1、映射
1.1、动态映射
底层会自动的根据存入的数据判断数据类型,这种自动分析就叫动态映射。
创建一个索引:
PUT book/_doc/1
{
"name": "三国演义",
"author": "罗贯中",
"price": 20,
"publishDate": "2020-01-01"
}
查看动态映射:
GET /book/_mapping
返回:
{
"book" : {
"mappings" : {
"properties" : {
"author" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"price" : {
"type" : "long"
},
"publishDate" : {
"type" : "date"
}
}
}
}
}
text:字符串,存储需要分词的。
keyword:字符串,存储不需要分词的。
动态映射还有一个日期检测的问题。可以看到 publishDate 的数据类型会被推断是日期类型。如果这个时候再存一本书,publishDate 不是日期,而是其他数据类型,那么存储一定会报错;如果是要存字符串类型,我们存数字类型,都一样可以,因为字符串跟数字可以转换,但是日期类型不能转换。
要解决这个问题,可以使用静态映射,即在索引定义时,将 publishDate 指定为 text 类型。也可以关闭日期检测:
PUT blog
{
"mappings": {
"date_detection": false
}
}
默认情况下,文档中如果新增了字段,mappings 中也会自动新增进来。有的时候,如果希望新增字段时,能够抛出异常来提醒开发者,这个可以通过 mappings 中 dynamic属性来配置。但是这么设置,其实也就是变成静态映射了。
1.2、静态映射
如果希望新增字段时,能够抛出异常来提醒开发者,这个可以通过 mappings 中 dynamic属性来配置。
dynamic 属性有三种取值:
- true:默认即此。自动添加新字段。
- false:忽略新字段。
- strict:严格模式,发现新字段会抛出异常。
PUT blog
{
"mappings": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text"
},
"age": {
"type": "long"
}
}
}
}
静态映射的意思就是在定义索引时,就把索引中的所有字段类型,统统提前定义枚举好,那么以后往索引中加数据和字段时,就只能按照规定好的加。
PUT /user
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"phone": {
"type": "keyword"
},
"age": {
"type": "integer"
}
}
}
}
1.3、类型推断
| JSON中的数据 | 自动推断出来的数据类型 |
|---|---|
| null | 没有字段被添加 |
| true/false | boolean |
| 浮点数字 | float |
| 数字 | long |
| JSON对象 | object |
| 数组 | 数组中的第一个非空值决定 |
| string | text/keyword/date/double/long都有可能 |
2、核心类型
2.1、字符串类型
- string :这是一个已经过期的字符串类型。在 es5 之前,用这个来描述字符串,现在的话,它已经被 text 和 keyword替代了。
- text :如果一个字段是要被全文检索的,比如说博客内容、新闻内容、产品描述,那么可以使用text。用了 text
之后,字段内容会被分析,在生成倒排索引之前,字符串会被分词器分成一个个词项。text类型的字段不用于排序,很少用于聚合。这种字符串也被称为 analyzed 字段。 - keyword :这种类型适用于结构化的字段,例如标签、email地址、手机号码等等,这种类型的字段可以用作过滤、排序、聚合等。这种字符串也称之为 not-analyzed 字段。
2.2、数字类型
| 类型 | 取值范围 |
|---|---|
| long | -2^63到2^63-1 |
| integer | -2^31到2^31-1 |
| short | -2^15到2^15-1 |
| byte | -2^7到2^7-1 |
| double | 64位的双精度IEEE754浮点类型 |
| float | 32位的双精度IEEE754浮点类型 |
| half_float | 16位的双精度IEEE754浮点类型 |
| scaled_float | 缩放类型的浮点类型 |
- 在满足需求的情况下,优先使用范围小的字段。字段长度越短,索引和搜索的效率越高。
- 浮点数,优先考虑使用 scaled_float。
scaled_float 举例:
PUT /product
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
2.3、日期类型
由于 JSON 中没有日期类型,所以 es 中的日期类型形式就比较多样:
- 2020-11-11 或者 2020-11-11 11:11:11
- 一个从 1970.1.1 零点到现在的一个秒数或者毫秒数。
es 内部将时间转为 UTC,然后将时间按照 millseconds-since-the-epoch 的长整型来存储。
自定义日期类型:
PUT /product
{
"mappings": {
"properties": {
"date": {
"type": "date"
}
}
}
}
这个能够解析出来的时间格式比较多:
PUT /product/_doc/1
{
"date": "2020-11-11"
}
PUT /product/_doc/2
{
"date": "2020-11-11T11:11:11Z"
}
PUT /product/_doc/3
{
"date": "1604672099958"
}
上面三个文档中的日期都可以被解析,内部存储的是毫秒计时的长整型数。
2.4、布尔类型(boolean)
JSON 中的 “true”、“false”、true、false 都可以。
2.5、二进制类型(binary)
二进制接受的是 base64 编码的字符串,默认不存储,也不可以搜索。
PUT /img
{
"mappings": {
"properties": {
"icon": {
"type": "binary"
}
}
}
}
2.6、范围类型
| integer_range | 一个带符号的32位整数范围,最小值为,最大值为。 |
|---|---|
| integer_range | 一个带符号的32位整数范围,最小值为,最大值为。 |
| float_range | 一系列单精度32位IEEE754浮点值。 |
| long_range | 一系列带符号的64位整数,最小值为-2的63次方,最大值为2的63次方-1。 |
| double_range | 一系列双精度64位IEEE754浮点值。 |
| date_range | 自系 EPOCH 以来经过的一系列日期值,表示为无符号的64位整数毫秒。 |
