Controller设计
1、Controller概览
在一个Kafka集群中,某个broker会被选举出来承担特殊的角色,即控制器(下称controller)。顾名思义,引入controller就是用来管理和协调Kafka集群的。具体来说,就是管理集群中所有分区的状态并执行相应的管理操作。
每个Kafka集群任意时刻都只能有一个controller。当集群启动时,所有broker都会参与controller的竞选,但最终只能由一个broker胜出。一旦controller在某个时刻崩溃,集群中剩余的broker会立刻得到通知,然后开启新一轮的controller选举。新选举出来的controller将承担起之前controller的所有工作。下图展示了controller的架构。
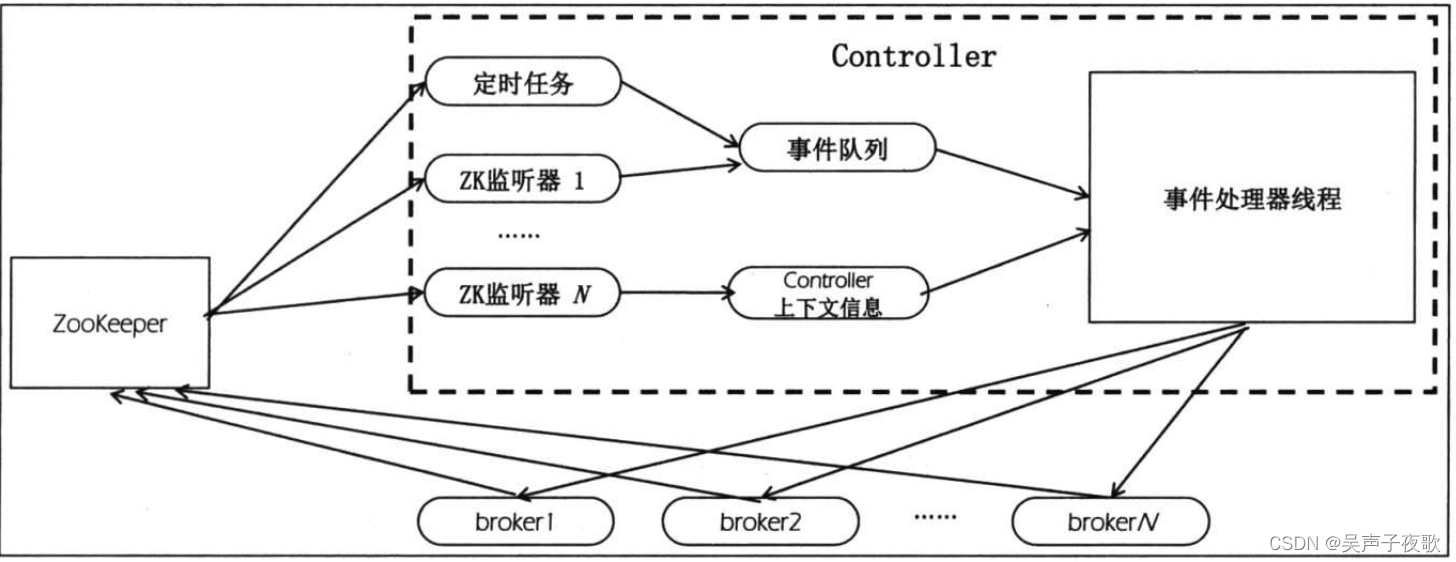
2、Controller管理状态
简单地说,controller维护的状态分为两类:每台broker上的分区副本和每个分区的leader副本信息。从维度上看,这些状态又可分为副本状态和分区状态。controller为了维护这两个状态专门引入了两个状态机,分别管理副本状态和分区状态。
2.1、副本状态机(Replica State Machine)
当前,Kafka为副本定义了7种状态以及每个状态之间的流转规则。这些状态分别如下。
NewReplicac:ontroller创建副本时的最初状态。当处在这个状态时,副本只能成为follower副本。OnlineReplica:启动副本后变更为该状态。在该状态下,副本既可以成为follower副本也可以成为leader副本。OfflineReplica:一旦副本所在broker崩溃,该副本将变更为该状态。ReplicaDeletionStarted1:若开启了topic删除操作,topic下所有分区的所有副本都会被删除。此时副本进入该状态。ReplicaDeletionSuccessful:若副本成功响应了删除副本请求,则进入该状态。ReplicaDeletionIneligible:若副本删除失败,则进入该状态。NonExistentReplica:若副本被成功删除,则进入该状态。
副本状态机的流转规则如图所示。当创建某个topic后,该topic下所有分区的所有副本都是NonExistent状态的,此时controller加载ZooKeeper中该topic每个分区的所有副本
信息到内存中,同时将副本状态变更为New,之后controller选择该分区副本列表中的第一个副本作为分区的leader副本并设置所有副本进入ISR,然后在ZooKeeper中持久化该决定。
一旦确定了分区的leader和ISR之后,controller会将这些信息以请求的方式发送给所有副本,同时将这些副本状态同步到集群的所有broker上以便让它们知晓。当这些都做完后,controller会将分区的所有副本状态置为Online,这也是副本正常工作的状态。
当开启了topic删除操作时,controller会尝试停止所有副本,此时副本将停止向leader获取数据,但若停止的副本就是leader副本本身,则controller会设置该分区的leader为
