Term向量
词项向量(term vector)是有elasticsearch在index document的时候产生,其包含对document解析过程中产生的分词的一些信息,例如分词在字段值中的位置、开始和结束的字符位置、分词的元数据payloads等;
term vector是单独进行存储的,会额外多占用一杯的空间,所以elasticsearch默认情况下禁用词项向量,如果要启用,我们需要在字段的mapping中使用term_vector进行设置;
1、term_vector的配置选项
| 配置选项 | 描述 |
|---|---|
| no | 不启用termvector,默认值 |
| yes | 启用termvector,但是仅记录分词 |
| with_positions | 启用termvector,记录分词及分词在字符串中的位置 |
| with_offsets | 启用termvector,记录分词在字符串中的起始字符位置 |
| with_positions_offsets | 启用termvector,记录分词在字符串中的位置及起始的字符位置 |
| with_positions_payloads | 启用termvector,记录分词在字符串中的位置及payloads |
| with_positions_offsets_payloads | 启用termvector,记录分词在字符串中的位置、起始字符位置及payloads |
PUT /twitter
{ "mappings": {
"properties": {
"text": {
"type": "text",
"term_vector": "with_positions_offsets_payloads",
"store" : true,
"analyzer" : "fulltext_analyzer"
},
"fullname": {
"type": "text",
"term_vector": "with_positions_offsets_payloads",
"analyzer" : "fulltext_analyzer"
}
}
},
"settings" : {
"index" : {
"number_of_shards" : 1,
"number_of_replicas" : 0
},
"analysis": {
"analyzer": {
"fulltext_analyzer": {
"type": "custom",
"tokenizer": "whitespace",
"filter": [
"lowercase",
"type_as_payload"
]
}
}
}
}
}
将以下两个document发送到elasticsearch进行index:
PUT /twitter/_doc/1
{
"fullname" : "John Doe",
"text" : "twitter test test test "
}
PUT /twitter/_doc/2?refresh=wait_for
{
"fullname" : "Jane Doe",
"text" : "Another twitter test ..."
}
2、查看term vector的数据结构
term vector主要由term information、term statistics、field statistics构成,其中term information又分成了positions、offsets、payloads三个选项,我们可以通过请求的body的参数分别控制返回的信息;
//语法:
GET /<index>/_termvectors/<_id>
示例:
GET /twitter/_termvectors/1
{
"fields" : ["text"],
"offsets" : true,
"payloads" : true,
"positions" : true,
"term_statistics" : true,
"field_statistics" : true
}
//返回
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"took" : 0,
"term_vectors" : {
"text" : {
"field_statistics" : {
"sum_doc_freq" : 6,
"doc_count" : 2,
"sum_ttf" : 8
},
"terms" : {
"test" : {
"doc_freq" : 2,
"ttf" : 4,
"term_freq" : 3,
"tokens" : [
{
"position" : 1,
"start_offset" : 8,
"end_offset" : 12,
"payload" : "d29yZA=="
},
{
"position" : 2,
"start_offset" : 13,
"end_offset" : 17,
"payload" : "d29yZA=="
},
{
"position" : 3,
"start_offset" : 18,
