Search API
搜索API(_search)允许用来执行搜索查询并返回匹配的结果。 可以使用简单查询字符串作为参数提供查询(URI形式),也可以使 用请求正文(body形式)。大多数搜索API都是支持多索引的, Explain API除外(用于调试性能)。
//语法
GET /<index>/_search
GET /_search
POST /<index>/_search
POST /_search
所有搜索API都支持跨索引机制,并支持多索引语法。例如,搜 索twitter索引中的所有文档:
GET /twitter/_search?q=user:kimchy
还可以在多个索引中搜索具有特定标记的所有文档,例如当每个 用户有一个索引时:
GET /kimchy,Elasticsearch/_search?q=tag:now
或者使用_all搜索所有可用索引:
GET /_all/_search?q=tag:now
为了确保快速响应,如果一个或多个分片失败,搜索API将以部 分结果响应。
1、URI模式
通过提供请求参数,可以纯粹使用URI执行搜索请求。在使用此 模式执行搜索时,并非所有搜索选项都可用,但对于快速的“测试” 来说,它非常方便。
GET twitter/_search?1=user:kimchy
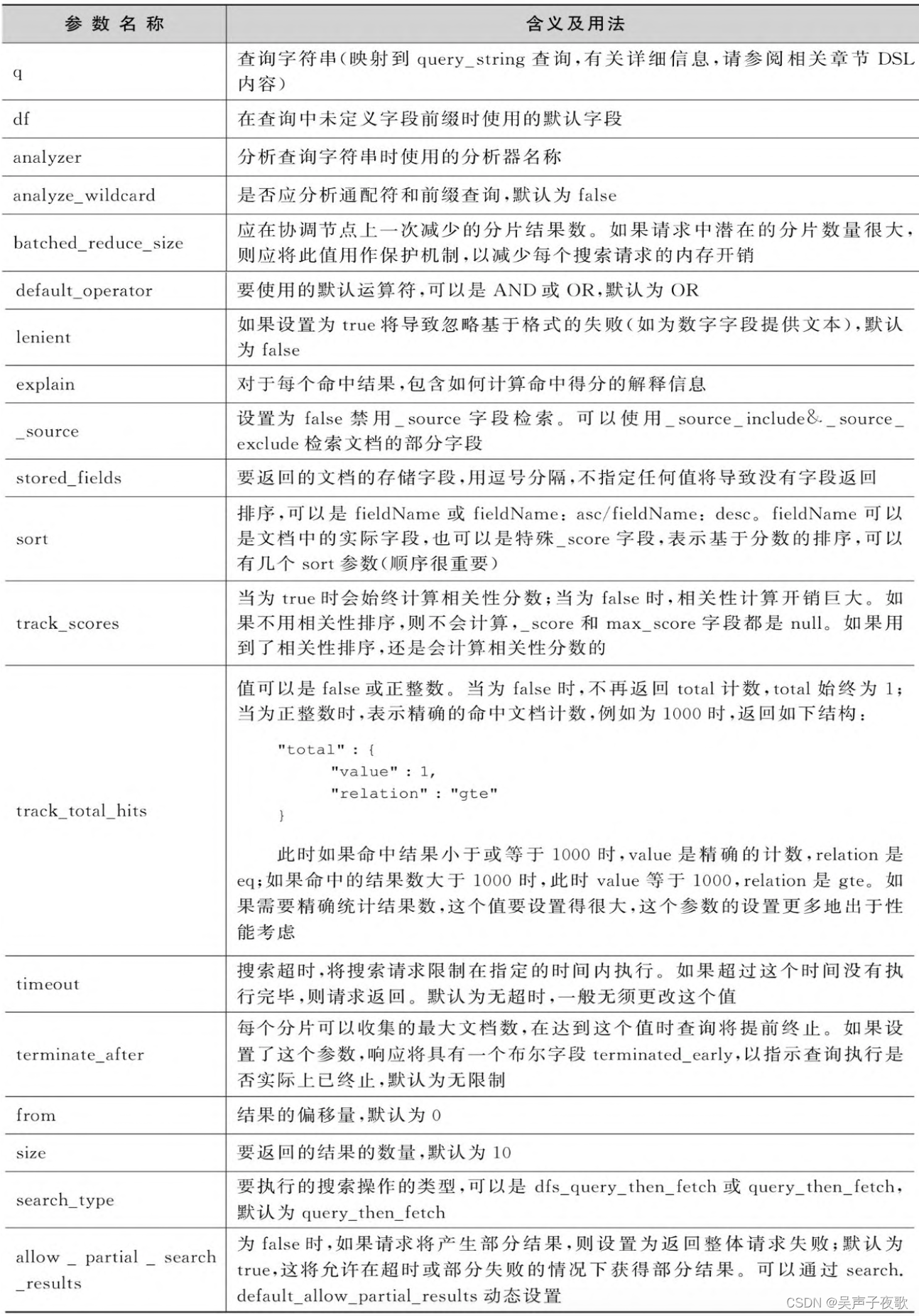
URI搜索模式支持的参数如下表:
2、Body模式
搜索请求可以在请求正文中使用Query DSL:
GET /twitter/_search
{
"query" : {
"term" : { "user" : "kimchy" }
}
}
Body搜索模式支持的参数如下表:

注 意 : search_type 、 request_cache 和 allow_partial_search_results必须作为查询字符串参数传递(不能放在body里面,要放在URL里面)。搜索请求的其余部分应该在主体内 部传递。正文内容也可以作为名为source的REST参数传递。HTTP GET 和HTTP POST都可以用于执行带Body的搜索。
terminate_after始终在post_filter之后应用,并在分片上收集到 足够的命中结果后停止查询和聚合。聚合上的文档计数可能不会反映 响应中的hits.total,因为聚合是在post_filter之前应用的。
如果只需要知道是否有任何文档匹配特定的查询,可以将size设 置为0,以表示对搜索结果不感兴趣。此外,还可以将 terminate_after设置为1,以指示只要找到第一个匹配的文档(每个 分片),就可以终止查询执行。示例如下:
GET /_search?q=message:number&size=0&terminate_after=1
{
"took": 3,
"timed_out": false,
"terminated_early": true,
"_shards": {
"total": 1,
"successful": 1,
"skipped" : 0,
"failed": 0
},
"hits": {
"total" : {
"value": 1,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
可以看到,响应结果中不包含任何文档,因为size设置为0。 hits.total将等于0,表示没有匹配的文档,或者大于0,表示在提前 终止查询时,至少有多个文档匹配此查询。此外,如果查询提前终 止,则在响应中将terminated_early标志设置为true。
响应中所用的时间took是处理此请求所用的毫秒数,从节点收到 查询后快速开始,直到完成所有与搜索相关的工作,然后再将上述 JSON返回到客户机。这意味着它包括在线程池中等待、在整个集群 中执行分布式搜索以及收集所有结果所花费的时间。
2.1、Explain参数
Explain参数是Elasticsearch提供的辅助API,经常不为人所知 和所用。Explain参数用来帮助分析文档的相关性分数是如何计算出 来的。
GET /test/_search
{
"explain": true,
"query": {
"match": {
"text": "hello"
}
}
}
返回:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_shard" : "[test][0]",
"_node" : "Cc6ARDA6TY-poOdtxvsA6g",
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"text" : "hello world",
"flag" : "foo"
},
"_explanation" : {
"value" : 0.2876821,
"description" : "weight(text:hello in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.2876821,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.2876821,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 1,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.45454544,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 2.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 2.0,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
}
]
}
}
结果形式上比较复杂,里面最重要的内容就是对文档计算得到的 总分以及总分的计算过程。如果总分等于0,则该文档将不能匹配给 定的查询。另一个重要内容是关于不同打分项的描述信息,根据查询 类型的不同,打分项会以不同方式对最后得分产生影响。
2.2、折叠结果(collapse)
允许基于字段值折叠(collapse)搜索结果。折叠是通过每个折 叠键仅选择顶部排序的文档来完成的。其实就是按照某个字段分组, 每个分组只取一条结果。例如,下面的查询示例为每个用户检索最好 的tweet,并按喜欢的次数(likes字段)对其进行排序。
GET /twitter/_search
{
"query": {
"match": {
"message": "elasticsearch"
}
},
"collapse" : {
"field" : "user"
},
"sort": ["likes"],
"from": 10
}
注意:响应中的命中total指示匹配文档的数量,是非折叠的结 果。非重复组(折叠后的数量)的总数是未知的。
用于折叠的字段必须是单值keyword或数字numeric字段,而且 doc_values属性开启。
示例:根据age字段折叠结果集,按balance倒序排序
GET /bank/_search
{
"query": {
"match": {
"address": "street"
}
},
"collapse": {
"field": "age"
},
"sort": [
{
"balance": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
返回:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 385,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "_doc",
"_id" : "854",
"_score" : null,
"_source" : {
"account_number" : 854,
"balance" : 49795,
"firstname" : "Jimenez",
"lastname" : "Barry",
"age" : 25,
"gender" : "F",
"address" : "603 Cooper Street",
"employer" : "Verton",
"email" : "jimenezbarry@verton.com",
"city" : "Moscow",
"state" : "AL"
},
"fields" : {
"age" : [
25
]
},
"sort" : [
49795
]
},
{
"_index" : "bank",
"_type" : "_doc",
"_id" : "926",
"_score" : null,
"_source" : {
"account_number" : 926,
"balance" : 49433,
"firstname" : "Welch",
"lastname" : "Mcgowan",
"age" : 21,
"gender" : "M",
"address" : "833 Quincy Street",
"employer" : "Atomica",
"email" : "welchmcgowan@atomica.com",
"city" : "Hampstead",
"state" : "VT"
},
"fields" : {
"age" : [
21
]
},
"sort" : [
49433
]
}
]
}
}
2.2.1、展开折叠结果
可以使用inner_hits选项展开每个折叠的顶部结果:
GET /bank/_search
{
"query": {
"match": {
"address": "street"
}
},
"collapse": {
"field": "age",
"inner_hits": {
"name":"inner_list",
"size":2,
"sort":[{"balance":{"order":"desc"}}]
},
"max_concurrent_group_searches": 4
},
"sort": [
{
"balance": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}
- name:响应中每个组内部展开结果使用的名称
- size:每个折叠键要检索的结果数,也就是每组返回多少个结 果。
- sort:如何对每组中的文档进行排序。
- max_concurrent_group_searches:允许每个组检索内部结果的并发请求数。
返回:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 385,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "_doc",
"_id" : "854",
"_score" : null,
"_source" : {
"account_number" : 854,
"balance" : 49795,
"firstname" : "Jimenez",
"lastname" : "Barry",
"age" : 25,
"gender" : "F",
"address" : "603 Cooper Street",
"employer" : "Verton",
"email" : "jimenezbarry@verton.com",
"city" : "Moscow",
"state" : "AL"
},
"fields" : {
"age" : [
25
]
},
"sort" : [
49795
],
"inner_hits" : {
"inner_list" : {
