了解了ByteBuf的结构和基本使用,我们来看 Netty 是如何进行内存管理的。Netty 借鉴了 jemalloc内存分配器 ,实现了一套高性能的内存管理机制:
- 在单线程和多线程的场景下,高效地进行内存分配和回收;
- 减少内存碎片,有效提高内存利用率。
jemalloc 是由 Jason Evans 在 FreeBSD 项目中引入的新一代内存分配器。它是一个通用的 malloc 实现,侧重于减少内存碎片和提升高并发场景下内存的分配效率,其目标是能够替代 malloc。jemalloc 的思想在很多场景都非常适用,在 Redis、Netty 等知名的高性能组件中都有它的原型,你会发现它们的实现思路都是类似的。
所以,我本章将先对Linux操作系统的内存管理算法进行介绍,然后对 jemalloc 内存分配器的基本原理进行讲解,最后再分析Netty的内存管理机制。
一、Linux内存管理
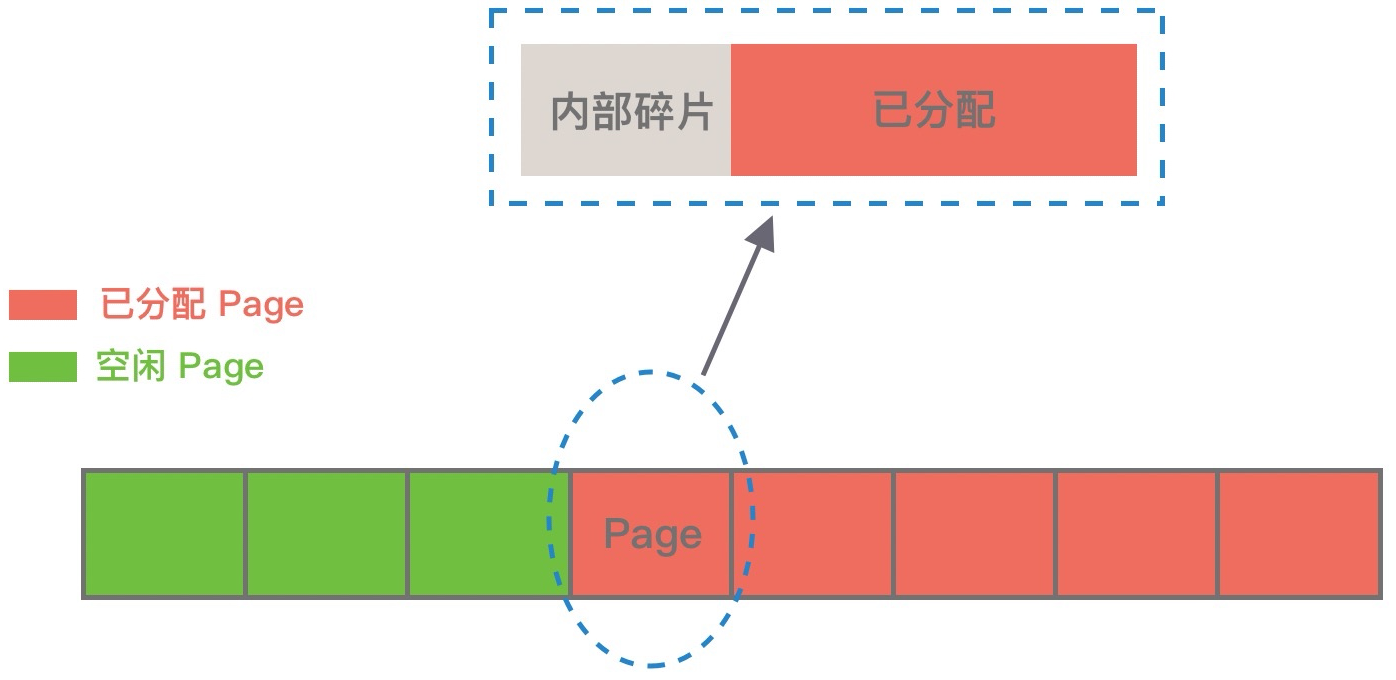
Linux中,物理内存会被划分成许多 4K 大小的内存页(Page),物理内存的分配和回收都是基于 Page 完成的,Page 内产生的内存碎片称为内部碎片,Page 之间产生的内存碎片称为外部碎片:
Linux常用的内存分配算法有: 动态内存分配 、 伙伴算法 和 Slab 算法 。我们先来一一看下,有助于后续理解jemalloc。
1.1 动态内存分配算法
动态内存分配(Dynamic memory allocation)又称为堆内存分配,后面简称 DMA。操作系统会根据程序运行过程中的需求,即时分配内存,且分配的内存大小就是程序需求的大小。在大部分场景下,只有在程序运行时才知道需要分配的内存大小,如果提前分配则比较难把控大小,分配太大会浪费空间,分配太小则无法使用。
DMA 是从一整块内存中按需分配,对于分配出的内存会记录元数据,同时还会使用空闲分区链维护空闲内存,便于在内存分配时查找可用的空闲分区,常用的有三种查找策略。
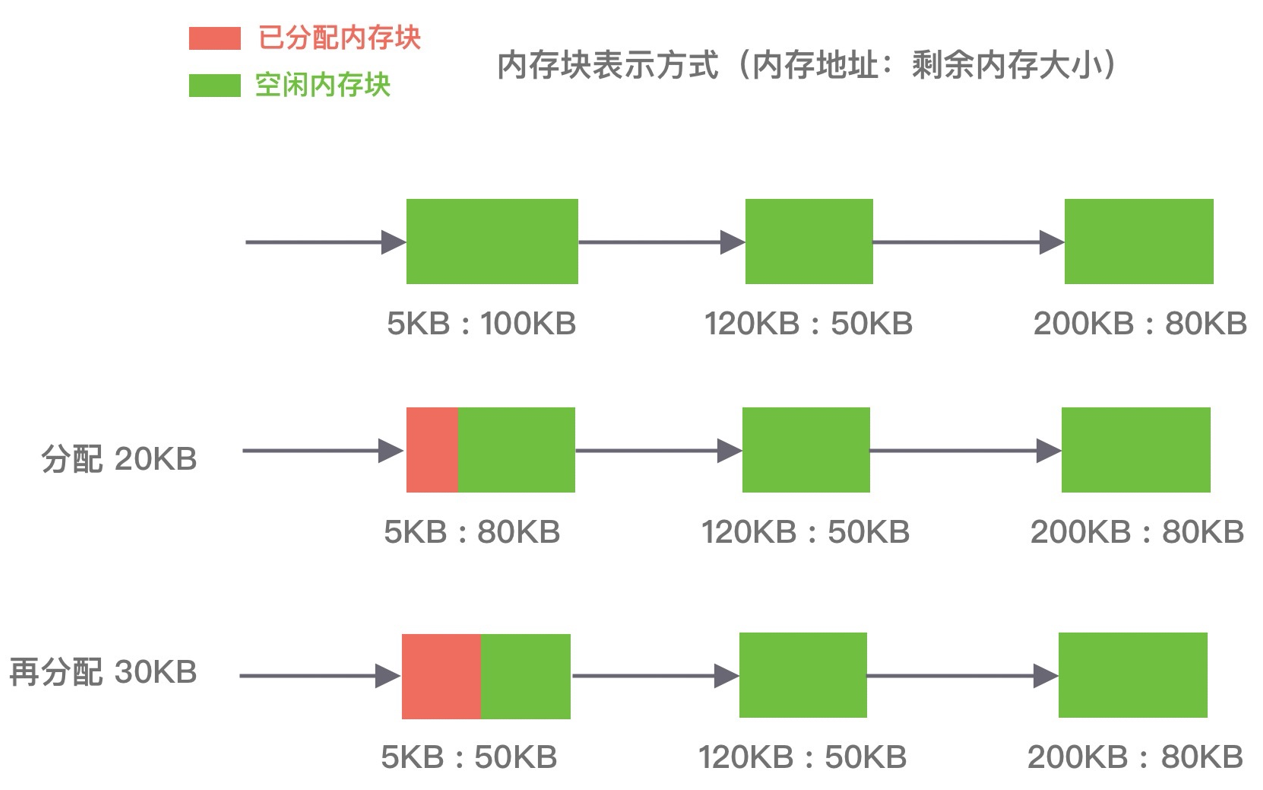
首次适应算法(first fit)
以地址递增的顺序,将空闲分区以双向链表的形式链接在一起,从链中找到第一个满足分配条件的空闲分区,然后从空闲分区中划分出一块可用内存给请求进程。
优缺点:该算法每次都从低地址开始查找,造成低地址部分会不断被分配,同时也会产生很多的小空闲分区。
如下图所示,P1和P2的请求可以在内存块A中完成分配:
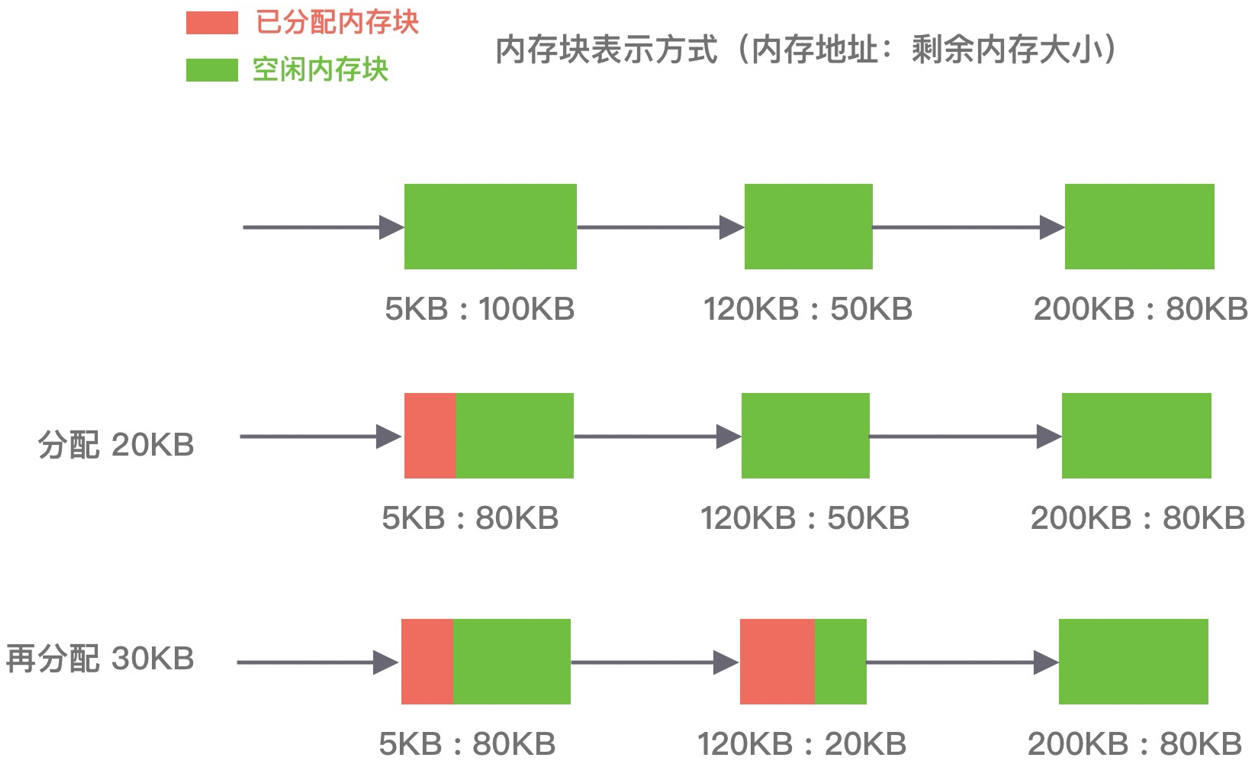
