RPC 框架需要通过网络完成跨 JVM 的通信,既然需要网络通信,就必然涉及使用序列化与反序列化的相关技术。下面我从 Java 序列化的基础内容开始,介绍常见的序列化算法,最后再分析 Dubbo 是如何支持这些序列化算法的。
一、Java序列化
Java语言原生支持序列化,使用起来分为如下几个步骤:
- 被序列化的对象实现
Serializable接口; - 生成一个序列化版本号
serialVersionUID,只有序列化和反序列化的 serialVersionUID 都相同的情况下,才能够成功地反序列化,如果类没有定义serialVersionUID, JDK 会随机生成一个; - 根据需求决定是否要重写 writeObject()/readObject() 方法,实现自定义序列化;
- 调用 java.io.ObjectOutputStream 的 writeObject()/readObject() 进行序列化与反序列化。
1.1 序列化算法
Java 自身提供的序列化操作非常简单,但是开源社区里还是有各种各样的序列化框架,因为这些 第三方序列化框架的速度更快、序列化的效率更高,而且支持跨语言操作 。本节,我先对这些常见的序列化算法进行介绍。
- Apache Avro :一种与编程语言无关的序列化框架。Avro 依赖于用户自定义的 Schema,在进行序列化数据的时候,无须多余的开销,就可以快速完成序列化,并且生成的序列化数据也较小。当进行反序列化的时候,需要获取到写入数据时用到的 Schema。Kafka、Hadoop 以及 Dubbo 中都可以使用 Avro 作为序列化方案。
- FastJson :阿里巴巴开源的 JSON 解析库,可以解析 JSON 格式的字符串。它支持将 Java 对象序列化为 JSON 字符串,反过来从 JSON 字符串也可以反序列化为 Java 对象。FastJson 的优点在于性能很高,比 Jackson 快 20% 左右,但是近几年 FastJson 的安全漏洞比较多,所以需要谨慎使用。
- Fst( fast-serialization) :一款高性能 Java 对象序列化工具包。100% 兼容 JDK 原生环境,序列化速度大概是JDK 原生序列化的 4~10 倍,序列化后的数据大小是 JDK 原生序列化大小的 1/3 左右。目前,Fst 已经更新到 3.x 版本,支持 JDK 14。
- Kryo :目前 Twitter、Yahoo、Apache 等都在使用该序列化技术,特别是 Spark、Hive 等大数据领域用得较多。Kryo 提供了一套快速、高效和易用的序列化 API。无论是数据库存储,还是网络传输,都可以使用 Kryo 完成 Java 对象的序列化。Kryo 还可以执行自动深拷贝和浅拷贝,支持环形引用。Kryo 的特点是 API 代码简单,序列化速度快,并且序列化之后得到的数据比较小。另外,Kryo 还提供了 NIO 的网络通信库——KryoNet。
- Hessian2 :一种支持动态类型、跨语言的序列化协议。Java 对象序列化的二进制流可以被其他语言使用。Hessian2 序列化之后的数据可以进行自描述,不会像 Avro 那样依赖外部的 Schema 描述文件或者接口定义。Dubbo 中使用的 Hessian2 序列化并不是原生的 Hessian2 序列化,而是阿里修改过的 Hessian Lite,它是 Dubbo 默认使用的序列化方式。其序列化之后的二进制流大小大约是 Java 序列化的 50%,序列化耗时大约是 Java 序列化的 30%,反序列化耗时大约是 Java 序列化的 20%。
- Protobuf :Google 开源的一套灵活、高效、自动化的、用于对结构化数据进行序列化的协议。相比于常用的 JSON 格式,Protobuf 有更高的转化效率,时间效率和空间效率都是 JSON 的 5 倍左右。Protobuf 可用于通信协议、数据存储等领域,它本身是语言无关、平台无关、可扩展的序列化结构数据格式。目前 Protobuf提供了 C++、Java、Python、Go 等多种语言的 API,gRPC 底层就是使用 Protobuf 实现的序列化。
二、Dubbo序列化
Dubbo的dubbo-serialization模块,提供了对多种序列化算法的支持:
其中的dubbo-serialization-api子模块定义了 Dubbo 序列化层的核心接口:

2.1 Serialization
Serialization是 Dubbo 序列化层最核心的接口之一。它是一个扩展接口,被 @SPI 修饰,默认的扩展实现是 Hessian2Serialization :
// Serialization.java
@SPI("hessian2")
public interface Serialization {
/**
* 获取ContentType的ID值,是一个byte类型的值,唯一确定一个算法.
*/
byte getContentTypeId();
/**
* 每一种序列化算法都对应一个ContentType,该方法用于获取ContentType.
*/
String getContentType();
/**
* 创建一个ObjectOutput对象,ObjectOutput负责实现序列化功能,即将Java对象转化为字节序列.
