linux进程管理—负载均衡
前面主要是学习进程的调度管理,默认都是在单CPU上的调度策略,在O(1)调度后,为了减小CPU之间的干扰,就会为每个CPU上分配一个任务队列,运行的时候可能会出现有的CPU很忙,有的CPU很闲,为了避免这个问题的出现,甚至最极端的情况是,一个 CPU 的可运行进程队列拥有非常多的进程,而其他 CPU 的可运行进程队列为空,这就是著名的 一核有难,多核围观,Linux 内核实现了 CPU 可运行进程队列之间的负载均衡。

1 什么是CPU负载
提到负载,我们首先会想到命令uptime或者top命令输出系统的平均负载(load average),例如uptime的输出结果
uptime
14:44:34 up 2 days, 4:14, 2 users, load average: 2.10, 2.31, 1.52
load average的三个值分别代表过去1分钟、5分钟、15分钟的系统平均负载,这三个值实际上来自于 /proc/loadavg, Linux的系统平均负载是系统中处于 runnable 与 uninterruptible 两个状态的任务总数与CPU数量的比值。
CPU负载(cpu load)指的是某个时间点进程对系统产生的压力。

- CPU的运行能力,就如大桥的通行能力,分别有满负荷,非满负荷,超负荷等状态,这几种状态对应不同的cpu load值;
- 单CPU满负荷运行时cpu_load为1,当多个CPU或多核时,相当于大桥有多个车道,满负荷运行时cpu_load值为CPU数或多核数;
- CPU负载的计算(以单CPU为例),假设一分钟内执行10个任务代表满负荷,当一分钟给出30个任务时,CPU只能处理10个,剩余20个不能处理,cpu_load=3;
从系统的角度而言,平均负载反映了系统面临的总体压力,而如果我们将视角切换到任务本身的化,那么从本质上说,系统负载代表着任务对系统资源的渴求程度。
从负载的定义是处于 runnable 与 uninterruptible 两种状态的平均进程数,也就是 平均活跃进程数 ,它和CPU是用来是没有直接关系的。而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
- 所以确切地说它不仅是CPU load,而是system load。如果因为uninterruptible的任务较多造成负载值看起来偏高,实际的系统在使用上也不见得就会出现明显的卡顿。
所以通过负载,我们直觉的认为,一个队列上挂着10个任务的CPU承受的压力比挂着5个任务的负载要更重一些,早期的CPU负载是使用runqueue深度来描述的。所以使用runqueue是一个比较粗略
- 假设当前CPU A和CPU B都挂有1个任务,但是A上运行是一个CPU密集型任务,是一个重载的任务
- 而B上是一个经常sleep的I/O密集型任务
那么仅仅通过runqueue深度来描述CPU负载就有点问题,因此现代调度器使用Cpu runqueue上task load之和来表示cpu的负载,这样就变成对任务的负载跟自动,linux3.8版本的linux内核引入了PELT算法来跟踪每一个sched entity的负载,把负载跟踪的算法从per-CPU进化到per-entity。PELT算法不但能知道CPU的负载,而且知道负载来自哪一个调度实体,从而可以更精准的进行负载均衡。
2 什么是均衡
无论是单核还是多核,只要是多任务系统,就需要调度,但调度对多核系统显得尤为重要,因为调度不当,会无法充分发挥多核的潜力。
基于多核的调度,大致有两种模型,一种是只有一个任务队列( single queue ),即当有一个任务需要执行时,选择一个空闲的CPU来承接。

这种调度方法可谓简单明了,但既然共享一个队列,那往往免不了需要上锁。此外,现代CPU可是使用了cache的,一个任务一会儿在这个CPU上运行,一会儿又在那个CPU上运行,每新到一处,cache往往都是“冷”的,执行效率必然大打折扣。
所以,任务既然交给了一个CPU做,就让它一直做嘛,各管各的,一竿子到底。从OS调度的角度,就是采用每个CPU有一个任务队列的模型( multiple queues )。

共享减少了,cache affinity(俗称"cpu affinity")也建立起来了,但新的问题也随之出现了。同时现在的CPU架构策略,对于均衡的策略也是有很大的影响soc上对于CPU的拓扑关系,我们知道目前如手机的系统都是采用的是SMP的架构,比如一个4核心的SOC,一大(更高的运算能力)一小(更低的功耗),两个核心一个cluster,那么每个cluster可以认为是一个调度域,每个MC调度域中有两个 调度组 ,每个调度组中只有一个CPU。跨cluster的负载均衡是需要清除L2 cache的,开销是很大的,因此SOC级别的DIE调度域进行负载均衡的开销会更大一些。