| ip_range | 支持IPv4或IPv6(或混合)地址的一系列ip值。 |
定义的时候,指定范围类型即可:
PUT range_index
{
"mappings": {
"properties": {
"expected_attendees": {
"type": "integer_range"
},
"time_frame": {
"type": "date_range",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
新增一个文档:
PUT range_index/_doc/1?refresh
{
"expected_attendees" : {
"gte" : 10,
"lte" : 20
},
"time_frame" : {
"gte" : "2015-10-31 12:00:00",
"lte" : "2015-11-01"
}
}
在上面的文档中,我们输入了两个 range 的数据,它们分别对应我们之前在 mapping 中定义的 integer_range 及 date_range。
下面我们可以使用一个 term query 来查询 integer_range 字段 expected_attendees:
GET range_index/_search
{
"query": {
"term": {
"expected_attendees": {
"value": "10"
}
}
}
}
返回:
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "range_index",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"expected_attendees" : {
"gte" : 10,
"lte" : 20
},
"time_frame" : {
"gte" : "2015-10-31 12:00:00",
"lte" : "2015-11-01"
}
}
}
]
}
}
因为 10 刚好是在我们之前的文档定义的 10-20 区间。为了验证我们的搜索是否有效,我们可以做另外的一个搜索:
GET range_index/_search
{
"query": {
"term": {
"expected_attendees": {
"value": "40"
}
}
}
}
返回空:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
2.7、复核类型
2.7.1、数组
es 中没有专门的数组类型。默认情况下,任何字段都可以有一个或者多个值。需要注意的是,数组中的元素必须是同一种类型。
添加数组时,数组中的第一个元素决定了整个数组的类型。
2.7.2、嵌套类型(nested)
nested 是 object 中的一个特例。
如果使用 object 类型,假如有如下一个文档:
{
"user":[
{"first":"zhang", "last":"san"},
{"first":"li", "last":"si"}
]
}
由于 Lucene 没有内部对象的概念,所以 es 会将对象层次扁平化,将一个对象转为字段名和值构成的简单列表。即上面的文档,最终存储形式如下:
{
"user.first":["zhang", "li"],
"user.last":["san", "si"]
}
扁平化之后,用户名之间的关系没了。这样会导致如果搜索 Zhang si 这个人,会搜索到。
此时可以 nested 类型来解决问题,nested 对象类型可以保持数组中每个对象的独立性。nested 类型将数组中的每一组对象作为独立隐藏文档来索引,这样每一个嵌套对象都可以独立被索引。
{
{"user.first":"zhang", "user.last":"san"},
{"user.fisrt":"li", "user.last":"si"}
}
- 优点:文档存储在一起,读取性能高。
- 缺点:更新父或者子文档时需要更新更个文档。比如更新 zhang 这个姓,需要连 san 这个名也一起更新。
2.7.3、对象类型(object)
由于 JSON 本身具有层级关系,所以文档包含内部对象。内部对象中,还可以再包含内部对象。
PUT /product/_doc/2
{
"date":"2020-11-11",
"info": {
"address": "Japan"
}
}
2.8、地理类型
使用场景:
- 查找某一个范围内的地理位置
- 通过地理位置或者相对中心点的距离来聚合文档
- 把距离整个到文档的评分中
- 通过距离对文档进行排序
2.8.1、geo_point
就是一个坐标点,定义方式如下:
PUT /people
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}
存储的时候,有四种方式:
PUT /people/_doc/1
{
"location": {
"lat": 34.27,
"lon": 108.94
}
}
PUT /people/_doc/2
{
"location": "34.27, 108,94"
}
PUT /people/_doc/3
{
"location": "uzbrgzfxuzup"
}
PUT /people/_doc/4
{
"location":[108.94, 34.27]
}
注意:使用数组描述,先经度后纬度。
地址位置转 geo_hash:http://www.csxgame.top/#/
2.8.2、geo_shape
| GeoJSON | Elasticsearch | 备注 |
|---|---|---|
| Point | point | 一个由经纬度描述的点 |
| LineString | linestring | 一个任意的线条,由两个以上的点组成 |
| Polygon | polygon | 一个封闭多边形 |
| MultiPoint | multipoint | 一组不连续的点 |
| MultLineString | multilinestring | 多条不关联的线 |
| MultiPolygon | multipolygon | 多个多边形 |
| GeometryCollection | geometrycollection | 集合对象的集合 |
| circle | 一个圆形 | |
| envelope | 通过左上角和右下角两个点确认的矩形 |
指定geo_shape类型:
PUT /people
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}
添加文档时,需要指定具体的类型:
PUT /people/_doc/1
{
"location": {
"type": "point",
"coordinates": [10894, 34.27]
}
}
PUT /people/_doc/2
{
"location": {
"type": "linestring",
"coordinates": [[108.94, 34.27],[100,33]]
}
}
2.9、特殊类型
2.9.1、IP
存储ip地址:
PUT /web
