上一章讲到,Acceptor线程通过创建SocketChannel与客户端完成三次握手,建立TCP连接后,会将SocketChannel交给Processor线程处理。本章,我们就来看看Processor线程内部的运行机制。
一、整体架构
Processer线程的数量是通过num.network.threads配置的,默认3个,即一个Acceptor线程对应3个Processor线程。Processor会对读/写请求进行处理,我后面会分两部分分别讲解读/写流程,这样流程会更清晰,也便于读者理解,我们先来看Processer线程的整体工作流程。
1.1 工作流程
Acceptor线程通过调用Processor.accept()方法,将SocketChannel交给Processor线程处理:Processor线程会把SocketChannel放到自己内部的一个 ConcurrentLinkedQueue 队列中:
// Processor.scala
private val newConnections = new ConcurrentLinkedQueue[SocketChannel]()
def accept(socketChannel: SocketChannel) {
// 1.将已经建立连接的SocketChannel加入到Processor内部的队列
newConnections.add(socketChannel)
// 2.唤醒Processor线程
wakeup()
}
ConcurrentLinkedQueue 我在《透彻理解Java并发编程》系列中讲解过它的底层原理,队列本身是一种链表结构,使用了 自旋+CAS 的非阻塞算法来保证线程并发访问时的数据一致性。
Processor线程在运行过程中,会按照以下的流程进行处理:
- 首先,从内部队列的队首取出一个SocketChannel;
- 接着,利用Processor自身的Selector,在SocketChannel上配置连接,并注册对
OP_READ读事件的监听; - 然后,从RequestChannel组件的响应队列中获取一个Response对象,缓存到KafkaChannel中,同时增加对
OP_WRITE事件的监听; - 接着,通过Selector轮询SelectionKey,如果有
OP_READ/OP_WRITE事件发生,就进行相应的读写操作; - 最后,对断开的连接进行处理。
// Processor.scala
override def run() {
while (isRunning) {
try {
// 1.从队列获取SocketChannel,配置连接,监听OP_READ事件
configureNewConnections()
// 2.从RequestChannel的响应队列中获取Response对象,设置到对应的KafkaChannel,同时增加对OP_WRITE事件的监听
processNewResponses()
// 3.轮询处理读请求/写响应,封装/解析底层字节流
poll()
// 4.发送封装后的读请求
processCompletedReceives()
// 5.发送解析完的写响应
processCompletedSends()
// 6.处理断开连接
processDisconnected()
} catch {
case e: ControlThrowable => throw e
case e: Throwable =>
error("Processor got uncaught exception.", e)
}
}
debug("Closing selector - processor " + id)
swallowError(closeAll())
shutdownComplete()
}
可以看到,上述整个流程和我之前讲解的Kafka客户端的NIO处理流程比较相似,核心的NIO处理流程就是在上面这个循环中完成的。
二、读请求处理流程
了解了Processor线程的整体工作流程,我们再来看它到底是如何处理客户端发送过来的消息的,也就是读请求的处理流程。
2.1 整体流程
Processor线程处理读请求的整个流程,可以用我画的下面这张图表述:

- Acceptor会通过Round Robin的轮询方式,将建立连接的SocketChannel交给Processor线程处理,也就是入队到Processor内部的一个ConcurrentLinkedQueue队列;
- 同时,Processor线程会不断出队ConcurrentLinkedQueue中的SocketChannel,通过Selector组件监听上面
OP_READ事件; - 这样,当客户端发送消息时,Processor线程就可以通过底层的NIO组件读取消息,然后按照SocketChannel维度缓存到
stagedReceives中; - 接着,Processor线程会对这些已经接受完整的消息进行处理,只取每一个Channel的最近一个消息,缓存到
completedReceives中; - 最后,遍历
completedReceives中的消息,将消息封装成 Request 对象,交给RequestChannel组件处理。
2.2 实现细节
我们再来通过代码看Processor对读请求处理的内部细节,整体工作流程在一个While循环中完成,我们只关注与读请求相关的几个流程:
// Processor.scala
override def run() {
while (isRunning) {
try {
// 1.从队列获取SocketChannel,配置连接,监听OP_READ事件
configureNewConnections()
// 2.从RequestChannel的响应队列中获取Response对象,设置到对应的KafkaChannel,同时增加对OP_WRITE事件的监听
processNewResponses()
// 3.轮询处理读请求/写响应,封装/解析底层字节流
poll()
// 4.发送封装后的读请求
processCompletedReceives()
// 5.发送解析完的写响应
processCompletedSends()
// 6.处理断开连接
processDisconnected()
} catch {
case e: ControlThrowable => throw e
case e: Throwable =>
error("Processor got uncaught exception.", e)
}
}
debug("Closing selector - processor " + id)
swallowError(closeAll())
shutdownComplete()
}
configureNewConnections
configureNewConnections方法负责遍历内部缓存SocketChannel的队列,监听OP_READ事件:
// Processor.scala
private val newConnections = new ConcurrentLinkedQueue[SocketChannel]()
private def configureNewConnections() {
// 遍历出队
while (!newConnections.isEmpty) {
val channel = newConnections.poll()
try {
debug(s"Processor $id listening to new connection from ${channel.socket.getRemoteSocketAddress}")
val localHost = channel.socket().getLocalAddress.getHostAddress
val localPort = channel.socket().getLocalPort
val remoteHost = channel.socket().getInetAddress.getHostAddress
val remotePort = channel.socket().getPort
// 创建一个唯一的连接标识,每个SocketChannel唯一
val connectionId = ConnectionId(localHost, localPort, remoteHost, remotePort).toString
// 注册对OP_READ事件的监听
selector.register(connectionId, channel)
} catch {
// We explicitly catch all non fatal exceptions and close the socket to avoid a socket leak. The other
// throwables will be caught in processor and logged as uncaught exceptions.
