatchData() {
// assert isData; 当前结点必须为数据结点
Object x = item;
if (x != null && x != this && casItem(x, null)) {
LockSupport.unpark(waiter); // 唤醒等待线程
return true;
}
return false;
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
private static final long waiterOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("next"));
waiterOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("waiter"));
} catch (Exception e) {
throw new Error(e);
}
}
}
关于Node结点,有以下几点需要特别注意:
- Node结点有两种类型:数据结点、请求结点,通过字段
isData区分,只有不同类型的结点才能相互匹配; - Node结点的值保存在
item字段,匹配前后值会发生变化;
Node结点的状态变化如下表:
| 结点/状态 | 数据结点 | 请求结点 |
|---|---|---|
| 匹配前 | isData=true;item=数据结点值 | isData=false;item=null |
| 匹配后 | isData=true;item=null | isData=false;item=this |
从上表也可以看出,对于一个数据结点,当
item == null表示匹配成功;对于一个请求结点,当item == this表示匹配成功。归纳起来,匹配成功的结点Node就是满足(Node.item == this) || ((Node.item == null) == Node.isData)。
LinkedTransferQueue内部的其余字段定义如下,主要就是通过Unsafe类操作字段值,内部定义了很多常量字段,比如自旋,这些都是为了非阻塞算法的锁优化而定义的:
public class LinkedTransferQueue<E> extends AbstractQueue<E>
implements TransferQueue<E>, java.io.Serializable {
/**
* True如果是多核CPU
*/
private static final boolean MP = Runtime.getRuntime().availableProcessors() > 1;
/**
* 线程自旋次数(仅多核CPU时用到).
*/
private static final int FRONT_SPINS = 1 << 7;
/**
* 线程自旋次数(仅多核CPU时用到).
*/
private static final int CHAINED_SPINS = FRONT_SPINS >>> 1;
/**
* The maximum number of estimated removal failures (sweepVotes)
* to tolerate before sweeping through the queue unlinking
* cancelled nodes that were not unlinked upon initial
* removal. See above for explanation. The value must be at least
* two to avoid useless sweeps when removing trailing nodes.
*/
static final int SWEEP_THRESHOLD = 32;
/**
* 队首结点指针.
*/
transient volatile Node head;
/**
* 队尾结点指针.
*/
private transient volatile Node tail;
/**
* The number of apparent failures to unsplice removed nodes
*/
private transient volatile int sweepVotes;
// CAS设置队尾tail指针为val
private boolean casTail(Node cmp, Node val) {
return UNSAFE.compareAndSwapObject(this, tailOffset, cmp, val);
}
// CAS设置队首head指针为val
private boolean casHead(Node cmp, Node val) {
return UNSAFE.compareAndSwapObject(this, headOffset, cmp, val);
}
private boolean casSweepVotes(int cmp, int val) {
return UNSAFE.compareAndSwapInt(this, sweepVotesOffset, cmp, val);
}
/*
* xfer方法的入参, 不同类型的方法内部调用xfer方法时入参不同.
*/
private static final int NOW = 0; // for untimed poll, tryTransfer
private static final int ASYNC = 1; // for offer, put, add
private static final int SYNC = 2; // for transfer, take
private static final int TIMED = 3; // for timed poll, tryTransfer
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long headOffset;
private static final long tailOffset;
private static final long sweepVotesOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = LinkedTransferQueue.class;
headOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("tail"));
sweepVotesOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("sweepVotes"));
} catch (Exception e) {
throw new Error(e);
}
}
//...
}
上述比较重要的就是4个常量值的定义:
/*
* xfer方法的入参, 不同类型的方法内部调用xfer方法时入参不同.
*/
private static final int NOW = 0; // for untimed poll, tryTransfer
private static final int ASYNC = 1; // for offer, put, add
private static final int SYNC = 2; // for transfer, take
private static final int TIMED = 3; // for timed poll, tryTransfer
这四个常量值,作为xfer方法的入参,用于标识不同操作类型。其实从常量的命名也可以看出它们对应的操作含义:
NOW表示即时操作(可能失败),即不会阻塞调用线程:
poll(获取并移除队首元素,如果队列为空,直接返回null);tryTransfer(尝试将元素传递给消费者,如果没有等待的消费者,则立即返回false,也不会将元素入队)
ASYNC表示异步操作(必然成功):
offer(插入指定元素至队尾,由于是无界队列,所以会立即返回true);put(插入指定元素至队尾,由于是无界队列,所以会立即返回);add(插入指定元素至队尾,由于是无界队列,所以会立即返回true)
SYNC表示同步操作(阻塞调用线程):
transfer(阻塞直到出现一个消费者线程);take(从队首移除一个元素,如果队列为空,则阻塞线程)
TIMED表示限时同步操作(限时阻塞调用线程):
poll(long timeout, TimeUnit unit);tryTransfer(E e, long timeout, TimeUnit unit)
关于xfer方法,它是LinkedTransferQueued的核心内部方法,我们后面会详细介绍。
2.2 transfer方法
transfer方法,用于将指定元素e传递给消费者线程(调用take/poll方法)。如果有消费者线程正在阻塞等待,则调用transfer方法的线程会直接将元素传递给它;如果没有消费者线程等待获取元素,则调用transfer方法的线程会将元素插入到队尾,然后阻塞等待,直到出现一个消费者线程获取元素:
/**
* 将指定元素e传递给消费者线程(调用take/poll方法).
*/
public void transfer(E e) throws InterruptedException {
if (xfer(e, true, SYNC, 0) != null) {
// 进入到此处, 说明调用线程被中断了
Thread.interrupted(); // 清除中断状态, 然后抛出中断异常
throw new InterruptedException();
}
}
transfer 方法的内部实际是调用了xfer方法,入参为SYNC=2:
/**
* 入队/出队元素的真正实现.
*
* @param e 入队操作, e非null; 出队操作, e为null
* @param haveData true表示入队元素, false表示出队元素
* @param how NOW, ASYNC, SYNC, TIMED 四种常量定义
* @param nanos 限时模式下使用(纳秒)
* @return 匹配成功则返回匹配的元素, 否则返回e本身
*/
private E xfer(E e, boolean haveData, int how, long nanos) {
if (haveData && (e == null)) // 入队操作, 元素e不能为null
throw new NullPointerException();
Node s = null;
retry:
for (; ; ) {
for (Node h = head, p = h; p != null; ) { // 尝试匹配p指向的结点
boolean isData = p.isData; // 结点类型
Object item = p.item; // 结点值
if (item != p && (item != null) == isData) { // 如果结点还未匹配过
if (isData == haveData) // 同种类型结点不能匹配
break;
if (p.casItem(item, e)) { // p指向从队首开始向后的第一个匹配结点
for (Node q = p; q != h; ) {
Node n = q.next; // update by 2 unless singleton
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
LockSupport.unpark(p.waiter); // 唤醒匹配结点上的等待线程
return LinkedTransferQueue.<E>cast(item); // 返回匹配结点的值
}
}
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
}
if (how != NOW) {
if (s == null)
s = new Node(e, haveData); // 创建一个入队结点, 添加到队尾
Node pred = tryAppend(s, haveData); // pred指向s的前驱结点或s(队列中只有一个结点)或null(tryAppend失败)
if (pred == null)
continue retry; // 入队失败,则重试
if (how != ASYNC)
return awaitMatch(s, pred, e, (how == TIMED), nanos); // 等待出队线程
}
return e;
}
}
我们通过示例看下 xfer 方法到底做了哪些事:
①队列初始状态