{
"mappings": {
"properties": {
"address": {
"type": "ip"
}
}
}
}
新增:
PUT /web/_doc/1
{
"address": "192.168.91.1"
}
查询:
GET /blog/_search
{
"query": {
"term": {
"address": {
"value": "182.168.0.0/16"
}
}
}
}
2.9.2、token_count
用于统计字符串分词后的词项个数:
PUT /blog
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"length": {
"type": "token_count",
"analyzer": "standard"
}
}
}
}
}
}
相当于新增了title.length字段用来统计分词后词项的个数,新增文档:
PUT /blog/_doc/1
{
"title": "zhang san"
}
查询:
GET /blog/_search
{
"query": {
"term": {
"title.length": {
"value": 2
}
}
}
}
3、映射参数
3.1、analyzer
定义文本字段的分词器。默认对索引和查询都是有效的。
可分词的字符串型字段的值通过一个分析器将字符串装换为一连串的索引词。每个查询、每个字段或每个索引都可以指定分析器。
在创建索引时,Elasticsearch会以这个顺序查找分析器:
- 在字段映射中定义的分析器
- 在索引设置中名为default的分析器
- 标准分析器
- 在查询时,有更多的层次
- 在全文查询中定义的分析器
- 在字段映射中定义的搜索分析器
- 在字段映射中定义的分析器
- 在索引设置中名为default_search的分析器
- 在索引设置中名为default的分析器
- 标准分析器
假设不用分词器,先看一下索引的结果:
PUT /blog/_doc/1
{
"title": "定义文本字段的分词器。默认对索引和查询都是有效的。"
}
GET /blog/_termvectors/1
{
"fields": ["title"]
}
返回:
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"took" : 22,
"term_vectors" : {
"title" : {
"field_statistics" : {
"sum_doc_freq" : 22,
"doc_count" : 1,
"sum_ttf" : 23
},
"terms" : {
"义" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 1,
"end_offset" : 2
}
]
},
"分" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 7,
"start_offset" : 7,
"end_offset" : 8
}
]
},
"和" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 15,
"start_offset" : 16,
"end_offset" : 17
}
]
},
"器" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 9,
"start_offset" : 9,
"end_offset" : 10
}
]
},
"字" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 4,
"start_offset" : 4,
"end_offset" : 5
}
]
},
"定" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 1
}
]
},
"对" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 12,
"start_offset" : 13,
"end_offset" : 14
}
]
},
"引" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 14,
"start_offset" : 15,
"end_offset" : 16
}
]
},
"效" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 21,
"start_offset" : 22,
"end_offset" : 23
}
]
},
"文" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 2,
"start_offset" : 2,
"end_offset" : 3
}
]
},
"是" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 19,
"start_offset" : 20,
"end_offset" : 21
}
]
},
"有" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 20,
"start_offset" : 21,
"end_offset" : 22
}
]
},
"本" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 3,
"start_offset" : 3,
"end_offset" : 4
}
]
},
"查" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 16,
"start_offset" : 17,
"end_offset" : 18
}
]
},
"段" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 5,
"start_offset" : 5,
"end_offset" : 6
}
]
},
"的" : {
"term_freq" : 2,
"tokens" : [
{
"position" : 6,
"start_offset" : 6,
"end_offset" : 7
},
{
"position" : 22,
"start_offset" : 23,
"end_offset" : 24
}
]
},
"索" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 13,
"start_offset" : 14,
"end_offset" : 15
}
]
},
"认" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 11,
"start_offset" : 12,
"end_offset" : 13
}
]
},
"词" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 8,
"start_offset" : 8,