我们假设整个系统如果有800的负载,那么每个CPU上分配400的负载其实是不均衡的,因为大核CPU可以提供更强的算力。这样就会导致大核供给不足,而小核会出现过度供给。所以需要有两个和运算力相关的参数
| 成员 | 描述 |
|---|---|
| unsignedlongcpu_capacity | 可以用于CFS任务的算力 |
| unsignedlongcpu_capacity_orig | 该CPU的原始算力,和微架构及最大频率 |
有了各个任务负载,将runqueue中的任务负载累加起来就可以得到CPU负载,配合系统中各个CPU的算力,看起来我们就可以完成负载均衡的工作,然而事情没有那么简单,当负载不均衡的时候,任务需要在CPU之间迁移,不同形态的迁移会有不同的开销。例如一个任务在小核cluster上的CPU之间的迁移所带来的性能开销一定是小于任务从小核cluster的CPU迁移到大核cluster的开销。因此,为了更好的执行负载均衡,我们需要构建和CPU拓扑相关的数据结构,也就是调度域和调度组的概念。
3 如何负载
要实现多核系统的负载均衡,主要依靠task在不同CPU之间的迁移( migration ),也就是将一个task从负载较重的CPU上转移到负载相对较轻的CPU上去执行。从CPU的runqueue上取下来的这个动作,称为"pull",放到另一个CPU的runqueue上去,则称之为"push"。

负载均衡有两种方式:pull, push
- pull拉:负载轻的CPU,从负载繁重的CPU pull tasks来运行。这应该是主要的方式,因为不应该让负载本身就繁重的CPU执行负载均衡任务。相应的为load balance。
- push推:负载重的CPU,向负载轻的CPU,推送tasks由其帮忙执行。相应的为active balance。
但是迁移是有代价的。在同一个物理CPU的两个logical core之间迁移,因为共享cache,代价相对较小。如果是在两个物理CPU之间迁移,代价就会增大。更进一步,对于NUMA系统,在不同node之间的迁移将带来更大的损失。
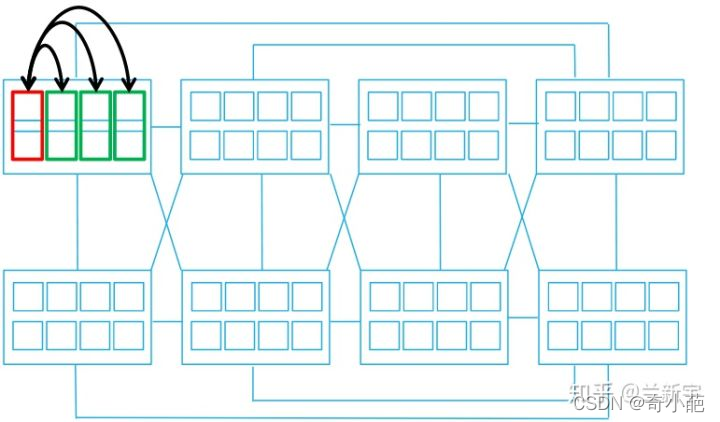
这其实形成了一个调度上的约束,在Linux中被实现为" sched domain ",并以hierarchy的形式组织。处于同一内层domain的,迁移可以更频繁地进行,越往外层,迁移则应尽可能地避免。

一个CPU拓扑示例
我们以一个4小核+4大核的处理器来描述CPU的domain和group:

在上面的结构中,sched domain是分成两个level,base domain称为MC domain(multi core domain),顶层的domain称为DIE domain。顶层的DIE domain覆盖了系统中所有的CPU,小核cluster的MC domain包括所有小核cluster中的cpu,同理,大核cluster的MC domain包括所有大核cluster中的cpu。
- 对于小核MC domain而言,其所属的sched group有四个,cpu0、1、2、3分别形成一个sched group,形成了MC domain的sched group环形链表。
- 不同CPU的MC domain的环形链表首元素(即sched domain中的groups成员指向的那个sched group)是不同的,对于cpu0的MC domain,其groups环形链表的顺序是0-1-2-3,对于cpu1的MC domain,其groups环形链表的顺序是1-2-3-0
为了减少锁的竞争,每一个cpu都有自己的MC domain和DIE domain,并且形成了sched domain之间的层级结构。在MC domain,其所属cpu形成sched group的环形链表结构,各个cpu对应的MC domain的groups成员指向环形链表中的自己的cpu group。在DIE domain,cluster形成sched group的环形链表结构,各个cpu对应的DIE domain的groups成员指向环形链表中的自己的cluster group。
4 调度域(sched domain)和调度组(sched group)
负载均衡的复杂性主要和复杂的系统拓扑有关。由于当前CPU很忙,我们把之前运行在该CPU上的一个任务迁移到新的CPU上的时候,如果迁移到新的CPU是和原来的CPU在不同的cluster中,性能会受影响(因为会cache flush)。
但是对于超线程架构,cpu共享cache,这时候超线程之间的任务迁移将不会有特别明显的性能影响。NUMA上任务迁移的影响又不同,我们应该尽量避免不同NUMA node之间的任务迁移,除非NUMA node之间的均衡达到非常严重的程度。
总之,一个好的负载均衡算法必须适配各种cpu拓扑结构。为了解决这些问题,linux内核引入了sched_domain的概念,CPU对应的调度域和调度组可通过在设备模型文件/proc/sys/kernel/sched_domain/中查看。

