学习文件系统,我们的目标是如何实现一个简单的文件系统?磁盘上需要什么结构?它们需要记录什么?如何访问?对于这些问题,我们就需要理解文件系统的基本工作原理,可以从以下两个方面着手
- 文件系统的数据结构:文件系统在磁盘上使用哪些类型的结构来组织其数据和元数据?当一个进程打开一个文件时,会发生什么?在读取或写期间会访问哪些磁盘结构?
- 访问方法:如何将进程发出的调用,如open()/write()/read()等,映射到它的结构上?在执行特定系统调用期间读取哪些结构
本章就基于以上的目的,主要学习访问过程中发生具体的细节
1 数据结构
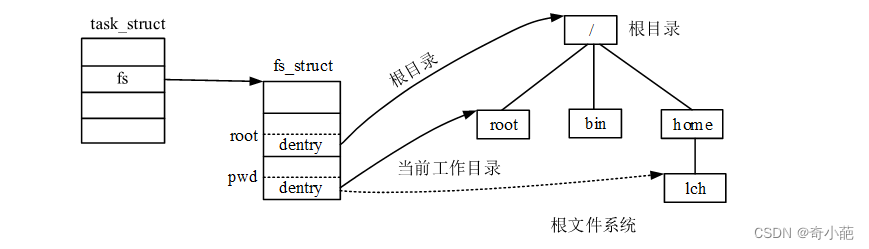
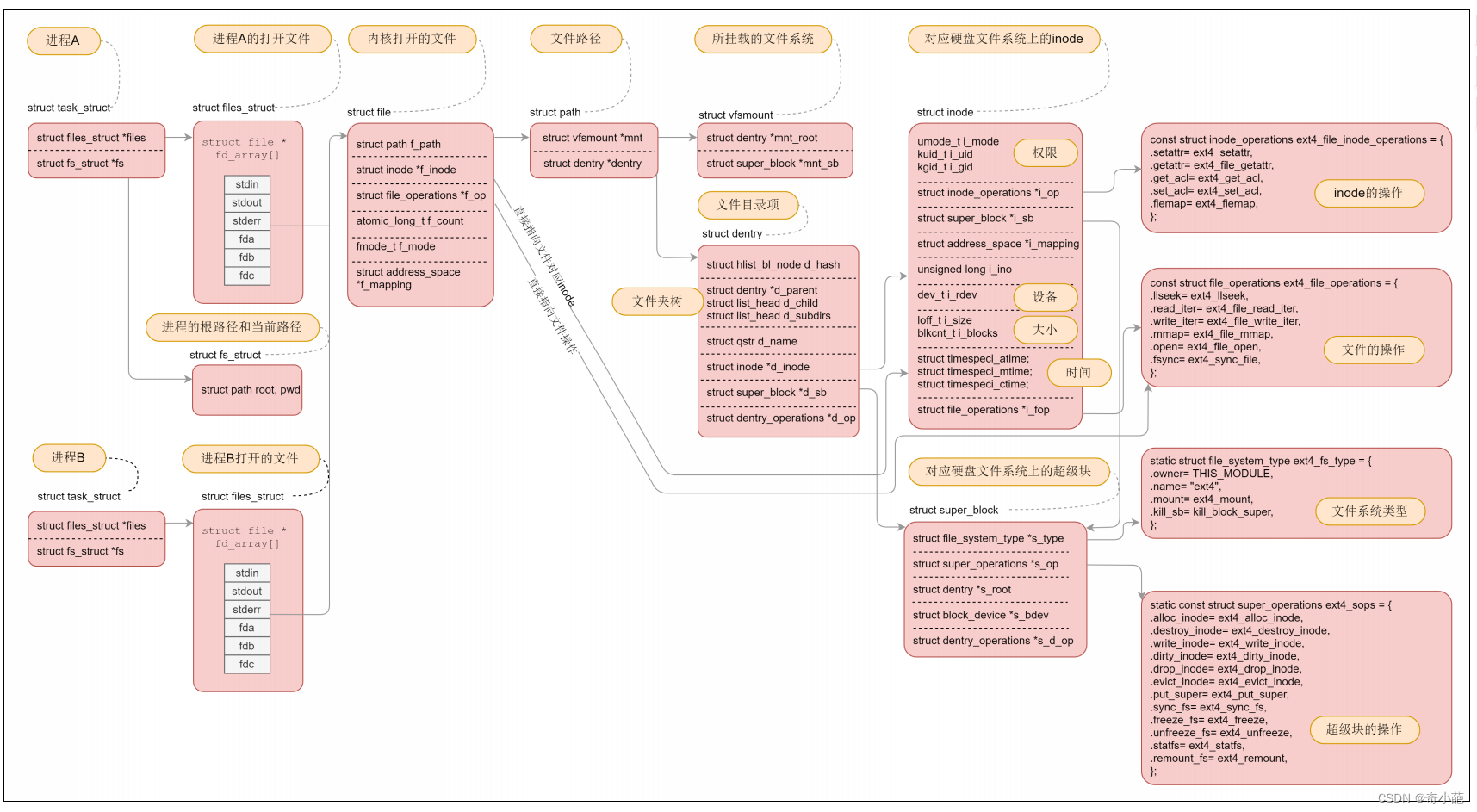
首先,我们通过进程task_struct结构体中fs成员表示了进程可见根文件系统的根节点及当前工作目录:
task_struct{
...
struct fs_struct *fs; /*进程目录信息*/
struct files_struct *files; /*进程打开文件信息*/
...
}
fs_struct结构体定义在/include/linux/fs_struct.h头文件:
struct fs_struct {
int users; /*结构体实例用户数量*/
spinlock_t lock;
seqcount_t seq;
int umask;
int in_exec;
struct path root, pwd; /*进程根目录和当前工作目录*/
};
path结构体实例,结构体定义如下:
struct path {
struct vfsmount *mnt; /*目录项所在文件系统挂载信息,vfsmount.mnt*/
struct dentry *dentry; /*目录项指针*/
};
- root成员表示进程访问内核根文件系统,通常为根文件系统的根节点,但也可以通过chroot()系统调用修改进程根目录。进程以绝对路径搜索文件时,从进程根目录开始。
- pwd成员表示进程当前工作目录。进程以相对路径访问文件时,将会从当前工作目录开始查找。chdir()系统调用用于改变进程当前工作目录。在前面介绍的VFS初始化中,将创建内核根文件系统,并设置内核线程的根目录、当前工作目录为根文件系统根目录
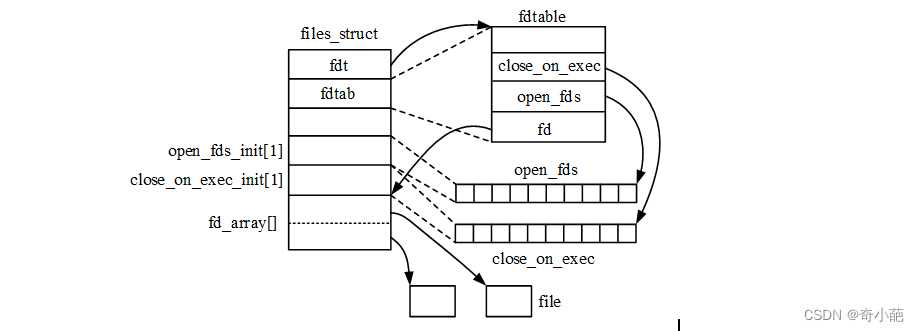
files成员指向files_struct结构体实例,结构体定义在include/linux/fdtable.h头文件:
struct files_struct {
/*
* read mostly part
*/
atomic_t count; /*实例引用计数*/
bool resize_in_progress;
wait_queue_head_t resize_wait; /*进程等待队列*/
struct fdtable __rcu *fdt; /*fdtable结构体指针,初始值指向fdtab成员*/
struct fdtable fdtab; /*fdtable结构体成员*/
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
/*下一个打开文件的文件描述符,初始值为0,每次分配描述符后设置*/
unsigned int next_fd;
/*执行execve()系统调用时关闭文件的位图*/
unsigned long close_on_exec_init[1];
/*打开文件位图*/
unsigned long open_fds_init[1];
unsigned long full_fds_bits_init[1];
/*打开文件file指针数组*/
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
files_struct结构体主要成员简介如下:
- **open_fds_init[1]:**进程打开文件位图,与打开文件file指针数组对应,每个比特位对应数组项是否为空,1表示数组项关联了file实例
- **fdt:**fdtable结构体指针,初始值指向fdtab成员
- fd_array[] :file指针数组,数组项指向file实例,指针数组项索引为文件描述符,无符号整数。数组项数NR_OPEN_DEFAULT与整型数比特位数相同。
- **fdtab:**fdtable结构体成员,用于管理文件位图,其定义如下(include/linux/fdtable.h)
struct fdtable {
unsigned int max_fds; /*fdtable能管理的打开文件最大数量,由位图大小决定*/
struct file __rcu **fd; /*指向file指针数组的指针*/
unsigned long *close_on_exec; /*执行execve()系统调用时关闭文件的位图*/
unsigned long *open_fds; /*进程打开文件位图*/
unsigned long *full_fds_bits;
