IK中文分词器
IK是基于字典的一款轻量级的中文分词工具包,可以通过elasticsearch的插件机制集成
1、下载
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
2、集成
在elasticsearch的安装目录下的plugin下,新建ik目录:
cd elasticsearch-7.16.0/plugings
mkdir ik
解压ik压缩包,将所有文件都放入ik目录中:
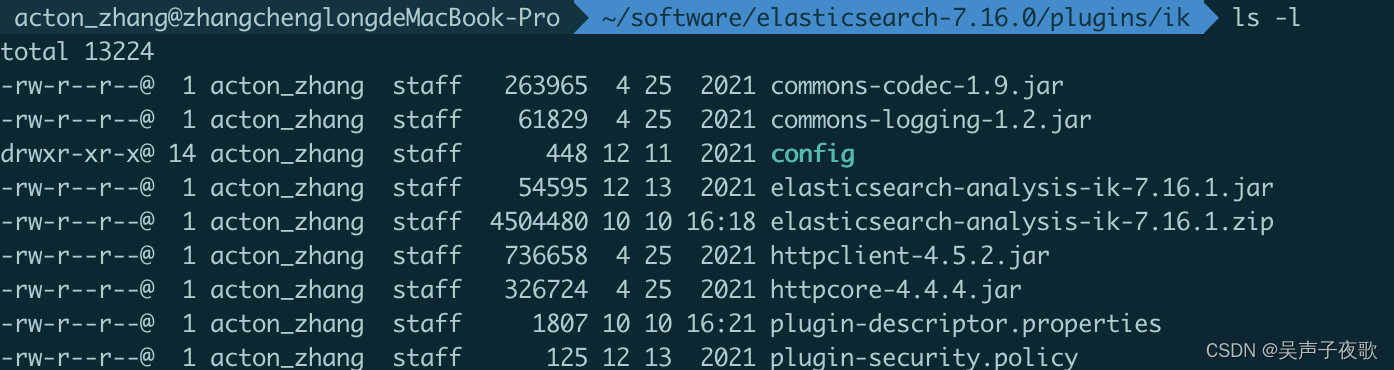
重启elasticsearch:

3、测试
IK提供了ik_smart和ik_max_word两个分析器;
ik_max_word分析器会最大程度的对文本进行分词,分词的粒度还是比较细致的;
POST _analyze
{
"analyzer": "ik_max_word",
"text":"这次出差我们住的是闫团如家快捷酒店"
}
返回:
{
"tokens" : [
{
"token" : "这次",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "出差",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "我们",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "住",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "的",
"start_offset" : 7,
"end_offset" : 8,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "是",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "闫",
"start_offset" : 9,
"end_offset" : 10,
"type" : "CN_CHAR",
"position" : 6
},
{
"token" : "团",
"start_offset" : 10,
"end_offset" : 11,
"type" : "CN_CHAR",
"position" : 7
},
{
"token" : "如家",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 8
},
{
"token" : "快捷酒店",
"start_offset" : 13,
"end_offset" : 17,
"type" : "CN_WORD",
"position" : 9
},
{
"token" : "快捷",
"start_offset" : 13,
"end_offset" : 15,
"type" : "CN_WORD",
"position" : 10
},
{
"token" : "酒店",
"start_offset" : 15,
"end_offset" : 17,
"type" : "CN_WORD",
"position" : 11
}
]
}
ik_smart相对来说粒度会比较粗:
POST _analyze
{
"analyzer": "ik_smart",
"text":"这次出差我们住的是闫团如家快捷酒店"
}
返回:
{
"tokens" : [
{
"token" : "这次",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "出差",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "我们",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "住",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "的",
"start_offset" : 7,
"end_offset" : 8,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "是",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "闫",
"start_offset" : 9,
"end_offset" : 10,
"type" : "CN_CHAR",