"end_offset" : 9
}
]
},
"询" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 17,
"start_offset" : 18,
"end_offset" : 19
}
]
},
"都" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 18,
"start_offset" : 19,
"end_offset" : 20
}
]
},
"默" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 10,
"start_offset" : 11,
"end_offset" : 12
}
]
}
}
}
}
}
默认情况下,中文就是一个字一个字的分,这种分词方式没有任何意义。如果这样分词,查询就只能按照一个字一个字来查。
所以,我们要根据实际情况,配置合适的分词器:
PUT /blog
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
再次查询:
PUT /blog/_doc/1
{
"title": "定义文本字段的分词器。默认对索引和查询都是有效的。"
}
GET /blog/_termvectors/1
{
"fields": ["title"]
}
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"took" : 1,
"term_vectors" : {
"title" : {
"field_statistics" : {
"sum_doc_freq" : 12,
"doc_count" : 1,
"sum_ttf" : 13
},
"terms" : {
"分词器" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 4,
"start_offset" : 7,
"end_offset" : 10
}
]
},
"和" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 8,
"start_offset" : 16,
"end_offset" : 17
}
]
},
"字段" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 2,
"start_offset" : 4,
"end_offset" : 6
}
]
},
"定义" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 2
}
]
},
"对" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 6,
"start_offset" : 13,
"end_offset" : 14
}
]
},
"文本" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 2,
"end_offset" : 4
}
]
},
"有效" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 11,
"start_offset" : 21,
"end_offset" : 23
}
]
},
"查询" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 9,
"start_offset" : 17,
"end_offset" : 19
}
]
},
"的" : {
"term_freq" : 2,
"tokens" : [
{
"position" : 3,
"start_offset" : 6,
"end_offset" : 7
},
{
"position" : 12,
"start_offset" : 23,
"end_offset" : 24
}
]
},
"索引" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 7,
"start_offset" : 14,
"end_offset" : 16
}
]
},
"都是" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 10,
"start_offset" : 19,
"end_offset" : 21
}
]
},
"默认" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 5,
"start_offset" : 11,
"end_offset" : 13
}
]
}
}
}
}
}
3.2、search_analyzer
查询时候的分词器。默认情况下,如果没有配置 search_analyzer,则查询时,首先查看有没有search_analyzer,有的话,就用 search_analyzer 来进行分词,如果没有,则看有没有 analyzer,如果有,则用 analyzer 来进行分词,否则使用 es 默认的分词器。
PUT /blog
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "standard"
}
}
}
}
3.3、normalizer
normalizer 参数用于解析前(索引或者查询)的标准化配置。
比如,在 es 中,对于一些我们不想切分的字符串,我们通常会将其设置为 keyword,搜索时候也是使用整个词进行搜索。如果在索引前没有做好数据清洗,导致大小写不一致,例如 javaboy 和JAVABOY,此时,我们就可以使用 normalizer 在索引之前以及查询之前进行文档的标准化。
先来一个反例,创建一个名为 blog 的索引,设置 author 字段类型为 keyword:
PUT /blog
{
"mappings": {
"properties": {
"author": {
"type": "keyword"
}
}
}
}
PUT /blog/_doc/1
{
"author": "javaboy"
}
PUT /blog/_doc/2
{
"author": "JAVABOY"
}
返回:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.6931471,
"_source" : {
"author" : "JAVABOY"
}
}
]
}
}
大写关键字可以搜到大写的文档,小写关键字可以搜到小写的文档。
如果使用了 normalizer,可以在索引和查询时,分别对文档进行预处理。
normalizer 定义方式如下:
PUT /blog
{
"settings": {
"analysis": {
"normalizer": {
"my_normalizer": {
"type": "custom",
"filter": ["lowercase"]
}
}
}
},
"mappings": {
"properties": {
"author": {
"type": "keyword",