struct rcu_head rcu;
};
文件位图就是file指针数组对应的位图,每位对应指针数组中一项,比特位位置就是数组项索引,即文件描述符
进程打开的文件由file结构体表示,结构体定义在include/linux/fs.h头文件:
struct file {
union {
struct llist_node fu_llist; /*单链表成员*/
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path; /*文件路径信息*/
struct inode *f_inode; /*指向内核文件inode实例*/
const struct file_operations *f_op; /*文件操作结构指针,通常在打开文件时设为inode->i_fop*/
/*
* Protects f_ep_links, f_flags.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock;
atomic_long_t f_count;
unsigned int f_flags; /*系统调用传递的flags标记参数*/
fmode_t f_mode; /*标记进程以何种模式打开文件*/
struct mutex f_pos_lock;
loff_t f_pos; /*文件当前读写位置,相对于文件开头处的字节偏移量*/
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
u64 f_version;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
/* needed for tty driver, and maybe others */
void *private_data; /*文件私有数据指针,例如设备文件指向驱动程序定义的数据结构*/
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
struct list_head f_tfile_llink;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping; /*文件地址空间指针 */
} __attribute__((aligned(4)));
2 系统调用
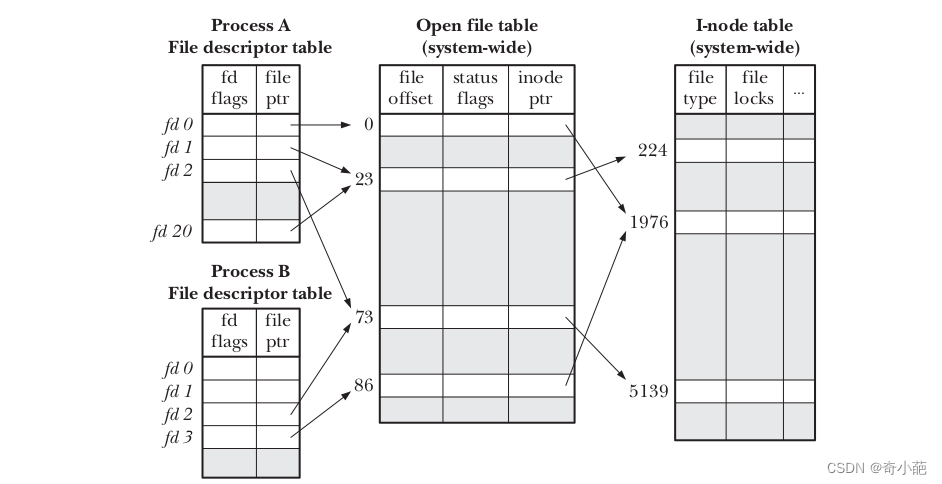
