前面我们已经学习了 ArrayList 、Vector、LinkedList、Stack 的源码,现在我们来对List做个简单的总结。
List整体结构
先来回顾一下List的整体结构
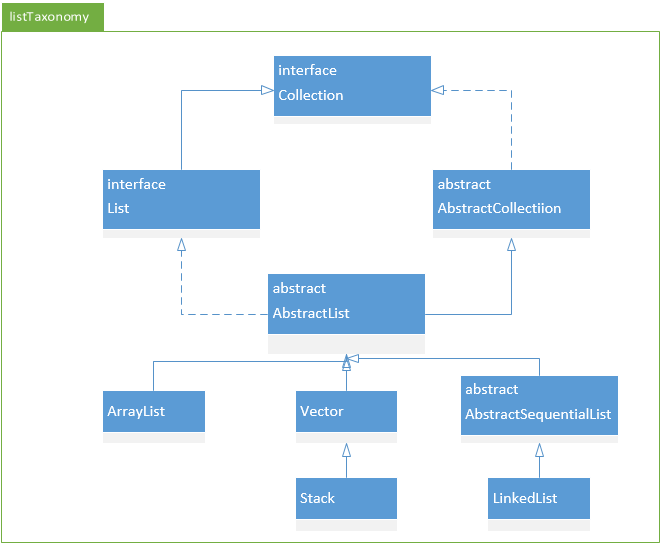
List以线性方式存储元素,集合中可以存放重复对象,元素有序。
最常用实现类:
- ArrayList :随机访问元素快,增删元素慢。
- Vector :Vector与ArrayList相似。但Vector的方法是线程安全的,而ArrayList的方法不是,由于线程的同步必然要影响性能,因此ArrayList的性能比Vector好。
- LinkedList :随机访问元素慢,顺序访问快,增删元素快。
- Stack :栈,继承Vector,特点是先进后出(FILO, First In Last Out)。
从上面List的各个实现类的特点不难得出以下结论:
-
需要快速插入删除元素,应使用LinkedList
-
不需要快速插入删除元素,需要快速随机访问元素
- 只有单个线程操作list,应使用ArrayList
- 有多个线程操作list,应使用Vector
下面从源码角度来分析为什么。
ArrayList与LinkedList比较
先来分析下为什么LinkedList比ArrayList在插入删除操作更快,然后分析为什么ArrayList在随机访问比LinkedList快。
插入删除操作的比较
先来看看LinkedList插入指定元素到指定索引处的方法。
LinkedList代码片段
/**
* 插入指定元素到指定索引处
*
* @param index 指定索引
* @param element 指定元素
* @throws IndexOutOfBoundsException 索引越界
*/
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
/**
* 检查插入操作时给定的索引是否合法
*/
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 返回插入操作时给定的索引是否合法
*/
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
/**
* 在表尾插入指定元素e
*/
void linkLast(E e) {
//使节点l指向原来的尾结点
final Node<E> l = last;
//新建节点newNode,节点的前指针指向l,后指针为null
final Node<E> newNode = new Node<>(l, e, null);
//尾指针指向新的头节点newNode
last = newNode;
//如果原来的尾结点为null,更新头指针,否则使原来的尾结点l的后置指针指向新的头结点newNode
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
/**
* 在指定节点succ之前插入指定元素e。指定节点succ不能为null。
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
//获得指定节点的前驱
final Node<E> pred = succ.prev;
//新建节点newNode,前置指针指向pred,后置指针指向succ
final Node<E> newNode = new Node<>(pred, e, succ);
//succ的前置指针指向newTouch
succ.prev = newNode;
//如果指定节点的前驱为null,将newTouch设为头节点。否则更新pred的后置节点
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
从源码中我们可以看到,通过add(int index, E element)向LinkedList插入元素时。先是判断index是否越界;然后判断index是否在链尾,如果是,就在链尾插入元素,如果不是则在链表的index处插入新的节点。
再来看看ArrayList插入指定元素到指定索引处的方法。
ArrayList代码片段
/**
* 在制定位置插入元素。当前位置的元素和index之后的元素向后移一位
*
* @param index 即将插入元素的位置
* @param element 即将插入的元素
* @throws IndexOutOfBoundsException 如果索引超出size
*/
public void add(int index, E element) {
//越界检查
rangeCheckForAdd(index);
//确认list容量,如果不够,容量加1。注意:只加1,保证资源不被浪费
ensureCapacityInternal(size + 1); // Increments modCount!!
// 对数组进行复制处理,目的就是空出index的位置插入element,并将index后的元素位移一个位置
System.arraycopy(elementData, index, elementData, index + 1,size - index);
//将指定的index位置赋值为element
elementData[index] = element;
//实际容量+1
size++;
}
/**
* 被add and addAll方法使用的索引越界检查方法
*/
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 数组容量检查,不够时则进行扩容,只供类内部使用。
*
* @param minCapacity 想要的最小容量
*/
private void ensureCapacityInternal(int minCapacity) {
//// 若elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA,则取minCapacity为DEFAULT_CAPACITY和参数minCapacity之间的最大值
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
/**
* 数组容量检查,不够时则进行扩容,只供类内部使用
*
* @param minCapacity 想要的最小容量
*/
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 确保指定的最小容量 > 数组缓冲区当前的长度
if (minCapacity - elementData.length > 0)
//扩容
grow(minCapacity);
}
/**
* 分派给arrays的最大容量
* 为什么要减去8呢?