循环首次适应算法(next fit)
该算法是首次适应算法的变种,不再每次从链表的开始进行查找,而是从上次找到的空闲分区的下⼀个空闲分区开始查找。
优缺点:该算法相比⾸次适应算法空闲分区的分布更加均匀,而且查找的效率有所提升,但是会造成空闲分区链中的大空闲分区越来越少。
如下图所示,P1 请求在内存块 A 完成分配,然后再为 P2 分配内存时,是直接继续向下寻找可用分区,最终在 B 内存块中完成分配:
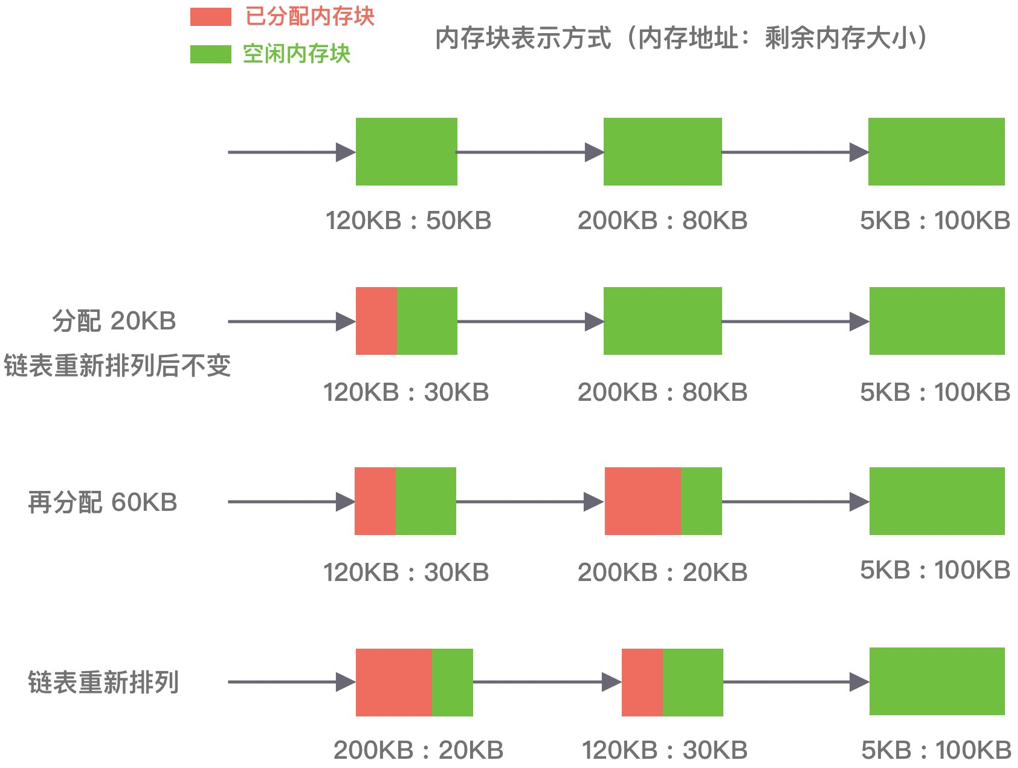
最佳适应算法(best fit)
该算法根据照空闲分区大小,以递增顺序将它们按双向链表的形式链接在一起,每次从空闲分区链的开头进行查找,这样第一个满足分配条件的空间分区就是最优解。
优缺点:空间利用率高,但会留下很多较难利用的小空闲分区,并且每次分配完需要重新排序,所以会有造成性能损耗。
如下图所示,在 A 内存块分配完 P1 请求后,空闲分区链重新按分区大小进行排序,再为 P2 请求查找满足条件的空闲分区:
1.2 伙伴算法
伙伴算法是一种非常经典的内存分配算法,它采用了分离适配的设计思想,将物理内存按照 2 的次幂进行划分,内存分配时也是按照 2 的次幂大小进行按需分配,例如 4KB、 8KB、16KB 等。假设我们请求分配的内存大小为 10KB,那么会按照 16KB 分配。
伙伴算法相对比较复杂,我们结合下面这张图来讲解它的分配原理:
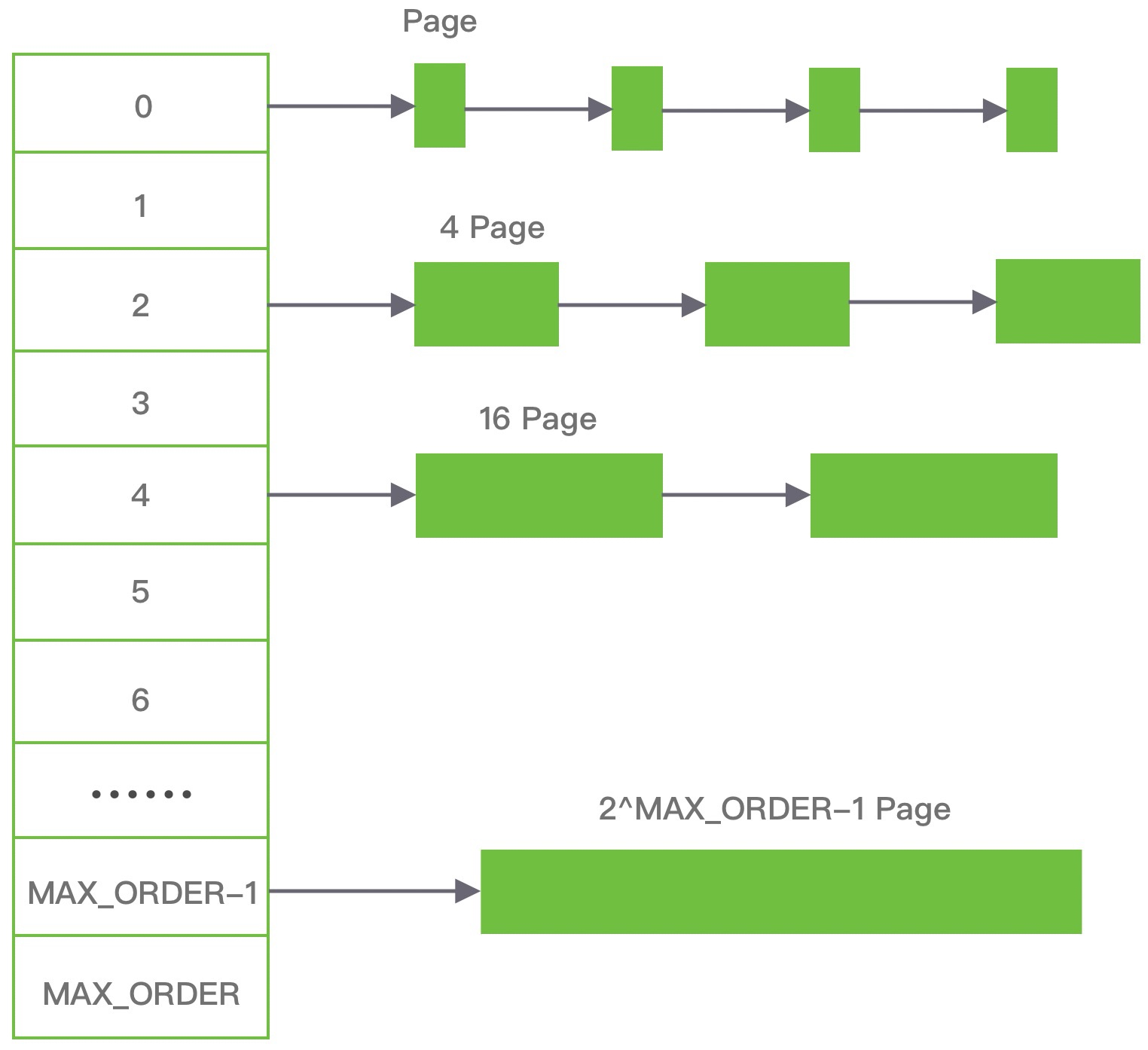
伙伴算法把内存划分为 11 组不同的 2 次幂大小的内存块集合,每组内存块集合都用双向链表连接。链表中每个节点的内存块大小分别为 1、2、4、8、16、32、64、128、256、512 和 1024 个连续的 Page,例如第一组链表的节点为 2 个连续 Page,第二组链表的节点为 2^1 个连续 Page,以此类推。
假设我们需要分配 10K 大小的内存块,看下伙伴算法的具体分配过程:
- 首先需要找到存储 2^4 连续 Page 所对应的链表,即数组下标为 4;
- 查找 2^4 链表中是否有空闲的内存块,如果有则分配成功;
- 如果 2^4 链表不存在空闲的内存块,则继续沿数组查找,即定位到数组下标为 5 的链表,链表中每个节点存储 2^5 的连续 Page;
- 如果 2^5 链表中存在空闲的内存块,则取出该内存块并将它分割为 2 个 2^4 大小的内存块,其中一块分配给进程使用,剩余的一块链接到 2^4 链表中。
以上是伙伴算法的分配过程,那么伙伴算法又是如何释放内存的呢?