NO LEADER,之后副本进入Offline状态。一旦所有副本进入Offline状态,controller需要将副本进一步变更到ReplicaDeletionStarted状态表明删除topic任务的开启。在这一步的状态流转中,controller会给这些副本所在的broker发送请求,让它们删除本机上的副本数据。一
旦删除成功,这些副本就变更到ReplicaDeletionSuccessful状态;如果有失败的副本,那么该副本进入ReplicaDeletionIneligible状态表明暂时还无法删除该副本,等待controller的重试。
那些处于ReplicaDeletionSuccessful状态的副本稍后会被自动地变更到NonExistent终止状态,同时controller的上下文缓存会清除这些副本信息。这就是副本状态机操作副本状态流转的典型场景。

2.2、分区状态机(Partition State Machine)
除了副本状态机,controller还引入了分区状态机来负责集群下所有分区的状态管理:
分区状态机只定义了4个分区状态,它们分别如下。
NonExistent:表明不存在的分区或已删除的分区。NewPartition:一旦被创建,分区便处于该状态。此时,Kafka己经为分区确定了副本列表,但尚未选举出leader和ISR。OnlinePartition:一旦该分区的leader被选出,则进入此状态。这也是分区正常工作时的状态。OfflinePartition:在成功选举出leader后,若leader所在的broker宕机,则分区将进入该状态,表明无法正常工作了。

比起副本状态机7个状态,分区状态机的状态空间要小得多,分析它们之间状态的流转也要容易得多。当创建topic时,controller负责创建分区对象,它首先会短暂地将所有分区状态设置为NonExistent,之后马上读取ZooKeeper中(严格来说是从controller的上下文信息中读取,关于controller的上下文信息稍后会详细讨论)的副本分配方案,然后令分区状态进入NewPartition。处于NewPartition状态的分区尚未有leader和ISR,因此controller会初始化leader和ISR信息并设置分区状态为OnlinePartition。此时分区开始正常工作。
若用户发起了删除topic操作或关闭broker操作,那么controller会令受影响的分区进入到Offline状态。如果是删除操作,则controller还会开启分区下面副本的删除操作并最终将分区状态设置为NonExistent。而如果是关闭broker操作,则controller会判断该broker是否是分区的leader。如果是则需要开启新一轮的leader选举并调整分区状态回OnlinePartition。
3、Controller职责
对集群状态的维护只是controller保持运行状态一致性的一个基本要素,但却不是controller的职责所在。应该这样说,如果保持controller持续稳定地对外提供服务,就必须要求controller妥善地保存这些状态。实际上,controller的职责相当多,包括如下职责。
- 更新集群元数据信息。
- 创建topice
- 删除topic.
