上一章,Sender线程检查完Broker状态,并对未建立连接的Broker初始化连接后,会将请求重新进行分类处理:
// Sender.java
// 1. 转换成 Map<Integer, List<RecordBatch>> 形式
Map<Integer, List<RecordBatch>> batches = this.accumulator.drain(cluster, result.readyNodes,
this.maxRequestSize, now);
//...
// 2.转换成ClientRequest形式,并“发送”
sendProduceRequests(batches, now);
可以看到,上述操作对请求做了两次转换处理:
- 按照Broker ID维度,对RecordAccumulator缓冲区中的消息进行归类;
- 将要发送给一个Broker Node的所有batch进行报文拼装,转换成一个ClientRequest对象,然后“发送出去”。
本章,我就来分析上述的这两个过程。
一、请求转换
1.1 Broker维度归类
首先,我们来看RecordAccumulator.drain()的整体流程。它的核心思路就是, 对于那些已经就绪的Broker,把要往它发送的所有消息归到一起 :
- 遍历每个就绪Broker的所有Partition;
- 对每个Partition,从RecordAccumulator缓冲区获取到Deque队首的batch,放入一个
List<RecordBatch>中,表示待发送到当前Broker的所有Batch列表。
// RecordAccumulator.java
private final ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches;
public Map<Integer, List<RecordBatch>> drain(Cluster cluster, Set<Node> nodes, int maxSize, long now) {
if (nodes.isEmpty())
return Collections.emptyMap();
Map<Integer, List<RecordBatch>> batches = new HashMap<>();
// 遍历所有就绪的Broker
for (Node node : nodes) {
int size = 0;
// 获取该Broker的所有分区
List<PartitionInfo> parts = cluster.partitionsForNode(node.id());
List<RecordBatch> ready = new ArrayList<>();
int start = drainIndex = drainIndex % parts.size();
// 遍历每一个分区
do {
PartitionInfo part = parts.get(drainIndex);
TopicPartition tp = new TopicPartition(part.topic(), part.partition());
if (!muted.contains(tp)) { // 不存在未响应的请求
// 获取该分区缓存的RecordBatch
Deque<RecordBatch> deque = getDeque(new TopicPartition(part.topic(), part.partition()));
if (deque != null) {
synchronized (deque) {
// 拿出第一个RecordBatch
RecordBatch first = deque.peekFirst();
if (first != null) {
// 是否属于重试batch,backoff=true表示是
boolean backoff = first.attempts > 0 && first.lastAttemptMs + retryBackoffMs > now;
if (!backoff) {
// 请求数据大小超过限制
if (size + first.sizeInBytes() > maxSize && !ready.isEmpty()) {
break;
} else {
RecordBatch batch = deque.pollFirst();
batch.close();
size += batch.sizeInBytes();
ready.add(batch); // 加入到List
batch.drainedMs = now;
}
}
}
}
}
}
this.drainIndex = (this.drainIndex + 1) % parts.size();
} while (start != drainIndex);
batches.put(node.id(), ready);
}
return batches;
}
// 获取缓存的batch
private Deque<RecordBatch> getDeque(TopicPartition tp) {
return batches.get(tp);
}
1.2 ClientRequest对象
再来看ClientRequest对象是如何封装的。由于发送出去的请求,需要符合Kafka的二进制协议数据格式,所以客户端需要将一个个RecordBatch转换成二进制字节数组,主要包含以下内容:
- 请求头:比如api key、api version、acks、request timeout等信息;
- 请求体:RecordBatch消息内容。
// Sender.java
private void sendProduceRequests(Map<Integer, List<RecordBatch>> collated, long now) {
// 遍历每一个broker node
for (Map.Entry<Integer, List<RecordBatch>> entry : collated.entrySet())
// 封装成ClientRequest对象,并“发送”
sendProduceRequest(now, entry.getKey(), acks, requestTimeout, entry.getValue());
}
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<RecordBatch> batches) {
Map<TopicPartition, MemoryRecords> produceRecordsByPartition = new HashMap<>(batches.size());
final Map<TopicPartition, RecordBatch> recordsByPartition = new HashMap<>(batches.size());
// 1.遍历destination这个broker的所有batch,分类暂存
for (RecordBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
produceRecordsByPartition.put(tp, batch.records()); // 将batch转换成MemoryRecords形式
recordsByPartition.put(tp, batch); // 这个Map保存原始batch信息
}
// 2.ProduceRequest.Builder用来构造ClientRequest
ProduceRequest.Builder requestBuilder =
new ProduceRequest.Builder(acks, timeout, produceRecordsByPartition);
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds());
}
};
// 3.创建ClientRequest对象
String nodeId = Integer.toString(destination); // broker ID
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0, callback);