"normalizer": "my_normalizer"
}
}
}
}
再次测试返回:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.18232156,
"hits" : [
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.18232156,
"_source" : {
"author" : "javaboy"
}
},
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.18232156,
"_source" : {
"author" : "JAVABOY"
}
}
]
}
}
3.4、boost
boost 参数可以设置字段的权重。
boost 有两种使用思路,一种就是在定义 mappings 的时候使用,在指定字段类型时使用;另一种就是在查询(搜索)时使用。
实际开发中建议使用后者,前者有问题:如果不重新索引文档,权重无法修改。
注意:索引时最好不要进行加权,主要有这几个原因:
- 除非重索引所有的文档,索引加权值不会发生改变
- 每个查询都支持查询加权,会产生同样的效果。不同的地方在于不需要重索引就可以调整加权值
- 索引加权值所谓norm的一部分,只有一个字节。降低了字段长度归一化因子的分辨率,会导致低质量的相关性计算
PUT /blog
{
"mappings": {
"properties": {
"content": {
"type": "text",
"boost": 2
}
}
}
}
另一种方式就是在查询(搜索)的时候,指定 boost(推荐):
GET /blog/_search
{
"query": {
"match": {
"content": {
"query": "你好",
"boost": 2
}
}
}
}
3.5、coerce
数据不都是干净的。一个数字取决于如何产生,可能通过JSON体中确定的JSON数值进行提供,比如5;也可能通过一个字符串进行提供,比如"5"。或者,整型数据可能被提供浮点型数据,例如5.0或者"5…0"。
强制尝试清理脏值来匹配字段的数据类型:
- 字符串会被强制转换为数字
- 浮点型数据会被截取为整型数据
- 经纬地理点数据会归一化到标准-180:180/–90:90坐标系统
默认情况下,一下操作没有问题,就是coerce起作用:
PUT /blog
{
"mappings": {
"properties": {
"age": {
"type": "integer"
}
}
}
}
POST /blog/_doc
{
"age": "99.0"
}
如果需要修改coerce,方式如下:
PUT /blog
{
"mappings": {
"properties": {
"age": {
"type": "integer",
"coerce": false
}
}
}
}
当coerce修改为false后,数字就只能是数字,传入字符串就会报错。
3.6、copy_to
这个属性,可以将多个字段的值,复制到同一个字段中。
PUT /blog
{
"mappings": {
"properties": {
"title": {
"type": "text",
"copy_to": "full_content"
},
"content": {
"type": "text",
"copy_to": "full_content"
},
"full_content": {
"type": "text"
}
}
}
}
PUT /blog/_doc/1
{
"title": "杭州亚运会",
"content": "东道主,杭州,团体冠军"
}
GET /blog/_search
{
"query": {
"term": {
"full_content": {
"value": "团"
}
}
}
}
返回:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"title" : "杭州亚运会",
"content" : "东道主,杭州,团体冠军"
}
}
]
}
}
3.7、doc_values和fielddata
es 中的搜索主要是用到倒排索引,doc_values 参数是为了加快排序、聚合操作而生的。当建立倒排索引的时候,会额外增加列式存储映射。
doc_values 默认是开启的,如果确定某个字段不需要排序或者不需要聚合,那么可以关闭doc_values。
大部分的字段在索引时都会生成 doc_values,除了 text。text 字段在查询时会生成一个 fielddata 的数据结构,fieldata 在字段首次被聚合、排序的时候生成。
| doc_values | fielddata |
|---|---|
| 索引时创建 | 使用时动态创建 |
| 磁盘 | 内存 |
| 不占用内存 | 不占用磁盘 |
| 索引数独稍微低一点 | 文档很多时,动态创建慢,占内存 |
doc_values默认开启,fielddata默认关闭。
3.7.1、doc_values
PUT /users/_doc/1
{
"age": 100
}
PUT /users/_doc/2
{
"age": 99
}
PUT /users/_doc/3
{
"age": 98
}
PUT /users/_doc/4
{
"age": 101
}
GET /users/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
返回:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "users",
"_type" : "_doc",
"_id" : "4",
"_score" : null,
"_source" : {
"age" : 101
},
"sort" : [
101
]
},
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_score" : null,
"_source" : {
"age" : 100
},
"sort" : [
100
]
},
{
"_index" : "users",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : {
"age" : 99
},
"sort" : [
99
]
},
{
"_index" : "users",
"_type" : "_doc",
"_id" : "3",
"_score" : null,
"_source" : {
"age" : 98
},
"sort" : [
98
]
}
]
}
}
如果确定一个字段不需要排序、聚合或者在脚本中访问字段值,可以禁用文档值来节省存储空间。
由于 doc_values 默认时开启的,所以可以直接使用该字段排序,如果想关闭 doc_values ,如下:
PUT /users
{
"mappings": {
"properties": {
"age": {
"type": "integer",
"doc_values": false
}
}
}
}
此时进行排序则会报错:

3.7.2、fielddata
Doc values 是不支持 analyzed 字符串字段的,然而,这些字段仍然可以使用聚合,是因为使用了fielddata 的数据结构。与 doc values 不同,fielddata 构建和管理 100% 在内存中,常驻于 JVM 内存堆。
Fielddata默认是不启用的,因为text字段比较长,一般只做关键字分词和搜索,很少拿它来进行全文匹配和聚合还有排序,因为大多数这种情况是无意义的,一旦启用将会把text都加载到内存中,那将带来很大的内存压力。
Fielddata一些特性:
- Fielddata 是延迟加载的。如果你从来没有聚合一个分析字符串,就不会加载 fielddata 到内存中,是在查询时候构建的。
- fielddata 是基于字段加载的, 只有很活跃地使用字段才会增加fielddata 的负担。
- fielddata 会加载索引中(针对该特定字段的) 所有的文档,而不管查询是否命中。逻辑是这样:如果查询会访问文档 X、Y 和 Z,那很有可能会在下一个查询中访问其他文档。
- 如果空间不足,使用最久未使用(LRU)算法移除fielddata。
PUT /article/_doc/1
{
"content": "中国人不骗中国人"
}
GET /article/_search
{
"aggs": {
"test_aggs": {
"terms": {
"field": "content",
"size": 10
}
}
}
}
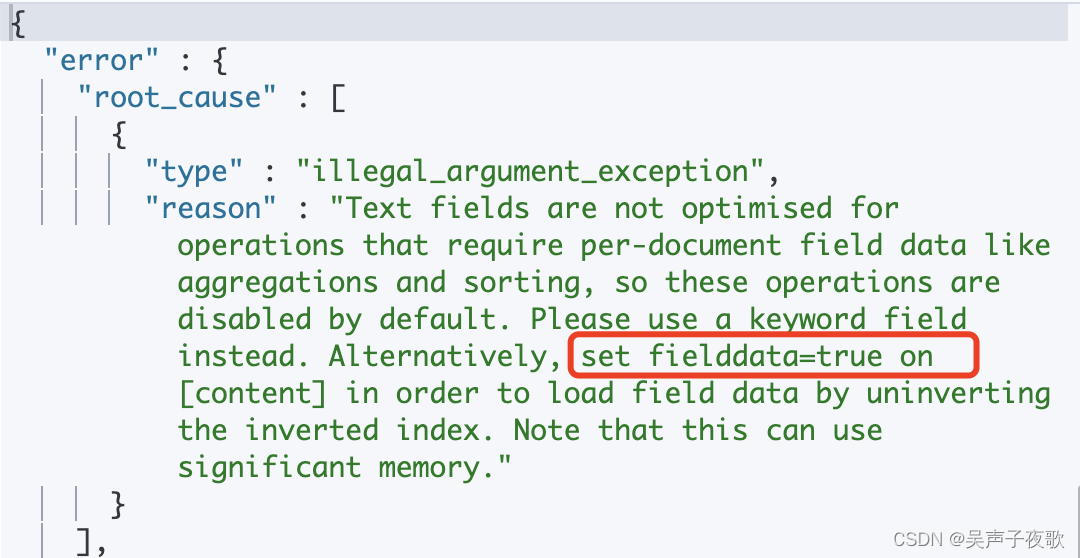
根据提示,设置fielddata为ture可以使text类型支持聚合操作:
PUT /article
{
"mappings": {
"properties": {
"content": {
"type": "text",
"fielddata": true
}
}
}
}

3.8、dynamic
默认,字段可以被动态地添加到一个文档中,或者添加到文档内部对象中,仅仅通过索引一个包含新字段的文档。
dynamic设置控制新字段是否可以被动态添加,接受三种设置:
- true:新检测到的字段会被添加到映射中(默认)
- false:新检测的字段会被忽略。新字段必须明确添加
- strict:如果新字段被检测到,一个异常会被抛出而且文档会被丢失
PUT /blog
{
"mappings": {
"dynamic": "false",
"properties": {
"title": {
"type": "text"
},
"age": {
"type": "long"
}
}
}
}
3.9、enabled
es 默认会索引所有的字段,但是有的字段可能只需要存储,不需要索引。此时可以通过 enabled 字段来控制:
enabled设置,仅可以被应用于映射类型和对象字段,导致Elasticsearch跳过字段内容的分解。JSON仍然可以从_source字段取回,但是不能搜索或以其它方式存储。
PUT /myindex2
{
"mappings": {
"properties": {
"user_id":{"type": "text", "index":false},
"last_updated":{"type": "date"},
//enabled参数为false,任意的数据都可以被存储在session_data字段,不过session_data会忽略非JSON对象的值
"session_data":{"enabled":false}
}
}
}
PUT /myindex2/_doc/1
{
"user_id":"kimchy",
"session_data":{
"arbitrary_object":{"some_array":["foo","bar",{"baz":2}]}
},
"last_updated":"2015-12-06T18:20:22"
}
PUT myindex2/_doc/2
{
"user_id":"jpountz",
"session_data":"none",
"last_updated":"2015-12-06T18:22:13"
}
GET /myindex2/_search
{
"query": {
"term": {
"session_data": {
"value": "none"
}
}
}
}
3.10、format
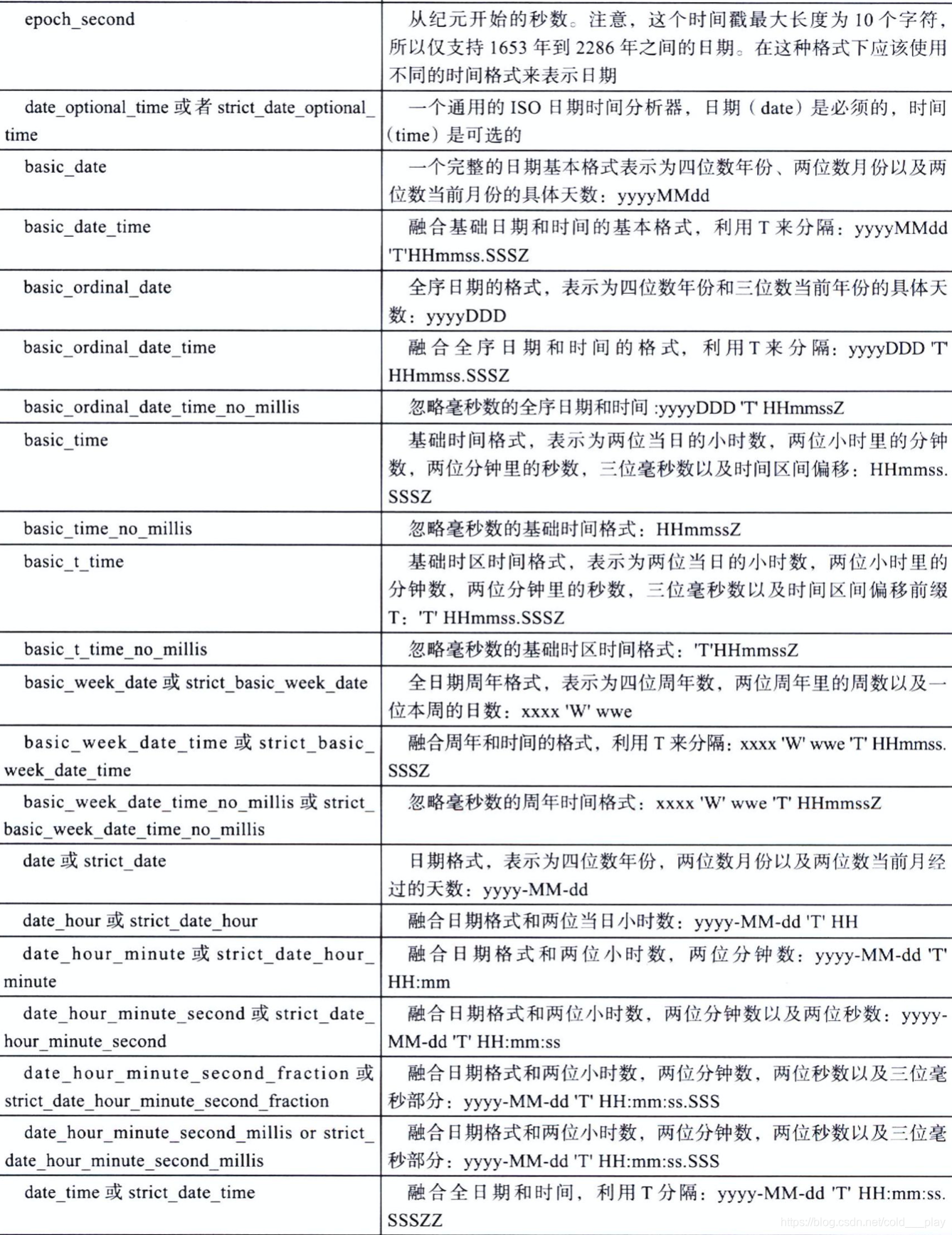
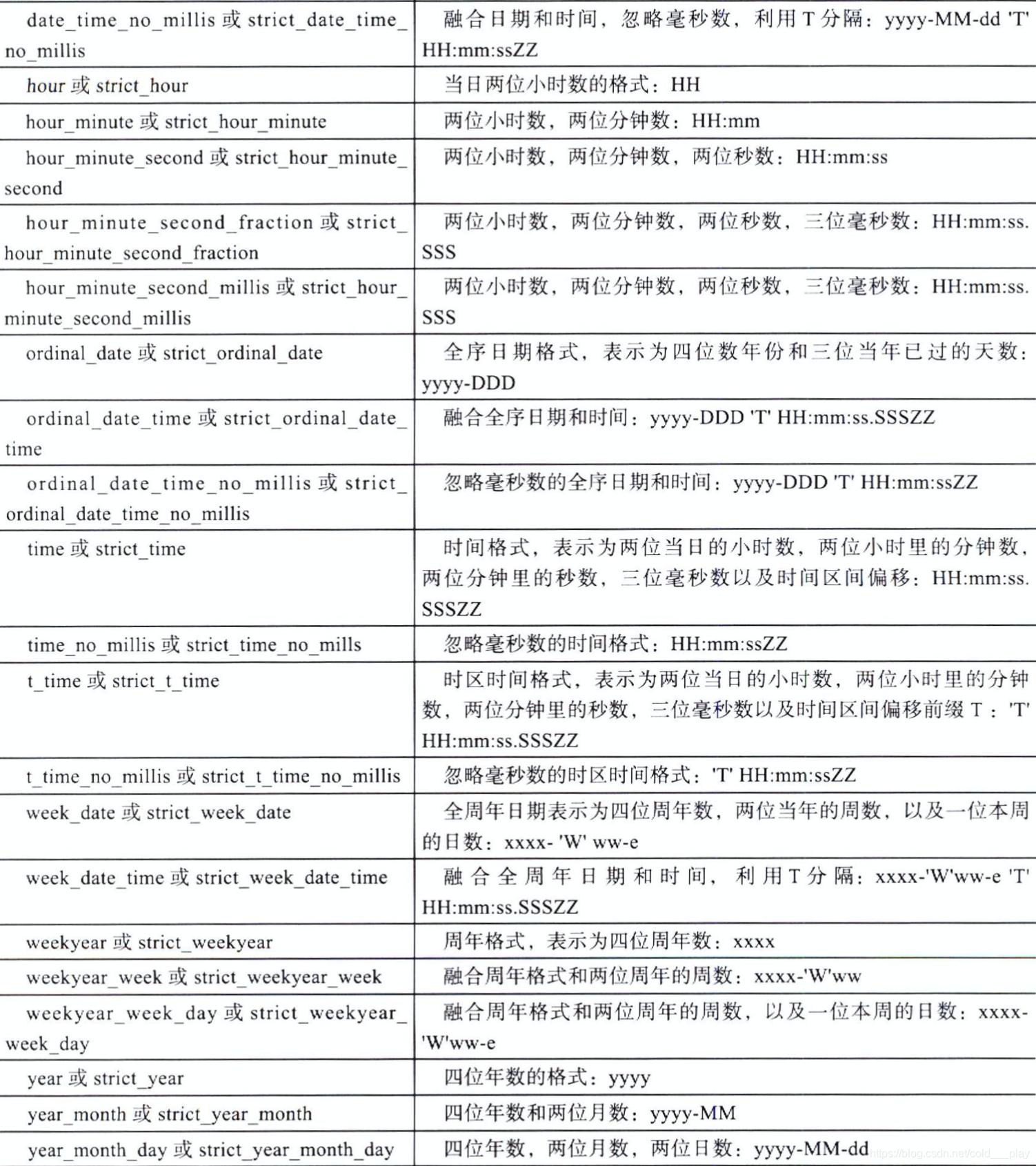
在JSON格式文档中,日期用字符串表示。Elasticsearch利用一系列的预先设定的格式来识别和分析这些字符串,产生一个长整型数值,代表世界标准时间的毫秒数。
除了内置的格式之外,也可以使用通俗的yyyy/MM/dd语法来指定自定义格式:
PUT /myindex
{
"mappings": {
"properties": {
"date":{"type": "date", "format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"}
}
}
}
3.11、ignore_above
igbore_above 用于指定分词和索引的字符串最大长度,超过最大长度的话,该字段将不会被索引,这个字段只适用于 keyword 类型。
PUT /blog
{
"mappings": {
"properties": {
"title": {
"type": "keyword",
"ignore_above": 10
}
}
}
}
PUT /blog/_doc/1
{
"title": "javaboy"
}
PUT /blog/_doc/2
{
"title": "javaboyjavaboyjavaboy"
}
GET /blog/_search
{
"query": {
"term": {
"title": {
"value": "javaboyjavaboyjavaboy"
}
}
}
}
返回:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
3.12、ignore_malformed
ignore_malformed 可以忽略不规则的数据,该参数默认为 false。
通常对于收到的数据没有做更多的控制。一个用户发送的login字段可能是日期,另一个发送的login字段可能是电子邮件地址。
默认情况下,在试着索引错误的数据类型的时候会抛出异常并拒绝整个文档。如果ignore_malformed参数被设置为true,异常会被忽略。错误字段不会被索引,但文档中的其它字段会正常处理。
PUT /blog
{
"mappings": {
"properties": {
"birthday": {
"type": "date",
"format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"
},
"age": {
"type": "integer",
"ignore_malformed": true
}
}
}
}
PUT /blog/_doc/1
{
"birthday": "2020-11-11",