case NonFatal(e) =>
val remoteAddress = channel.getRemoteAddress
// need to close the channel here to avoid a socket leak.
close(channel)
error(s"Processor $id closed connection from $remoteAddress", e)
}
}
}
// Selector.java
public void register(String id, SocketChannel socketChannel) throws ClosedChannelException {
// 监听OP_READ事件
SelectionKey key = socketChannel.register(nioSelector, SelectionKey.OP_READ);
// 将SocketChannel封装成KafkaChannel
KafkaChannel channel = channelBuilder.buildChannel(id, key, maxReceiveSize);
key.attach(channel);
// 与connectionId关联
this.channels.put(id, channel);
}
poll
Processor的poll方法负责遍历SeletionKey,如果有对应的事件发生,就进行处理:
// Processor.scala
private def poll() {
// 遍历SeletionKey,有事件发生就处理,最多阻塞300毫秒
try selector.poll(300)
catch {
case e @ (_: IllegalStateException | _: IOException) =>
error(s"Closing processor $id due to illegal state or IO exception")
swallow(closeAll())
shutdownComplete()
throw e
}
}
底层是调用了Selector.poll方法,这个方法大家应该已经很熟悉了,我在讲解Kafka客户端时已经进行过详尽分析:
// Selector.java
public void poll(long timeout) throws IOException {
if (timeout < 0)
throw new IllegalArgumentException("timeout should be >= 0");
// 清楚各类缓存的数据
clear();
if (hasStagedReceives() || !immediatelyConnectedKeys.isEmpty())
timeout = 0;
long startSelect = time.nanoseconds();
int readyKeys = select(timeout);
long endSelect = time.nanoseconds();
this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds());
if (readyKeys > 0 || !immediatelyConnectedKeys.isEmpty()) {
// 遍历SelectionKey并进行处理
pollSelectionKeys(this.nioSelector.selectedKeys(), false, endSelect);
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
}
// 将完整请求添加到completedReceives缓存
addToCompletedReceives();
//...
}
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
// 遍历SelectionKey
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
// 找到关联的KafkaChannel
KafkaChannel channel = channel(key);
try {
//...
// OP_READ事件发生
if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) {
// 读取完整请求,并缓存到stagedReceives中
NetworkReceive networkReceive;
while ((networkReceive = channel.read()) != null)
addToStagedReceives(channel, networkReceive);
}
//...