当进程使用完内存归还时,需要检查其伙伴块的内存是否释放,所谓伙伴块是大小相同且块地址连续,其中低地址的内存块起始地址必须为 2 的整数次幂。如果伙伴块是空闲的,那么就会将两个内存块合并成更大的块,然后重复执行上述伙伴块的检查机制,直至伙伴块是非空闲状态,那么就会将该内存块按照实际大小归还到对应的链表中。
伙伴算法有效地减少了外部碎片,但是频繁的合并会造成 CPU 浪费,且以 Page 为最小管理单位,并不适用小内存的分配场景,容易造成非常严重的内部碎片,最严重的情况会带来 50% 的内存碎片。
1.3 Slab算法
Slab 算法在伙伴算法的基础上,对小内存的场景专门做了优化,采用了内存池的方案,解决内部碎片问题。
Linux内核使用的就是 Slab 算法,因为内核需要频繁地分配小内存,所以 Slab 算法提供了一种高速缓存机制,使用缓存存储内核对象,当内核需要分配内存时,基本上可以通过缓存中获取。此外 Slab 算法还可以支持通用对象的初始化操作,避免对象重复初始化的开销。
下图是 Slab 算法的结构图,Slab 算法实现起来非常复杂,本文只做一个简单的了解:
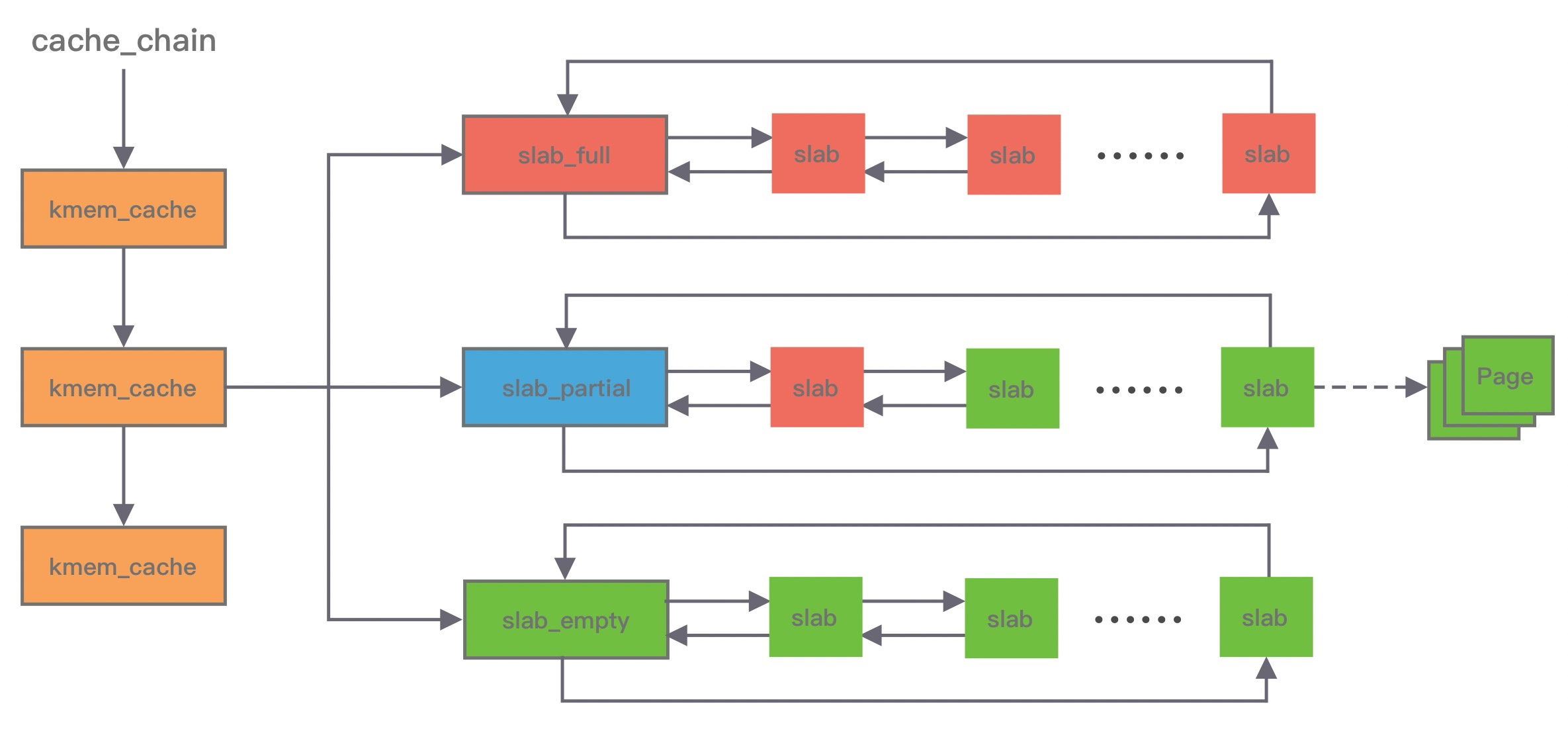
Slab 算法维护了大小不同的 Slab 集合,在最顶层是 cache_chain,cache_chain 中维护着一组 kmem_cache 引用,kmem_cache 负责管理一块固定大小的对象池。通常会提前分配一块内存,然后将这块内存划分为大小相同的 slot,不会对内存块再进行合并,同时使用位图 bitmap 记录每个 slot 的使用情况。
kmem_cache 中包含三个 Slab 链表: 完全分配使用 slab_full 、 部分分配使用 slab_partial 和 完全空闲 slabs_empty ,这三个链表负责内存的分配和释放。每个链表中维护的 Slab 都是一个或多个连续 Page,每个 Slab 被分配多个对象进行存储。Slab 算法是基于对象进行内存管理的,它把相同类型的对象分为一类。当分配内存时,从 Slab 链表中划分相应的内存单元;当释放内存时,Slab 算法并不会丢弃已经分配的对象,而是将它保存在缓存中,当下次再为对象分配内存时,直接会使用最近释放的内存块。
单个Slab可以在不同的链表之间移动,例如当一个Slab被分配完,就会从slab_partial移动到slabs_full,当一个Slab中有对象被释放后,就会从slab_full再次回到slab_partial,所有对象都被释放完的话,就会从slab_partial移动到 slab_empty。
二、 jemalloc
了解了Linux常用的内存分配算法之后,再理解 jemalloc 会相对轻松一些。下图是 jemalloc 的架构图:
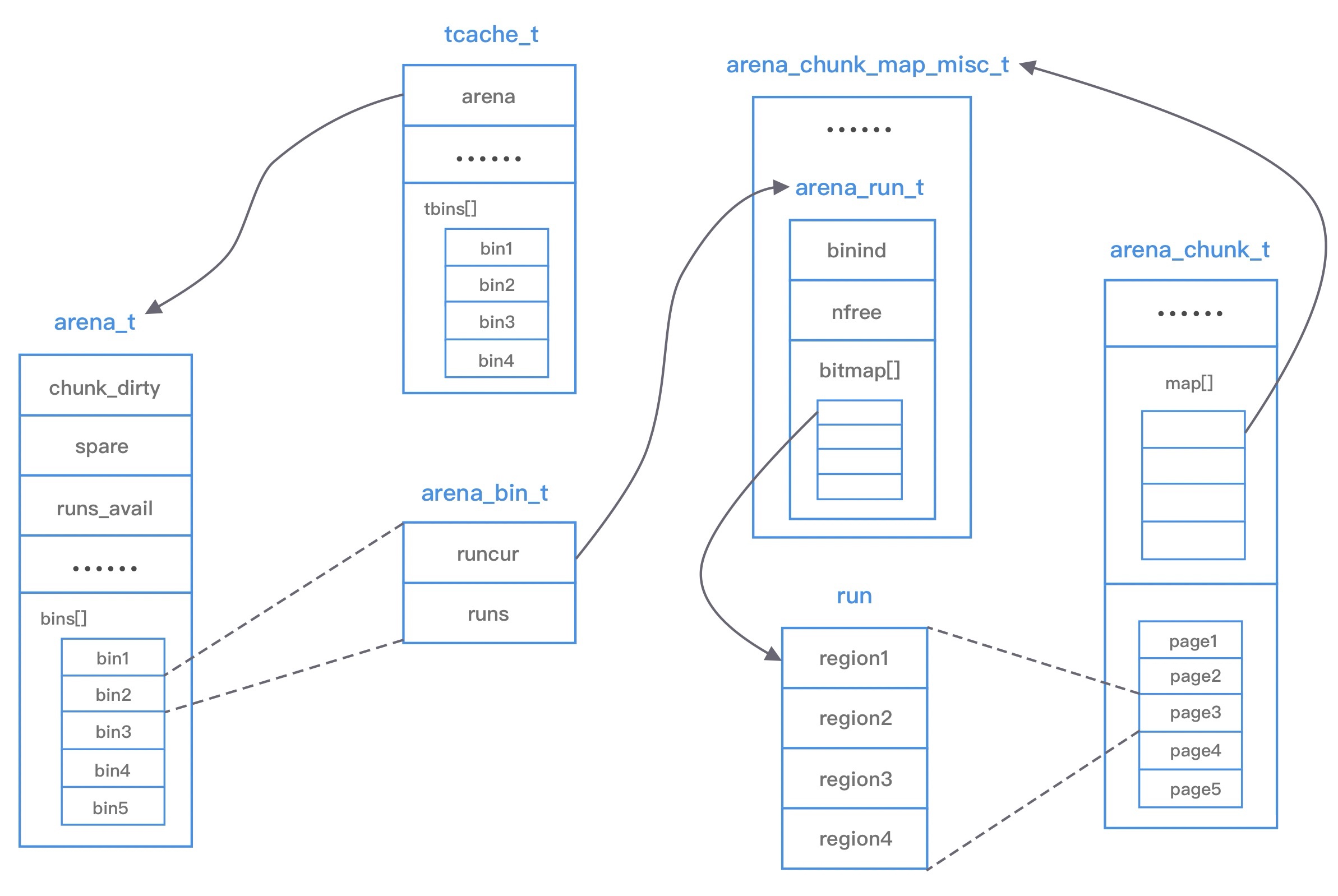
上图涉及 jemalloc 的几个核心概念,例如 arena、bin、chunk、run、region、tcache 等。
arena 是 jemalloc 最重要的部分 ,内存由一定数量的 arena 负责管理。每个用户线程都会被绑定到一个 arena 上,线程采用 round-robin 轮询的方式选择可用的 arena 进行内存分配,为了减少线程之间的锁竞争,默认每个 CPU 会分配 4 个 arena。