调度组: 调度组是组成调度域的基本单位,在最小的调度域中一个cpu core是一个调度组,在最大的调度域中,一个NUMA结点内的所有cpu core成一个调度组。
调度域: 上述结构中有3个调度域
- D0,整个系统,包括所有CPU组成一个调度域,D0调度域仅有一个,其包括两个调度组,即两个NUMA结点。
- D1,两个NUMA结点分别独立组成一个调度域,D1域的调度组是每个CPU上的物理core,即每个D1拥有4个调度组。
- D2,每个物理core构成最小的调度域,D2域的组是每个超线程。
struct sched_domain {
/*Sched domain会形成层级结构,parent和child建立了不同层级结构的父子关系。
对于base domain而言,其child等于NULL,对于top domain而言,其parent等于NULL */
struct sched_domain __rcu *parent; /* top domain must be null terminated */
struct sched_domain __rcu *child; /* bottom domain must be null terminated */
/* 一个调度域中有若干个调度组,这些调度组形成一个环形链表,groups成员就是链表头*/
struct sched_group *groups; /* the balancing groups of the domain */
/* 做均衡也是需要开销的,我们不可能时刻去检查调度域的均衡状态,
这两个参数定义了检查该sched domain均衡状态的时间间隔范围 */
unsigned long min_interval; /* Minimum balance interval ms */
unsigned long max_interval; /* Maximum balance interval ms */
/* 正常情况下,balance_interval定义了均衡的时间间隔,如果cpu繁忙,
那么均衡要时间间隔长一些,即时间间隔定义为busy_factor x balance_interval */
unsigned int busy_factor; /* less balancing by factor if busy */
/* 调度域内的不均衡状态达到了一定的程度之后就开始进行负载均衡的操作。
imbalance_pct这个成员定义了判定不均衡的门限 */
unsigned int imbalance_pct; /* No balance until over watermark */
/* 这个成员应该是和nr_balance_failed配合控制负载均衡过程的迁移力度。
当nr_balance_failed大于cache_nice_tries的时候,负载均衡会变得更加激进。*/
unsigned int cache_nice_tries; /* Leave cache hot tasks for # tries */
/* 每个cpu都有其对应LLC sched domain,而LLC SD记录对应cpu的idle状态得到该domain中busy cpu的个数*/
int nohz_idle; /* NOHZ IDLE status */
int flags; /* 调度域标志* */
int level; /* 该sched domain在整个调度域层级结构中的level*/
/* 上次进行balance的时间点,ast_balance加上这个计算得到的均衡时间间隔就是下一次均衡的时间点*/
unsigned long last_balance; /* init to jiffies. units in jiffies */
unsigned int balance_interval; /* 定义了该sched domain均衡的基础时间间隔. */
unsigned int nr_balance_failed; /*本sched domain中进行负载均衡失败的次数 */
/* 在该domain上进行newidle balance的最大时间长度 */
u64 max_newidle_lb_cost;
unsigned long last_decay_max_lb_cost;
u64 avg_scan_cost; /* 平均扫描成本 */
/* 负载均衡的统计信息 */
#ifdef CONFIG_SCHEDSTATS
/* load_balance() stats */
unsigned int lb_count[CPU_MAX_IDLE_TYPES];
unsigned int lb_failed[CPU_MAX_IDLE_TYPES];
unsigned int lb_balanced[CPU_MAX_IDLE_TYPES];
unsigned int lb_imbalance[CPU_MAX_IDLE_TYPES];
unsigned int lb_gained[CPU_MAX_IDLE_TYPES];
unsigned int lb_hot_gained[CPU_MAX_IDLE_TYPES];
unsigned int lb_nobusyg[CPU_MAX_IDLE_TYPES];
unsigned int lb_nobusyq[CPU_MAX_IDLE_TYPES];
/* Active load balancing */
unsigned int alb_count;
unsigned int alb_failed;
unsigned int alb_pushed;
/* SD_BALANCE_EXEC stats */
unsigned int sbe_count;
unsigned int sbe_balanced;
unsigned int sbe_pushed;
/* SD_BALANCE_FORK stats */
unsigned int sbf_count;
unsigned int sbf_balanced;
unsigned int sbf_pushed;
/* try_to_wake_up() stats */
unsigned int ttwu_wake_remote;
unsigned int ttwu_move_affine;
unsigned int ttwu_move_balance;
#endif
#ifdef CONFIG_SCHED_DEBUG
char *name;
#endif
union {
void *private; /* used during construction */
struct rcu_head rcu; /* used during destruction */
};
/* 为了降低锁竞争,Sched domain是per-CPU的, 该sched domain中的busy cpu的个数,
该sched domain中是否有idle的cpu*/
struct sched_domain_shared *shared;
/* span_weight说明该sched domain中CPU的个数 */
unsigned int span_weight;
/*
* Span of all CPUs in this domain.
*
* NOTE: this field is variable length. (Allocated dynamically
* by attaching extra space to the end of the structure,
* depending on how many CPUs the kernel has booted up with)
*/
/* span等于该sched domain中所有CPU core形成的cpu mask */
unsigned long span[];
};
调度域并不是一个平层结构,而是根据CPU拓扑形成层级结构。相对应的,负载均衡也不是一蹴而就的,而是会在多个sched domain中展开(例如从base domain开始,一直到顶层sched domain,逐个domain进行均衡)。内核中struct sched_group来描述调度组,其主要的成员如下:
struct sched_group {
/* sched domain中的所有sched group会形成环形链表,next指向groups链表中的下一个节点 */
struct sched_group *next; /* Must be a circular list */
atomic_t ref; /* 该sched group的引用计数 */
unsigned int group_weight; /* 该调度组中有多少个cpu */
struct sched_group_capacity *sgc; /* 该调度组的算力信息*/
int asym_prefer_cpu; /* CPU of highest priority in group */
int flags;
/*
* The CPUs this group covers.
*
* NOTE: this field is variable length. (Allocated dynamically
* by attaching extra space to the end of the structure,
* depending on how many CPUs the kernel has booted up with)
*/
unsigned long cpumask[]; /* 该调度组包括哪些CPU */
};
5 何时均衡
作为OS的心跳,只要不是NO_HZ的CPU,tick都会如约而至,这为判断是否需要均衡提供了一个绝佳的时机。不过,如果在每次tick时钟中断都去做一次balance,那开销太大了,所以balance的触发是有一个周期要求的。当tick到来的时候,在scheduler_tick函数中会调用trigger_load_balance来触发周期性负载均衡,相关的代码如下:
void scheduler_tick(void)
{
...
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
}
void trigger_load_balance(struct rq *rq)
{
/*
* Don't need to rebalance while attached to NULL domain or
* runqueue CPU is not active
*/
if (unlikely(on_null_domain(rq) || !cpu_active(cpu_of(rq))))
return;
/* 触发periodic balance */
if (time_after_eq(jiffies, rq->next_balance))
raise_softirq(SCHED_SOFTIRQ);
/* -触发nohz idle balance */
nohz_balancer_kick(rq);
}
进行调度和均衡本身也是需要消耗CPU的资源,因此比较适合交给idle的CPU来完成,idle_cpu被选中的这个idle CPU被叫做"idle load balancer "。
-
系统中有多个idle的cpu,如何选择执行nohz idle balance的那个CPU呢?
如果不考虑功耗,那么就从所有idle cpu中选择一个就可以了,但是在异构的系统中,我们应该要考虑的更多,如果idle cpu中有大核也有小核,是选择大核还是选择小核?大核CPU虽然算力强,但是功耗高。如果选择小核,虽然能省功耗,但是提供的算力是否足够。标准内核选择的最简单的算法:随便选择一个idle cpu(也就是idle cpu mask中的第一个)。