"age": 99
}
PUT /blog/_doc/2
{
"birthday": "2020-11-11 11:11:11",
"age": "abc"
}
GET /blog/_search
3.13、include_in_all
include_in_all参数对每个字段进行控制是否被包含在_all字段中。默认值为true,除非索引被设为no。
这个是针对 _all 字段的,但是在 es7 中,该字段已经被废弃了。
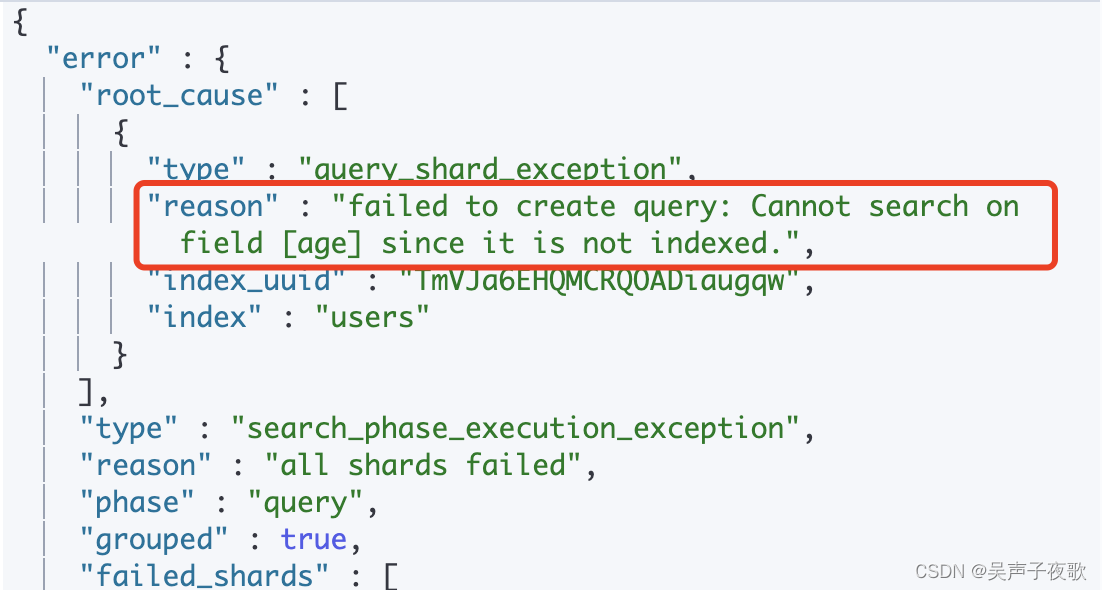
3.14、index
index 属性指定一个字段是否被索引,该属性为 true 表示字段被索引,false 表示字段不被索引。
如果 index 为 false,则不能通过对应的字段搜索。
PUT /users
{
"mappings": {
"properties": {
"age": {
"type": "integer",
"index": false
}
}
}
}
PUT /users/_doc/1
{
"age": 99
}
GET /users/_search
{
"query": {
"term": {
"age": {
"value": 99
}
}
}
}
3.15、index_options
index_options参数控制将什么信息添加到反向索引(text 类型),用于搜索和强调的目的。接受下面的参数:
- docs:只有被索引的文档数量。可以解决『字段中是否包含这个索引词』的问题。
- freqs:被索引的文档数量和索引词频率。索引词频率用来使重复索引词的得分高于单个索引词。
- positions:文档数量,索引词频率以及索引词位置。位置可以被用于临近或短语查询。
- offsets:文档数量,索引词频率、位置以及开始和结束字符偏移量(映射索引词到原始字符串)
分词字符串字段利用positions作为默认值,其他字段利用docs作为默认值。
PUT /myindex2
{
"mappings": {
"properties": {
"text":{"type": "text", "index_options": "offsets"}
}
}
}
3.16、norms
norms存储各种标准化系数(一个数字),表示相关字段得长度和索引时相关性加权设置。将会用在查询的时候计算文档对于查询条件得相关性得分。
虽然对于计算相关性得分非常有用,但是norms也需要大量得内存。所以,如果不需要在一个特殊得字段上计算相关性得分,应该在字段上禁用norms。在这种情况下,字段仅仅用于过滤或聚合。
text 默认开启 norms,如果不是特别需要,不要开启 norms。
norms可以利用PUT映射接口取消(不能被重新启用):
PUT /myindex2
{
"mappings": {
"properties": {
"title":{
"type": "text",
"norms": false
}
}
}
}
3.17、null_value
空值是不能被索引或搜索得。当一个字段设置为null(或者是一个空数组或者null值的数组),这个字段会当做没有值得字段。
null_value参数可以用指定得值替换掉确切得空值,以便可以被索引和搜索。
PUT /users
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"null_value": "notaword"
}
}
}
}
PUT /users/_doc/1
{
"name": null
}
GET /users/_search
{
"query": {
"term": {
"name": {
"value": "notaword"
}
}
}
}
3.18、position_increment_gap
被解析的 text 字段会将 term 的位置考虑进去,目的是为了支持近似查询和短语查询,当我们去索引一个含有多个值的 text 字段时,会在各个值之间添加一个假想的空间,将值隔开,这样就可以有效避免一些无意义的短语匹配,间隙大小通过 position_increment_gap 来控制,默认是 100。
PUT /users/_doc/1
{
"name": ["zhang san", "li si"]
}
GET /users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "sanli"
}
}
}
}
返回:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
sanli 搜索不到,因为两个短语之间有一个假想的空隙,为 100。
GET /users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li",
"slop": 101
}
}
}
}
返回:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.010358453,
"hits" : [
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.010358453,
"_source" : {
"name" : [
"zhang san",
"li si"
]
}
}
]
}
}
也可以在定义索引的时候,指定空隙:
PUT /users
{
"mappings": {
"properties": {
"name": {
"type": "text",
"position_increment_gap": 0
}
}
}
}
PUT /users/_doc/1
{
"name": ["zhang san", "li si"]
}
GET /users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li"
}
}
}
}
3.19、properties
类型映射,对象字段和嵌套类型字段包含子字段,成为属性。这些属性可以是任何数据类型,包含对象和嵌套类型。
属性在以下情况中添加:
- 创建索引的时候明确定义
- 利用创建映射接口添加或修改映射类型的时候明确定义
- 索引包含新字段的文档可以动态添加
PUT /myindex2
{
"mappings": {
"properties": {
"manager":{
"properties": {
"age":{"type":"integer"},
"name":{"type":"text"}
}
},
"employees":{
"type": "nested",
"properties": {
"age":{"type":"integer"},
"name":{"type":"text"}
}
}
}
}
}
PUT /myindex2/_doc/1
{
"manager": {
"age": 18,
"name": "tom"
},
"employees": {
"age": 18,
"name": "tom"
}
}
GET /myindex2/_search
{
"query": {
"match": {
"manager.name": "tom"
}
},
"aggs": {