// 4.发送请求
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
上述构造过程我就不赘述了,最关键的是要清楚 往一个Broker发送的所有batch消息,会被封装成一个ClientRequest对象 。
二、请求缓存
请求转换完成后,请求的发送其实是一个异步的过程,调用了NetworkClient.send()方法,核心是做了两个事情:
- 将请求封装成Send对象,然后缓存到InFlightRequests中;
- 通过NIO组件,监听 OP_WRITE 事件,后续会异步发送请求。
2.1 InFlightRequests
NetworkClient.send()方法内部就是对请求做一些处理,核心是最后的几行代码:
// NetworkClient.java
public void send(ClientRequest request, long now) {
doSend(request, false, now);
}
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now) {
String nodeId = clientRequest.destination();
if (!isInternalRequest) {
// Broker连接状态校验
if (!canSendRequest(nodeId))
throw new IllegalStateException("Attempt to send a request to node " + nodeId + " which is not ready.");
}
// 1.构造请求
AbstractRequest request = null;
AbstractRequest.Builder<?> builder = clientRequest.requestBuilder();
try {
NodeApiVersions versionInfo = nodeApiVersions.get(nodeId);
if (versionInfo == null) {
if (discoverBrokerVersions && log.isTraceEnabled())
log.trace("No version information found when sending message of type {} to node {}. " +
"Assuming version {}.", clientRequest.apiKey(), nodeId, builder.version());
} else {
short version = versionInfo.usableVersion(clientRequest.apiKey());
builder.setVersion(version);
}
request = builder.build();
} catch (UnsupportedVersionException e) {
log.debug("Version mismatch when attempting to send {} to {}",
clientRequest.toString(), clientRequest.destination(), e);
ClientResponse clientResponse = new ClientResponse(clientRequest.makeHeader(),
clientRequest.callback(),
clientRequest.destination(), now, now,
false, e, null);
abortedSends.add(clientResponse);
return;
}
RequestHeader header = clientRequest.makeHeader();
if (log.isDebugEnabled()) {
int latestClientVersion = ProtoUtils.latestVersion(clientRequest.apiKey().id);
if (header.apiVersion() == latestClientVersion) {
log.trace("Sending {} to node {}.", request, nodeId);
} else {
log.debug("Using older server API v{} to send {} to node {}.",
header.apiVersion(), request, nodeId);
}
}
// 2.构造一个Send请求对象
Send send = request.toSend(nodeId, header);
// 3.添加到InFlightRequests缓存
InFlightRequest inFlightRequest = new InFlightRequest(
header, clientRequest.createdTimeMs(), clientRequest.destination(),
clientRequest.callback(), clientRequest.expectResponse(), isInternalRequest, send, now);
this.inFlightRequests.add(inFlightRequest);
// 4.设置监听OP_WRITE事件
selector.send(inFlightRequest.send);
}
可以看到,首先构造了Send请求对象,然后把请求对象封装成了一个 InFlightRequest 对象,最后添加到了InFlightRequests中。 InFlightRequests 内部就是保存了最近每个Broker连接当前还没有收到响应的请求:
final class InFlightRequests {
private final int maxInFlightRequestsPerConnection;
private final Map<String, Deque<NetworkClient.InFlightRequest>> requests = new HashMap<>();
public void add(NetworkClient.InFlightRequest request) {
String destination = request.destination; // Broker ID
Deque<NetworkClient.InFlightRequest> reqs = this.requests.get(destination);
if (reqs == null) {
reqs = new ArrayDeque<>();
this.requests.put(destination, reqs);
}
reqs.addFirst(request);
}
}
InFlightRequests 默认最多保存5个未收到响应的请求,通过参数max.in.flight.requests.per.connection设置:
// NetworkClient.java
private final InFlightRequests inFlightRequests;
private NetworkClient(MetadataUpdater metadataUpdater, Metadata metadata, Selectable selector,
String clientId, int maxInFlightRequestsPerConnection, long reconnectBackoffMs,
int socketSendBuffer, int socketReceiveBuffer, int requestTimeoutMs, Time time,
boolean discoverBrokerVersions) {
// maxInFlightRequestsPerConnection就是参数`max.in.flight.requests.per.connection`值
this.inFlightRequests = new InFlightRequests(maxInFlightRequestsPerConnection);
//...