如上流程图,实际上内核的负载均衡有以下几种
- 一种是busy cpu的periodic balancer: 这种周期性负载均衡用于CFS任务的busy cpu上的负载均衡,是在时钟中断 scheduler_tick 中,找到该 domain 中最繁忙的 sched group 和 CPU runqueue,将其上的任务 pull 到本 CPU,以便让系统的负载处于均衡的状态。

- 一种是ilde cpu的NOHZ load balance: 当其他的 CPU 已经进入 idle,本 CPU 任务太重,需要通过 IPI 将其他 idle 的 CPU 唤醒来进行负载均衡。

如果没有dynamic tick特性,那么其实不需要进行nohz idle load balance,因为tick会唤醒处于idle的cpu,从而周期性tick就可以覆盖这个场景。
-
一种是ilde cpu的New idle load balance: 本 CPU 上没有任务执行,当前cfs runque中没有runnable,马上要进入 idle 状态的时候,调度器在pick next的时候,看看其他 CPU 是否需要帮忙,来从 busy cpu 上 pull 任务,让整个系统的负载处于均衡状态。

由于idle状态的CPU通常处于tickless/ nohz 模式,所以需要向它发送IPI(核间中断)来唤醒(“ kick ”),这也是为什么实现此过程的函数被命名为"nohz_balancer_kick"。
作为idle的CPU收到IPI后,将在softirq上下文中(类型为"SCHED_SOFTIRQ")执行负载均衡,其对应的处理函数是在初始化时就注册好了的。
__init void init_sched_fair_class(void)
{
#ifdef CONFIG_SMP
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
#ifdef CONFIG_NO_HZ_COMMON
nohz.next_balance = jiffies;
nohz.next_blocked = jiffies;
zalloc_cpumask_var(&nohz.idle_cpus_mask, GFP_NOWAIT);
#endif
#endif /* SMP */
这段最重要的是在内核中注册了一个软中断来做负载均衡run_rebalance_domains
static __latent_entropy void run_rebalance_domains(struct softirq_action *h)
{
struct rq *this_rq = this_rq();
/* 1. 如果当前运行队列有idle_balance值,即如果是idle,则选择CPU_IDLE类型,
如果不是idle,则选择CPU_NOT_IDLE类型。 */
enum cpu_idle_type idle = this_rq->idle_balance ?
CPU_IDLE : CPU_NOT_IDLE;
/*
* If this CPU has a pending nohz_balance_kick, then do the
* balancing on behalf of the other idle CPUs whose ticks are
* stopped. Do nohz_idle_balance *before* rebalance_domains to
* give the idle CPUs a chance to load balance. Else we may
* load balance only within the local sched_domain hierarchy
* and abort nohz_idle_balance altogether if we pull some load.
*/
/* 尝试idle cpu请求的 nohz, 并在通过 IPI 唤醒 nohz 空闲 cpu 时在 cpu 的运行队列中请求唤*/
if (nohz_idle_balance(this_rq, idle))
return;
/* normal load balance */
update_blocked_averages(this_rq->cpu);
/* 开始负载均衡,从这里可以知道负载均衡是在一个domain 内的cpu来做的 */
rebalance_domains(this_rq, idle);
}
这里暂时先不考虑nohz相关的函数,从rebalance_domains开始入手
static void rebalance_domains(struct rq *rq, enum cpu_idle_type idle)
{
int continue_balancing = 1;
int cpu = rq->cpu;
int busy = idle != CPU_IDLE && !sched_idle_cpu(cpu);
unsigned long interval;
struct sched_domain *sd;
