字段数据类型
Elasticsearch支持一系列不同的数据类型来定义文档字段,分为核心数据、复杂数据、地理数据、专门数据类型。
核心数据:
- 字符串数据类型:string
- 数字型数据类型:long、integer、short、byte、double、float
- 日期型数据类型:date
- 布尔型数据类型:boolean
- 二进制数据类型:binary
复杂数据类型:
- 数组数据类型:不需要专门的类型来定义数组
- 对象数据类型:object,单独的JSON对象
- 嵌套数据类型:nested,关于JSON对象的数据
地理数据类型:
- 地理点数据类型:geo_point,经纬点
- 地理形状数据类型:geo_shape,多边形的复杂地理形状
专门数据类型
- IPv4数据类型:IP协议为IPv4的地址
- 完成数据类型:completion,提供自动补全的建议
- 单词计数数据类型:token_count,统计字符串中的单词数量
核心数据类型
1. 字符串数据类型
字符串数据类型的字段接受文本值,可以分为如下两种:
- 全文本:全文本值通常用于基于文本的相关性搜索,全文本字段可以分词,即在索引执行之前通过一个分词器将字符串转换为单词列表。分词操作使得Elasticsearch可以在全文本字段上搜索单词。全文本字段不用玉排序而且很少用于聚合。
- 关键字:关键字是个精准值,通常用于过滤、排序、参与聚合。关键字字段不参与分词。
示例:全文本(可以分词)字段和关键字(不可以分词)字段
PUT /myindex2
{
"mappings": {
"test2":{
"properties": {
"full_name":{"type": "text"},
"status":{"type": "text", "index": false}
}
}
}
}
其中full_name字段是一个可分词的全文本类型字段——index;默认是analyzed。status字段是一个不可分词的关键字段。
同一个字段同时拥有全文本和关键字两个版本非常游泳:一个用于全文搜索,另一个用于聚合和排序。
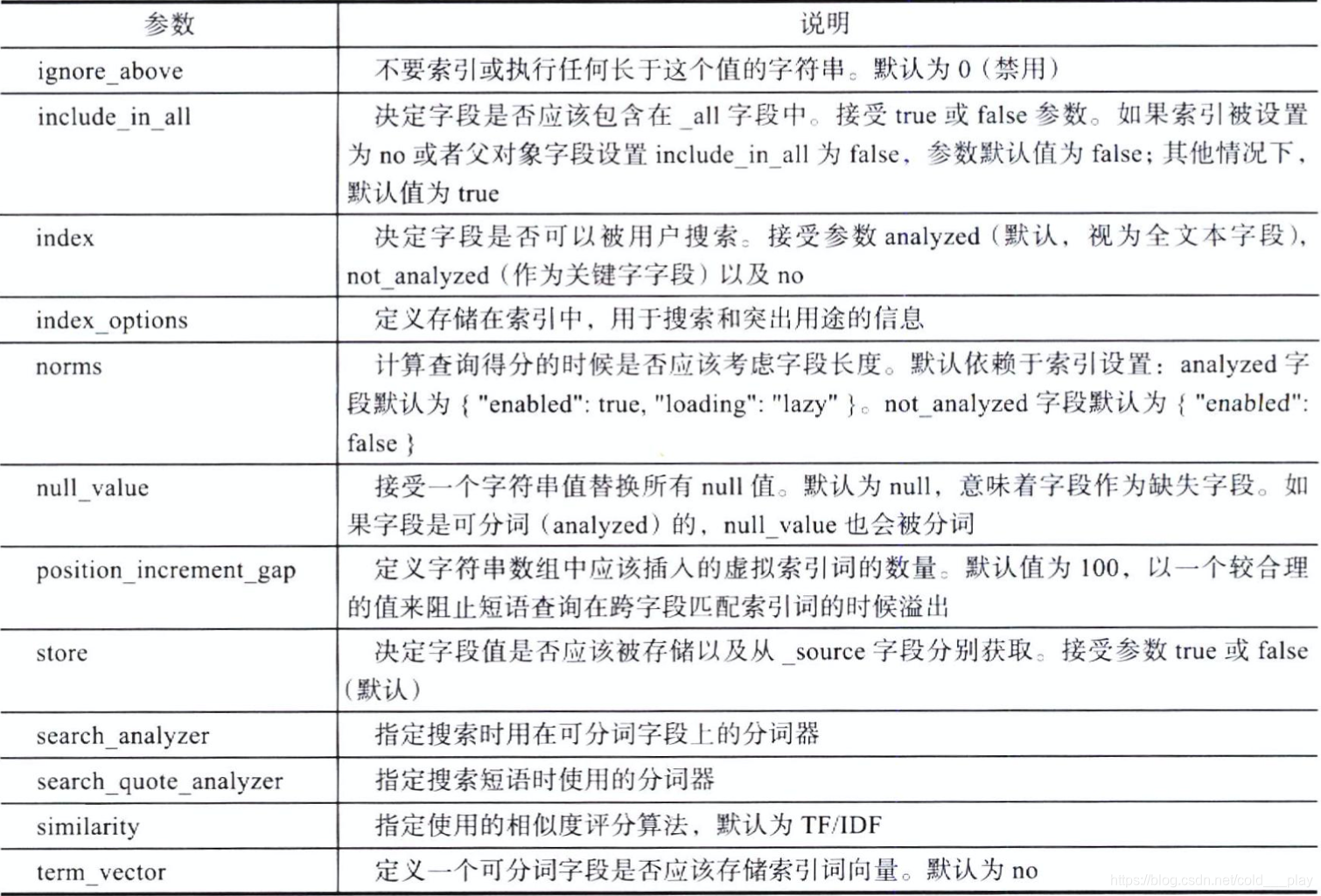
字符串数据类型的字段可以接受的参数如下表:

2. 数字型数据类型

PUT /myindex2
{
"mappings": {
"test2":{
"properties": {
"number_of_bytes": {"type": "integer"},
"time_in_seconds":{"type": "float"}
}
}
}
}
数字型字段参数:

3. 日期型数据类型
JSON没有日期型数据类型,所以在Elasticsearch中,日期可以是:
- 包含格式化日期的字符串,例如『2015-01-01』或者『2015/01/01 12:10:30』
- 代表时间毫秒数的长整型数字
- 代表时间秒数的整数
通常,日期被转换为UTC(如果时区被指定)但是存储为代表时间毫秒数的长整型数。可以自定义时间格式,如果没有指定格式,则使用默认值:
strict_date_optional_time||epoch_millis这意味着接受任何时间戳的日期值。
PUT /myindex2
{
"mappings": {
"test2":{
"properties": {
"date":{"type": "date"}
}
}
}
}
PUT /myindex2/test2/1
{
"date":"2015-01-01"
}
PUT /myindex2/test2/2
{
"date":"2015-01-01T12:10:30Z"
}
PUT /myindex2/test2/3
{
"date":"1420070400001"
}
日期字段参数:

4. 布尔数据类型
布尔字段接受true或false值,也可以接受代表真或假的字符串和数字:
- 假值:
false,"false","off","no","0",""(空串),0,0.0 - 真值:其它任何非假值
PUT /myindex2
{
"mappings": {
"test2":{
"properties": {
"is_published":{"type": "boolean"
}
}
}
}
}
PUT /myindex2/test2/1
{
"is_published": true
}
布尔类型字段参数:

5. 二进制数据类型
二进制数据类型接受Base64编码字符串的二进制值。字段不以默认方式存储而且不能搜索:
PUT /myindex2
{
"mappings": {
"test2": {
"properties": {
"name":{"type": "text"},
"blob":{"type": "binary"}
}
}
}
}
PUT /myindex2/test2/1
{
"name":"Some binary blob",
"blob": "U29tZSBiaW5hcnkgYmxvYg=="
}
Base64编码二进制值不能嵌入换行符\n。二进制数据类型的字段参数如下:
- doc_values——定义字段是否应该以列跨宽度存储在磁盘上,以便与排序、聚合或者脚本。接受true(默认)或false参数。
- dtore——决定字段值是否应该存储以及从_source字段分别获取。接受参数true或false(默认)。
复杂数据类型
1. 数组数据类型
在Elasticsearch中,没有专门的数组类型。每个字段默认可以包含零个或多个值,然而,数组中的所有值都必须是相同的数据类型。
注意:无法对数组中的每一个对象进行单独的查询。
- 当动态添加字段的时候,数组中第一个元素的值决定了字段类型
- 数组可能包含null值,会被
null_value配置替换掉或者忽略掉 - 一个空数组[]被当做缺失字段——没有值的字段
2. 对象数据类型
JSON文档是天然分层的:文档可以包含内部对象。同样,内部对象也可以包含内部对象。
对象数据类型的参数如下所示:
- dynamic:定义新的参数是否应该动态假如到已经存在的对象中。接受true(默认),false和strict。
- enabled:复制给对象字段的JSON值应该被解析和索引(true,默认)还是完全忽略(false)
- include_in_all:为对象内的所有属性设置include_in_all值。对象本身不添加到_all字段。
- properties:对象内的字段可以是任意类型,包括对象数据类型。新的属性可以添加到已存在的对象中。
3. 嵌套数据类型
嵌套数据类型是对象数据类型一个专门的版本,用来使一组对象被单独地索引和查询。
(1)对象数组是如何摊平的
Lucene没有内部对象的概念,所以Elasticsearch利用简单的列表存储字段名和值,将对象层次摊平。
PUT /myindex2/test2/1
{
"group":"fans",
"user":[
{"first":"John","last":"Smith"},
{"first":"Alice","last":"White"}
]
}
//转换为内部文档,结构如下
{
"group":"fans",
"user.first":["alice", "john"],
"user.last":["smith", "white"]
}
user.first和user.last字段存在多值字段中,alice和white的关联性丢失了。这个文档可能错误匹配到关于alice和smith的查询。
(2)对一组对象使用嵌套字段
如果需要对一组对象进行索引而且保留数组中每个对象的独立性,可以使用嵌套数据类型而不是对象数据类型。本质上,嵌套对象将数组中的每个对象作为分离出来的隐藏文档进行索引。这也意味着每个嵌套对象可以独立于其它对象被查询:
PUT /myindex2
{
"mappings": {
"test2":{
"properties": {
"user":{"type": "nested"}
}
}
}
}
PUT /myindex2/test2/1
{
"group":"fans",
"user":[
{"first":"John","last":"Smith"},
{"first":"Alice","last":"White"}
]
}
可以根据对象进行搜索,但对象的条件要全匹配才能搜到:
POST /myindex2/_search
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{"match":{"user.first":"Alice" }},
{"match":{"user.last":"White" }}
]
}
}
}
}
}
嵌套数据类型的字段参数如下:
- dynamic:定义新的参数是否应该动态加入到已经存在的对象中。接受true(默认),false和strict。
- include_in_all:为对象内的所有属性设置include_in_all值。嵌套文档没有它们自身的_all字段,取而代之的是,值被添加到"跟"文档的_all字段中。
- properties:对象内的字段可以是任意类型,包括对象数据类型。新的属性可以添加到已存在的嵌套对象中。
地理数据类型
1. 地理点数据类型
地理点数据类型字段接受经纬度,可用于:
- 查找一定范围内的的地理点,这个范围可以是相对于一个中心点的固定距离,也可以是多边形或者地理散列单元。
- 通过地理位置或者相对于中心点的距离聚合文档。
- 整合距离到文档的相关性评分中。
- 通过距离对文档进行排序。
示例:指定类型为地理位置数据类型
PUT /myindex2
{
"mappings": {
"test2":{
"properties": {
"location":{"type": "geo_point"}
}
}
}
}
存储地理位置数据有4种不同方式:
//地理点参数形如对象参数,拥有纬度和经度键值对
PUT /myindex2/test2/1
{
"text":"Geo-point as an object",
"location":{"lat":41.12,"lon":-71.34}
}
//字符串地理点参数的格式为"纬度,经度"
PUT /myindex2/test2/2
{
"text":"Geo-point as a string",
"location": "41.12,-71.34"
}
//散列地理点参数
PUT /myindex2/test2/3
{
"text":"Geo-point as a geohash",
"location": "drm3btev3e86"
}
//地理点数组参数,格式为 [经度,纬度]
PUT /myindex2/test2/4
{
"text":"Geo-point as a array",
"location": [-71.34,41.12]
}
地理点字段参数:

2. 地理形状数据类型
不常用,不做介绍…
专门数据类型
1. IPv4数据类型
IPv4字段本质上是一个长整型字段,接受IPv4地址并作为长整型进行索引。
PUT /myindex2
{
"mappings": {
"test2":{
"properties": {
"ip_addr":{"type": "ip"}
}
}
}
}
PUT /myindex2/test2/1
{
"ip_addr":"192.168.1.1"
}
IP字段参数:

2. 单词计数数据类型
单词计数型字段本质上是一个整数型字段,接受并分析字符串值,然后索引字符串中单词的个数。
PUT /myindex2
{
"mappings": {
"test2":{
"properties": {
"name":{
"type": "text",
"fields": {
"length":{"type":"token_count","analyzer":"standard"}
}
}
}
}
}
}
PUT /myindex2/test2/1
{
"name": "John Smith"
}
严格来说,单词计数类型计算位置增量而不是统计单词。这意味着即使分析器过滤掉一部分单词,它们也会被包含在计数中。
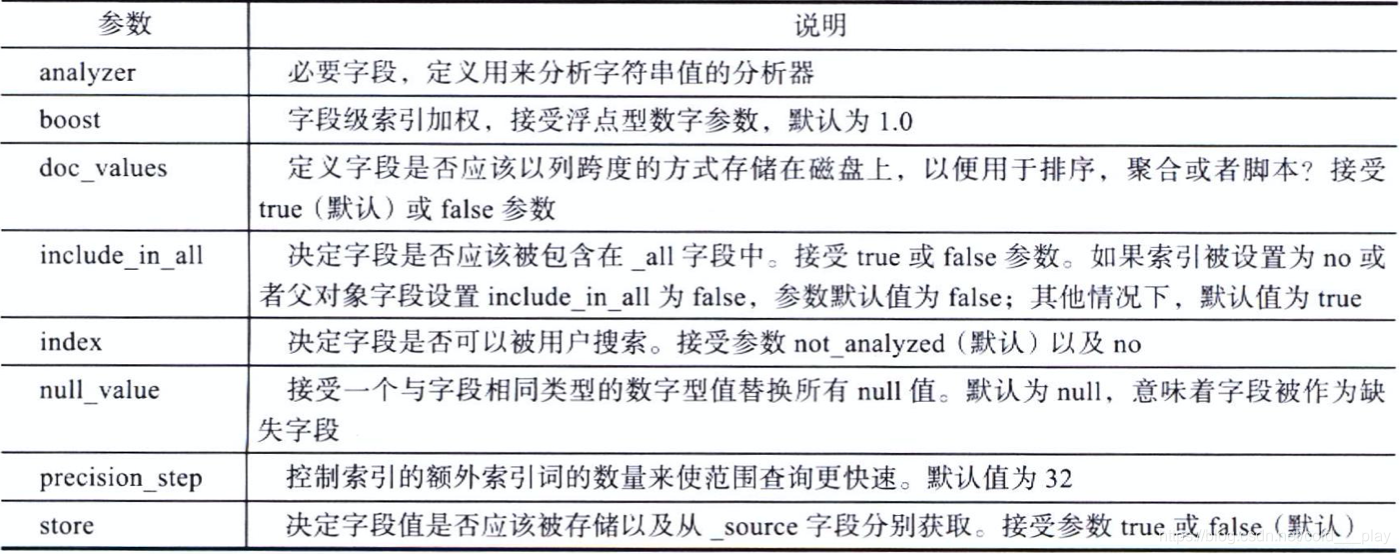
单词计数型字段参数:
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