bin 用于管理不同档位的内存单元 ,每个 bin 管理的内存大小按档位依次递增。因为 jemalloc 中小内存的分配是基于 Slab 算法完成的,所以会产生不同类别的内存块。
chunk 是负责管理用户内存块的数据结构 ,chunk 以 Page 为单位管理内存,默认大小是 4M,即 1024 个连续 Page。每个 chunk 可被用于多次小内存的申请,但是在大内存分配的场景下只能分配一次。
run 实际上是 chunk 中的一块内存区域 ,每个 bin 管理相同类型的 run,最终通过操作 run 完成内存分配。run 结构具体的大小由不同的 bin 决定,例如 8 字节的 bin 对应的 run 只有一个 Page,可以从中选取 8 字节的块进行分配。
region 是每个 run 中的对应的若干个小内存块 ,每个 run 会将划分为若干个等长的 region,每次内存分配也是按照 region 进行分发。
tcache 是每个线程私有的缓存 ,用于 small 和 large 场景下的内存分配,每个 tcahe 会对应一个 arena,tcache 本身也会有一个 bin 数组,称为tbin。与 arena 中 bin 不同的是,它不会有 run 的概念。tcache 每次从 arena 申请一批内存,在分配内存时首先在 tcache 查找,从而避免锁竞争,如果分配失败才会通过 run 执行内存分配。
jemalloc 的几个核心的概念介绍完了,我们再重新梳理下它们之间的关系:
- 内存是由一定数量的 arenas 负责管理,线程均匀分布在 arenas 当中;
- 每个 arena 都包含一个 bin 数组,每个 bin 管理不同档位的内存块;
- 每个 arena 被划分为若干个 chunks,每个 chunk 又包含若干个 runs,每个 run 由连续的 Page 组成,run 才是实际分配内存的操作对象;
- 每个 run 会被划分为一定数量的 regions,在小内存的分配场景,region 相当于用户内存;
- 每个 tcache 对应 一个 arena,tcache 中包含多种类型的 bin。
接下来我分析下 jemalloc 的整体内存分配和释放流程,主要分为 Small 、 Large 和 Huge 三种场景。
2.1 Small场景
如果请求分配内存的大小小于 arena 中的最小的 bin,那么优先从线程中对应的 tcache 中进行分配。首先确定查找对应的 tbin 中是否存在缓存的内存块,如果存在则分配成功,否则找到 tbin 对应的 arena,从 arena 中对应的 bin 中分配region保存在 tbin 的 avail 数组中,最终从 availl 数组中选取一个地址进行内存分配,当内存释放时也会将被回收的内存块进行缓存。
2.2 Large场景
Large 场景的内存分配与 Small 类似,如果请求分配内存的大小大于 arena 中的最小的 bin,但是不大于 tcache 中能够缓存的最大块,依然会通过 tcache 进行分配,但是不同的是此时会分配 chunk 以及所对应的 run,从 chunk 中找到相应的内存空间进行分配。内存释放时也跟 samll 场景类似,会把释放的内存块缓存在 tacache 的 tbin 中。此外还有一种情况,当请求分配内存的大小大于tcache 中能够缓存的最大块,但是不大于 chunk 的大小,那么将不会采用 tcache 机制,直接在 chunk 中进行内存分配。