透過 open(), read(), write() 等函都是以 file descriptor 为对象。而实际上这件事牵扯到 3 个面向:
-
每个进程自己看到的 file descriptor
-
open file table
-
inode:那個「檔案」真正的 inode
2.1 open
open负责在内核生成与文件相对应的struct file元数据结构,并且与文件系统中该文件的struct inode进行关联,装载对应文件系统的操作回调函数,然后返回一个int fd给用户进程。后续用户对该文件的相关操作,会涉及到其相关的struct file、struct inode、inode->i_op、inode->i_fop和inode->i_mapping->a_ops等。
在读写文件之前,我们必须打开文件,从应用程序的角度来看,这是通过标准库的open函数来完成的,该函数返回一个文件描述符,会调用fs/open.c中的sys_open函数,代码流程如下所示:

- PathWalk找到目标文件
- 构造并初始化inode
- 构造并初始化file
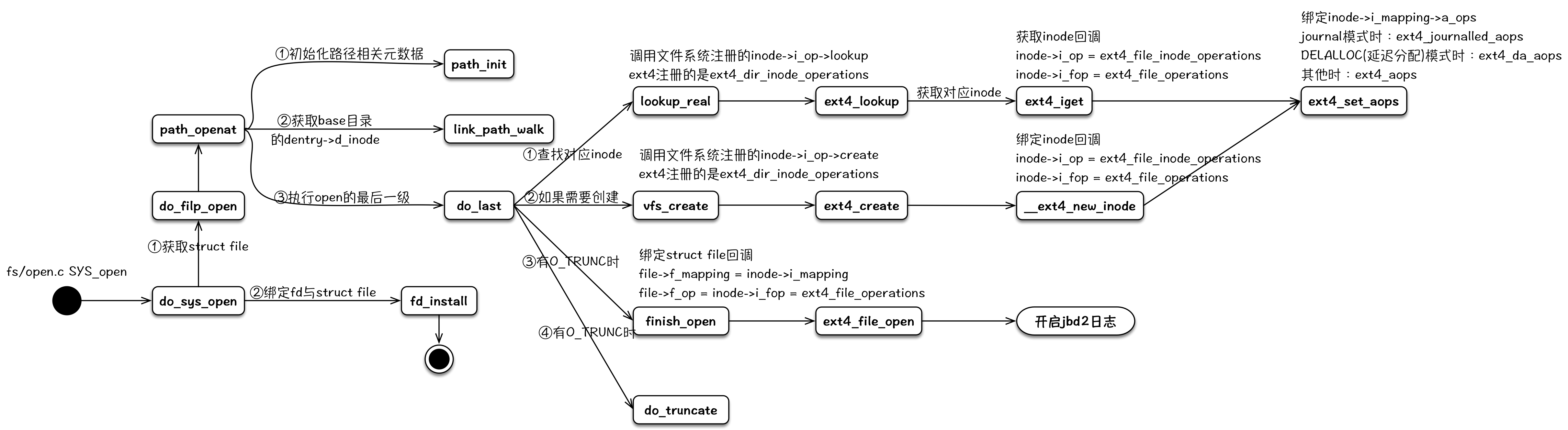
do_filp_open()函数要完成打开文件操作最重要、最繁重的工作,函数内需要创建文件file实例,遍历文件路径中每个分量,在内核根文件系统中搜索/创建对应的dentry和inode结构体实例,当到达最末尾分量时(文件名称),将其inode实例(文件inode)与file实例建立关联。因此,do_filp_open()函数执行的主要工作可概括为从路径到节点,即由文件路径确定文件inode实例,赋予file实例
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op)
{
struct nameidata nd; /*nameidata实例*/
int flags = op->lookup_flags;
struct file *filp;
set_nameidata(&nd, dfd, pathname); /*设置nameidata实例*/
/* 创建file实例,依次查找各路径分量,默认设置LOOKUP_RCU标记 */
filp = path_openat(&nd, op, flags | LOOKUP_RCU);
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(&nd, op, flags);