- 分区重分配。
- preferred leader副本选举。
- topic分区扩展。
- broker加入集群。
- broker崩溃。
- 受控关闭。
- controller leader选举。
3.1、更新集群元数据
一个clients能够向集群中任意一台broker发送METADATA请求来查询topic的分区信息(比如topic有多少个分区、每个分区的leader在哪台broker上以及分区的副本列表)。随着
集群的运行,这部分信息可能会发生变化,因此就需要controller提供一种机制,用于随时随地地把变更后的分区信息广播出去,同步给集群上所有的broker。具体做法就是,当有分区信息发生变更时,controller将变更后的信息封装进UpdateMetadataRequests请求(通信协议中的
一种)中,然后发送给集群中的每个broker,这样clients在请求数据时总是能够获取最新、最及时的分区信息。
3.2、创建topic
controller启动时会创建一个ZooKeeper的监听器,该监听器的唯一任务就是监控ZooKeeper节点brokers/topics下子节点的变更情况。当前一个clients或admin创建topic的方
式主要有如下3种。
- 通过kafka-topics脚本的-create创建。
- 构造CreateTopicsRequest请求创建。
- 配置broker端参数auto.create.topics.enable为true,然后发送MetadataRequest请求。
无论上述哪种方式,其基本的原理都是在ZooKeeper的brokers/topics下创建一个对应的znode,然后把这个topic的分区以及对应的副本列表写入这个znode中。之前所说的controller监听器一旦监控到该目录下有新增znode,就立即触发topic创建逻辑,即controller会为新建topic的每个分区确定leader和ISR,然后更新集群的元数据信息。做完这些之后controller还会创建一个新的监听器用于监听ZooKeeper的brokers/topics/<新增topic>节点内容的变更。这样当topic分区发生变化的时候controller也能在第一时间得到通知。
3.3、删除topic
标准的Kafka删除topic方法有如下两种。
- 通过kafka-topics脚本的-delete来删除topic。
- 构造DeleteTopicsRequest.。
这两种方式都是向ZooKeeper的/admin/delete topics下新建一个znode。controller启动时会创建一个监听器专门监听该路径下的子节点变更情况,一旦发现有新增节点,则controller立即开启删除topc的逻辑。该逻辑主要分为两个阶段:①停止所有副本运行;②删除所有副本的日志数据。一旦完成这些操作,controller会移除/admin/delete topics/<待删除topic>节点,这代表topic删除操作正式完成。
3.4、分区重分配
分区重分配操作通常都是由Kafka集群的管理员发起的,旨在对topic的所有分区重新分配副本所在broker的位置,以期望实现更均匀的分配效果。在该操作中管理员需要手动制定分配方案并按照指定的格式写入ZooKeeper的/admin/reassign_partitions节点下。
分区副本重分配的过程实际上是先扩展再收缩的过程。controller首先将分区副本集合进行扩展(I旧副本集合与新副本集合的合集),等待它们全部与leader保持同步之后将leader设置为新分配方案中的副本,最后执行收缩阶段,将分区副本集合缩减成分配方案中的副本集合。
3.5、preferred leader选举