②ThreadA线程调用transfer入队元素“9”
注意,此时入队一个数据结点,且队列为空,所以会直接进入xfer中的下述代码:
if (how != NOW) {
if (s == null)
s = new Node(e, haveData); // 创建一个入队结点, 添加到队尾
Node pred = tryAppend(s, haveData); // pred指向s的前驱结点或s(队列中只有一个结点)或null(tryAppend失败)
if (pred == null)
continue retry; // 入队失败,则重试
if (how != ASYNC)
return awaitMatch(s, pred, e, (how == TIMED), nanos); // 等待出队线程
}
上述代码会插入一个结点至队尾,然后线程进入阻塞,等待一个出队线程(消费者)的到来。
队尾插入结点的方法是tryAppend,由于此时队列为空,会进入CASE1分支,设置队首指针head指向新结点,tryAppend方法的返回值有三种情况:
- 入队失败,返回null;
- 入队成功且队列只有一个结点,返回该结点自身;
- 入队成功且队列不止一个结点,返回该入队结点的前驱结点。
/**
* 尝试将结点s添加到队尾.
*
* @param s 待添加的结点
* @param haveData true: 数据结点
* @return 返回null表示失败; 否则返回s的前驱结点(没有前驱则返回s自身)
*/
private Node tryAppend(Node s, boolean haveData) {
for (Node t = tail, p = t; ; ) {
Node n, u;
if (p == null && (p = head) == null) { // CASE1: 队列为空
if (casHead(null, s)) // 设置队首指针head
return s;
} else if (p.cannotPrecede(haveData)) // CASE2: 结点s不能链接到结点p
return null;
else if ((n = p.next) != null) // CASE3: 遍历至队尾结点
p = p != t && t != (u = tail) ? (t = u) : // stale tail
(p != n) ? n : null; // restart if off list
else if (!p.casNext(null, s)) // CASE4: 插入结点s
p = p.next; // re-read on CAS failure
else { // CASE5: 尝试进行松弛操作
if (p != t) { // update if slack now >= 2
while ((tail != t || !casTail(t, s)) &&
(t = tail) != null &&
(s = t.next) != null && // advance and retry
(s = s.next) != null && s != t) ;
}
return p;
}
}
}
等待出队线程方法awaitMatch,该方法核心作用就是进行结点匹配:
- 匹配成功,返回匹配值;
- 匹配失败(中断或限时等待的超时情况),返回原匹配结点的值;
- 阻塞线程,等待与之匹配的结点的到来。
从awaitMatch方法其实可以看到一种经典的“锁优化”思路,就是 自旋 -> yield -> 阻塞 ,线程不会立即进入阻塞,因为线程上下文切换的开销往往比较大,所以会先自旋一定次数,中途可能伴随随机的yield操作,让出cpu时间片,如果自旋次数用完后,还是没有匹配线程出现,再真正阻塞线程。
经过上述步骤,ThreadA最终会进入CASE4分支中等待,此时的队列结构如下:
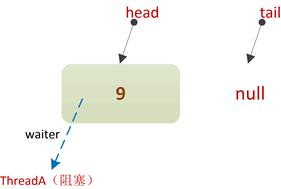
注意,此时的队列中tail队尾指针并不指向结点“9”,这是一种“松弛”策略,后面会讲到。
③ThreadB线程调用transfer入队元素“2”
由于此时队首head指针不为null,所以会进入 transfer 方法中的以下循环:
for (Node h = head, p = h; p != null; ) {
boolean isData = p.isData; // 结点类型
Object item = p.item; // 结点值
if (item != p && (item != null) == isData) { // 如果结点还未匹配过
if (isData == haveData) // 同种类型结点不能匹配
break;
if (p.casItem(item, e)) { // match
for (Node q = p; q != h; ) {
Node n = q.next; // update by 2 unless singleton
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
LockSupport.unpark(p.waiter);
return LinkedTransferQueue.<E>cast(item);
}
}
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
}
上述方法会读取队首结点,判断该结点有没被匹配过(item != p && (item != null) == isData):
- 如果已经被其它线程匹配过了,则继续判断下一个结点(
p.next); - 如果还没有被匹配,则判断下当前的入队结点类型是否和队首中的一致;如果一致(
isData == haveData)就匹配失败,跳出循环,否则进行匹配操作。
显然,目前队首结点是“数据结点”,ThreadB线程的入队结点也是“数据结点”,结点类型一致,所以匹配失败,直接跳过循环,也进入以下代码块:
if (how != NOW) {
if (s == null)
s = new Node(e, haveData); // 创建一个入队结点, 添加到队尾
Node pred = tryAppend(s, haveData); // pred指向s的前驱结点或s(队列中只有一个结点)或null(tryAppend失败)
if (pred == null)
continue retry; // 入队失败,则重试
if (how != ASYNC)
return awaitMatch(s, pred, e, (how == TIMED), nanos); // 等待出队线程
}
再次调用 tryAppend 方法, 会在CASE4分支中将元素“2”插入队尾,然后在CASE5分支中重新设置队尾指针tail:
/**
* 尝试将结点s添加到队尾.
*
* @param s 待添加的结点
* @param haveData true: 数据结点
* @return 返回null表示失败; 否则返回s的前驱结点(没有前驱则返回s自身)
*/
private Node tryAppend(Node s, boolean haveData) {
for (Node t = tail, p = t; ; ) {
Node n, u;
if (p == null && (p = head) == null) { // CASE1: 队列为空
if (casHead(null, s)) // 设置队首指针head
return s;
} else if (p.cannotPrecede(haveData)) // CASE2: 结点s不能链接到结点p
return null;
else if ((n = p.next) != null) // CASE3: 遍历至队尾结点
p = p != t && t != (u = tail) ? (t = u) : // stale tail
(p != n) ? n : null; // restart if off list
else if (!p.casNext(null, s)) // CASE4: 插入结点s
p = p.next; // re-read on CAS failure
else { // CASE5: 尝试进行松弛操作
if (p != t) { // update if slack now >= 2
while ((tail != t || !casTail(t, s)) &&
(t = tail) != null &&
(s = t.next) != null && // advance and retry
(s = s.next) != null && s != t) ;
}
return p;
}
}
}
此时队列结构如下:

最终,ThreadB也会在 awaitMatch 方法中进入阻塞,最终队列结构如下:

④ThreadC线程调用transfer入队元素“93”
过程和前几步几乎相同,不再赘述,最终队列结构如下:

可以看到,队尾指针tail的设置实际是滞后的,这是一种“松弛”策略,用以提升无锁算法并发修改过程中的性能。
2.3 take方法
再来看下消费者线程调用的take方法,该方法会从队首取出一个元素,如果队列为空,则线程会阻塞:
/**
* 从队首出队一个元素.
*/
public E take() throws InterruptedException {
E e = xfer(null, false, SYNC, 0); // (e == null && isData=false)表示一个请求结点
if (e != null) // 如果e!=null, 则表示匹配成功, 此时e为与之匹配的数据结点的值
return e;
Thread.interrupted();
throw new InterruptedException();
}
内部依然调用了 xfer 方法,不过此时入参有所不同,由于是消费线程调用,所以入参e == null && hasData == false,表示一个“请求结点”:
/**
* 入队/出队元素的真正实现.
*
* @param e 入队操作, e非null; 出队操作, e为null
* @param haveData true表示入队元素, false表示出队元素
* @param how NOW, ASYNC, SYNC, TIMED 四种常量定义
* @param nanos 限时模式下使用(纳秒)
* @return 匹配成功则返回匹配的元素, 否则返回e本身
*/
private E xfer(E e, boolean haveData, int how, long nanos) {
if (haveData && (e == null)) // 入队操作, 元素e不能为null
throw new NullPointerException();
Node s = null;
retry:
for (; ; ) {
for (Node h = head, p = h; p != null; ) { // 尝试匹配p指向的结点
boolean isData = p.isData; // 结点类型
Object item = p.item; // 结点值
if (item != p && (item != null) == isData) { // 如果结点还未匹配过
if (isData == haveData) // 同种类型结点不能匹配
break;
if (p.casItem(item, e)) { // p指向从队首开始向后的第一个匹配结点
for (Node q = p; q != h; ) {
Node n = q.next; // update by 2 unless singleton
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
LockSupport.unpark(p.waiter); // 唤醒匹配结点上的等待线程
return LinkedTransferQueue.<E>cast(item); // 返回匹配结点的值
}
}
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
}
if (how != NOW) {
if (s == null)
s = new Node(e, haveData); // 创建一个入队结点, 添加到队尾
Node pred = tryAppend(s, haveData); // pred指向s的前驱结点或s(队列中只有一个结点)或null(tryAppend失败)
if (pred == null)
continue retry; // 入队失败,则重试
if (how != ASYNC)
return awaitMatch(s, pred, e, (how == TIMED), nanos); // 等待出队线程
}
return e;
}
}
还是通过示例看:
①队列初始状态

②ThreadD调用take方法,消费元素
此时,在 xfer 方法中,会从队首开始,向后找到第一个匹配结点,并交换元素值,然后唤醒队列中匹配结点上的等待线程:
/**
* 入队/出队元素的真正实现.
*
* @param e 入队操作, e非null; 出队操作, e为null
* @param haveData true表示入队元素, false表示出队元素
* @param how NOW, ASYNC, SYNC, TIMED 四种常量定义
* @param nanos 限时模式下使用(纳秒)
* @return 匹配成功则返回匹配的元素, 否则返回e本身
*/
private E xfer(E e, boolean haveData, int how, long nanos) {
if (haveData && (e == null)) // 入队操作, 元素e不能为null
throw new NullPointerException();
Node s = null;
retry:
for (; ; ) {
for (Node h = head, p = h; p != null; ) { // 尝试匹配p指向的结点
boolean isData = p.isData; // 结点类型
Object item = p.item; // 结点值
if (item != p && (item != null) == isData) { // 如果结点还未匹配过
if (isData == haveData) // 同种类型结点不能匹配
break;
if (p.casItem(item, e)) { // p指向从队首开始向后的第一个匹配结点
for (Node q = p; q != h; ) {
Node n = q.next; // update by 2 unless singleton
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
LockSupport.unpark(p.waiter); // 唤醒匹配结点上的等待线程
return LinkedTransferQueue.<E>cast(item); // 返回匹配结点的值
}
}
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
}
if (how != NOW) {
if (s == null)
s = new Node(e, haveData); // 创建一个入队结点, 添加到队尾
Node pred = tryAppend(s, haveData); // pred指向s的前驱结点或s(队列中只有一个结点)或null(tryAppend失败)
if (pred == null)
continue retry; // 入队失败,则重试
if (how != ASYNC)
return awaitMatch(s, pred, e, (how == TIMED), nanos); // 等待出队线程
}
return e;
}
}
最终队列结构如下,匹配结点的值被置换为null,ThreadA被唤醒,ThreadD拿到匹配结点上的元素值“9”并返回:

③ThreadA被唤醒后继续执行
ThreadA被唤醒后,从原阻塞处——继续向下执行,然后进入下一次自旋,进入CASE1分支:
/**
* 自旋/yield/阻塞,直到结点s被匹配.
*
* @param s 等待被匹配的结点s
* @param pred s的前驱结点或s自身(队列中只有一个结点的情况)
* @param e 结点s的值
* @return 匹配值, 或e本身(中断或超时情况)
*/
private E awaitMatch(Node s, Node pred, E e, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L; // 限时等待情况下使用
Thread w = Thread.currentThread();
int spins = -1; // 自旋次数, 锁优化操作
ThreadLocalRandom randomYields = null; // bound if needed
for (; ; ) {
Object item = s.item;
if (item != e) { // CASE1: 匹配成功
// assert item != s;
s.forgetContents(); // avoid garbage
return LinkedTransferQueue.<E>cast(item);
}
if ((w.isInterrupted() || (timed && nanos <= 0))
&& s.casItem(e, s)) { // CASE2: 取消(线程被中断或超时)
unsplice(pred, s);
return e;
}
// CASE3: 设置轻量级锁(自旋 -> yield)
if (spins < 0) { // 初始化自旋次数
if ((spins = spinsFor(pred, s.isData)) > 0)
randomYields = ThreadLocalRandom.current();
} else if (spins > 0) { // 自选次数减1
--spins;
if (randomYields.nextInt(CHAINED_SPINS) == 0)
Thread.yield(); // 随机yield线程
} else if (s.waiter == null) { // waiter保存待阻塞线程
s.waiter = w;
} else if (timed) { // 限时等待情况, 计算剩余有效时间
nanos = deadline - System.nanoTime();
if (nanos > 0L)
LockSupport.parkNanos(this, nanos);
} else { // CASE4: 阻塞线程
LockSupport.park(this);
}
}
}
在CASE1分支中,由于结点的item项已经被替换成了null,所以调用s.forgetContents(),并返回null
/**
* 设置当前结点的值为自身.
* 设置当前结点的等待线程为null.
*/
final void forgetContents() {
UNSAFE.putObject(this, itemOffset, this);
UNSAFE.putObject(this, waiterOffset, null);
}
最终队列结构如下:

④ThreadE调用take方法出队元素
ThreadE调用 take 方法出队元素,过程和步骤②相同,进入xfer方法(e == null,hasData == false),由于head指针指向的元素已经匹配过了,所以
向后继续查找,找到第一个未匹配过的结点“2”,然后置换结点“2”中的元素值为null,唤醒线程ThreadB,返回匹配结点的元素值“2”:
for (Node h = head, p = h; p != null; ) { // 尝试匹配p指向的结点
boolean isData = p.isData; // 结点类型
Object item = p.item; // 结点值
if (item != p && (item != null) == isData) { // 如果结点还未匹配过
if (isData == haveData) // 同种类型结点不能匹配
break;
if (p.casItem(item, e)) { // p指向从队首开始向后的第一个匹配结点
for (Node q = p; q != h; ) {
Node n = q.next; // update by 2 unless singleton
if (head == h && casHead(h, n == null ? q : n)) {
h.forgetNext();
break;
} // advance and retry
if ((h = head) == null ||
(q = h.next) == null || !q.isMatched())
break; // unless slack < 2
}
LockSupport.unpark(p.waiter); // 唤醒匹配结点上的等待线程
return LinkedTransferQueue.<E>cast(item); // 返回匹配结点的值
}
}
Node n = p.next;
p = (p != n) ? n : (h = head); // Use head if p offlist
}
此时队列状态如下,可以看到,队首指针head一次性向后跳了2个位置,原来已经匹配过的元素的next指针指向自身,等待被GC回收,这其实就是LinkedTransferQueue的“松弛”策略:

⑤ThreadB被唤醒后继续执行
过程和步骤③完全相同,在 awaitMatch 方法中,将结点的item置为this,然后返回匹配结点值——null,最终队列结构如下:

⑥ThreadF调用take方法出队元素
ThreadF调用take方法出队元素,过程和步骤②相同,进入xfer方法(e == null,hasData == false),由于head指针指向的元素此时没有匹配,所以不用像步骤②那样向后查找,而是直接置换匹配结点的元素值“93”,然后唤醒ThreadC,返回匹配值“93”。最终队列结构如下:

⑦ThreadC被唤醒后继续执行
过程和步骤③完全相同,在 awaitMatch 方法中,将结点的item置为this,然后返回匹配结点值——null,最终队列结构如下:

此时的队列结构,读者移一定感到非常奇怪,并不严格遵守队列的定义,这其实就是 “Dual Queue” 算法的实现,为了对自旋优化,做了很多看似别扭的操作,不必奇怪。
假设此时再有一个线程ThreadH调用take方法出队元素会怎么样?其实这是队列已经空了,ThreadH会被阻塞,但是会创建一个“请求结点”入队:
/**
* 尝试将结点s添加到队尾.
*
* @param s 待添加的结点
* @param haveData true: 数据结点
* @return 返回null表示失败; 否则返回s的前驱结点(没有前驱则返回s自身)
*/
private Node tryAppend(Node s, boolean haveData) {
for (Node t = tail, p = t; ; ) {
Node n, u;
if (p == null && (p = head) == null) { // CASE1: 队列为空
if (casHead(null, s)) // 设置队首指针head
return s;
} else if (p.cannotPrecede(haveData)) // CASE2: 结点s不能链接到结点p
return null;
else if ((n = p.next) != null) // CASE3: 遍历至队尾结点
p = p != t && t != (u = tail) ? (t = u) : // stale tail
(p != n) ? n : null; // restart if off list
else if (!p.casNext(null, s)) // CASE4: 插入结点s
p = p.next; // re-read on CAS failure
else { // CASE5: 尝试进行松弛操作
if (p != t) { // update if slack now >= 2
while ((tail != t || !casTail(t, s)) &&
(t = tail) != null &&
(s = t.next) != null && // advance and retry
(s = s.next) != null && s != t) ;
}
return p;
}
}
}
调用完 tryAppend 方法后,队列结构如下,橙色的为“请求结点”—— item==null && isData==false:

然后ThreadH也会进入在 awaitMatch 方法后进入阻塞,并等待一个入队线程的到来。最终队列结构如下:

三、总结
截止本篇为止,我们已经学习完了juc-collection框架中的所有阻塞队列,如下表所示:
| 队列特性 | 有界队列 | 近似无界队列 | 无界队列 | 特殊队列 |
|---|---|---|---|---|
| 有锁算法 | ArrayBlockingQueue | LinkedBlockingQueue、LinkedBlockingDeque | / | PriorityBlockingQueue、DelayQueue |
| 无锁算法 | / | / | LinkedTransferQueue | SynchronousQueue |
可以看到,LinkedTransferQueue其实兼具了SynchronousQueue的特性以及无锁算法的性能,并且是一种无界队列:
- 和SynchronousQueue相比,LinkedTransferQueue可以存储实际的数据;
- 和其它阻塞队列相比,LinkedTransferQueue直接用无锁算法实现,性能有所提升。
另外,由于LinkedTransferQueue可以存放两种不同类型的结点,所以称之为“ Dual Queue ”:
内部Node结点定义了一个 boolean 型字段——isData,表示该结点是“ 数据结点 ”还是“ 请求结点 ”。
为了节省 CAS 操作的开销,LinkedTransferQueue使用了 松弛(slack) 操作:
在结点被匹配(被删除)之后,不会立即更新队列的head、tail,而是当 head、tail结点与最近一个未匹配的结点之间的距离超过“松弛阀值”后才会更新(默认为 2)。这个“松弛阀值”一般为1到3,如果太大会增加沿链表查找未匹配结点的时间,太小会增加 CAS 的开销。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