"end_offset" : 22,
"payload" : "d29yZA=="
}
]
},
"twitter" : {
"doc_freq" : 2,
"ttf" : 2,
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 7,
"payload" : "d29yZA=="
}
]
}
}
}
}
}
3、返回值信息
可以请求三种类型的值:Term信息、Term统计信息和字段统计 信息。默认情况下,返回所有字段的所有Term信息和字段统计信息, 但不返回Term统计信息。
基于以下两点term statistics和field statistics并不是准确的;
- 删除的文档不会计算在内;
- 只计算请求文档所在的分片的数据;
3.1、Term信息
- term_freq :Term的频率(在对应字段中),这部分信息是始终返回的。
- position :Term的位置,需要设置positions:true。
- start_offset、end_offset :Term开始和结束的偏移量,需要设置offsets:true。
- payload :分词的元数据,可以看到每个分词的payload都是d29yZA==,从这里可以到elasticsearch默认值为 word;
Term信息在Elasticsearch中的具体存储格式如图所示:
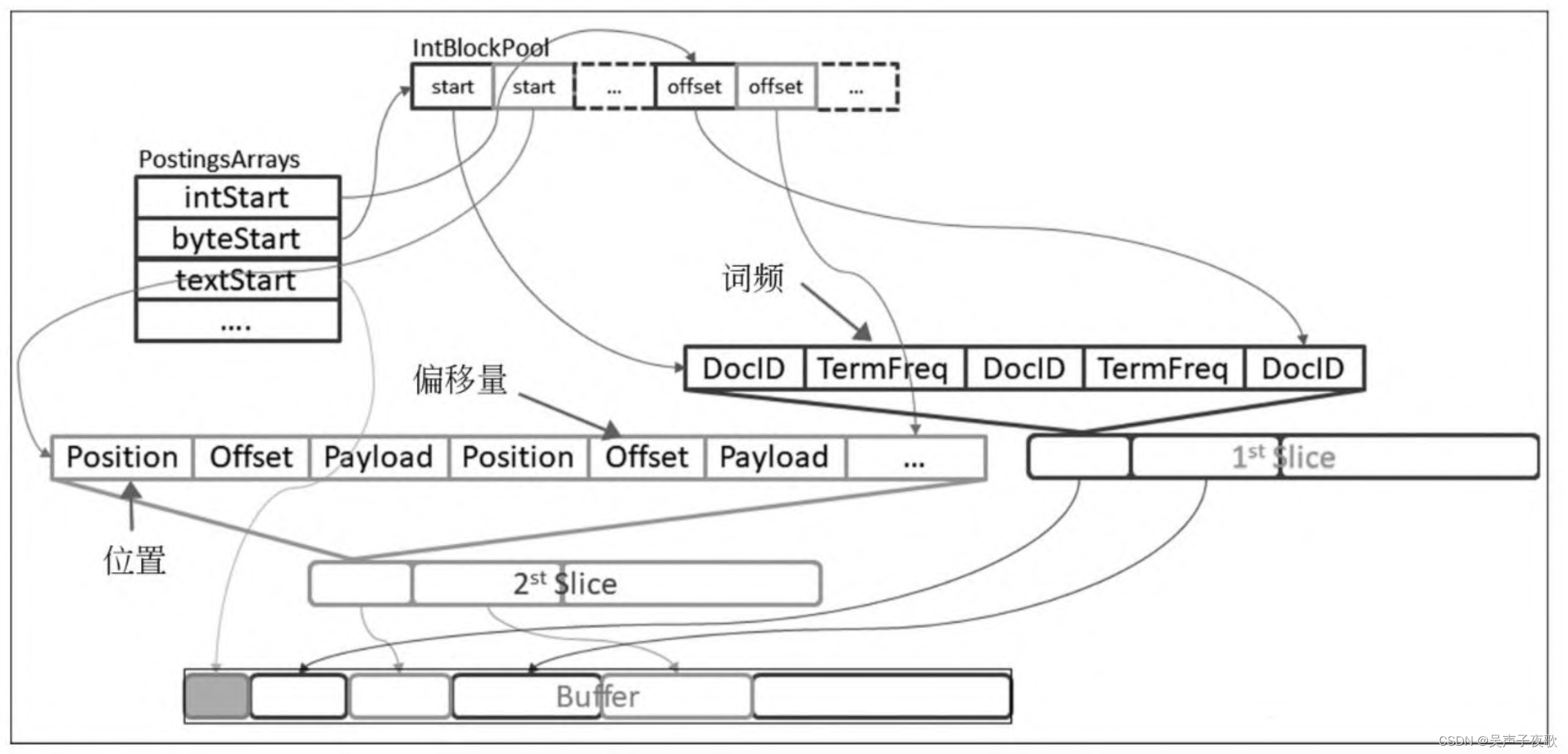
如果请求的信息没有存储在索引中,可能的话,它将被动态计算。此外,还可以为索引中不存在但由用户提供的文档计算Term向量。
开始和结束偏移量假定使用了UTF-16编码。如果要使用这些偏 移量来获取原始文本,应确保子字符串也使用UTF-16编码。
3.2、Term统计信息
需要将term_statistics设置为true,其默认值为false。Term统 计信息包括如下两方面的信息:
- ttf(total term frequency) :Term的总词频,即在所有文档中Term出现的总次数。可以看到twitter的ttf是2,test的ttf是4;
- doc_freq(document frequency) :当前字段包含当前分词的文档的数量,可以看到两个document的text字段都包含test及twitter,所以两者的doc_freq为2;
默认情况下,不会返回这些信息,因为Term统计信息可能会对性 能产生严重影响。
3.3、字段统计信息
字段统计信息默认是返回的,可以将field_statistics设为false来 禁止返回。字段统计信息包括如下三方面的内容:
-
doc_count :文档计数,即多少个文档存在这个字段值。这里两个文档都包含text字段,所以doc_count为2;
-
sum_doc_freq :文档频率总和,当前字段中所有分词对应的document frequency的加和。 这里以下计算可以得到sum_doc_freq为6;
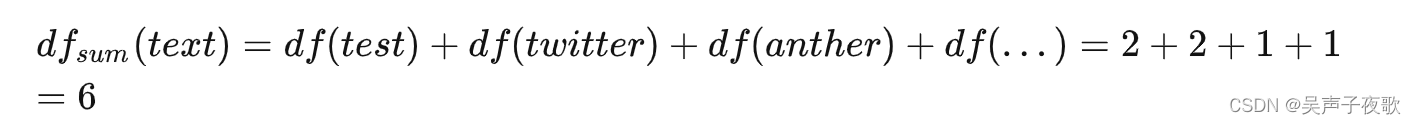
-
sum_ttf :Term频率总和,当前字段中所有分词对应的total term frequency的加和,这里以下计算可以得到sum_ttf为8;
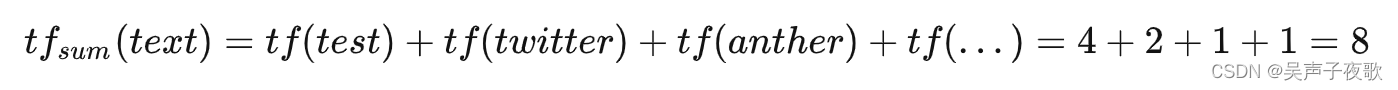
4、Term过滤
使用参数filter,还可以根据tf-idf分数过滤返回的Term。这有助 于找出文档的特征向量。此功能的工作方式更类似于此查询的第二阶 段。
在下面的示例中,从具有给定plot字段值的文档中获得三个用户 “最感兴趣”的关键字。请注意,关键字Tony或任何停止词都不是响 应的一部分,因为它们的tf-idf太低。
GET /imdb/_termvectors
{
"doc": {
"plot": "When wealthy industrialist Tony Stark is forced to build an armored suit after a life-threatening incident, he ultimately decides to use its technology to fight against evil."
},
"term_statistics" : true,
"field_statistics" : true,
"positions": false,
"offsets": false,
"filter" : {
"max_num_terms" : 3,
"min_term_freq" : 1,
"min_doc_freq" : 1
}
}
返回:
{
"_index": "imdb",
"_type": "_doc",
"_version": 0,
"found": true,
"term_vectors": {
"plot": {
"field_statistics": {
"sum_doc_freq": 3384269,
"doc_count": 176214,
"sum_ttf": 3753460
},
"terms": {