为了避免分区副本分配不均匀,Kafka引入了preferred副本的概念。比如一个分区的副本列表是[l,2,3],那么broker1就被称为该分区的preferred leader,因为它位于副本列表的第一位。在集群运行的过程中,分区的leader因为各种各样的原因会发生变更,从而使得leader不再是preferred leader,此时用户可以发起命令将这些分区的leader重新调整为preferred leader。.具体的方法有如下两种。
- 设置broker端参数auto.leader.rebalance.enable为true,这样controller会定时地自动调整preferred leader。.
- 通过kafka-preferred-replica-election脚本手动触发。
在内部,这两种方法都向ZooKeeper的/admin/preferred replica_election节点写入数据。同样地,controller也会注册监听该目录的监听器。一旦被触发,controller会将对应分区的leader调整回副本列表中的第一个副本,之后将此变更广播出去。
3.6、topic分区扩展
在Kafka集群的运行过程中,用户可能会发现某些topic的现有分区数不足以支撑clients的业务量,因此可能有增加分区的需求。当前增加分区主要使用kafka-topics脚本的-alter选项来完成。和创建topic一样它会向ZooKeeper的brokers/topics//节点下写入新的分区目录。
前面说过,controller在创建topic之后会注册一个新的监听器用于监听分区目录数据的变化。因此一旦增加了topc分区,该监听器会被触发,执行对应的分区创建任务(比如选举leader和ISR等),之后更新集群元数据信息。
3.7、broker加入集群
每个broker成功启动之后都会在ZooKeeper的broker/ids下创建一个znode,并写入broker的信息。如果要让Kafka动态地维护broker列表,就必须注册一个ZooKeeper监听器时刻监控该目录下的数据变化。
每当有新broker加入集群时,该监听器会感知到变化,执行对应的broker启动任务,之后更新集群元数据信息并广而告之。
3.8、broker崩溃
由于当前broker在ZooKeeper中注册的znode是临时节点,因此一旦broker崩溃,broker与ZooKeeper的会话会失效并导致临时节点被删除,故上面监控broker加入的那个监听器同样被用来监控那些因为崩溃而退出集群的broker列表。若发现有broker子目录“消失”,
controller便立即可知该broker退出集群,从而开启broker退出逻辑,最后更新集群元数据并同步到其他broker上。
3.9、受控关闭
“优雅”地关闭broker是指通过kafka-server-stop脚本、kill-9或kil-l5的方式关闭Kafka broker,而broker崩溃或强制退出通常都是以“掉电”或kill-9的方式实现的。前者被称为受控关闭。受控关闭能够最大限度地降低broker的不一致性。与其他controller功能中controller向其他broker发送请求不同的是,受控关闭是由即将关闭的broker向controller发送
请求的。请求的名字是ControlledShutdownRequest。一旦发送完ControlledShutdownRequest,待关闭broker将一直处于阻塞状态,直到接收到broker端发送的ControlledShutdownResponse,表示关闭成功,或用完所有重试机会后强行退出。
controller在处理完必要的leader重选举和ISR收缩调整之后,会给broker发送ControlledShutdownResponse表明该broker现在可以正常退出。
之前所有controller的功能都是依托于ZooKeeper的帮助来实现的,具体来说就是依靠ZooKeeper的监听器功能实现的。但对于受控关闭而言,它依赖于broker端的RPC来实现,即broker直接发送请求给controller,而没有借助ZooKeeper。