} catch (Exception e) {
String desc = channel.socketDescription();
if (e instanceof IOException)
log.debug("Connection with {} disconnected", desc, e);
else
log.warn("Unexpected error from {}; closing connection", desc, e);
close(channel, true);
}
}
}
上面代码,需要特别注意的地方就是读取请求并缓存到stagedReceives中。stagedReceives本质是一个Map,按照KafkaChannel维度(一个KafkaChannel代表了一个与客户端的连接)缓存接受到的请求——NetworkReceive:
// Selector.java
private final Map<KafkaChannel, Deque<NetworkReceive>> stagedReceives;
private void addToStagedReceives(KafkaChannel channel, NetworkReceive receive) {
if (!stagedReceives.containsKey(channel))
stagedReceives.put(channel, new ArrayDeque<NetworkReceive>());
Deque<NetworkReceive> deque = stagedReceives.get(channel);
deque.add(receive);
}
然后,遍历stagedReceives,取出每个KafkaChannel最近一个读取完成的请求,缓存到completedReceives:
// Selector.java
private final List<NetworkReceive> completedReceives;
private void addToCompletedReceives() {
if (!this.stagedReceives.isEmpty()) {
Iterator<Map.Entry<KafkaChannel, Deque<NetworkReceive>>> iter = this.stagedReceives.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry<KafkaChannel, Deque<NetworkReceive>> entry = iter.next();
KafkaChannel channel = entry.getKey();
if (!channel.isMute()) {
Deque<NetworkReceive> deque = entry.getValue();
addToCompletedReceives(channel, deque);
if (deque.isEmpty())
iter.remove();
}
}
}
}
private void addToCompletedReceives(KafkaChannel channel, Deque<NetworkReceive> stagedDeque) {
NetworkReceive networkReceive = stagedDeque.poll();
this.completedReceives.add(networkReceive);
this.sensors.recordBytesReceived(channel.id(), networkReceive.payload().limit());
}
每一个KafkChannel,同一时间一次只能处理一个读请求(NetworkReceive)或写响应(NetworkSend),并且会在OP_READ和OP_WRITE间不断切换,这个后面我会详细讲。
processCompletedReceives
按照上面的流程处理完一遍后,completedReceives里面就已经保存了各个KafkaChannel接受到的最近一个读取完成的请求了,但是还没有完,Processor会遍历这些请求,封装成Request对象,交给RequestChannel处理:
// Processor.scala
private def processCompletedReceives() {
// 遍历CompletedReceives
selector.completedReceives.asScala.foreach { receive =>
try {
// 1.获取该请求关联的KafkaChannel
val openChannel = selector.channel(receive.source)
val session = {
val channel = if (openChannel != null) openChannel else selector.closingChannel(receive.source)
RequestChannel.Session(new KafkaPrincipal(KafkaPrincipal.USER_TYPE, channel.principal.getName), channel.socketAddress)
}
// 2.将请求封装成Request对象
val req = RequestChannel.Request(processor = id, connectionId = receive.source, session = session,
buffer = receive.payload, startTimeMs = time.milliseconds, listenerName = listenerName,