"armored": {
"doc_freq": 27,
"ttf": 27,
"term_freq": 1,
"score": 9.74725
},
"industrialist": {
"doc_freq": 88,
"ttf": 88,
"term_freq": 1,
"score": 8.590818
},
"stark": {
"doc_freq": 44,
"ttf": 47,
"term_freq": 1,
"score": 9.272792
}
}
}
}
}
可以在请求中传递以下子参数:
- max_num_terms:每个字段返回的最大Term数。默认值 为25。也就是只有一个字段最多25个Term。
- min_term_freq:忽略源文档中低于此频率的单词。默认值 为1。
- max_term_freq:忽略源文档中超过此频率的单词。默认为 无限大。
- min_doc_freq:忽略文档频率低于这个值的Term。默认值 为1。
- max_doc_freq:忽略文档频率高于这个值的Term。默认值 为1。
- min_word_length:忽略低于此值的Term。默认值为0。
- max_word_length:忽略高于此值的Term。默认值为无穷 大。
5、行为分析
Term和Field统计信息是不准确的,仅检索请求文档所在的分片 的信息,而删除的文档不考虑在内。因此,Term和Field统计信息仅 用作相对测量,而绝对数值在此上下文中没有意义。默认情况下,当 请求人工文档的Term向量时,将随机选择一个分片来获取统计信息。 使用routing只命中特定的分片。
5.1、返回存储Term向量
以下请求返回ID为1的文档(john doe)中字段text的所有信息 和统计信息:
GET /twitter/_termvectors/1
{
"fields" : ["text"],
"offsets" : true,
"payloads" : true,
"positions" : true,
"term_statistics" : true,
"field_statistics" : true
}
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"took" : 0,
"term_vectors" : {
"text" : {
"field_statistics" : {
"sum_doc_freq" : 6,
"doc_count" : 2,
"sum_ttf" : 8
},
"terms" : {
"test" : {
"doc_freq" : 2,
"ttf" : 4,
"term_freq" : 3,
"tokens" : [
{
"position" : 1,
"start_offset" : 8,
"end_offset" : 12,
"payload" : "d29yZA=="
},
{
"position" : 2,
"start_offset" : 13,
"end_offset" : 17,
"payload" : "d29yZA=="
},
{
"position" : 3,
"start_offset" : 18,
"end_offset" : 22,
"payload" : "d29yZA=="
}
]
},
"twitter" : {
"doc_freq" : 2,
"ttf" : 2,
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 7,
"payload" : "d29yZA=="
}
]
}
}
}
}
}
5.2、动态生成Term向量
未存储在索引中的字段的Term向量将自动动态计算。以下请求返 回ID为1的文档中字段的所有信息和统计信息,即使这些Term尚未显式存储在索引中。请注意,对于字段text,不会重新生成Term向量。
PUT /twitter/_doc/3
{
"fullname" : "Jane Doe",
"text" : "Another twitter test ...",
"filed_without_term_vector": "hello world"
}
GET /twitter/_termvectors/3
{
"fields" : ["text", "filed_without_term_vector"],
"offsets" : true,
"positions" : true,
"term_statistics" : true,
"field_statistics" : true
}
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "3",
"_version" : 1,
"found" : true,
"took" : 0,
"term_vectors" : {
"text" : {
"field_statistics" : {
"sum_doc_freq" : 10,
"doc_count" : 3,
"sum_ttf" : 12
},
"terms" : {
"..." : {