3.10、controller leader选举
作为Kafka集群的重要组件,controller必然要支持故障转移(fail-over)。若当前controller发生故障或显式关闭,Kafka必须要能够保证及时选出新的controller。当前,一个
Kafka集群中发生controller leader选举的场景共有如下4种。
- 关闭controller所在broker。
- 当前controller所在broker宕机或崩溃。
- 手动删除ZooKeeper的/controller节点。
- 手动向ZooKeeper的/controller节点写入新的broker id。
在用户没有完全理解controller的选举机制之前,不推荐用户使用后两种操作来触发controller的leader选举。
万变不离其宗的是,这4种操作变更实际上都是/controller节点的内容,因此controller只需要做一件事情:创建一个监听该目录的监听器。/controller本质上是一个临时节点,节点保存了当前controller所在的broker id。集群首次启动时所有broker都会抢着创建该节点,但ZooKeeper保证了最终只能有一个broker胜出一胜出的那个broker即成为controller。
一旦成为controller,它会增加controller的版本号,即更新/controller epoch节点的值,然后履行上面所有的这些职责。对于那些没有成为controller的broker们而言,它们不会甘心失败,而是继续监听controller节点的存活情况并随时准备竞选新的controller。
4、controller与broker间的通信
目前,controller启动时会为集群中所有broker创建一个专属的Socket连接(也包括controller所在的broker)。这就是说,若一个Kafka集群有l00台broker机器,那么controller
会创建l00个Socket连接。虽说当前比较新的Kafka版本已经统一使用基于Java NIO Selector的网络连接库来实现这一功能,但controller依然会为每个TCP连接创建一个
RequestSendThread线程。还是拿刚才的例子进行说明,l00台broker会创建l00个Socket连接和100个I/O线程。
这些连接和线程被用于让controller给集群broker发送请求。在当前的设计下,controller只能给broker发送3种请求,它们分别如下。
UpdateMetadataRequest:之前反复提到的更新集群元数据请求。该请求携带了集群当前最新的元数据信息。接收到该请求后,broker会更新本地内存中的缓存信息,从而保证返还给clients的信息总是最新、最及时的。LeaderAndIsrRequest:用于创建分区、副本,同时完成作为leader和作为follower角色各自的逻辑。StopReplicaRequest:停止指定副本的数据请求操作,另外还负责删除副本数据的功能。
controller通常都是发送请求给broker的,但在controller职责部分中我们提到的ControlledShutdownRequest请求是例外,该请求是待关闭broker通过RPC直接发给controller
的,即请求的流向是反的。另外这个请求还有一个特别之处,controller绝大多数的功能都是依托ZooKeeper来完成的,但只有这个请求是broker与controller直接进行交互完成的。
5、controller组件
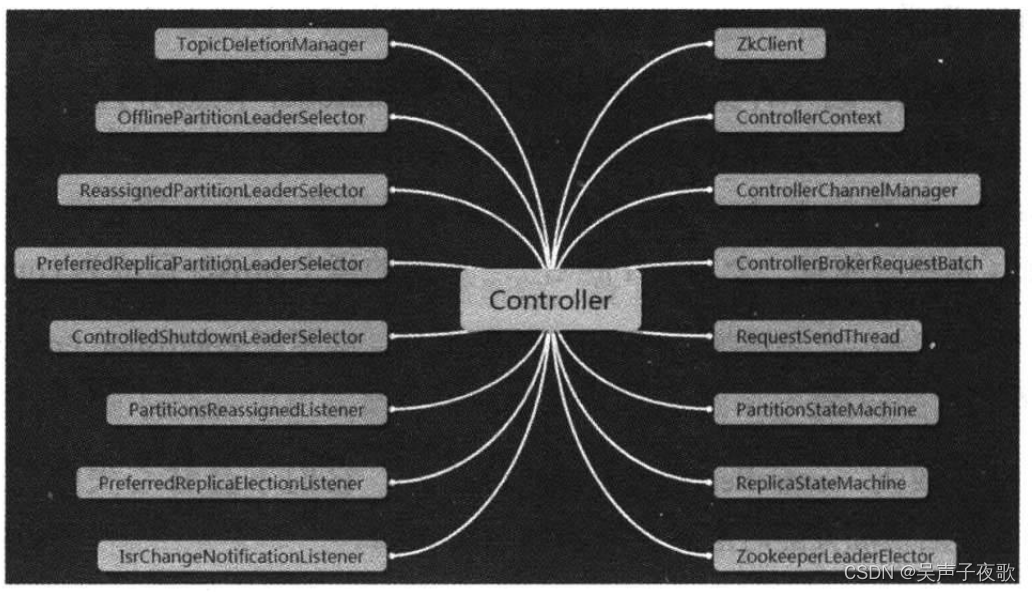
5.1、数据类组件——ControllerContext