"hits" : {
"total" : {
"value" : 16,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "_doc",
"_id" : "854",
"_score" : null,
"_source" : {
"account_number" : 854,
"balance" : 49795,
"firstname" : "Jimenez",
"lastname" : "Barry",
"age" : 25,
"gender" : "F",
"address" : "603 Cooper Street",
"employer" : "Verton",
"email" : "jimenezbarry@verton.com",
"city" : "Moscow",
"state" : "AL"
},
"sort" : [
49795
]
},
{
"_index" : "bank",
"_type" : "_doc",
"_id" : "835",
"_score" : null,
"_source" : {
"account_number" : 835,
"balance" : 46558,
"firstname" : "Glover",
"lastname" : "Rutledge",
"age" : 25,
"gender" : "F",
"address" : "641 Royce Street",
"employer" : "Ginkogene",
"email" : "gloverrutledge@ginkogene.com",
"city" : "Dixonville",
"state" : "VA"
},
"sort" : [
46558
]
}
]
}
}
}
}
]
}
}
还可以为每个折叠组定义不同的展开请求参数。当希望获得折叠 的多个表示形式时,这很有用。示例如下:
GET /twitter/_search
{
"query": {
"match": {
"message": "elasticsearch"
}
},
"collapse" : {
"field" : "user",
"inner_hits": [
{
"name": "most_liked",
"size": 3,
"sort": ["likes"]
},
{
"name": "most_recent",
"size": 3,
"sort": [{ "date": "asc" }]
}
]
},
"sort": ["likes"]
}
2.2.2、二级折叠
二级折叠也是支持的,并可应用于inner_hits。例如,下面的请 求为每个国家(country字段)查找得分最高的tweet,在每个国家内 为每个用户查找得分最高的tweet。
GET /twitter/_search
{
"query": {
"match": {
"message": "elasticsearch"
}
},
"collapse" : {
"field" : "country",
"inner_hits" : {
"name": "by_location",
"collapse" : {"field" : "user"},
"size": 3
}
}
}
返回:
{
...
"hits": [
{
"_index": "twitter",
"_type": "_doc",
"_id": "9",
"_score": ...,
"_source": {...},
"fields": {"country": ["UK"]},
"inner_hits":{
"by_location": {
"hits": {
...,
"hits": [
{
...
"fields": {"user" : ["user124"]}
},
{
...
"fields": {"user" : ["user589"]}
},
{
...
"fields": {"user" : ["user001"]}
}
]
}
}
}
},
{
"_index": "twitter",
"_type": "_doc",
"_id": "1",
"_score": ..,
"_source": {...},
"fields": {"country": ["Canada"]},
"inner_hits":{
"by_location": {
"hits": {
...,
"hits": [
{
...
"fields": {"user" : ["user444"]}
},
{
...
"fields": {"user" : ["user1111"]}
},
{
...
"fields": {"user" : ["user999"]}
}
]
}
}
}
},
....
]
}
第二级折叠不允许再展开。
2.3、对结果分页
可以使用from和size参数对结果进行分页。from参数定义要获取 的第一个结果的偏移量,size参数表示要返回的最大结果的数量。
尽管可以将from和size设置为请求参数,但它们也可以在body中 设置。from默认值为0,size默认值为10,示例如下。
GET /_search
{
"from":0,
"size":10,
"query": {
"term":{"user":"kimchy"}
}
}
注意:from+size不能超过index.max_result_window参数设置的 值,后者的默认值为10000。增大此参数,会导致系统开销线性增大。
2.4、高亮结果
高亮器(Highlighter)用来标识出搜索结果中的一个或多个字段 中需要突出显示的代码段,以便向用户显示查询匹配的位置。
当请求中包括高亮的参数设置时,响应结果包含每个搜索命中的 高亮元素,其中包括突出显示的字段和突出显示的片段。
高亮器在提取要突出显示的项时不反映查询的布尔逻辑。因此, 对于某些复杂的布尔查询(例如嵌套布尔查询、 minimum_should_match等),可能会突出显示与查询匹配不对应 的部分文档。
高亮需要字段有实际内容(索引时将store设置为true)。如果未 存储字段(映射未将store设置为true),则加载实际的_source,并 从_source提取相关字段。
例如,使用默认高亮器对每条搜索结果中的content字段突出显 示,请在请求正文中包含一个highlight对象,该对象指定content字 段:
GET /bank/_search
{
"query": {
"match": {
"firstname": "Jimenez"
}
},
"highlight": {
"fields": {
"firstname": {}
}
}
}
{
"took" : 46,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 6.5052857,
"hits" : [
{
"_index" : "bank",
"_type" : "_doc",
"_id" : "854",
"_score" : 6.5052857,
"_source" : {
"account_number" : 854,
"balance" : 49795,
"firstname" : "Jimenez",
"lastname" : "Barry",
"age" : 25,
"gender" : "F",
"address" : "603 Cooper Street",
"employer" : "Verton",
"email" : "jimenezbarry@verton.com",
"city" : "Moscow",
"state" : "AL"
},
"highlight" : {
"firstname" : [
"<em>Jimenez</em>"
]
}
}
]
}
}
Elasticsearch支持三种高亮器:unified(基于BM25算法的高 亮器)、plain(Lucene标准高亮器)和fvh(快速矢量高亮器)。实 际应用中,可以为每个字段指定不同的高亮。
2.4.1、unified高亮器
unified高亮器使用的是Lucene Unified Highlighter。这个高亮 器将文本分成句子,并使用BM25算法对单个句子进行评分,就如同 它们是语料库中的文档。这是默认的高亮器。
2.4.2、plain高亮器
plain高亮器使用标准Lucene高亮器。它试图从词的重要性和短 语查询中的任何词定位条件来反映查询匹配逻辑。
plain高亮器最适合在单个字段中突出显示简单查询匹配项。为了 准确反映查询逻辑,它会创建一个很小的内存中的索引,并通过 Lucene的查询执行计划器重新运行原始查询条件,以访问当前文档的 低级匹配信息。对于需要突出显示的每个字段和每个文档,重复此操 作。如果想突出显示许多文档中的许多字段,进行较为复杂的查询, 作者建议在postings或term_vector字段上使用unified高亮器。
2.4.3、fvh高亮器
fvh高亮器使用Lucene快速矢量高亮器。此高亮器可用于在映射 中将term_vector设置为with_positions_offsets的字段。此高亮器特 点如下:
- 可以通过boundary_scanner参数进行自定义设置。
- 需要设置term_vector为with_positions_offsets,以增加索 引的大小。
- 可以将多个字段中的匹配项组合为一个结果。
- 可以为不同位置的匹配分配不同的权重,将短语匹配排序在 Term匹配前面,主要应用于boost查询(对某个字段加 权)。
2.4.4、为字段设置高亮器
如下示例中,对每个字段进行单独设置,覆盖全局高亮设置。
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"number_of_fragments" : 3,
"fragment_size" : 150,
"fields" : {
"body" : { "pre_tags" : ["<em>"], "post_tags" : ["</em>"] },
"blog.title" : { "number_of_fragments" : 0 },
"blog.author" : { "number_of_fragments" : 0 },
"blog.comment" : { "number_of_fragments" : 5, "order" : "score" }
}
}
}
2.4.5、highlight_query查询
可以指定highlight_query查询(重评分查询),以便在突出显 示时考虑其他信息。例如,下面的查询同时包含搜索查询和重新评分查询,如果用了highlight_query查询,突出显示将只考虑搜索查 询。
GET /_search
{
"query" : {
"match": {
"comment": {
"query": "foo bar"
}
}
},
"rescore": {
"window_size": 50,
"query": {
"rescore_query" : {
"match_phrase": {
"comment": {
"query": "foo bar",
"slop": 1
}
}
},
"rescore_query_weight" : 10
}
},
"_source": false,
"highlight" : {
"order" : "score",
"fields" : {
"comment" : {
"fragment_size" : 150,
"number_of_fragments" : 3,
"highlight_query": {
"bool": {
"must": {
"match": {
"comment": {
"query": "foo bar"