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(&nd, op, flags | LOOKUP_REVAL);
/*释放处理符号链接中分配的save[]数组*/
restore_nameidata();
/*返回file实例指针*/
return filp;
}
- 定义了nameidata结构体实例nd,用于暂存目录项查找中间结果,并调用函数set_nameidata()设置nd实例
- 主要工作交给 path_openat (&nd, op, flags | LOOKUP_RCU)函数完成
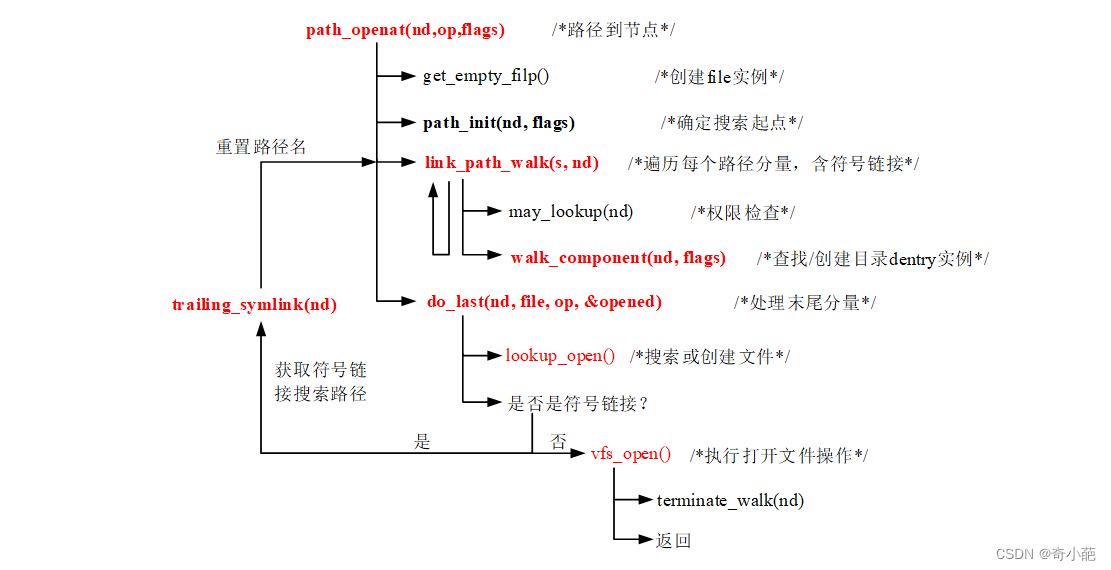
****path_openat()函数在/fs/namei.c文件内实现,代码如下:
static struct file *path_openat(struct nameidata *nd,
const struct open_flags *op, unsigned flags)
{
const char *s;
struct file *file;
int opened = 0;
int error;
file = get_empty_filp(); //从slab缓存中分配file实例并初始化
if (IS_ERR(file))
return file;
file->f_flags = op->open_flag; //系统调用flags参数传递的打开文件标记
if (unlikely(file->f_flags & __O_TMPFILE)) {
error = do_tmpfile(nd, flags, op, file, &opened);
goto out2;
}
if (unlikely(file->f_flags & O_PATH)) {
error = do_o_path(nd, flags, file);
if (!error)
opened |= FILE_OPENED;
goto out2;
}
s = path_init(nd, flags); //确定查找起点,s指向路径名称字符串
if (IS_ERR(s)) {
put_filp(file);
return ERR_CAST(s);
}
/*遍历每个路径分量,创建(查找)dentry和inode实例*/
while (!(error = link_path_walk(s, nd)) &&
(error = do_last(nd, file, op, &opened)) > 0) {