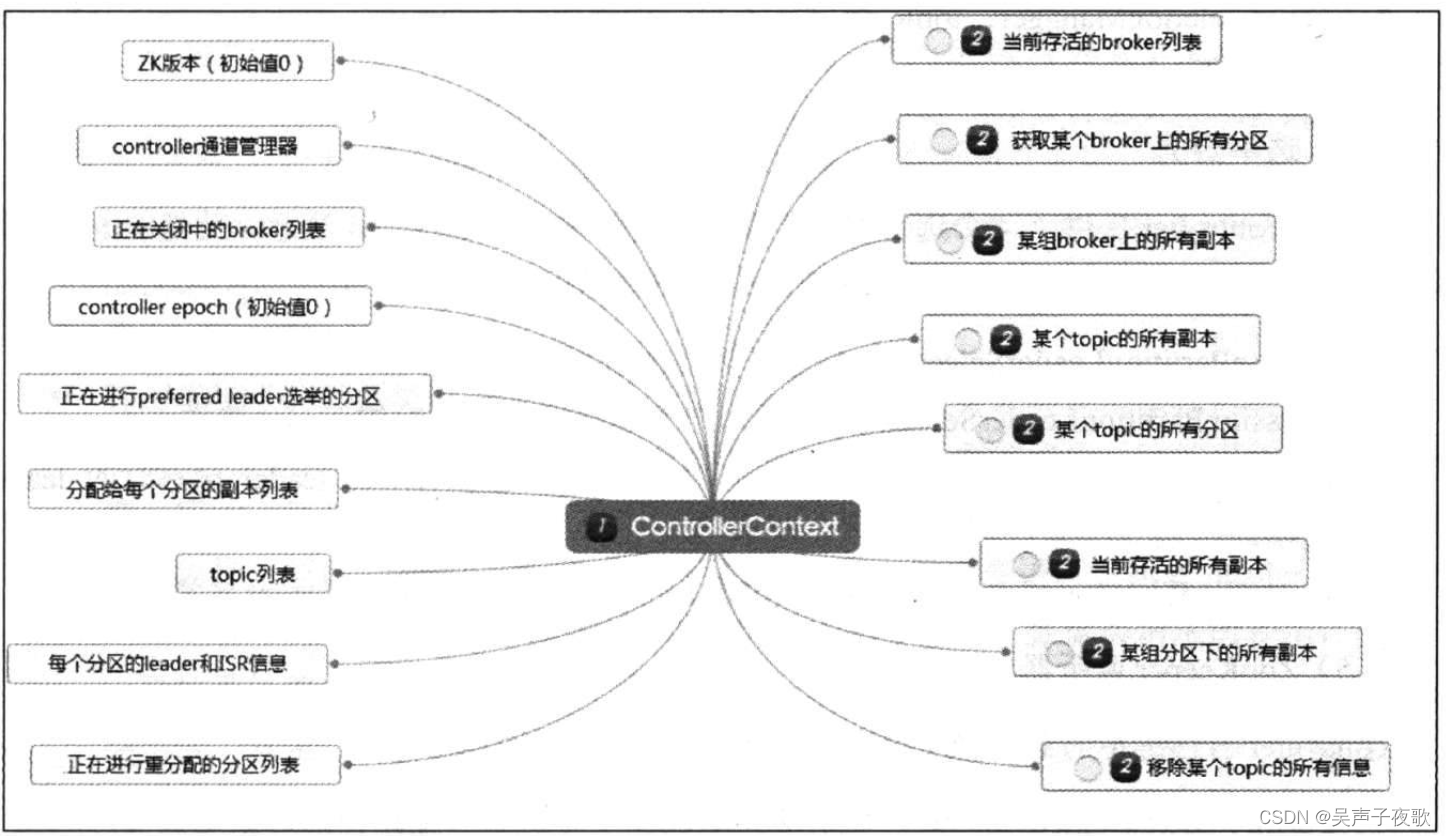
ControllerContext被称为controller上下文或controller缓存,可以说是controller最重要的数据组件了。它汇总了ZooKeeper中关于Kafka集群的所有元数据信息,是controller能够正确提供服务的基础。在0.1l.0.0版本之前,Kafka controller的设计是多线程的,因此保护好这个上下文,使其免受多线程并发修改就成了controller很重要的任务。事实上,0.11.0.0之前的版本中,controller被用户广为诟病的主要原因就是,使用了大量的同步机制来保护这个东西。
ControllerContext里面的内容非常丰富,如图所示。
5.2、基础功能类
ZkClient:封装与ZooKeeper的各种交互API。controller与ZooKeeper的所有操作都交由该组件完成。ControllerChannelManager:前面说过了controller需要向其他broker发送请求,这个通道管理器即负责此事。ControllerBrokerRequestBatch:controller将发往同一broker的各种请求按照类型分组,稍后统一发送以提升效率。此组件就是用来管理请求batch的。RequestSendThread:负责给其他broker发送请求的I/O线程。ZookeeperLeaderElector:结合ZooKeeper负责controller的leader选举。
5.3、状态机类
ReplicaStateMachine:副本状态机,负责定义副本状态以及合法的副本状态流转。PartitionStateMachine:分区状态机,负责定义分区状态以及合法的分区状态流转。TopicDeletionManager:topic删除状态机,处理删除topic的各种状态流转以及相应的状态变更。
5.4、选举器类
当前,controller提供了4个选举器用于各种情况下的leader选举。注意,此处的leader选举是为分区进行leader选举而非选举controller。它们分别如下。
OfflinePartitionLeaderSelector:负责常规性的分区leader选举。ReassignPartitionLeaderSelector:负责用户发起分区重分配时的leader选举。PreferredReplicaPartitionLeaderSelector:负责用户发起preferred leader选举时的leader选举。ControlledShutdownLeaderSelector:负责broker在受控关闭后的leader选举。
5.5、Zookeeper监听器
controller自己维护的监听器实际上只有3个,它们分别如下。
PartitionsReassignedListener:监听ZooKeeper下分区重分配路径的数据变更情况。PreferredReplicaElectionListener:监听ZooKeeper下preferred leader选举路径的数据变更。IsrChangeNotificationListener:监听ZooKeeper下ISR列表变更通知路径下的数据变化。
这里简单解释一下上面最后一个监听器的含义。Kafka一旦发现topic分区的ISR发生了变化,就会在ZooKeeper的/isr change notification节点下写入一个新的数据节点,里面封装了集群中哪些topic的哪些分区对应的IS发生了变更。该监听器监控到节点变化后会发起“更新元数据”请求给集群中的所有broker。
事实上,controller定义的监听器远不止这3个,上面3个监听器只是controller自己维护的。更多的监听器交由各个状态机分别来维护。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