}
}
},
"should": {
"match_phrase": {
"comment": {
"query": "foo bar",
"slop": 1,
"boost": 10.0
}
}
},
"minimum_should_match": 0
}
}
}
}
}
}
2.4.6、高亮器类型选择
类型字段type允许强制使用特定的高亮器类型。允许值为 unified、plain和fvh。以下是强制使用plain高亮器的示例:
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"fields" : {
"comment" : {"type" : "plain"}
}
}
}
2.4.7、配置高亮器标签
默认情况下,高亮显示的文本包裹在<em>和</em>中。这可以 通过设置pre_tags标记和post_tags标记来控制,例如:
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"pre_tags" : ["<tag1>"],
"post_tags" : ["</tag1>"],
"fields" : {
"body" : {}
}
}
}
当使用快速矢量高亮器时,可以指定其他标签,并按重要性进行 排序,示例如下。
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"body" : {}
}
}
}
还可以使用内置样式的styled模式:
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"tags_schema" : "styled",
"fields" : {
"comment" : {}
}
}
}
2.4.8、_source字段高亮显示
可以强制高亮显示_source中的字段,即使字段是单独存储的, 示例如下:
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"fields" : {
"comment" : {"force_source" : true}
}
}
}
2.4.9、高亮显示所有字段
默认情况下,只高亮显示包含查询匹配的字段。设置 require_field_match为false可以高亮显示所有字段,示例如下。
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"require_field_match": false,
"fields": {
"body" : { "pre_tags" : ["<em>"], "post_tags" : ["</em>"] }
}
}
}
2.4.10、组合字段高亮显示
只有fvh高亮器支持这个特性。快速矢量高亮器可以把多个字段的 匹配结果组合成单个字段来高亮显示。对于以不同方式分析同一字符 串的多字段来说,这是最直观的。所有匹配的matched_fields字段都 必须将term_vector设置为with_positions_offsets,但只有匹配项组 合到的字段才会被加载,因此最好将该字段的store属性设置为 true(加速查询,无须加载_source)。
在 下 面 的 示 例 中 , comment 由 英 语 分 析 器 分 析 , comment.plain由标准分析器分析。
GET /_search
{
"query": {
"query_string": {
"query": "comment.plain:running scissors",
"fields": ["comment"]
}
},
"highlight": {
"order": "score",
"fields": {
"comment": {
"matched_fields": ["comment", "comment.plain"],
"type" : "fvh"
}
}
}
}
以上两种匹配查询既会匹配run with scissors,又会匹配 running with scissors。但只会高亮running和scissors,而不会高 亮run。如果这两个短语都出现在一个大文档中,那么running with scissors对应的文档将排在run with scissors对应的文档上方,因为 该片段中有更多的匹配项。用running scissors查询时,默认是OR 的关系,所以只要文档中出现其一就会匹配到,但只会高亮查询词 run和scissors,排序是同时命中两个词的文档会排在只命中一个词 的前面。示例如下。
GET /_search
{
"query": {
"query_string": {
"query": "running scissors",
"fields": ["comment", "comment.plain^10"]
}
},
"highlight": {
"order": "score",
"fields": {
"comment": {
"matched_fields": ["comment", "comment.plain"],
"type" : "fvh"
}
}
}
}
上面高亮显示了run以及running和scissors,但仍然将 running with scissors匹配的文档排序在run with scissors匹配文 档的前面,因为plain匹配(running)被加权了。
2.4.11、高亮字段排序
Elasticsearch按发送顺序显示高亮字段,但根据JSON规范,对 象是无序的。如果需要明确高亮字的显示顺序,请将高亮字段fields 指定为数组,用法如下。
GET /_search
{
"highlight": {
"fields": [
{ "title": {} },
{ "text": {} }
]
}
}
2.4.12、高亮片段控制
高亮的每个字段可以控制高亮显示片段的大小(以字符为单位, 默认值为100),以及要返回的最大片段数(默认值为5),示例如 下。
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"fields" : {
"comment" : {"fragment_size" : 150, "number_of_fragments" : 3}
}
}
}
除此之外,还可以指定高亮显示的片段按分数排序:
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"order" : "score",
"fields" : {
"comment" : {"fragment_size" : 150, "number_of_fragments" : 3}
}
}
}
如果number_of_fragments值设置为0,则不会生成片段,而是 高亮返回字段的全部内容。如果需要高亮显示短文本(如文档标题或 地址),但不需要片段,操作非常方便。注意,在这种情况下 fragment_size被忽略。示例如下。
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"fields" : {
"body" : {},
"blog.title" : {"number_of_fragments" : 0}
}
}
}
使用fvh时,可以使用fragment_offset参数控制要从中开始高亮 显示的边距。如果没有匹配的片段要高亮显示,则默认情况下不返回 任何内容。相反,可以通过将no_match_size(默认值为0)设置为 要返回的文本的长度,从字段开头返回一段文本。实际长度可能比指 定的短或长,因为它试图在单词边界上中断(不会把一个词截断)。
GET /_search
{
"query" : {
"match": { "user": "kimchy" }
},
"highlight" : {
"fields" : {
"comment" : {
"fragment_size" : 150,
"number_of_fragments" : 3,
"no_match_size": 150
}
}
}
}
2.4.13、Posting List的应用
Posting List就是一个整型数组,存储了所有符合某个Term的文 档ID。
以下示例在索引映射中设置comment字段以允许使用Posting List高亮显示结果。
PUT /example
{
"mappings": {
"properties": {
"comment" : {
"type": "text",
"index_options" : "offsets"
}
}
}
}
下面是设置comment字段以允许使用term_vectors向量(这将 导致索引更大)的示例:
PUT /example
{
"mappings": {
"properties": {
"comment" : {
"type": "text",
"term_vector" : "with_positions_offsets"
}
}
}
}
2.4.14、为Plain高亮器指定片段
使用Plain高亮器时,可以在simple片段和span片段之间进行选 择:
GET twitter/_search
{
"query" : {
"match_phrase": { "message": "number 1" }
},
"highlight" : {
"fields" : {
"message" : {
"type": "plain",
"fragment_size" : 15,
"number_of_fragments" : 3,
"fragmenter": "simple"
}
}
}
}
2.5、索引加权
在搜索多个索引时,可以为每个索引配置不同的权重。当来自一 个索引的命中文档比来自另一个索引的更重要时,这非常方便。
GET /_search
{
"indices_boost" : {
"index1" : 1.4,
"index2" : 1.3
}
}
这在使用别名或通配符表达式时很重要。如果找到多个匹配项, 将使用第一个匹配项。例如,如果一个索引同时包含在alias1和 index*中,则将应用1.4的boost值。
GET /_search
{
"indices_boost" : [
{ "alias1" : 1.4 },
{ "index*" : 1.3 }
]
}
2.6、命中文档嵌套
父联接(parent-join)和嵌套(nested)功能允许返回在不同 范围内具有匹配项的文档。在父/子案例中,父文档基于子文档中的匹配项返回,或者子文档基于父文档中的匹配项返回。在嵌套的情况 下,基于嵌套内部对象中的匹配项返回文档。
在这两种情况下,导致返回文档的不同范围中的实际匹配都是隐 藏的。在许多情况下,了解哪些内部嵌套对象(对于嵌套对象)或子 /父文档(对于父/子文档)导致返回某些信息是非常必要的。此功 能在搜索响应中返回每次搜索命中的其他嵌套命中,这些嵌套命中导 致搜索命中在不同范围内匹配。
使用方法是通过在nested、has_child或has_parent查询和筛选 上定义内部定义inner_hits。结构如下:
"<query>" : {
"inner_hits" : {
<inner_hits_options>
}
}
如果在查询上定义了inner_hits,那么每个搜索命中都将包含一 个具有以下结构的inner_hits JSON对象:
"hits": [
{
"_index": ...,
"_type": ...,
"_id": ...,
"inner_hits": {
"<inner_hits_name>": {
"hits": {
"total": ...,
"hits": [
{
"_type": ...,
"_id": ...,
...