2.3 Huge场景
Huge 场景,如果请求分配内存的大小大于 chunk 的大小,那么直接通过 mmap 进行分配,调用 munmap 进行回收。
三、Netty内存管理
3.1 内存规格
Netty 对内存规格进行了分类,不同大小的内存块采用的分配策略是不同的,具体的内存规格分类见下图:
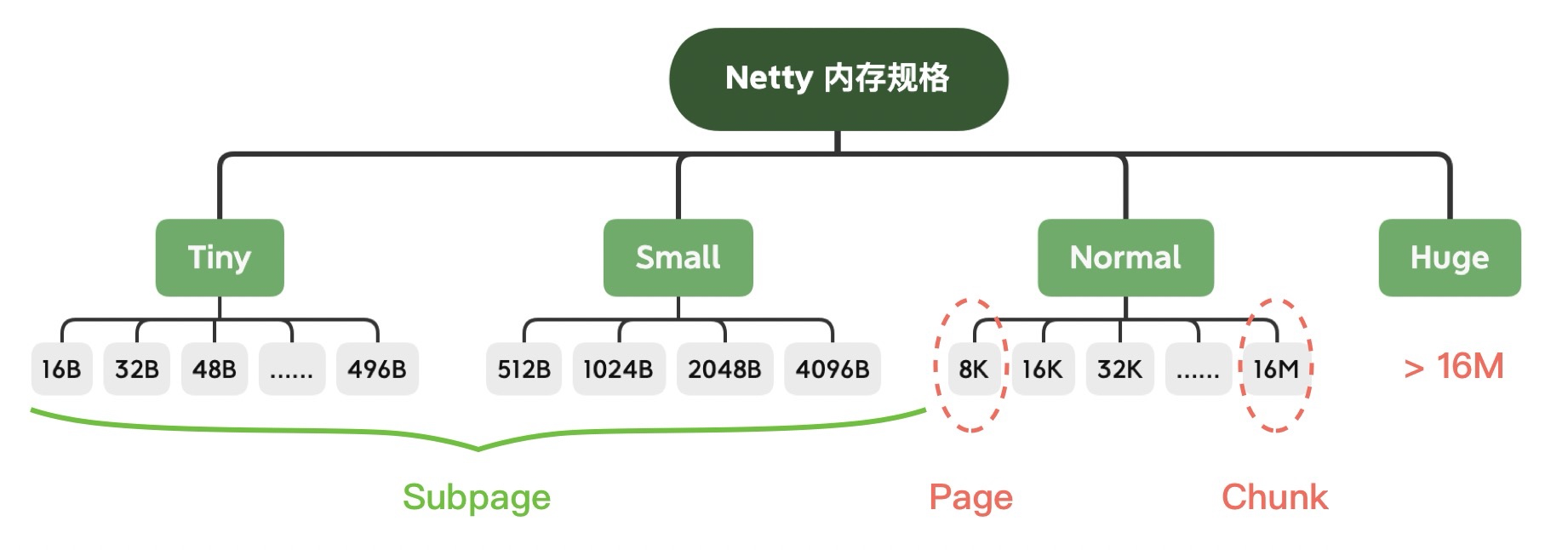
- Tiny:0 ~ 512B 之间的内存块;
- Small:512B ~ 8K 之间的内存块;
- Normal:8K ~ 16M 之间的内存块;
- Huge:大于 16M 的内存块。
Netty 定义了一个
SizeClass枚举类,描述上述的内存规格类型,分别为 Tiny、Small 和 Normal。但是并未在代码中定义Huge,当分配内存大于16M 时,可以归类为Huge,此时Netty直接以非池化方式分配内存。
Netty在上述每个区域内又定义了更细粒度的分配单位,分别为Chunk、Page、Subpage:
-
Chunk:Netty向操作系统申请内存的单位,所有的内存分配操作也是基于Chunk完成的,每个Chunk默认16M;
-
Page:Chunk 用于管理内存的单位,大小为 8K;
-
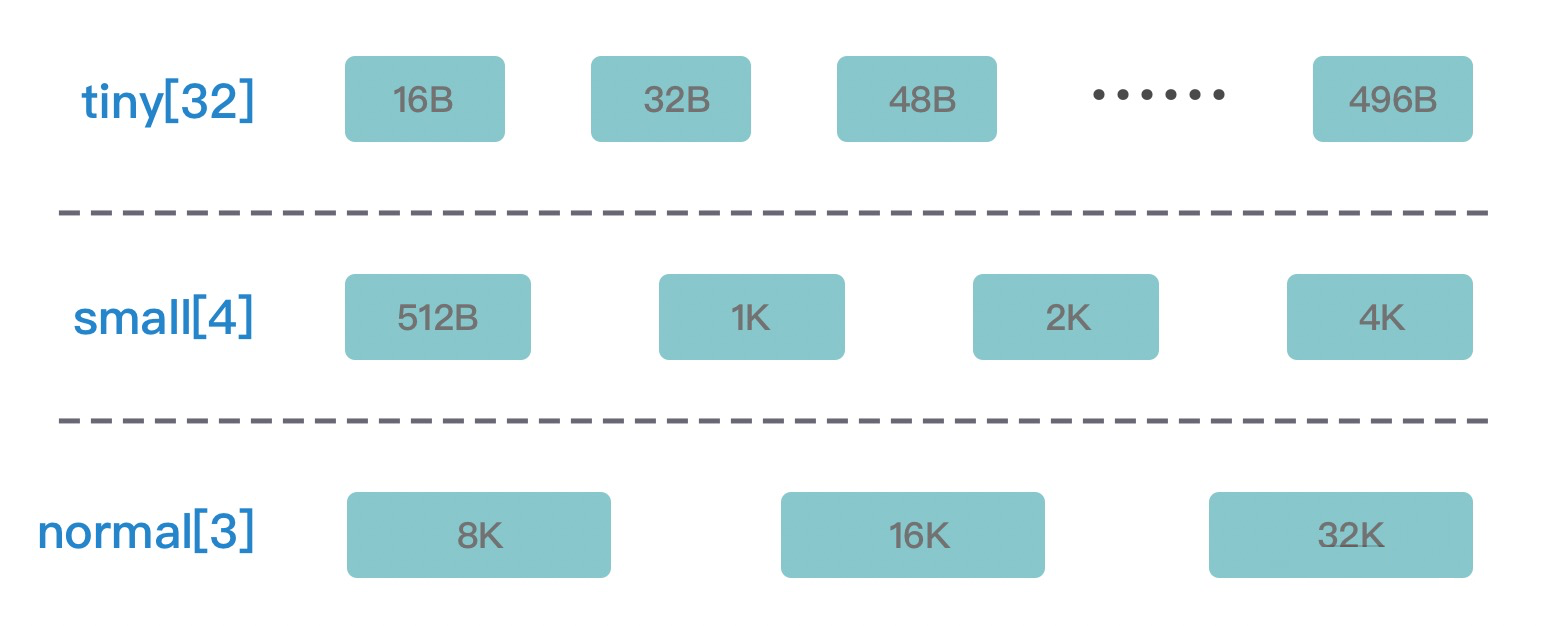
Subpage:负责Page内的内存分配,假如我们分配的内存大小远小于 Page,直接分配一个 Page 会造成严重的内存浪费,所以需要将 Page 划分为多个相同的子块进行分配,这里的子块就相当于 Subpage。按照 Tiny 和 Small 两种内存规格,SubPage 的大小也会分为两种情况:
- Tiny 场景下:最小的划分单位为 16B,按 16B 依次递增,16B、32B、48B ...... 496B;
- Small 场景下:总共可以划分为 512B、1024B、2048B、4096B 四种情况。Subpage 没有固定的大小,需要根据用户申请的缓冲区大小决定,例如申请1K内存时,Netty会把一个Page等分为8个1K的Subpage。
3.2 内存池架构
Netty中的内存池可以看作一个 Java 版本的 jemalloc 实现,并结合 JVM 的诸多特性做了部分优化。我们首先从全局看下 Netty内存池的整体架构:
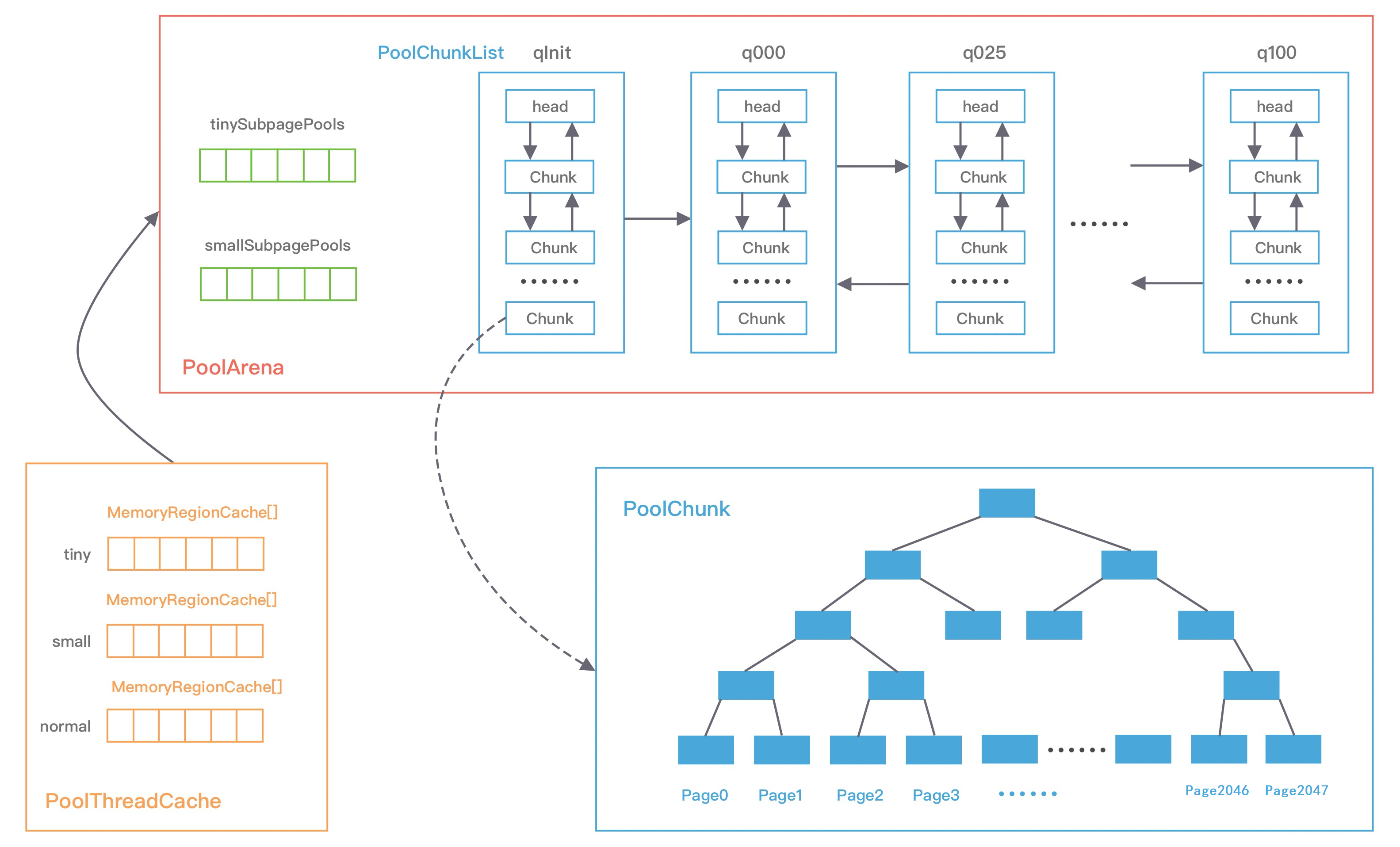
PoolArena
Netty 借鉴了 jemalloc 中 Arena 的设计思想,采用固定数量的多个 Arena 进行内存分配,Arena 的默认数量与 CPU 核数有关,通过创建多个 Arena 来缓解资源竞争问题,从而提高内存分配效率。线程在首次申请分配内存时,会通过 round-robin 的方式轮询 Arena 数组,选择一个固定的 Arena,在线程的生命周期内只与该 Arena 打交道,所以每个线程都保存了 Arena 信息,从而提高访问效率。
PoolArena的数据结构,如下图所示:
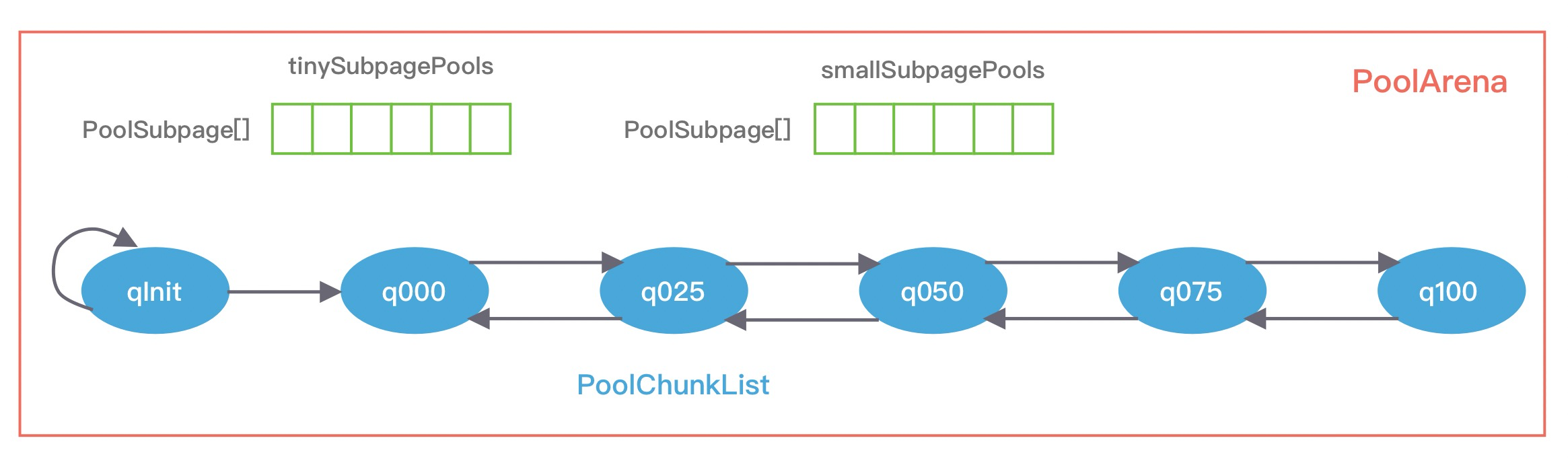
可以看到,PoolArena包含两个 PoolSubpage 数组和六个 PoolChunkList,两个 PoolSubpage 数组分别存放 Tiny 和 Small 类型的内存块(用于分配小于8K的内存,数组大小分别为32和4),六个 PoolChunkList 分别存储不同利用率的 PoolChunk(分配大于 8K 的内存,构成一个双向循环链表)。
六个 PoolChunkList,分别为 qInit、q000、q025、q050、q075、q100,分别代表不同的内存使用率,随着 PoolChunkList内部的PoolChunk内存使用率的变化,Netty会将PoolChunk在不同PoolChunkList中移动:
- qInit,内存使用率为 0 ~ 25% 的 PoolChunk;
- q000,内存使用率为 1 ~ 50% 的 PoolChunk;
- q025,内存使用率为 25% ~ 75% 的 PoolChunk;
- q050,内存使用率为 50% ~ 100% 的 PoolChunk;
- q075,内存使用率为 75% ~ 100% 的 PoolChunk;
- q100,内存使用率为 100% 的 PoolChunk。
每个 PoolChunkList 的上下限都有交叉重叠的部分,因为 Chunk 需要在不同 PoolChunkList 之间不断移动,如果每个 PoolChunkList 的内存使用率完全按照临界值衔接,例如 1 ~ 50%、50% ~ 75%,那么会导致 PoolChunk 在两个 PoolChunkList 间频繁移动,造成性能损耗。
在分配大于8K的内存时,PoolChunkList链表的访问顺序是
q050->q025->q000->qInit->q075,目的是使 PoolChunk 的使用率范围保持在中间水平,降低 PoolChunk 被回收的概率,从而兼顾性能。
PoolChunkList
PoolChunkList 负责管理多个 PoolChunk 的生命周期,每个 PoolChunkList 中存放内存使用率相近的 PoolChunk,这些 PoolChunk 同样以双向链表的形式连接在一起,如下图:
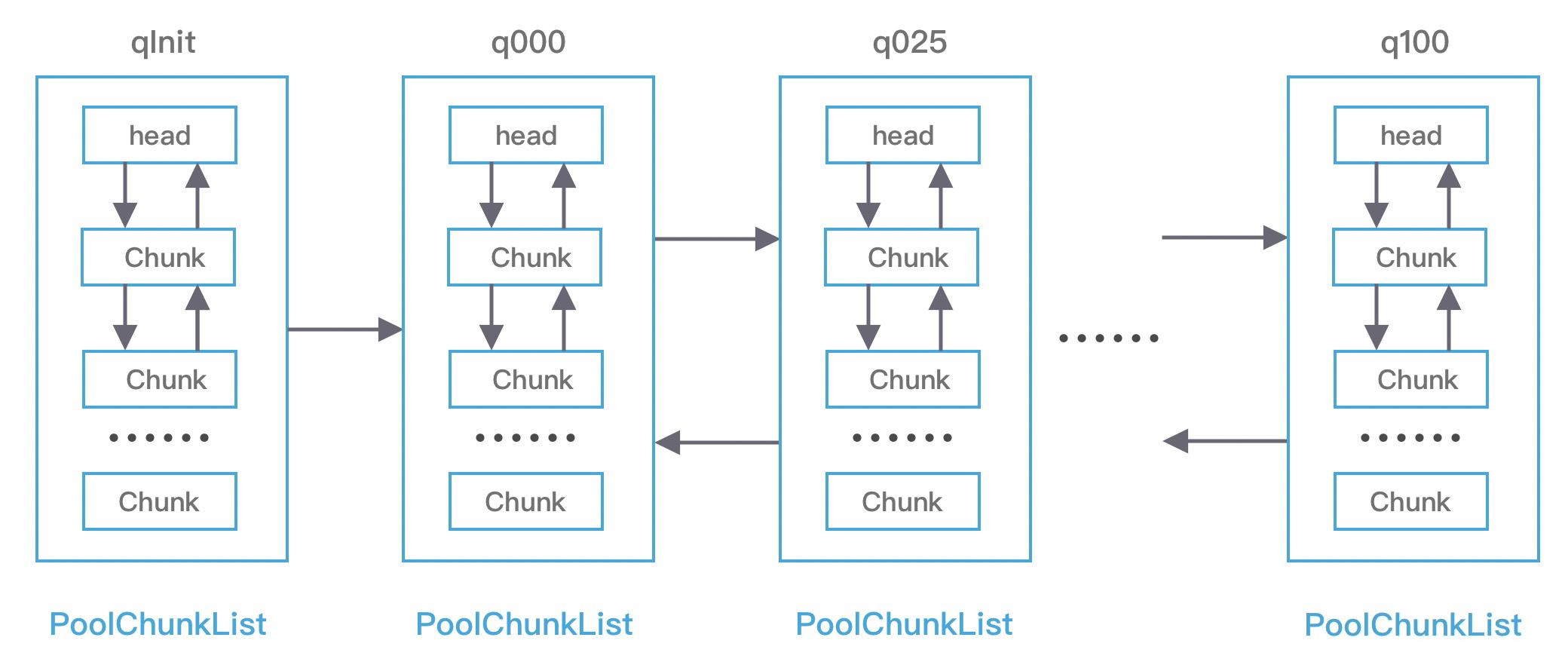
每个 PoolChunkList 都有内存使用率的上下限:minUsage 和 maxUsage,当 PoolChunk 进行内存分配后,如果使用率超过 maxUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到下一个 PoolChunkList。内存释放时,亦然。所以,对于这种频繁增删的操作,链表是比较好的数据结构。
PoolChunk
Netty 内存的分配和回收都是基于 PoolChunk 完成的,PoolChunk 是真正存储内存数据的地方,每个 PoolChunk 的默认大小为 16M。
PoolChunk 可以理解为 Page 的集合,在 Netty 中,Page指的是PoolChunk所管理的子内存块,采用PoolSubpage表示。Netty 会使用 伙伴算法 将 PoolChunk 分成 2048 个 Page,最终形成一颗满二叉树,二叉树中所有子节点的内存都由其父节点管理:
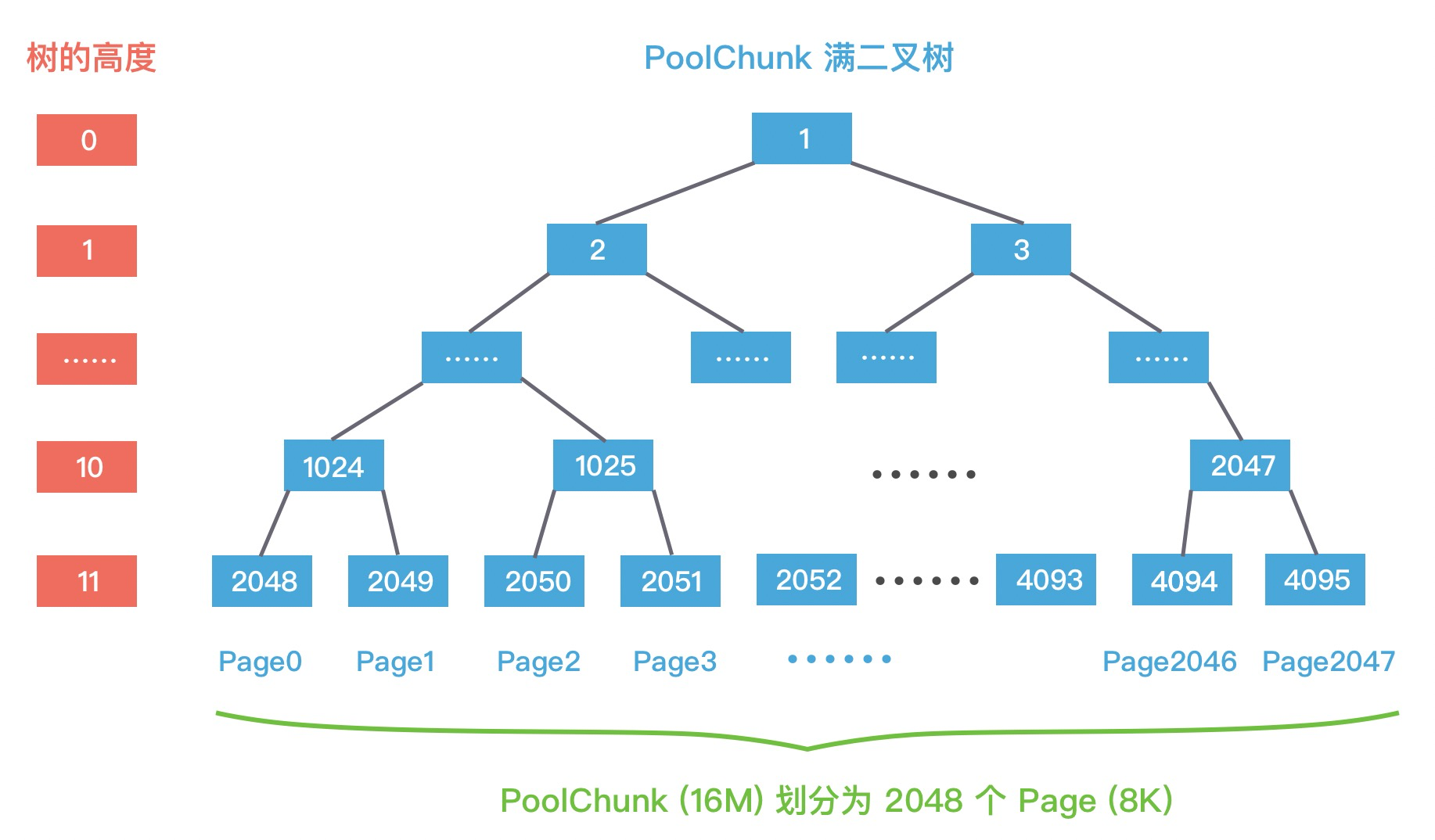
当分配的内存小于 8K 时,PoolChunk 中的每个 Page 节点会被划分成为更小粒度的内存块进行管理,小内存块同样以 PoolSubpage 管理。从图中可以看出,小内存的分配场景下,会首先找到对应的 PoolArena ,然后根据计算出对应的 tinySubpagePools 或者 smallSubpagePools 数组对应的下标,如果对应数组元素所包含的 PoolSubpage 链表不存在任何节点,那么将创建新的 PoolSubpage 加入链表中。
PoolSubpage
在小内存分配的场景下,即分配的内存小于8K,会使用 PoolSubpage 进行管理。PoolSubpage 通过位图 bitmap 记录子内存是否已经被使用:
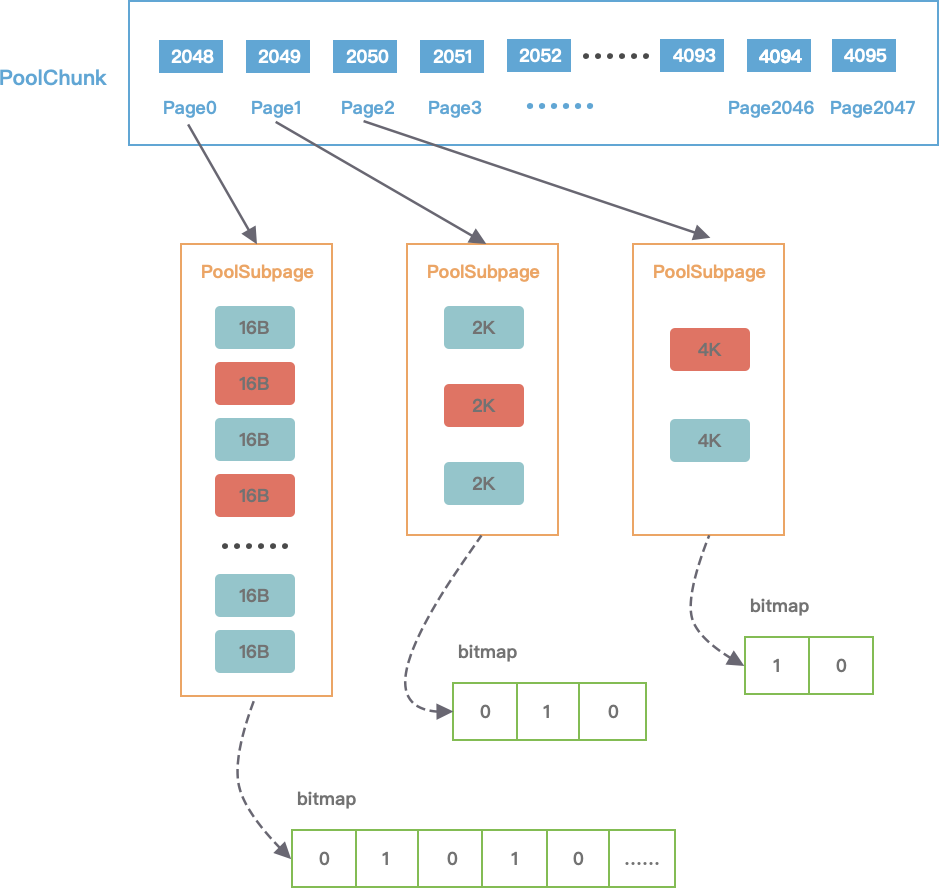
我们来看一个示例理解下,假设现在申请一块20B的内存。首先,向上取整为 32B,从满二叉树的第 11 层找到一个 PoolSubpage 节点,并把它等分为 8KB/32B = 256B 个小内存块,然后找到这个 PoolSubpage 节点对应的 PoolArena,将 PoolSubpage 节点与 tinySubpagePools[1] 对应的 head 节点连接成双向链表,形成下图所示的结构:
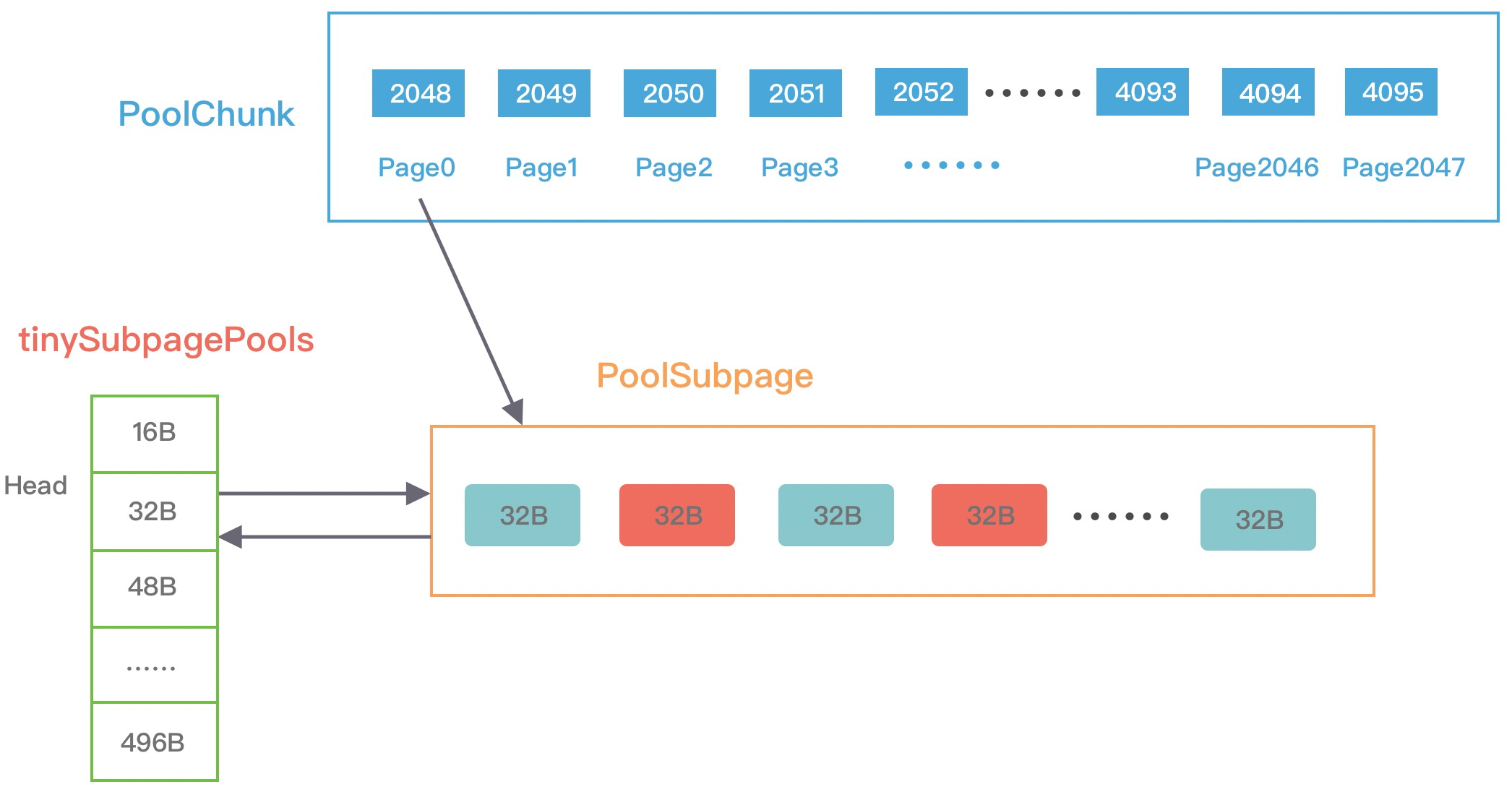
下次再有 32B 规格的内存分配时,会直接查找 PoolArena 中 tinySubpagePools[1] 元素的 next 节点是否存在可用的 PoolSubpage,如果存在将直接使用该 PoolSubpage 执行内存分配,从而提高了内存分配效率,其他内存规格的分配原理类似。
PoolThreadCache
PoolThreadCache ,对应的是 jemalloc 中本地线程缓存的概念。当内存释放时,与 jemalloc 一样,Netty 并没有将缓存归还给 PoolChunk,而是使用 PoolThreadCache 缓存起来,当下次有同样规格的内存分配时,直接从 PoolThreadCache 取出使用即可。PoolThreadCache 缓存 Tiny、Small、Normal 三种类型的数据,而且根据堆内和堆外内存的类型进行了区分,如 PoolThreadCache 的源码定义所示:
MemoryRegionCache
PoolThreadCache 中有一个重要的数据结构:MemoryRegionCache。MemoryRegionCache 实际就是一个队列,当内存释放时,将内存块加入队列当中,下次再分配同样规格的内存时,直接从队列中取出空闲的内存块。
PoolThreadCache 将不同规格大小的内存都使用单独的 MemoryRegionCache 维护,如下图所示:
图中的每个节点都对应一个 MemoryRegionCache,例如 Tiny 场景下对应的 32 种内存规格会使用 32 个 MemoryRegionCache 维护,所以 PoolThreadCache 源码中 Tiny、Small、Normal 类型的 MemoryRegionCache 数组长度分别为 32、4、3。