*/
@Adaptive
ObjectOutput serialize(URL url, OutputStream output) throws IOException;
/**
* 创建一个ObjectInput对象,ObjectInput负责实现反序列化功能,即将字节序列转换成Java对象
*
* @param url URL address for the remote service
* @param input the underlying input stream
* @return deserializer
* @throws IOException
*/
@Adaptive
ObjectInput deserialize(URL url, InputStream input) throws IOException;
}
2.2 Hessian2Serialization
下面我以默认的 hessian2 序列化方式为例,介绍 Serialization 接口的实现:
// Hessian2Serialization.java
public class Hessian2Serialization implements Serialization {
@Override
public byte getContentTypeId() {
return HESSIAN2_SERIALIZATION_ID;
}
@Override
public String getContentType() {
return "x-application/hessian2";
}
@Override
public ObjectOutput serialize(URL url, OutputStream out) throws IOException {
return new Hessian2ObjectOutput(out);
}
@Override
public ObjectInput deserialize(URL url, InputStream is) throws IOException {
return new Hessian2ObjectInput(is);
}
}
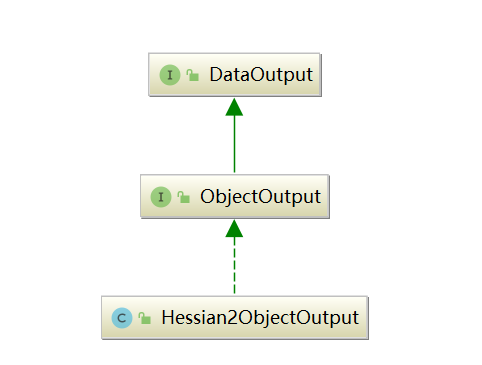
Hessian2Serialization.serialize() 方法创建了一个 Hessian2ObjectOutput 对象,Hessian2ObjectOutput继承自ObjectOutput,而ObjectOutput又继承了DataOutput,继承关系如下图所示:
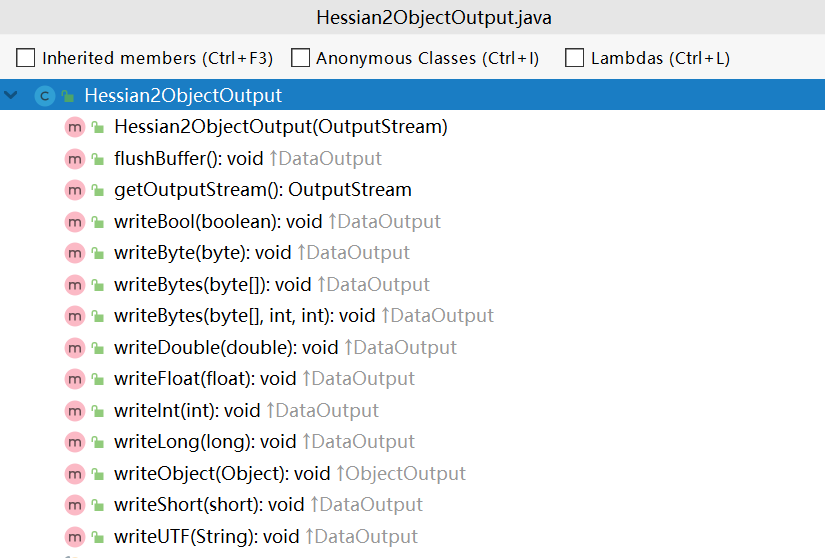
DataOutput 接口定义了序列化 Java 数据类型的各类方法,比如 boolean、short、int、long 等基础类型,也有 String、byte[] 类型:
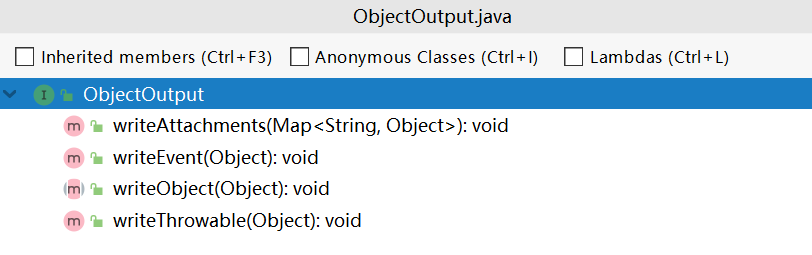
而 ObjectOutput 在DataOutput 接口的基础之上,添加了序列化对象的功能,其中的 writeThrowable()、writeEvent() 和 writeAttachments() 方法都是调用 writeObject() 方法实现的:
Hessian2ObjectOutput 内部封装了一个 Hessian2Output 对象,这个对象基于 ThreadLocal 与线程进行绑定,也就是说它是一个线程本地变量。在 DataOutput 接口以及 ObjectOutput 接口中,序列化各类型数据的方法都会委托给 Hessian2Output 对象的相应方法完成,这也保证了线程安全性:
// Hessian2ObjectOutput.java
public class Hessian2ObjectOutput implements ObjectOutput {
private static ThreadLocal<Hessian2Output> OUTPUT_TL = ThreadLocal.withInitial(() -> {
Hessian2Output h2o = new Hessian2Output(null);
h2o.setSerializerFactory(Hessian2SerializerFactory.SERIALIZER_FACTORY);
h2o.setCloseStreamOnClose(true);
return h2o;
});
// 每一个构造Hessian2ObjectOutput的线程,拥有独立的Hessian2Output对象
private final Hessian2Output mH2o;
public Hessian2ObjectOutput(OutputStream os) {
// 触发OUTPUT_TL的初始化
mH2o = OUTPUT_TL.get();
mH2o.init(os);
}
@Override
public void writeBool(boolean v) throws IOException {
mH2o.writeBoolean(v);
}
@Override
public void writeByte(byte v) throws IOException {
mH2o.writeInt(v);
}
@Override
public void writeObject(Object obj) throws IOException {
mH2o.writeObject(obj);
}
@Override
public void flushBuffer() throws IOException {
mH2o.flushBuffer();
}
public OutputStream getOutputStream() throws IOException {
return mH2o.getBytesOutputStream();
}
//...
}
Hessian2Serialization 中的 deserialize() 方法与 serialize() 方法类似,只不过构造的是一个Hessian2ObjectInput对象,我就不赘述了,大家可以自己阅读下源码。
三、总结
本章,我对 Java 序列化的基础知识进行了讲解,并介绍了常见的一些开源序列化框架。Dubbo的dubbo-serialization模块实现了底层的序列化功能,Dubbo采用Hessian作为默认的序列化实现。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