},
...
]
}
}
},
...
},
...
]
2.6.1、嵌套的inner_hits
嵌套的inner_hits可用于将嵌套的内部对象包含为搜索命中的内 部命中。示例如下:
PUT test
{
"mappings": {
"properties": {
"comments": {
"type": "nested"
}
}
}
}
PUT test/_doc/1?refresh
{
"title": "Test title",
"comments": [
{
"author": "kimchy",
"number": 1
},
{
"author": "nik9000",
"number": 2
}
]
}
POST test/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"match": {"comments.number" : 2}
},
"inner_hits": {}
}
}
}
返回:
{
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "Test title",
"comments" : [
{
"author" : "kimchy",
"number" : 1
},
{
"author" : "nik9000",
"number" : 2
}
]
},
"inner_hits" : {
"comments" : {
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_nested" : {
"field" : "comments",
"offset" : 1
},
"_score" : 1.0,
"_source" : {
"number" : 2,
"author" : "nik9000"
}
}
]
}
}
}
}
]
}
}
在上面的例子中,嵌套元数据_nested是至关重要的,因为它定 义了这个内部命中来自哪个内部嵌套对象。Field定义嵌套命中来自的 对象数组字段,以及相对于其在_source中位置的偏移量offset。由于 排序和评分,inner_hits中命中对象的实际位置通常与定义嵌套内部 对象的位置不同。
默认情况下,也会为inner_hits中的命中对象返回_source,但 这可以更改。通过_source过滤功能可以返回部分字段。如果在嵌套 级别上定义了存储字段,也可以通过fields功能返回这些字段。
一个重要的默认行为是,在返回结果中,inner_hits元素中的 hits元素的_source字段只包含定义为_nested类型的字段。因此在上 面的示例中,每次嵌套命中只返回注释部分,而不是包含注释的顶级 文档的整个源。
2.6.2、嵌套内部名字和_source
嵌套文档没有_source字段,因为整个文档_source是与根文档一 起存储在其_source字段下。为了仅包含嵌套文档的源,将解析根文 档的源,并且只将嵌套文档的相关bit作为源包含在内部命中中。为每 个匹配的嵌套文档执行此操作会影响执行整个搜索请求所需的时间, 特别是当size和内部命中数的size设置高于默认值时,会付出相对昂 贵的代价。为了避免为获取嵌套内部命中的_source而解析整个根文 档的_source,可以禁用返回_source的功能(“source”:false), 并且只依赖于doc values字段。示例如下:
PUT test
{
"mappings": {
"properties": {
"comments": {
"type": "nested"
}
}
}
}
PUT test/_doc/1?refresh
{
"title": "Test title",
"comments": [
{
"author": "kimchy",
"text": "comment text"
},
{
"author": "nik9000",
"text": "words words words"
}
]
}
POST test/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"match": {"comments.text" : "words"}
},
"inner_hits": {
"_source" : false,
"docvalue_fields" : [
"comments.text.keyword"
]
}
}
}
}
返回:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0444684,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0444684,
"_source" : {
"title" : "Test title",
"comments" : [
{
"author" : "kimchy",
"text" : "comment text"
},
{
"author" : "nik9000",
"text" : "words words words"
}
]
},
"inner_hits" : {
"comments" : {
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0444684,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_nested" : {
"field" : "comments",
"offset" : 1
},
"_score" : 1.0444684,
"fields" : {
"comments.text.keyword" : [
"words words words"
]
}
}
]
}
}
}
}
]
}
}
2.6.3、嵌套对象字段和内部命中的层次级别
如果映射具有多层次嵌套对象字段,则可以通过点标记访问每个 级别。例如,如果有一个包含votes嵌套字段的comments嵌套字 段,并且votes应直接与根一起返回,则可以定义以下路径:
PUT test
{
"mappings": {
"properties": {
"comments": {
"type": "nested",
"properties": {
"votes": {
"type": "nested"
}
}
}
}
}
}
PUT test/_doc/1?refresh
{
"title": "Test title",
"comments": [
{
"author": "kimchy",
"text": "comment text",
"votes": []
},
{
"author": "nik9000",
"text": "words words words",
"votes": [
{"value": 1 , "voter": "kimchy"},
{"value": -1, "voter": "other"}
]
}
]
}
POST test/_search
{
"query": {
"nested": {
"path": "comments.votes",
"query": {
"match": {
"comments.votes.voter": "kimchy"
}
},
"inner_hits" : {}
}
}
}
返回:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.6931471,
"_source" : {
"title" : "Test title",
"comments" : [
{
"author" : "kimchy",
"text" : "comment text",
"votes" : [ ]
},
{
"author" : "nik9000",
"text" : "words words words",
"votes" : [
{
"value" : 1,
"voter" : "kimchy"
},
{
"value" : -1,
"voter" : "other"
}
]
}
]
},
"inner_hits" : {
"comments.votes" : {
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_nested" : {
"field" : "comments",
"offset" : 1,
"_nested" : {
"field" : "votes",
"offset" : 0
}
},
"_score" : 0.6931471,
"_source" : {
"voter" : "kimchy",
"value" : 1
}
}
]
}
}
}
}
]
}
}
2.6.4、父子嵌套
父/子inner_hits可用于包括父或子对象,示例如下:
PUT test
{
"mappings": {
"properties": {
"my_join_field": {
"type": "join",
"relations": {
"my_parent": "my_child"
}
}
}
}
}
PUT test/_doc/1?refresh
{
"number": 1,
"my_join_field": "my_parent"
}
PUT test/_doc/2?routing=1&refresh
{
"number": 1,
"my_join_field": {
"name": "my_child",
"parent": "1"
}
}
POST test/_search
{
"query": {
"has_child": {
"type": "my_child",
"query": {
"match": {
"number": 1
}
},
"inner_hits": {}
}
}
}
返回:
{
"took" : 13,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"number" : 1,
"my_join_field" : "my_parent"
},
"inner_hits" : {
"my_child" : {
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_routing" : "1",
"_source" : {
"number" : 1,
"my_join_field" : {
"name" : "my_child",
"parent" : "1"
}
}
}
]
}
}
}
}
]
}
}
2.7、分数值过滤
如下实例中,排除得分_score低于设定的min_score的文档:
GET /_search
{
"min_score": 0.5,
"query" : {
"term" : { "user" : "kimchy" }
}
}
注意:大多数情况下,这没有多大意义,但它是为高级用例提供 的。
2.8、查询命名
可以为每个查询或过滤起个名字:
GET /_search
{
"query": {
"bool" : {
"should" : [
{"match" : { "name.first" : {"query" : "shay", "_name" : "first"} }},
{"match" : { "name.last" : {"query" : "banon", "_name" : "last"} }}
],
"filter" : {
"terms" : {
"name.last" : ["banon", "kimchy"],
"_name" : "test"
}
}
}
}
}
搜索响应将包括matched_queries。查询和过滤器的命名只对 bool查询有意义。
2.9、post_filter过滤
在计算聚合之后,post_filter用来对搜索结果进行二次过滤。其 目的通过如下示例来解释:
PUT /shirts
{
"mappings": {
"properties": {
"brand": { "type": "keyword"},
"color": { "type": "keyword"},
"model": { "type": "keyword"}
}
}
}
PUT /shirts/_doc/1?refresh
{
"brand": "gucci",
"color": "red",
"model": "slim"
}