* 因为某些VM会在数组中保留一些头字,尝试分配这个最大存储容量,可能会导致array容量大于VM的limit,最终导致OutOfMemoryError。
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 扩容,保证ArrayList至少能存储minCapacity个元素
* 第一次扩容,逻辑为newCapacity = oldCapacity + (oldCapacity >> 1);即在原有的容量基础上增加一半。第一次扩容后,如果容量还是小于minCapacity,就将容量扩充为minCapacity。
*
* @param minCapacity 想要的最小容量
*/
private void grow(int minCapacity) {
// 获取当前数组的容量
int oldCapacity = elementData.length;
// 扩容。新的容量=当前容量+当前容量/2.即将当前容量增加一半。
int newCapacity = oldCapacity + (oldCapacity >> 1);
//如果扩容后的容量还是小于想要的最小容量
if (newCapacity - minCapacity < 0)
//将扩容后的容量再次扩容为想要的最小容量
newCapacity = minCapacity;
//如果扩容后的容量大于临界值,则进行大容量分配
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData,newCapacity);
}
/**
* 进行大容量分配
*/
private static int hugeCapacity(int minCapacity) {
//如果minCapacity<0,抛出异常
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//如果想要的容量大于MAX_ARRAY_SIZE,则分配Integer.MAX_VALUE,否则分配MAX_ARRAY_SIZE
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
越界检查,确认list容量,如果不够,进行扩容,然后对数组进行复制处理,目的就是空出index的位置插入element,并将index后的元素位移一个位置,最后将指定的index位置赋值为element,实际容量+1。
在这些操作中花费时间最多的是System.arraycopy(elementData, index, elementData, index + 1,size - index);,操作将index后的所有元素右移一位。相比之下,在Linkedlist中插入元素,只需要在index处新插入一个节点,修改index前后节点的指针即可。通过上面的分析,我们就能理解为什么LinkedList中插入元素很快,而ArrayList中插入元素很慢。
随机访问操作方面的比较
下面分析为什么ArrayList在随机访问方面比LinkedList快。
再来看看ArrayList随机访问的方法。
ArrayList代码片段
/**
* 返回list中索引为index的元素
*
* @param index 需要返回的元素的索引
* @return list中索引为index的元素
* @throws IndexOutOfBoundsException 如果索引超出size
*/
public E get(int index) {
//越界检查
rangeCheck(index);
return elementData(index);
}
/**
* 返回索引为index的元素
*/
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
通过源码可以看出,在ArrayList中查找索引为index处的元素,直接返回数组中index位置的元素即可。
再来看看LinkedList随机访问的方法。
LinkedList代码片段
/**
* 返回指定索引处的元素
*
* @param index 指定索引
* @return 指定索引处的元素
* @throws IndexOutOfBoundsException 如果索引index越界
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
/**
* 返回在指定索引处的非空元素
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
从源码中可以看出,要找到索引为index的元素,LinkedList需要遍历,相比之下,ArrayList直接返回数组中索引为index处的元素无疑快了很多。
ArrayList与Vector比较
根据源码分析ArrayList与Vector的相同点和不同点
相同点
ArrayList代码片段
public class ArrayList<E> extends AbstractList<E> implements List<E>,RandomAccess,Cloneable,java.io.Serializable{
transient Object[] elementData; // non-private to simplify nested class access
}
Vector代码片段
public class Vector<E> extends AbstractList<E> implements List<E>,RandomAccess, Cloneable, Java.io.Serializable{
protected Object[] elementData;
}
从ArrayList和Vector的定义中可以看出两者是很相似的。
-
ArrayList 和Vectort :它们都支持泛型
-
extends AbstractList implements List:它们都继承于AbstractList,并且实现List了接口。
implements RandomAccess:它们都支持快速(通常是固定时间)随机访问。此接口的主要目的是允许一般的算法更改其行为,从而在将其应用到随机或连续访问列表时能提供良好的性能。下面是JDK1.8中对RandomAccess的介绍:Marker interface used by List implementations to indicate that they support fast (generally constant time) random access. The primary purpose of this interface is to allow generic algorithms to alter their behavior to provide good performance when applied to either random or sequential access lists.
-
implements Cloneable:它们都可以调用clone()方法来返回实例的field-for-field拷贝。
-
implements java.io.Serializable:它们都可以序列化。
-
Object[] elementData:它们本质都是数组
除了这些它们还有很多相似点,欢迎大家补充。
不同点**
- 线程安全性。ArrayList不是线程安全的,而Vector是线程安全的。这是它们最大的不同。
- 遍历方法不完全相同。Vector支持通过Enumeration去遍历,而ArrayList不支持。
- 构造方法不完全相同。构造Vector时支持指定自增容量。
- 扩容方法不同。
除了这些它们还有很多不同点,欢迎大家补充。
关于List的实现类的学习就到这里了,接下来学习Map的实现类。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