securityProtocol = securityProtocol)
// 3.交给RequestChannel处理
requestChannel.sendRequest(req)
// 4.将当前KafkaChannel取消对OP_READ事件的监听,也就是切换到写模式
selector.mute(receive.source)
} catch {
case e @ (_: InvalidRequestException | _: SchemaException) =>
error(s"Closing socket for ${receive.source} because of error", e)
close(selector, receive.source)
}
}
}
上面代码,需要特别注意的一点是最后调用了selector.mute(receive.source)方法, 让KafkaChannel取消对OP_READ事件的关注,一旦取消关注,意味着不再处理读请求,只关注OP_WRITE,处理写响应 :
// Selector.java
public void mute(String id) {
KafkaChannel channel = channelOrFail(id, true);
mute(channel);
}
private void mute(KafkaChannel channel) {
channel.mute();
}
// KafkaChannel.java
public void mute() {
if (!disconnected)
// 取消对OP_READ事件的关注
transportLayer.removeInterestOps(SelectionKey.OP_READ);
muted = true;
}
三、写响应处理流程
了解了Processor线程的读请求处理流程,我再来讲解它是如何处理写响应的,也就是怎么处理响应并返回给Kafka客户端。
3.1 整体流程
每一个Processor线程在RequestChannel组件中都有一个自己的响应队列responseQueue,本质是一个LinkedBlockingQueue。RequestChannel会将处理完的响应对象Response入队,然后由Processor线程进行解析并响应给客户端。
处理写响应的整个流程,可以用我画的下面这张图表述:
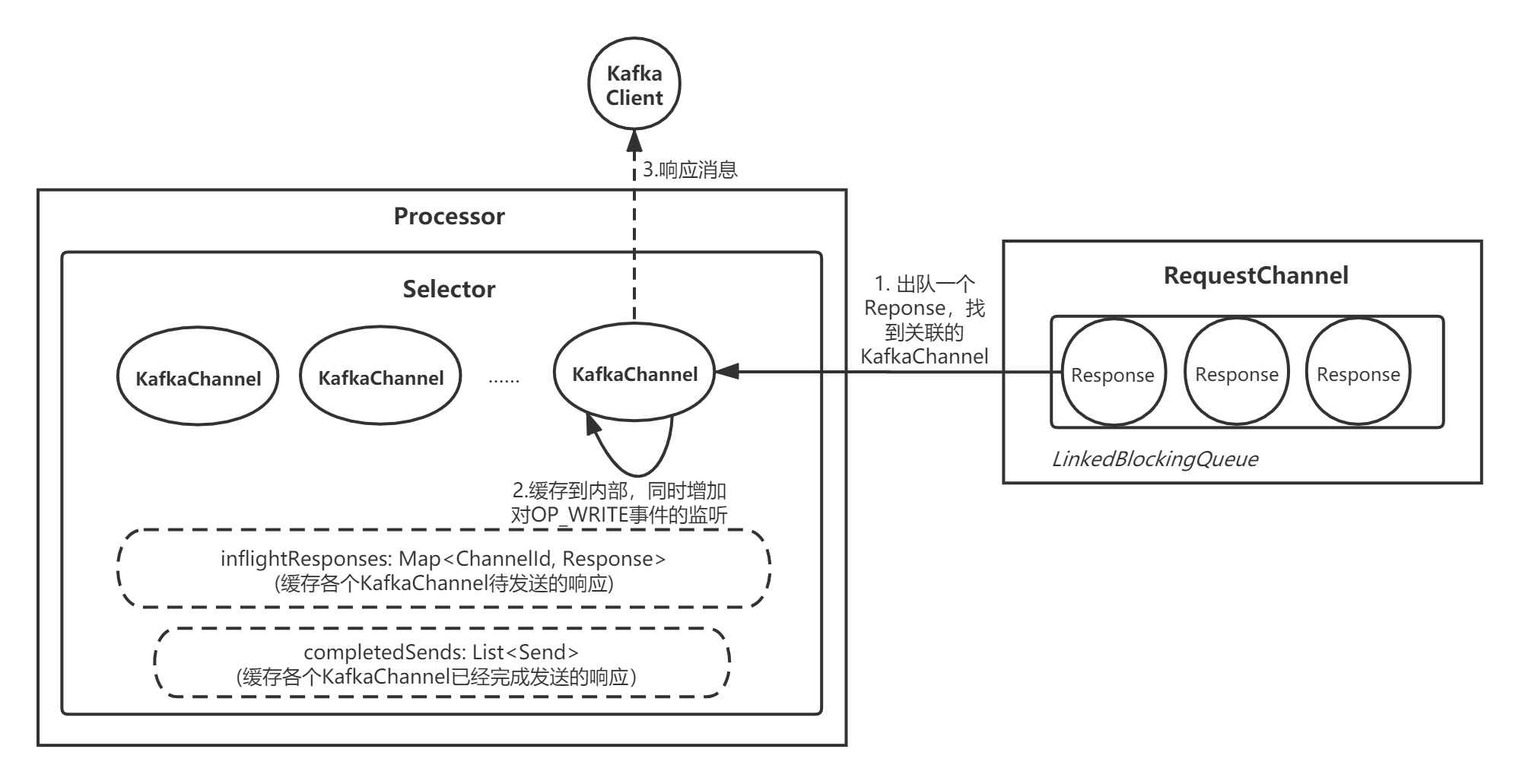
3.2 实现细节
我们再来通过代码看Processor对写响应处理的内部细节,整体工作流程还是在一个While循环中完成,我们只关注与写请求相关的几个流程:
// Processor.scala
override def run() {
while (isRunning) {
try {
// 1.从队列获取SocketChannel,配置连接,监听OP_READ事件
configureNewConnections()
// 2.从RequestChannel的响应队列中获取Response对象,设置到对应的KafkaChannel,同时增加对OP_WRITE事件的监听
processNewResponses()
// 3.轮询处理读请求/写响应,封装/解析底层字节流
poll()
// 4.发送封装后的读请求
processCompletedReceives()
// 5.发送解析完的写响应
processCompletedSends()
// 6.处理断开连接
processDisconnected()
} catch {
case e: ControlThrowable => throw e
case e: Throwable =>
error("Processor got uncaught exception.", e)
}
}
debug("Closing selector - processor " + id)
swallowError(closeAll())
shutdownComplete()
}
processNewResponses
processNewResponses方法,主要就是从RequestChannel中获取与当前Processor线程关联的一个响应队列,从响应队列中出队一个Response对象:
// Processor.scala
private def processNewResponses() {
// 1.获取Response
var curr = requestChannel.receiveResponse(id)
while (curr != null) {
try {
curr.responseAction match {
case RequestChannel.NoOpAction =>
curr.request.updateRequestMetrics
trace("Socket server received empty response to send, registering for read: " + curr)
val channelId = curr.request.connectionId
if (selector.channel(channelId) != null || selector.closingChannel(channelId) != null)
selector.unmute(channelId)
case RequestChannel.SendAction =>
// 处理Response
sendResponse(curr)
case RequestChannel.CloseConnectionAction =>
curr.request.updateRequestMetrics
trace("Closing socket connection actively according to the response code.")