3.3 内存分配原理
Netty 中负责线程分配的组件有两个: PoolArena 和 PoolThreadCache 。PoolArena 是多个线程共享的,每个线程会固定绑定一个 PoolArena,PoolThreadCache 是每个线程私有的缓存空间,如下图所示:
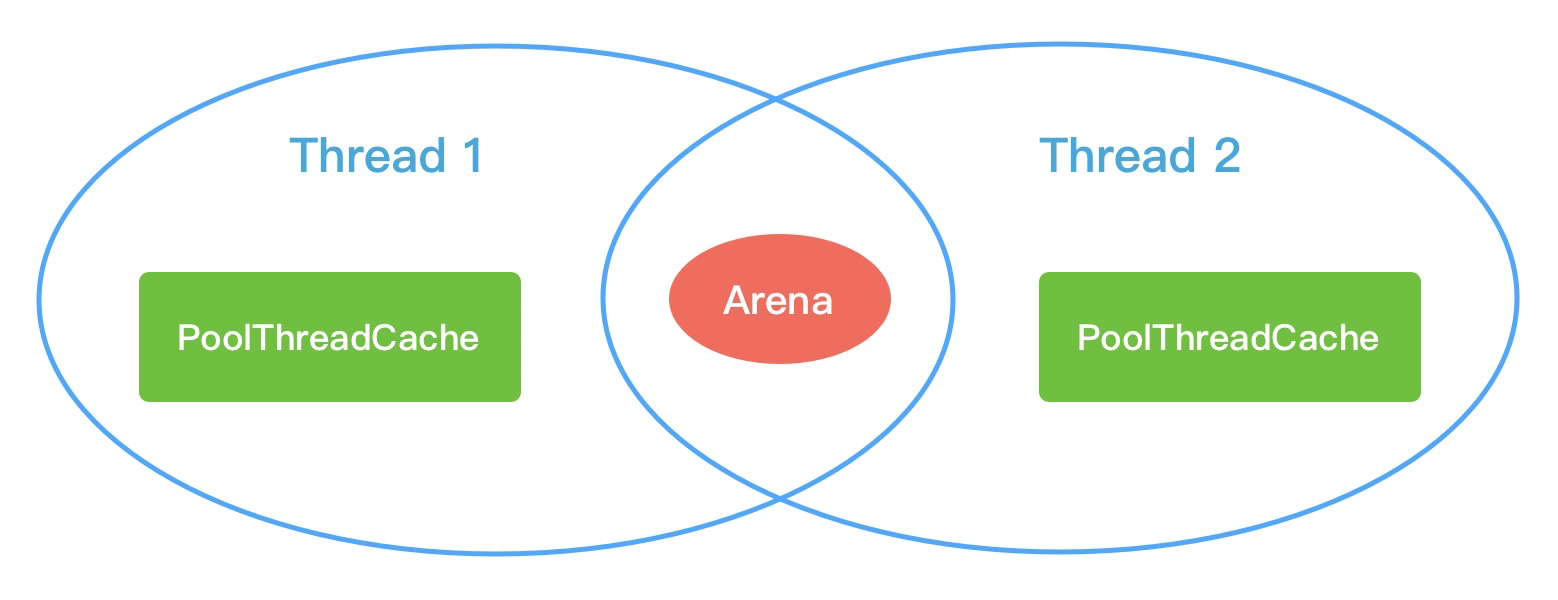
PoolArena 中管理的内存单位为 PoolChunk,每个 PoolChunk(16Mb) 会被划分为2048个8K的Page。在申请的内存大于 8K 时,PoolChunk 会以 Page 为单位进行内存分配。当申请的内存小于 8K 时,会由 PoolSubpage 管理更小粒度的内存分配。
PoolArena 分配的内存被释放后,不会立即会还给 PoolChunk,而且会缓存在本地私有缓存 PoolThreadCache 中,在下一次进行内存分配时,会优先从 PoolThreadCache 中查找匹配的内存块。
由此可见,Netty 中不同的内存规格采用的内存分配策略是不同的,主要分为以下三个场景:
- 分配内存大于 8K 时,PoolChunk 中采用的 Page 级别的内存分配策略:主要采用伙伴算法,尽可能保证分配内存地址的连续性,有效地降低内存碎片;
- 分配内存小于 8K 时,由 PoolSubpage 负责管理的内存分配策略:利用位图 bitmap ,节省内存空间,加快定位内存块的速度;
- 分配内存小于 8K 时,由 PoolThreadCache 本地线程缓存提供的内存分配。
对于内存回收而言,当用户线程释放内存时,会将内存块缓存到本地线程的私有缓存 PoolThreadCache 中,这样在下次分配内存时会提高分配效率,但是当内存块被用完一次后,再没有分配需求,那么一直驻留在内存中又会造成浪费。Netty 在线程退出的时候还会回收该线程的所有内存。
最后,我对 Netty 内存管理的设计思想做一个知识点总结:
- 分四种内存规格管理内存,分别为 Tiny、Samll、Normal、Huge,PoolChunk 负责管理 8K 以上的内存分配,PoolSubpage 用于管理 8K 以下的内存分配。当申请内存大于 16M 时,不会经过内存池,直接分配。;
- 设计了本地线程缓存机制 PoolThreadCache,用于提升内存分配时的并发性能。申请 Tiny、Samll、Normal 三种类型的内存时,会优先尝试从 PoolThreadCache 中分配;
- PoolChunk 使用伙伴算法管理 Page,以二叉树的数据结构实现,是整个内存池分配的核心所在;
- 调用 PoolThreadCache 的 allocate() 方法达到一定次数时,会检查 PoolThreadCache 中缓存的使用频率,使用频率较低的内存块会被释放;
- 线程退出时,Netty 会回收该线程对应的所有内存。
四、总结
本章,我对Netty的内存管理机制进行了深入讲解。Netty 引入了类似 jemalloc 的内存池管理技术,极大的提升了性能,Netty对于内存管理的设计思想,在缓存设计的场景下也值得借鉴学习。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