"Employees": {
"nested": {
"path": "employees"
},
"aggs": {
"Employee Ages": {
"histogram": {
"field": "employees.age",
"interval": 5
}
}
}
}
}
}
返回:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "myindex2",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"manager" : {
"age" : 18,
"name" : "tom"
},
"employees" : {
"age" : 18,
"name" : "tom"
}
}
}
]
},
"aggregations" : {
"Employees" : {
"doc_count" : 1,
"Employee Ages" : {
"buckets" : [
{
"key" : 15.0,
"doc_count" : 1
}
]
}
}
}
}
3.20、similarity
similarity 指定文档的评分模型,默认有三种:
| 取值 | 备注 |
|---|---|
| BM25 | es和lucene默认的评分模型 |
| classic | TF/IDF评分 |
| boolean | boolean模型评分 |
PUT /blog
{
"mappings": {
"properties": {
"title" : {
"type" :"text",
"similarity": "BM25"
}
}
}
}
3.21、strore
默认情况下,字段值被索引来确保可以被搜索,但是不会被存储。这意味着可以查询字段,但是无法取回原始字段值。
通常这么做没有什么问题。字段值早已是默认存储的-source字段的一部分。如果仅仅想取回单个字段或一些字段的值,而不是整个_source字段,可以通过数据源过滤来实现:
PUT /myindex2
{
"mappings": {
"properties": {
"title":{"type": "text", "store": true},
"date":{"type": "date", "store": true, "format":"yyyy/MM/dd"},
"content":{"type": "text"}
}
}
}
PUT /myindex2/_doc/1
{
"title":"testTitle",
"date":"2015/09/12",
"content":"xxxxx"
}
//title和date字段会被存储,该请求可以取回title和date的字段值
POST /myindex2/_search
{
"stored_fields":["title","date"]
}
返回:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "myindex2",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"fields" : {
"date" : [
"2015/09/12"
],
"title" : [
"testTitle"
]
}
}
]
}
}
3.22、term_vectors
索引词向量包含分析过程产生的索引词信息,包括:
- 索引词term列表
- 每个索引词term的位置(或顺序)
- term 的首字符/尾字符与原始字符串原点的偏移量
这些索引词向量会被存储,所以作为一个特殊文档取回
term_vector设置接受以下参数:
- no:不存储索引词向量(默认)
- yes:只存储字段的索引词
- with_positions:索引词和位置将会被存储
- with_offsets:索引词和字符偏移量会被存储
- with_positions_offsets:索引词,位置以及字符偏移量都会被存储
PUT /myindex2
{
"mappings": {
"properties": {
"text":{"type": "text","term_vector": "with_positions_offsets"}
}
}
}
PUT /myindex2/_doc/1
{
"text": "hello world"
}
GET /myindex2/_doc/1/_termvectors
返回:
{
"_index" : "myindex2",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"took" : 0,
"term_vectors" : {
"text" : {
"field_statistics" : {
"sum_doc_freq" : 2,
"doc_count" : 1,
"sum_ttf" : 2
},
"terms" : {
"hello" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 5
}
]
},
"world" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 6,
"end_offset" : 11
}
]
}
}
}
}
}
3.23、fields
fields 参数可以让同一字段有多种不同的索引方式。
例如,一个字符串字段可以作为分词字段被索引用于全文搜索,也可以作为不可分词字段用于排序或聚合:
PUT /blog
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"raw": {"type": "keyword"}
}
}
}
}
}
PUT /blog/_doc/1
{
"title": "javaboy"
}
GET /blog/_search
{
"query": {
"term": {
"title.raw": {
"value": "javaboy"
}
}
}
}
另一种多字段得情况是用不同得方式对相同得字段进行分词来达到更好得相关性。
例如,可以索引一个字段,利用标准分词器将文本划分为单词,然后利用英文分词器把单词划分为它们得词根形式:
PUT /blog
{
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"english":{"type": "text","analyzer": "english"}
}
}
}
}
}
PUT /blog/_doc/1
{
"title": "quick brown foxes"
}
GET /blog/_search
{
"query": {
"term": {
"title.english": {
"value": "fox"
}
}
}
}
返回:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"title" : "quick brown foxes"
}
}
]
}
}
3.24、官方文档
映射参数官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