假设用户指定了两个过滤器:color:red和brand:gucci。通常 情况下,也可以使用bool查询进行此操作:
GET /shirts/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "color": "red" }},
{ "term": { "brand": "gucci" }}
]
}
}
}
但是,用户可能还需要使用faceted切面导航来显示用户可以单击 的其他选项的列表。也许有一个model字段,允许用户将搜索结果限 制为t-shirts或dress-shirts。

可以使用如下聚合查询,实现上述功能:
GET /shirts/_search
{
"query": {
"bool": {
"filter": [
{ "term": { "color": "red" }},
{ "term": { "brand": "gucci" }}
]
}
},
"aggs": {
"models": {
"terms": { "field": "model" }
}
}
}
同时,用户可能需要知道有多少其他颜色的Gucci衬衫。如果只 是在颜色字段color上添加一个Term聚合,那么将只返回red对应的结 果,因为查询只返回Gucci的红色衬衫。
相反,用户希望在聚合期间包含所有颜色的衬衫,然后只将 colors过滤器应用于搜索结果。这是post_filter过滤器的目的:
GET /shirts/_search
{
"query": {
"bool": {
"filter": {
"term": { "brand": "gucci" }
}
}
},
"aggs": {
"colors": {
"terms": { "field": "color" }
},
"color_red": {
"filter": {
"term": { "color": "red" }
},
"aggs": {
"models": {
"terms": { "field": "model" }
}
}
}
},
"post_filter": {
"term": { "color": "red" }
}
}
2.10、分片选择(preference)
参数preference控制要对其执行搜索的分片的选择机制。默认情 况下,Elasticsearch以未指定的顺序从可用的分片中进行选择。但 是,有时可能需要尝试将某些搜索路由到特定的分片副本集,以更好 地利用每个副本的缓存。
preference是一个查询字符串参数,可以设置为如下参数:
- _only_local :该操作将仅在接受请求的本地节点的分片上执 行。
- _local :优先选择本地的分片,本地没有对应分片或对应分 片不可用时再路由到其他分片。
- _prefer_nodes :abc,xyz:如果可能,该操作将在具有提 供的节点ID之一的节点上执行(本例中为abc或xyz)。如果 在多个选定节点上存在合适的分片副本,则这些副本之间的 首选顺序不确定。指定的ID不满足时会路由到其他分片。
- _shards :2,3:将操作限制在为指定的分片,本例中为2 和3。此首选项可以与其他首选项组合,但必须首先配置: _shards:2,3_u local。
- _only_nodes :abc*,x*yz,…:将操作限制到根据节点规 范指定的节点。如果在多个选定节点上存在合适的分片副 本,则这些副本之间的首选顺序不确定。
在实际生产环境中用得最多的是_local,可以节省一定的网络开 销。
2.11、重排序
重新排序有助于提高检索结果的精度,只需重新排序顶部(例如 100-500)文档,使用二级(通常更昂贵)算法,而不是将昂贵的算 法应用于索引中的所有文档。
在每个分片返回其结果给协调节点之前,就会执行重排序 (rescore)请求。
目前,rescore API只有一个实现:query rescorer,它使用查询 来调整评分。在未来,可能会有其他的实现方式。
如果在重排序查询rescore中提供了显式排序,则将引发错误。既 然重排序,就不能再自定义排序。
当向用户显示分页时,不应该在单步浏览每个页面时更改窗口大 小window_size(通过传递不同的值),因为这样会改变顶部命中, 导致结果在用户单步浏览页面时发生令人困惑的移动(结果重复或缺 少某些文档)。
查询重新排序器(query rescorer)仅对查询和post_filter筛选 阶段返回的前k个结果执行二次查询。每个分片上要检查的文档数可 以由window_size参数控制,该参数默认为10。
默认情况下,原始查询和重排序查询的分数是线性组合的,以生 成每个文档的最终分数。原始查询和重排序查询的相对重要性可以分 别 用 查 询 权 重 query_weight 和 重 排 序 查 询 权 重 rescore_query_weight来控制。两者都默认为1。下面是一个具体示 例:
POST /_search
{
"query" : {
"match" : {
"message" : {
"operator" : "or",
"query" : "the quick brown"
}
}
},
"rescore" : {
"window_size" : 50,
"query" : {
"rescore_query" : {
"match_phrase" : {
"message" : {
"query" : "the quick brown",
"slop" : 2
}
}
},
"query_weight" : 0.7,
"rescore_query_weight" : 1.2
}
}
}
score_mode控制分数的组合方式,支持以下模式:
- total:加总原始查询和重排序查询的分数,这是默认方式。
- multiply:原始分数乘以重排序查询分数,适用于函数查询 的重排序。
- avg:原始查询和重排序查询的分数取平均值。
- max:原始查询和重排序查询的分数取二者的最大值。
- min:原始查询和重排序查询的分数取二者的最小值。
下面示例按顺序执行多个重排序查询:
POST /_search
{
"query" : {
"match" : {
"message" : {
"operator" : "or",
"query" : "the quick brown"
}
}
},
"rescore" : [ {
"window_size" : 100,
"query" : {
"rescore_query" : {
"match_phrase" : {
"message" : {
"query" : "the quick brown",
"slop" : 2
}
}
},
"query_weight" : 0.7,
"rescore_query_weight" : 1.2
}
}, {
"window_size" : 10,
"query" : {
"score_mode": "multiply",
"rescore_query" : {
"function_score" : {
"script_score": {
"script": {
"source": "Math.log10(doc.likes.value + 2)"
}
}
}
}
}
} ]
}
首先第一个query获取查询结果,然后第二个query得到第一个 query的结果。第二个rescore将“看到”第一个rescore所做的排 序,因此可以使用第一个rescore上的大窗口将文档拉到第二个 rescore的较小窗口中。
2.12、脚本字段
允许为每次命中返回脚本(script)计算值(基于不同字段), 例如:
GET /_search
{
"query" : {
"match_all": {}
},
"script_fields" : {
"test1" : {
"script" : {
"lang": "painless",
"source": "doc['price'].value * 2"
}
},
"test2" : {
"script" : {
"lang": "painless",
"source": "doc['price'].value * params.factor",
"params" : {
"factor" : 2.0
}
}
}
}
}
脚本字段可以处理未存储的字段,并允许返回自定义值(脚本的 计算值)。
脚 本 字 段 还 可 以 访 问 实 际 的 _source 文 档 , 并 使 用 params[‘_source’]从中提取要返回的特定元素。下面是一个例子:
GET /_search
{
"query" : {
"match_all": {}
},
"script_fields" : {
"test1" : {
"script" : "params['_source']['message']"
}
}
}
理解doc[‘my_field’].value和params[‘_source’][‘my_field’]之间 的区别很重要。本节第一个示例,使用doc关键字,将导致该字段的 Term被加载到内存(缓存),致使更快的执行速度,但会造成更多的 内存消耗。另外,doc[…]表示法只允许简单值字段(不能从中返回 JSON对象),并且只对非分析字段或基于单Term的字段有意义。但 是,如果可能,使用doc仍然是从文档中访问值的推荐方法,因为每 次使用_source时都必须加载和分析,导致使用_source非常慢。
2.13、滚动查询
当搜索请求返回单个“页面”的结果时,可以使用滚动查询 (scroll)API从单个搜索请求中检索大量结果(甚至是所有结果), 这与在传统数据库中使用游标的方式非常相似。
滚动不适用于实时用户请求,而适用于处理大量数据,例如为了 将一个索引的内容重新索引到具有不同配置的新索引中。
从滚动请求返回的结果反映了在发出初始搜索请求时索引的状 态,如及时快照。对文档的后续更改(索引、更新或删除)只会影响 以后的搜索请求。
为了使用滚动搜索功能,初始搜索请求应该在查询字符串中指定 scroll参数,该参数告诉Elasticsearch“搜索上下文”应保持活动多长时间,例如scroll=1m。示例如下:
POST /twitter/_search?scroll=1m
{
"size": 100,
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
上述请求的结果包括一个_scroll_id,它应该传递给scroll API, 以便检索下一批结果:
POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
上述示例中,scroll参数告诉Elasticsearch将搜索上下文再保持 活跃时间1m。scroll_id参数是上一次查询的返回值。
size参数用来配置每批结果返回的最大命中数。对scroll API的每 次调用都会返回下一批结果,直到没有更多的结果可以返回,即hits 数组为空。
初始搜索请求和随后的每个滚动请求都返回一个_scroll_id。虽 然_scroll_id可能在请求之间发生变化,但它并不总是变化。在任何 情况下,只应使用最近收到的_scroll_id。
如果请求指定聚合,则只有初始搜索响应将包含聚合结果。
当排序顺序为_doc时,滚动请求会进行优化。如果需要迭代所有 文档,不管顺序如何,这都是最有效的选项,示例如下:
GET /_search?scroll=1m
{
"sort": [
"_doc"
]
}
2.13.1、保持搜索上下文处于活跃状态
滚动搜索请求可返回初始搜索请求匹配的所有文档。它忽略对这 些文档的任何后续更改,搜索上下文跟踪Elasticsearch返回正确文 档所需的所有信息。搜索上下文由初始请求创建,并由后续请求保持 活跃性。
滚动参数scroll(传递给搜索请求和每个滚动请求)告诉 Elasticsearch应该保持搜索上下文活动多长时间。它的值(例如1分 钟)不需要足够长的时间来处理所有数据,只需要足够长的时间来处 理前一批结果,因为每个scroll请求(带有scroll参数)会设置一个新 的到期时间。如果scroll请求没有传递参数scroll,那么搜索上下文将 作为滚动请求的一部分被释放。
通常,后台合并过程通过合并较小的段来优化索引,从而创建新 的较大的段。一旦不再需要较小的段,它们就会被删除。此过程在 scroll查询期间也是正常执行的,但打开的搜索上下文会阻止删除旧 段,因为它们仍在使用中。