"position" : 6
},
{
"token" : "团",
"start_offset" : 10,
"end_offset" : 11,
"type" : "CN_CHAR",
"position" : 7
},
{
"token" : "如家",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 8
},
{
"token" : "快捷酒店",
"start_offset" : 13,
"end_offset" : 17,
"type" : "CN_WORD",
"position" : 9
}
]
}
4、扩展ik字典
4.1、本地自定义扩展词库
由于 闫团 是一个比较小的地方,ik的字典中并不包含导致分成两个单个的字符;我们可以将它添加到ik的字典中;
在ik的安装目录下config中新增my.dic文件,并将 闫团 放到文件中:

完成之后修改IKAnalyzer.cfg.xml文件,添加新增的字典文件:
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
重启elasticsearch并重新执行查看已经将地名作为一个分词了:
POST _analyze
{
"analyzer": "ik_max_word",
"text":"这次出差我们住的是闫团如家快捷酒店"
}
返回:
{
"tokens" : [
{
"token" : "这次",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "出差",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "我们",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "住",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "的",
"start_offset" : 7,
"end_offset" : 8,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "是",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "闫团",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "如家",
"start_offset" : 11,
"end_offset" : 13,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "快捷酒店",
"start_offset" : 13,
"end_offset" : 17,
"type" : "CN_WORD",
"position" : 8
},
{
"token" : "快捷",
"start_offset" : 13,
"end_offset" : 15,
"type" : "CN_WORD",
"position" : 9
},
{
"token" : "酒店",
"start_offset" : 15,
"end_offset" : 17,
"type" : "CN_WORD",
"position" : 10
}
]
}
4.2、远程词库
也可以配置远程词库,远程词库支持热更新(不用重启 es 就可以生效)。
热更新只需要提供一个接口,接口返回扩展词即可。
比如可以采用SpringBoot项目,引入Web依赖。在resources/static目录下新建my.dic,写入扩展词:
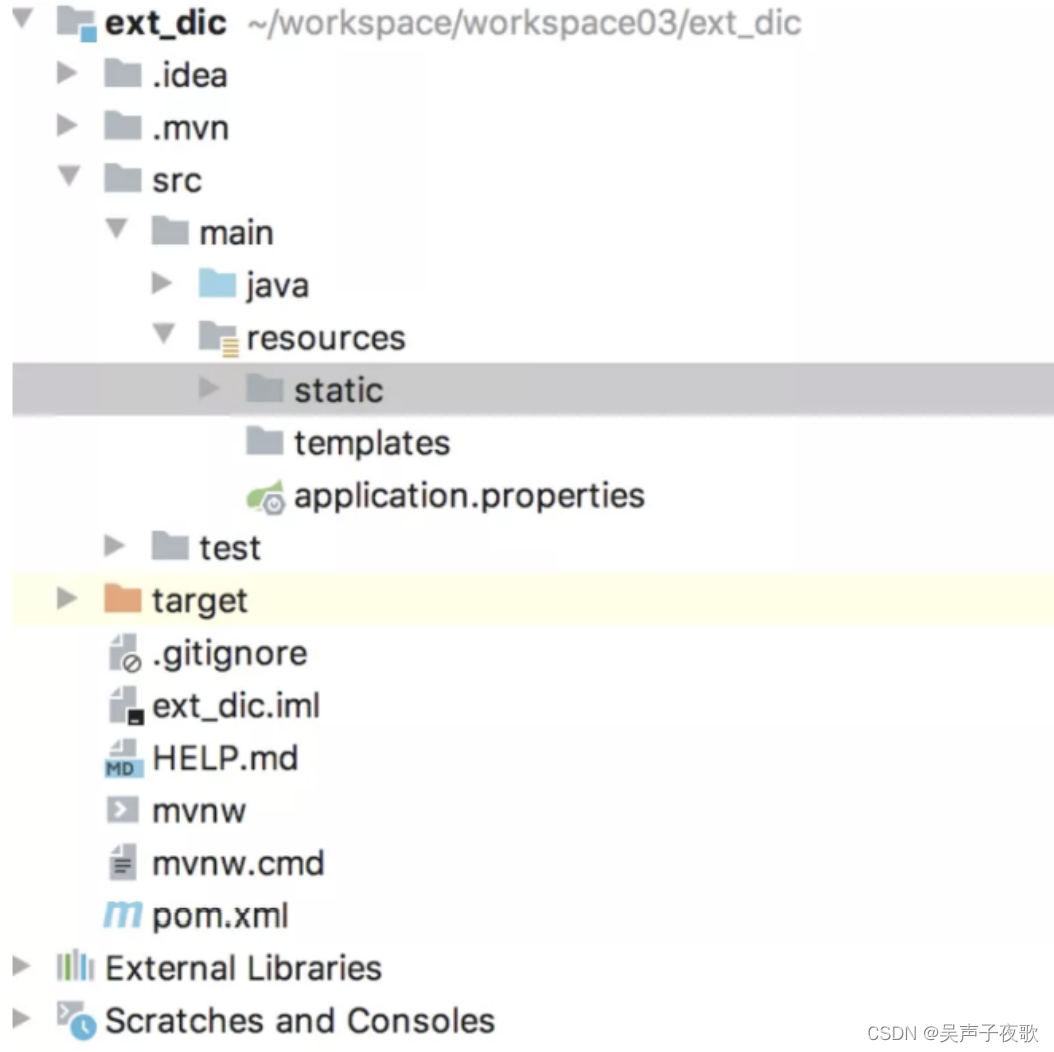
接下来,在 es/plugins/ik/config/IKAnalyzer.cfg.xml 文件中配置远程扩展词接口:
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://localhost:8080/my.dic</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
配置完成后,重启 es ,即可生效。
热更新,主要是响应头的 Last-Modified 或者 ETag 字段发生变化,ik 就会自动重新加载远程扩展。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