}
2.2 Selector
最后,我们来看下org.apache.kafka.common.network.Selector的send方法:
// Selector.java
public void send(Send send) {
String connectionId = send.destination(); // Broker ID
if (closingChannels.containsKey(connectionId))
this.failedSends.add(connectionId);
else {
// 获取Broker对应的SocketChannel
KafkaChannel channel = channelOrFail(connectionId, false);
try {
// 设置监听OP_WRITE事件
channel.setSend(send);
} catch (CancelledKeyException e) {
this.failedSends.add(connectionId);
close(channel, false);
}
}
}
可以看到,请求对象Send还在KafkaChannel中进行了一次缓存,应为Selector.send并不是真正发送请求,而是设置Channel监听OP_WRITE事件,那么后续Selector.poll调用时,如果监听到了事件,就会将Channel中缓存的请求发送出去:
// KafkaChannel.java
public void setSend(Send send) {
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress.");
this.send = send;
// 监听OP_WRITE事件
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
三、总结
本章,我对Sender线程Loop执行过程中创建ClientReqeust对象并“发送”的底层原理进行了讲解,核心流程可以用下面这张图总结:
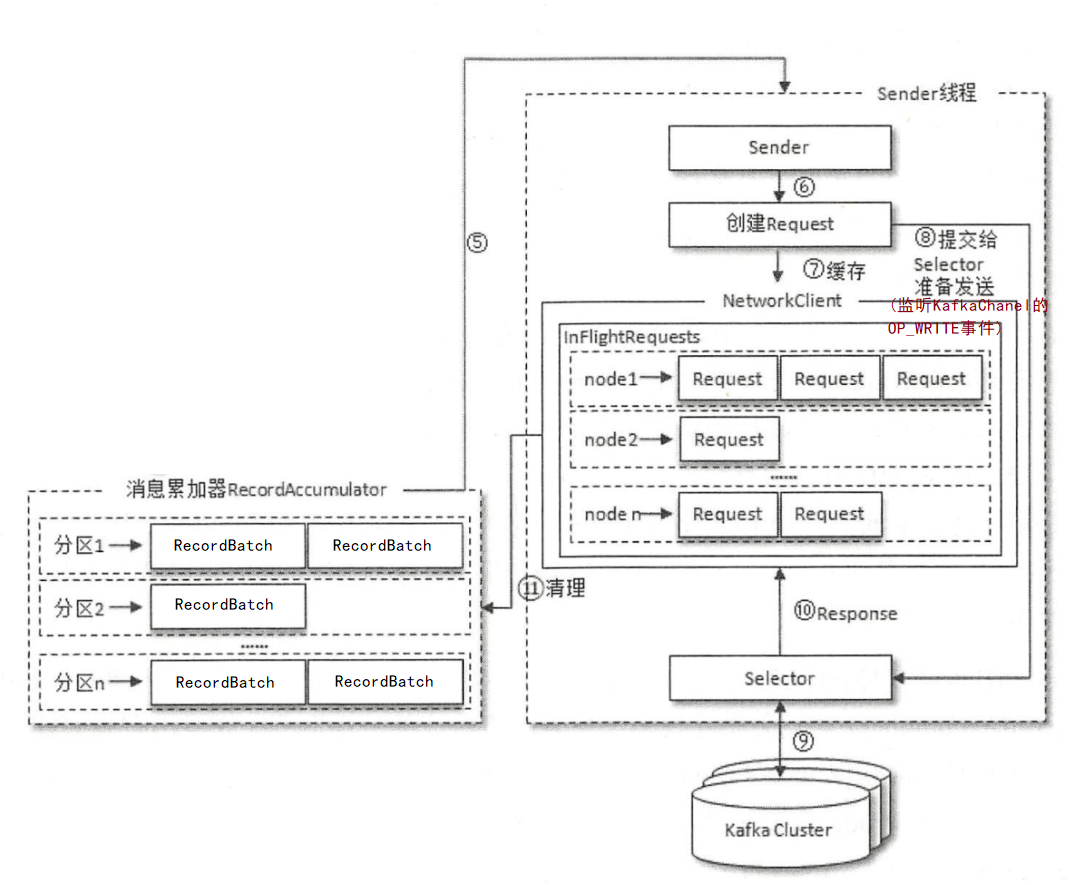
可以看到,Kafka客户端的所有网络通信请求都是通过NIO进行的,Sender.sendProduceRequests()并不是真正发送网络请求,而是封装请求对象并缓存到InFlightRequests,同时将请求提交到发送连接对应的KafkaChannel中。
Selector会监听各个Channel的OP_WRITE事件,那么当后续Sender线程执行Selector.poll()方法时,Selector如果轮询到了OP_WRITE事件的发生,就会将Channel中的请求发送给Broker。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