/* 我们必须再次进行重新平衡的最早时间 */
unsigned long next_balance = jiffies + 60*HZ;
int update_next_balance = 0;
int need_serialize, need_decay = 0;
u64 max_cost = 0;
rcu_read_lock();
for_each_domain(cpu, sd) { /* 遍历到顶级调度域 */
/*
* Decay the newidle max times here because this is a regular
* visit to all the domains.
*/
need_decay = update_newidle_cost(sd, 0);
max_cost += sd->max_newidle_lb_cost;
/*没有设置continue_balancing(初始值=1),则根据need_decay值设置则跳过,否则退出循环*/
if (!continue_balancing) {
if (need_decay)
continue;
break;
}
/* 找出调度域的平衡周期 (jiffies) */
interval = get_sd_balance_interval(sd, busy);
/* 当收到来自所有 CPU 的 numa 平衡请求时,将获取锁用于串行处理。如果失败,请跳过它 */
need_serialize = sd->flags & SD_SERIALIZE;
if (need_serialize) {
if (!spin_trylock(&balancing))
goto out;
}
/* 如果当前时间超过遍历域的均衡周期,则进行负载均衡 */
if (time_after_eq(jiffies, sd->last_balance + interval)) {
if (load_balance(cpu, rq, sd, idle, &continue_balancing)) {
/*
* The LBF_DST_PINNED logic could have changed
* env->dst_cpu, so we can't know our idle
* state even if we migrated tasks. Update it.
*/
idle = idle_cpu(cpu) ? CPU_IDLE : CPU_NOT_IDLE;
busy = idle != CPU_IDLE && !sched_idle_cpu(cpu);
}
/* 更新时间间隔 */
sd->last_balance = jiffies;
interval = get_sd_balance_interval(sd, busy);
}
if (need_serialize)
spin_unlock(&balancing);
out:
/* next_balance更新每个域的last_balance +区间值中的最小值 */
if (time_after(next_balance, sd->last_balance + interval)) {
next_balance = sd->last_balance + interval;
update_next_balance = 1;
}
}
/* 如果设置了 need_decay,则更新 max_idle_balance_cost */
if (need_decay) {
/*
* Ensure the rq-wide value also decays but keep it at a
* reasonable floor to avoid funnies with rq->avg_idle.
*/
rq->max_idle_balance_cost =
max((u64)sysctl_sched_migration_cost, max_cost);
}
rcu_read_unlock();
/* 将运行队列的 next_balance 设置为更新的最小 next_balance
*/
if (likely(update_next_balance))
rq->next_balance = next_balance;
}
该函数流程如下:
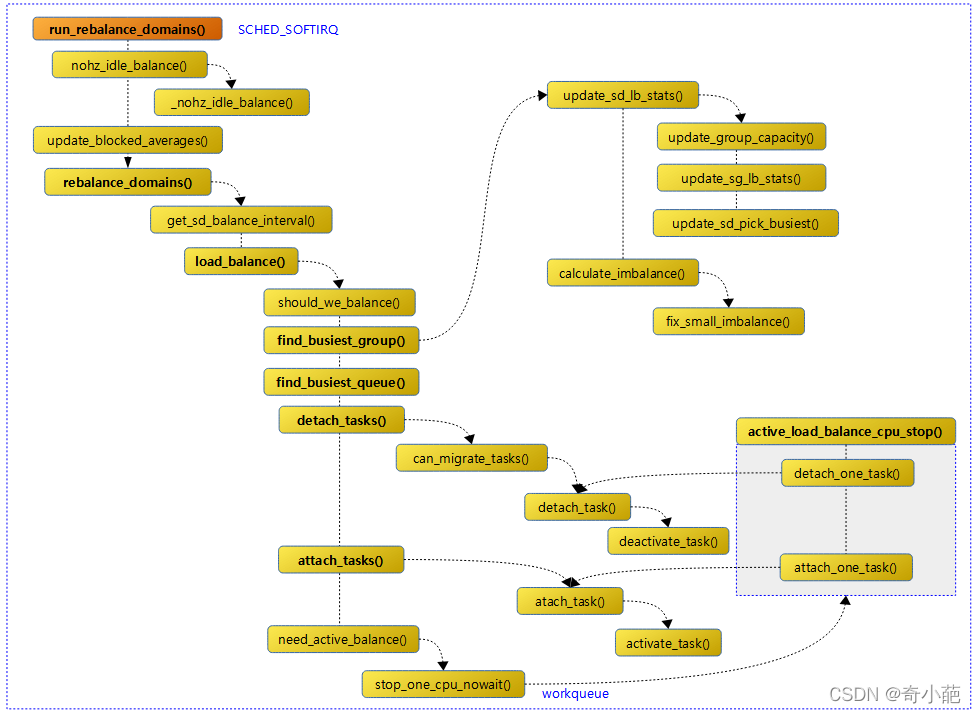
当一个CPU上进行负载均衡的时候,总是从base domain开始,检查其所属的sched group之间的负载均衡情况,如果有不均衡的情况,那么会在该CPU所属的cluster之间进行迁移,以维护cluster内各个CPU任务的负载均衡。
所以rebalance_domains职责是寻找需要被balance的sched domain,然后通过"find_busiest_group"找到该domain中最繁忙的sched group,进而通过"find_busiest_queue"在这个最繁忙的group中挑选最繁忙的CPU runqueue,被选中的CPU就成为任务迁移的 src 。