"doc_freq" : 2,
"ttf" : 2,
"term_freq" : 1,
"tokens" : [
{
"position" : 3,
"start_offset" : 21,
"end_offset" : 24,
"payload" : "d29yZA=="
}
]
},
"another" : {
"doc_freq" : 2,
"ttf" : 2,
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 7,
"payload" : "d29yZA=="
}
]
},
"test" : {
"doc_freq" : 3,
"ttf" : 5,
"term_freq" : 1,
"tokens" : [
{
"position" : 2,
"start_offset" : 16,
"end_offset" : 20,
"payload" : "d29yZA=="
}
]
},
"twitter" : {
"doc_freq" : 3,
"ttf" : 3,
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 8,
"end_offset" : 15,
"payload" : "d29yZA=="
}
]
}
}
},
"filed_without_term_vector" : {
"field_statistics" : {
"sum_doc_freq" : 2,
"doc_count" : 1,
"sum_ttf" : 2
},
"terms" : {
"hello" : {
"doc_freq" : 1,
"ttf" : 1,
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 5
}
]
},
"world" : {
"doc_freq" : 1,
"ttf" : 1,
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 6,
"end_offset" : 11
}
]
}
}
}
}
}
5.3、人工文档
可以为人工文档生成Term向量,即索引中不存在的文档。示例如 下:
GET /twitter/_termvectors
{
"doc" : {
"fullname" : "John Doe",
"text" : "twitter test test test"
}
}
{
"_index" : "twitter",
"_type" : "_doc",
"_version" : 0,
"found" : true,
"took" : 0,
"term_vectors" : {
"text" : {
"field_statistics" : {
"sum_doc_freq" : 10,
"doc_count" : 3,
"sum_ttf" : 12
},
"terms" : {
"test" : {
"term_freq" : 3,
"tokens" : [
{
"position" : 1,
"start_offset" : 8,
"end_offset" : 12
},
{
"position" : 2,
"start_offset" : 13,
"end_offset" : 17
},
{
"position" : 3,
"start_offset" : 18,
"end_offset" : 22
}
]
},
"twitter" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 7
}
]
}
}
},
"fullname" : {
"field_statistics" : {
"sum_doc_freq" : 6,
"doc_count" : 3,
"sum_ttf" : 6
},
"terms" : {
"doe" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 5,
"end_offset" : 8
}
]
},
"john" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 4
}
]
}
}
}
}
}
5.4、字段分析器
此外,可以使用per_field_analyzer参数为不同的字段提供不同 的分析器,这对于以任何方式生成Term向量都很有用,特别是在使用 人工文档时。当为已经存储Term向量的字段提供分析器时,将重新生 成Term向量。
GET /twitter/_termvectors
{
"doc" : {
"fullname" : "John Doe",
"text" : "twitter test test test"
},
"fields": ["fullname"],
"per_field_analyzer" : {
"fullname": "keyword"
}
}
{
"_index" : "twitter",
"_type" : "_doc",
"_version" : 0,