此外,如果某个段包含已删除或更新的文档,则搜索上下文必须 跟踪该段中的每个文档在初始搜索请求时是否处于活动状态。如果索 引上有许多打开的滚动查询,并且这些查询会受到正在进行的删除或 更新的影响,请确保节点具有足够的堆空间。
可以使用如下方式检查打开了多少搜索上下文:
GET /_nodes/stats/indices/search
2.13.2、清理搜索上下文
当超过scroll参数设置的超时时间时,搜索上下文将自动删除。 但是,正常情况下保持搜索上下文是有成本的,因此当滚动不再使用 时,应明确清除,示例如下:
DELETE /_search/scroll
{
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
也可以一次清除多个搜索上下文:
DELETE /_search/scroll
{
"scroll_id" : [
"DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==",
"DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAABFmtSWWRRWUJrU2o2ZExpSGJCVmQxYUEAAAAAAAAAAxZrUllkUVlCa1NqNmRMaUhiQlZkMWFBAAAAAAAAAAIWa1JZZFFZQmtTajZkTGlIYkJWZDFhQQAAAAAAAAAFFmtSWWRRWUJrU2o2ZExpSGJCVmQxYUEAAAAAAAAABBZrUllkUVlCa1NqNmRMaUhiQlZkMWFB"
]
}
要清除所有搜索上下文,可以使用_all参数:
DELETE /_search/scroll/_all
scroll_id可以作为查询字符串参数或在请求主体中传递。可以将 用逗号分隔的多个滚动ID传递:
DELETE /_search/scroll/DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==,DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAABFmtSWWRRWUJrU2o2ZExpSGJCVmQxYUEAAAAAAAAAAxZrUllkUVlCa1NqNmRMaUhiQlZkMWFBAAAAAAAAAAIWa1JZZFFZQmtTajZkTGlIYkJWZDFhQQAAAAAAAAAFFmtSWWRRWUJrU2o2ZExpSGJCVmQxYUEAAAAAAAAABBZrUllkUVlCa1NqNmRMaUhiQlZkMWFB
2.13.3、切片
对于返回大量文档的滚动查询,可以将滚动拆分为多个可独立使 用的切片,来并行执行整个查询过程,示例如下:
GET /twitter/_search?scroll=1m
{
"slice": {
"id": 0,
"max": 2
},
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
GET /twitter/_search?scroll=1m
{
"slice": {
"id": 1,
"max": 2
},
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
上述示例中,第一个请求的结果属于第一个切片(ID:0)的文 档,第二个请求的结果属于第二个切片的文档。由于最大切片数设置 为2,因此两个请求的结果的并集相当于不进行切片的滚动查询的结 果。默认情况下,首先在分片上完成分割,然后在每个分片上使用带 有以下公式的_id字段进行切片:
slice(doc) = floorMod(hashCode(doc._id),max)
例如,如果分片数量等于2,并且用户请求4个切片,则切片0和2 被分配给第一个分片,切片1和3被分配到第二个分片。
每个滚动是独立的,可以并行处理。
如果切片数量大于分片数量,则切片过滤器在第一次调用时速度 非常慢,它的复杂性为O(n),并且内存成本等于每个切片的 NBit,其中N是分片中的文档总数。在几次调用之后,应该会缓存过 滤器,随后的调用就会更快,但是应该限制并行执行的切片查询的数 量,以避免内存爆炸。
为了完全避免这种开销,可以使用另一个字段的doc_values进行 切片,但用户必须确保该字段具有以下属性:
- 该字段是数字。
- 在该字段上启用doc_values。
- 每个文档的该字段都应该是单值。如果一个文档的指定字段 有多个值,则使用第一个值。
- 创建文档时,每个文档的值都应设置一次,并且从不更新。 这样可以确保每个切片都得到确定的结果。
- 字段的基数应该很高,这样可以确保每个切片获得大致相同 数量的文档。
默认情况下,每个滚动请求允许的最大切片数限制为1024。可以 更新index.max_slices_per_scroll设置以绕过此限制。
2.14、search_after参数
结果的分页可以通过使用from和size来完成,但当达到深度分页 时,开销会变得难以控制。index.max_result_window默认值为10 000,是一种保护措施,搜索请求占用堆内存和时间,与from+size 大小成比例。建议使用scroll API进行深度分页,但滚动上下文成本 高昂,不建议将其用于实时用户请求。search_after参数通过提供活 动光标来绕过这个问题。其思想是使用上一页的结果来帮助检索下一 页。
假设检索第一页的查询如下所示:
GET twitter/_search
{
"size": 10,
"query": {
"match" : {
"title" : "elasticsearch"
}
},
"sort": [
{"date": "asc"},
{"tie_breaker_id": "asc"}
]
}
上述示例代码中,tie_breaker_id是_id字段的副本,已启用 doc_values。
每个文档应使用具有唯一值的字段来排序。否则,具有相同排序 值的文档的排序顺序将未定义,并可能导致结果丢失或重复。_id字段 对于每个文档都有唯一的值,但不建议将其直接用作排序的决定因 子。注意,tiebreaker要查找完全或部分匹配tiebreaker(排序的决 定值)提供的值的第一个文档。因此,如果一个文档的tiebreaker值 为654 323,并且在其后面搜索654,它仍然会匹配该文档并返回在 其之后找到的结果。doc_values在这个字段上被禁用,因此对它进行 排序需要在内存中加载大量数据。相反,建议在启用了doc_values的 另一个字段中复制id字段的内容,并使用此新字段作为排序字段。
上述请求的结果包括每个文档的sort values。这些sort values 可以与search_after参数一起使用,以在结果列表中的任何文档“之 后”开始返回结果。例如,可以使用最后一个文档的排序值sort values,然后将其传递给搜索者,以便检索下一页的结果,示例如 下:
GET twitter/_search
{
"size": 10,
"query": {
"match" : {
"title" : "elasticsearch"
}
},
"search_after": [1463538857, "654323"],
"sort": [
{"date": "asc"},
{"tie_breaker_id": "asc"}
]
}
参数from必须设置为0(或-1)。
search_after不是自由跳转到随机页面的解决方案,而是并行滚 动许多查询。它与scroll API非常相似,但与之不同的是, search_after参数是无状态的,它总是根据搜索者的最新版本进行解析。因此,在执行过程中,排序顺序可能会根据索引的更新或删除而 改变。
2.15、搜索类型
在进行分布式搜索时,会执行不同的路径。分布式搜索操作需要 把请求分发到所有相关的分片上,然后将所有结果收集回到协调节 点。当执行分发和收集时,有几种方法可以做到这一点,特别是使用 搜索引擎时。
执行分布式搜索时的一个问题是从每个分片中检索多少结果。例 如,如果有10个分片,第一个分片可能包含从0到10的最相关结果, 其他分片的结果排名低于它。因此,在执行请求时,需要从所有分片 中都获取从0到10的结果,对它们进行排序,然后返回结果,这样才 可以确保结果的正确性。
另一个与搜索引擎相关的问题是,每个分片都是独立存在的。当 对特定分片执行查询时,它不考虑来自其他分片的Term频率和向量信 息。如果我们想要支持精确的排名,需要首先从所有分片收集Term频 率来计算全局Term频率,然后使用这些全局频率对每个分片执行查 询。
此外,由于需要对结果进行排序、返回大型文档集,甚至滚动 它,同时保持正确的排序行为可能是一个非常昂贵的操作。对于大型 结果集的scroll操作,如果返回文档的顺序不重要,最好按_doc排 序。
Elasticsearch是非常灵活的,它允许根据每个搜索请求控制要 执行的搜索类型(search_type)。可以通过在查询字符串中设置 search_type参数来配置搜索类型,其中类型有如下两种:
- query_then_fetch(默认值):请求分两个阶段处理。在第 一阶段,查询被转发到所有相关的分片,每个分片执行搜索 并生成一个结果的排序列表。每个分片只返回足够的信息给 协调节点(排序过的文档ID和排序需要的相关字段),以允 许它合并并将分片级别的结果重新排序。
在第二阶段中,协调节点只从相关的分片请求文档内容(以及高 亮显示的片段,如果有)。
- dfs_query_then_fetch : 第 二 阶 段 与 query_then_fetch 相 同,但在初始请求分发执行阶段是不同的,该阶段进行并计 算分布式Term频率,以便更准确地评分。
2.16、排序
可以按特定一个或多个字段对结果排序。排序是在每个字段级别 上定义的,_score用于按得分排序,以及按索引顺序排序的_doc。
假设以下索引映射:
PUT /my_index
{
"mappings": {
"properties": {
"post_date": { "type": "date" },
"user": {
"type": "keyword"
},
"name": {
"type": "keyword"
},
"age": { "type": "integer" }
}
}
}
如下示例,返回结果按多个字段进行排序,与SQL语言中的 order by功能类似:
GET /my_index/_search
{
"sort" : [
{ "post_date" : {"order" : "asc"}},
"user",
{ "name" : "desc" },
{ "age" : "desc" },
"_score"
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
除了最准确的排序(因为_doc是唯一值,排序准确)顺序之外, _doc很少被实际应用。因此,如果不关心返回文档的顺序,那么应该 按_doc排序,这在滚动查询时尤其有用。
2.16.1、排序方式
排序方式有两种:asc,升序;desc,降序。与SQL语言是相同 的。
2.16.2、多值字段排序模式
Elasticsearch支持按数组或多值字段排序。模式选项mode控制 对文档进行排序的值,它有以下几种值:
- min :数组或多值字段的最小值作为排序值。
- max :数组或多值字段的最大值作为排序值。
- sum :数组或多值字段的和作为排序值。
- avg :数组或多值字段的平均值作为排序值。
- median :数组或多值字段的中位数作为排序值。
以升序排序的默认排序模式是min,选择最小值作为排序值。按 降序排列的默认排序模式是max,取最大值作为排序值。
在下面的示例中,字段price每个文档有多个价格。在这种情况 下,结果将按每个文档的平均价格升序排序。
PUT /my_index/_doc/1?refresh
{
"product": "chocolate",
"price": [20, 4]
}
POST /_search
{
"query" : {
"term" : { "product" : "chocolate" }
},
"sort" : [
{"price" : {"order" : "asc", "mode" : "avg"}}
]
}
2.16.3、嵌套对象的排序
Elasticsearch还支持按一个或多个嵌套对象中的字段排序。按 嵌套字段的排序支持一个nested属性,该属性具有以下选项:
- path :定义要用来排序的嵌套对象字段。实际排序字段必须 是此嵌套对象内的直接字段(内部不能再嵌套)。按嵌套字 段排序时,此字段是必需的。
- filter :常见的情况是在嵌套的过滤器或查询中重复查询/过 滤。
- max_children :选择排序值时每个根文档要考虑的最大子 级数,默认为无限制。
- nested :与顶层嵌套相同,但适用于当前嵌套对象中的另一 个嵌套路径。
在下面的示例中,offer是一个嵌套类型的字段。需要指定嵌套路 径path,否则Elasticsearch不知道需要获取什么嵌套级别的排序 值。
POST /_search
{
"query" : {
"term" : { "product" : "chocolate" }
},
"sort" : [
{
"offer.price" : {
"mode" : "avg",
"order" : "asc",
"nested": {
"path": "offer",
"filter": {
"term" : { "offer.color" : "blue" }
}
}
}
}
]
}
在下面的示例中,父字段和子字段的类型为嵌套。嵌套的路径需 要在每个级别上指定,否则,Elasticsearch不知道需要捕获哪个嵌 套级别的排序值。
POST /_search
{
"query": {
"nested": {
"path": "parent",
"query": {
"bool": {
"must": {"range": {"parent.age": {"gte": 21}}},
"filter": {
"nested": {
"path": "parent.child",
"query": {"match": {"parent.child.name": "matt"}}
}
}
}
}
}
},
"sort" : [
{
"parent.child.age" : {
"mode" : "min",
"order" : "asc",
"nested": {
"path": "parent",
"filter": {
"range": {"parent.age": {"gte": 21}}
},
"nested": {
"path": "parent.child",
"filter": {
"match": {"parent.child.name": "matt"}
}
}
}
}
}
]
}
2.16.4、缺失值的处理
missing参数指定如何处理缺少排序字段的文档。可以将 missing的值设置为_last、_first或自定义值(将用作缺失排序字段的文档的排序值),默认值为_last。示例如下:
GET /_search
{
"sort" : [
{ "price" : {"missing" : "_last"} }
],
"query" : {
"term" : { "product" : "chocolate" }
}
}
默认情况下,排序字段如果没有与字段关联的映射,则搜索请求 将失败。unmapped_type选项允许忽略没有映射的字段,不按它们 排序。此参数的值用于确定要排序字段的映射类型,即自定义排序字 段的数据类型。下面是一个如何使用它的示例:
GET /_search
{
"sort" : [
{ "price" : {"unmapped_type" : "long"} }
],
"query" : {
"term" : { "product" : "chocolate" }
}
}
如果查询的任何索引没有价格(price)映射类型,那么 Elasticsearch将当作long类型的映射来处理long,该索引中的所有 文档都没有该字段的值。
2.16.5、地理距离排序
可以按地理距离(geo)_geo_distance排序。下面是一个例子, 假设pin.location是geo_point类型的字段:
GET /_search
{
"sort" : [
{
"_geo_distance" : {
"pin.location" : [-70, 40],
"order" : "asc",
"unit" : "km",
"mode" : "min",
"distance_type" : "arc",
"ignore_unmapped": true
}
}
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
各参数的含义如下:
- distance_type :如何计算距离。可以是arc(默认),也可 以是plane(更快,但在长距离和接近极点时不准确)。
- mode :如果一个场景有几个地理点(也就是多值),该怎 么办?默认情况下,升序排序时考虑最短距离,降序排序时 考虑最长距离。支持的值包括min、max、median和avg。
- unit :排序字段值的单位,默认是m(米)。
- ignore_unmapped :上面已经讲过了,排序字段没有类型 该怎么处理。
地理距离排序不支持可配置的默认值:当文档没有用于距离计算 的字段值时,该距离将始终被视为无穷大(Infinity)。
地理距离排序支持多种坐标格式,如下是应用示例。
2.16.5.1、JSON经纬度格式
GET /_search
{
"sort" : [
{
"_geo_distance" : {
"pin.location" : {
"lat" : 40,
"lon" : -70
},
"order" : "asc",
"unit" : "km"
}
}
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
2.16.5.2、逗号分隔格式
GET /_search
{
"sort" : [
{
"_geo_distance" : {
"pin.location" : "40,-70",
"order" : "asc",
"unit" : "km"
}
}
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
2.16.5.3、pin码格式
GET /_search
{
"sort" : [
{
"_geo_distance" : {
"pin.location" : "drm3btev3e86",
"order" : "asc",
"unit" : "km"
}
}
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
2.16.5.4、数组格式
GET /_search
{
"sort" : [
{
"_geo_distance" : {
"pin.location" : [-70, 40],
"order" : "asc",
"unit" : "km"
}
}
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
2.16.5.5、两点距离格式
GET /_search
{
"sort" : [
{
"_geo_distance" : {
"pin.location" : [[-70, 40], [-71, 42]],
"order" : "asc",
"unit" : "km"
}
}
],
"query" : {
"term" : { "user" : "kimchy" }
}
}
2.16.6、自定义脚本排序
可以通过自定义的脚本的计算结果进行排序,示例如下:
GET /_search
{
"query" : {
"term" : { "user" : "kimchy" }
},
"sort" : {
"_script" : {
"type" : "number",
"script" : {
"lang": "painless",
"source": "doc['field_name'].value * params.factor",
"params" : {
"factor" : 1.1
}
},
"order" : "asc"
}
}
}
2.17、_source字段过滤
可以控制每个命中文档的_source字段的返回方式。默认情况 下,操作将返回_source字段的内容,除非使用了stored_fields参数 或禁用了_source字段。
可以使用_source参数关闭_source字段检索,要禁用_source字 段返回,设置为false,示例如下:
GET /_search
{
"_source": false,
"query": {
"term":{"user":"kimchy"}
}
}
_source还接受一个或多个通配符模式来控制应返回_source的哪 些部分,当然也可以不包括通配符即准确指定返回的字段,下面是两 个示例:
GET /_search
{
"_source": "obj.*",
"query": {
"term":{"user":"kimchy"}
}
}
GET /_search
{
"_source": ["obj1.*","obj2.*"]
"query": {
"term":{"user":"kimchy"}
}
}
如果需要更完全的控制,可以指定includes和excludes模式:
GET /_search
{
"_source": {
"includes":["obj1.*","obj2.*"],
"excludes":["*.description"]
}
"query": {
"term":{"user":"kimchy"}
}
}
2.18、存储字段
存储字段指的是建立索引映射,store设置为true的字段(默认是 false),通常不建议使用(增加内存开销)。
stored_fields参数控制存储字段的返回,建议使用source来选择 要返回的原始文档的哪些字段。
允许有选择地为搜索命中的文档加载特定的存储字段,示例如 下:
GET /_search
{
"stored_fields" : ["user", "postDate"],
"query" : {
"term" : { "user" : "kimchy" }
}
}
*可用于加载文档中的所有存储字段。
stored_fields为空数组将只返回每次命中的_id和_type字段,例 如:
GET /_search
{
"stored_fields" : [],
"query" : {
"term" : { "user" : "kimchy" }
}
}
如果请求的字段存储映射设置为false,则将忽略这些字段。
从文档本身获取的存储字段值始终作为数组返回。相反,像路由 _routing这样的元数据字段永远不会作为数组返回。此外,只能通过 字段选项返回叶字段,不能返回对象字段,这样的请求将失败。
脚本字段也可以自动检测并用作字段,因此可以使用 _source.obj1.field1之类的内容,但不推荐,因为obj1.field1是更好 的选择。
下面的示例禁用stored_fields:
GET /_search
{
"stored_fields": "_none_",
"query" : {
"term" : { "user" : "kimchy" }
}
}
2.19、total返回值详解(track_total_hits)
通常,要准确计算总命中数,必须访问所有匹配项,这对于匹配 大量文档的查询来说代价高昂。track_total_hits参数允许控制应如 何跟踪命中总数(控制total的准确度)。track_total_hits默认设置 为10 000,这意味着请求命中数在10 000以内,total计数是准确 的,total.relation值是eq。如果请求命中数大于10 000时,计数是不准确的,此时total的值是10 000,total.relation值是gte。如果不 需要准确的命中总数,这种设计可以加速查询。
当track_total_hits设置为true时,搜索响应返回的命中总数始 终是准确的(total.relation始终等于eq)。搜索响应中total对象中 返回的total.relation将决定total.value是否准确。gte的值表示 total.value匹配查询的总命中数的下限,eq的值表示total.value是准 确的计数。
通过如下示例,再来分析:
GET twitter/_search
{
"track_total_hits": true,
"query": {
"match" : {
"message" : "Elasticsearch"
}
}
}
返回:
{
"_shards": ...