- 那接下来从这个队列中选择哪些任务来迁移呢?这就是"detach_tasks"函数要完成的事了,判断的依据主要是task load的大小,优先选择load重的任务
- 被选中迁移的任务从其所在的runqueue中移除(对应"deactive_task"函数),并被打上"TASK_ON_RQ_MIGRATING"的标记,开始向着作为 dst 的CPU runqueue进发(对应"active_task"函数)。
这里有一个例外,设置了CPU affinity,和所在CPU进行了绑定(俗称被"pin"住)的任务不能被迁移(就像被pin住的内存page不能被swap到磁盘上一样),对此进行判断的函数是"can_migrate_task"。
需要注意的是,对于CFS调度,任务迁移到一个新的runqueue之后,其在之前runqueue上的vruntime值就不适用了,需要重新进行计算和矫正,否则可能造成“不公平”(详情可参考这篇文章)。
6 总结

- 为了更好的进行CFS任务的均衡,系统需要跟踪CFS任务负载、各个sched group的负载及其CPU算力(可用于CFS任务运算的CPU算力)。跟踪任务负载是主要有两个原因:
(1)判断该任务是否适合当前CPU算力
(2)如果判定需要均衡,那么需要在CPU之间迁移多少的任务才能达到平衡?有了任务负载跟踪模块,这个问题就比较好回答了。
- 通过DTS和CPU topo子系统,我们可以构建sched domain层级结构,用于具体的均衡算法。在手机平台上,负载均衡会进行两个level:MC domain的均衡和DIE domain的均衡。
(1)在MC domain上,我们会对跟踪每个CPU负载状态(sched group只有一个CPU)并及时更新其算力,使得每个CPU上有其匹配的负载。
(2)在DIE domain上,我们会跟踪cluster上所有负载(每个cluster对应一个sched group)以及cluster的总算力,然后计算cluster之间负载的不均衡状况,通过inter-cluster迁移让整个DIE domain进入负载均衡状态
- 负载均衡的基本过程
我们以周期性均衡为例来描述负载均衡的基本过程,当一个CPU上进行周期性负载均衡的时候,我们总是从base domain开始,检查其所属sched group之间(即各个cpu之间)的负载均衡情况,如果有不均衡情况,那么会在该cpu所属cluster之间进行迁移,以便维护cluster内各个cpu core的任务负载均衡。
MC domain的均衡大致需要下面几个步骤:
- 找到MC domain中最繁忙的sched group
- 找到最繁忙sched group中最繁忙的CPU(对于MC domain而言,这一步不存在,毕竟其sched group只有一个cpu)
- 从选中的那个繁忙的cpu上拉取任务,具体拉取多少的任务到本CPU runqueue上是和不均衡的程度相关,越是不均衡,拉取的任务越多。
完成MC domain均衡之后,继续沿着sched domain层级结构向上检查,进入DIE domain,在这个level的domain上,我们仍然检查其所属sched group之间(即各个cluster之间)的负载均衡情况,如果有不均衡的情况,那么会进行inter-cluster的任务迁移。基本方法和MC domain类似,只不过在计算均衡的时候,DIE domain不再考虑单个CPU的负载和算力,它考虑的是:
(1)该sched group的负载,即sched group中所有CPU负载之和
(2)该sched group的算力,即sched group中所有CPU算力之和
参考资料
http://www.wowotech.net/process_management/load_balance.html
https://zhuanlan.zhihu.com/p/126291950
https://www.cnblogs.com/LoyenWang/p/12316660.html
https://www.codenong.com/cs107028338/
https://www.cnblogs.com/LoyenWang/p/12316660.html
http://jake.dothome.co.kr/sched-domain-2/
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