close(selector, curr.request.connectionId)
}
} finally {
curr = requestChannel.receiveResponse(id)
}
}
}
然后,获取与该Response对象关联的KafkaChannel对象,并将Reponse缓存到里面,增加对OP_WRITE事件的监听:
// Processor.scala
private val inflightResponses = mutable.Map[String, RequestChannel.Response]()
protected[network] def sendResponse(response: RequestChannel.Response) {
trace(s"Socket server received response to send, registering for write and sending data: $response")
// 1.找到关联的KafkaChannel对象
val channel = selector.channel(response.responseSend.destination)
if (channel == null) {
warn(s"Attempting to send response via channel for which there is no open connection, connection id $id")
response.request.updateRequestMetrics()
}
else {
// 2.将响应对象缓存到KafkaChannel中,并增加对OP_WRITE事件的监听
selector.send(response.responseSend)
// 3.缓存到待响应的队列中
inflightResponses += (response.request.connectionId -> response)
}
}
// Selector.java
public void send(Send send) {
// 连接ID
String connectionId = send.destination();
if (closingChannels.containsKey(connectionId))
this.failedSends.add(connectionId);
else {
KafkaChannel channel = channelOrFail(connectionId, false);
try {
// 缓存响应,并增加对OP_WRITE的监听
channel.setSend(send);
} catch (CancelledKeyException e) {
this.failedSends.add(connectionId);
close(channel, false);
}
}
}
public void setSend(Send send) {
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress.");
this.send = send;
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
poll
Processor的poll方法负责遍历SeletionKey,如果有对应的事件发生,就进行处理,显然我们关注的是OP_WRITE事件。当OP_WRITE事件发生时,Processor线程会将对应KafkaChannel中缓存的响应对象通过底层NIO组件发送给客户端:
// Selector.java
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
// 遍历SeletionKey
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
KafkaChannel channel = channel(key);
try {
//...
// 如果发生了OP_WRITE事件
if (channel.ready() && key.isWritable()) {
// 将KafkaChannel中缓存的响应对象通过NIO组件发送给客户端
Send send = channel.write();
if (send != null) {
// 添加到已完成队列中
this.completedSends.add(send);
this.sensors.recordBytesSent(channel.id(), send.size());
}
}
//...
} catch (Exception e) {
String desc = channel.socketDescription();
if (e instanceof IOException)
log.debug("Connection with {} disconnected", desc, e);
else
log.warn("Unexpected error from {}; closing connection", desc, e);
close(channel, true);
}
}
}
// KafkaChanel.java
public Send write() throws IOException {
// 响应一个完整的对象
Send result = null;
if (send != null && send(send)) {
result = send;
send = null;
}
return result;
}
private boolean send(Send send) throws IOException {
// 1.通过底层NIO组件发送响应
send.writeTo(transportLayer);
// 2.发送完成后,取消对OP_WRITE事件的监听
if (send.completed())
transportLayer.removeInterestOps(SelectionKey.OP_WRITE);
return send.completed();
}
上述需要特别注意的两点是:
- 将一个请求进行完整响应后,KafkaChannel会取消对OP_WRITE事件的监听,也就是说会切换成读模式;
- 已经发送完的响应还会被缓存到
completedSends队列中。
processCompletedSends
最后,我们来看看Processor线程会对已经发送完毕的响应进行什么样的处理:
// Processor.scala
private def processCompletedSends() {
// 遍历已经发送完的响应
selector.completedSends.asScala.foreach { send =>
val resp = inflightResponses.remove(send.destination).getOrElse {
throw new IllegalStateException(s"Send for ${send.destination} completed, but not in `inflightResponses`")
}
// 更新统计信息
resp.request.updateRequestMetrics()
// 增加对OP_READ事件的监听
selector.unmute(send.destination)
}
}
显然,就是遍历已经发送的响应,同时对当前的KafkaChannel增加对OP_READ事件的监听,这样就又切换到读模式了:
// Selector.java
public void unmute(String id) {
KafkaChannel channel = channelOrFail(id, true);
unmute(channel);
}
private void unmute(KafkaChannel channel) {
channel.unmute();
}
// KafkaChannel.java
public void unmute() {
if (!disconnected)
// 增加对OP_READ事件的监听
transportLayer.addInterestOps(SelectionKey.OP_READ);
muted = false;
}
四、总结
本章,我对Processor线程的整体架构以及它对读写请求的处理流程进行了详尽的分析,我们需要重要了解: KafkaChannel只能交替处理读写请求 。下一章,我将对RequestChannel这个核心组件进行讲解。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