"found" : true,
"took" : 0,
"term_vectors" : {
"fullname" : {
"field_statistics" : {
"sum_doc_freq" : 6,
"doc_count" : 3,
"sum_ttf" : 6
},
"terms" : {
"John Doe" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 8
}
]
}
}
}
}
}
6、获取多个文档的Term向量
_mtermvectors API允许一次获取多个文档的Term向量。由索 引_index和_id参数指定多个文档,从指定的文档中检索出Term向 量。但是文档也可以在请求本身中人工提供。
//语法
POST /_mtermvectors
POST /<index>/_mtermvectors
POST /_mtermvectors
{
"docs": [
{
"_index":"twitter",
"_id": "2",
"fields": [
"message"
],
"term_statistics": true
},
{
"_index":"twitter",
"_id": "1"
}
]
}
响应包括一个docs数组,此数组包含所有获取的Term向量。
{
"docs" : [
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"found" : true,
"took" : 0,
"term_vectors" : { }
},
{
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"took" : 0,
"term_vectors" : {
"fullname" : {
"field_statistics" : {
"sum_doc_freq" : 6,
"doc_count" : 3,
"sum_ttf" : 6
},
"terms" : {
"doe" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 5,
"end_offset" : 8,
"payload" : "d29yZA=="
}
]
},
"john" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 4,
"payload" : "d29yZA=="
}
]
}
}
},
"text" : {
"field_statistics" : {
"sum_doc_freq" : 10,
"doc_count" : 3,
"sum_ttf" : 12
},
"terms" : {
"test" : {
"term_freq" : 3,
"tokens" : [
{
"position" : 1,
"start_offset" : 8,
"end_offset" : 12,
"payload" : "d29yZA=="
},
{
"position" : 2,
"start_offset" : 13,
"end_offset" : 17,
"payload" : "d29yZA=="
},
{
"position" : 3,
"start_offset" : 18,
"end_offset" : 22,
"payload" : "d29yZA=="
}
]
},
"twitter" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 7,
"payload" : "d29yZA=="
}
]
}
}
}
}
}
]
}
可以指定索引:
POST /twitter/_mtermvectors
{
"docs": [
{
"_id": "2",
"fields": [
"message"
],
"term_statistics": true
},
{
"_id": "1"
}
]
}
如果所有请求的文档都在同一索引上,并且参数相同,则可以简 化请求:
POST /twitter/_mtermvectors
{
"ids" : ["1", "2"],
"parameters": {
"fields": [
"message"
],
"term_statistics": true
}
}
此外,可以为用户提供的文档生成Term向量。使用的映射由索引 _index确定。下面是具体的实例:
POST /_mtermvectors
{
"docs": [
{
"_index": "twitter",
"doc" : {
"user" : "John Doe",
"message" : "twitter test test test"
}
},
{
"_index": "twitter",
"doc" : {
"user" : "Jane Doe",
"message" : "Another twitter test ..."
}
}
]
}
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