"timed_out": false,
"took": 100,
"hits": {
"max_score": 1.0,
"total" : {
"value": 2048,
"relation": "eq"
},
"hits": ...
}
}
也可以将track_total_hits设置为整数。例如,以下查询将准确 跟踪与查询匹配的命中总数,最多100个文档,也就是命中文档数低 于100时,是准确的,高于100时是不准确的(total.relation值是 gte):
GET twitter/_search
{
"track_total_hits": 100,
"query": {
"match" : {
"message" : "Elasticsearch"
}
}
}
如果不需要跟踪命中总数,可以通过将此选项设置为false来改进 查询时间:
GET twitter/_search
{
"track_total_hits": false,
"query": {
"match" : {
"message" : "Elasticsearch"
}
}
}
2.20、版本控制(_version)
Elasticsearch中的版本功能在并发更新文档时,用来处理冲突 的机制。Elasticsearch采用的是乐观并发控制机制。这种方法假定 冲突是不可能发生的,所以不会阻塞正在尝试的操作。然而,如果源 数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如 何解决冲突。例如,可以获取新的数据,重试更新或者将相关情况报 告给用户。
Elasticsearch是分布式的,当文档创建、更新、删除时,新版 本的文档必须复制到集群中其他节点,同时,Elasticsearch也是异 步和并发的。这就意味着这些复制请求被并行发送,并且到达目的地 时也许顺序是乱的(老版本可能在新版本之后到达)。 Elasticsearch需要一种方法确保文档的旧版本不会覆盖新的版本。 Elasticsearch利用_version(版本号)的方式来确保应用中相互冲 突的变更不会导致数据丢失。需要修改数据时,需要指定想要修改文 档的version号,如果该版本不是当前版本号,请求将会失败。
可以通过如下方式返回文档的版本信息:
GET /bank/_search
{
"version": true,
"query": {
"term": {
"city.keyword": {
"value": "Orick"
}
}
}
}
3、返回索引分片信息(_search_shards)
_search_shards API返回将针对其执行搜索请求的索引和分片 信息。这可以为解决问题或使用路由和分片首选项计划优化提供有用 的反馈。
//语法
GET /<index>/_search_shards
示例:
GET /twitter/_search_shards
返回:
{
"nodes" : {
"Cc6ARDA6TY-poOdtxvsA6g" : {
"name" : "zhangchenglongdeMacBook-Pro.local",
"ephemeral_id" : "YekwqhksTmazQePnvw1-YQ",
"transport_address" : "127.0.0.1:9300",
"attributes" : {
"ml.machine_memory" : "17179869184",
"xpack.installed" : "true",
"transform.node" : "true",
"ml.max_open_jobs" : "512",
"ml.max_jvm_size" : "1037959168"
},
"roles" : [
"data",
"data_cold",
"data_content",
"data_frozen",
"data_hot",
"data_warm",
"ingest",
"master",
"ml",
"remote_cluster_client",
"transform"
]
}
},
"indices" : {
"twitter" : { }
},
"shards" : [
[
{
"state" : "STARTED",
"primary" : true,
"node" : "Cc6ARDA6TY-poOdtxvsA6g",
"relocating_node" : null,
"shard" : 0,
"index" : "twitter",
"allocation_id" : {
"id" : "3OsEagVpRFifBrs-baJTzA"
}
}
]
]
}
也可以在请求中带有路由值:
GET /twitter/_search_shards?routing=foo,bar
支持的参数如下:
- routing :一个逗号分隔的路由值列表,在确定请求将分发哪个分片执行时 用到这些值。
- preference :这个是控制优先在哪些分片上执行请求,在上面的章节已经进行 过讲解。
- local :一个布尔值,控制是否在本地读取集群状态,以确定在何处分配 分片,而不是使用主节点的集群状态。
4、Count API
Count API可以轻量级执行查询并获取该查询的匹配文档数。它 可以跨一个或多个索引执行。可以使用简单查询字符串作为参数提供 查询,也可以使用请求正文中定义的查询DSL。
//语法
GET /<index>/_count
示例:
PUT /twitter/_doc/1?refresh
{
"user": "kimchy"
}
GET /twitter/_count?q=user:kimchy
GET /twitter/_count
{
"query" : {
"term" : { "user" : "kimchy" }
}
}
5、Validate API
Validate API允许用户在不执行查询的情况下验证查询的合法 性。
//语法
GET /<index>/_validate/<query>
示例:
PUT twitter/_bulk?refresh
{"index":{"_id":1}}
{"user" : "kimchy", "post_date" : "2009-11-15T14:12:12", "message" : "trying out Elasticsearch"}
{"index":{"_id":2}}
{"user" : "kimchi", "post_date" : "2009-11-15T14:12:13", "message" : "My username is similar to @kimchy!"}
发送一个验证查询:
GET twitter/_validate/query?q=user:foo
也可以使用body形式:
GET twitter/_validate/query
{
"query" : {
"bool" : {
"must" : {
"query_string" : {
"query" : "*:*"
}
},
"filter" : {
"term" : { "user" : "kimchy" }
}
}
}
}
6、调试(_explain)
调试API(_explain)可以查看查询和特定文档计算分数的细 节。无论文档是否匹配特定查询,这都可以提供有用的反馈。必须为 index参数提供单个索引。
//语法
GET /<index>/_explain/<id>
POST /<index>/_explain/<id>
示例:
GET /twitter/_explain/0
{
"query" : {
"match" : { "message" : "elasticsearch" }
}
}
返回:
{
"_index":"twitter",
"_type":"_doc",
"_id":"0",
"matched":true,
"explanation":{
"value":1.6943598,
"description":"weight(message:elasticsearch in 0) [PerFieldSimilarity], result of:",
"details":[
{
"value":1.6943598,
"description":"score(freq=1.0), computed as boost * idf * tf from:",
"details":[
{
"value":2.2,
"description":"boost",
"details":[]
},
{
"value":1.3862944,
"description":"idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details":[
{
"value":1,
"description":"n, number of documents containing term",
"details":[]
},
{
"value":5,
"description":"N, total number of documents with field",
"details":[]
}
]
},
{
"value":0.5555556,
"description":"tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details":[
{
"value":1.0,
"description":"freq, occurrences of term within document",
"details":[]
},
{
"value":1.2,
"description":"k1, term saturation parameter",
"details":[]
},
{
"value":0.75,
"description":"b, length normalization parameter",
"details":[]
},
{
"value":3.0,
"description":"dl, length of field",
"details":[]
},
{
"value":5.4,
"description":"avgdl, average length of field",
"details":[]
}
]
}
]
}
]
}
}
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