nd->flags &= ~(LOOKUP_OPEN|LOOKUP_CREATE|LOOKUP_EXCL);
/* 获取最末尾路径分量符号链接路径 */
s = trailing_symlink(nd);
if (IS_ERR(s)) {
error = PTR_ERR(s);
break;
}
}
terminate_walk(nd);
out2:
if (!(opened & FILE_OPENED)) {
BUG_ON(!error);
put_filp(file);
}
if (unlikely(error)) {
if (error == -EOPENSTALE) {
if (flags & LOOKUP_RCU)
error = -ECHILD;
else
error = -ESTALE;
}
file = ERR_PTR(error);
}
return file; //成功返回file实例指针
}
path_openat()函数调用关系如下图所示:
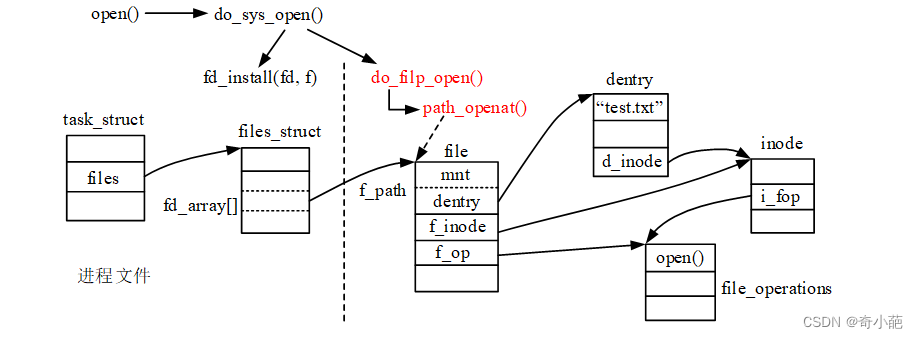
所以do_sys_open()函数首先将系统调用flags、mode参数转换成open_flags实例,将文件路径名称参数转换成filename实例,这两个转换而得的实例将作为后面调用do_filp_open()函数的参数;调用函数get_unused_fd_flags()获取进程最小未使用文件描述符;调用**do_filp_open()**函数创建文件file实例,依次搜索/创建各路径分量(目录)对应的dentry和inode实例,将最后分量dentry、inode及file_operations实例赋予file实例;最后调用fd_install()函数建立进程file指针数组项与file实例之间的关联。
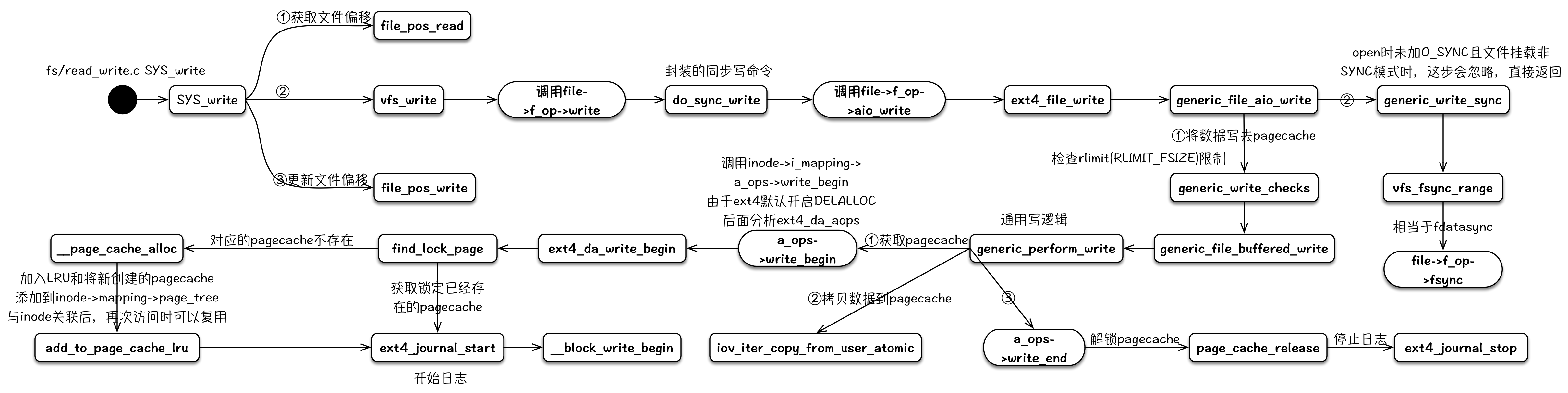
2.2 write
用户进程写文件内容操作的系统调用为write(),其实现与读操作非常相似,系统调用定义如下:
_vfs_write()函数内优先调用file->f_op->write()函数执行写文件操作,如果没有定义此函数则调用通用的同步写函数**new_sync_write()**完成写操作。同步写操作通常是先将数据写入文件内容缓存,然后在适当的时候同步(写入)到介质文件系统
2.3 read
read的读逻辑中包含预期readahead的逻辑,其可以通过与fadvise的配合达到文件预取的效果。用户进程读文件内容的read()系统调用定义如下(/fs/read_write.c):
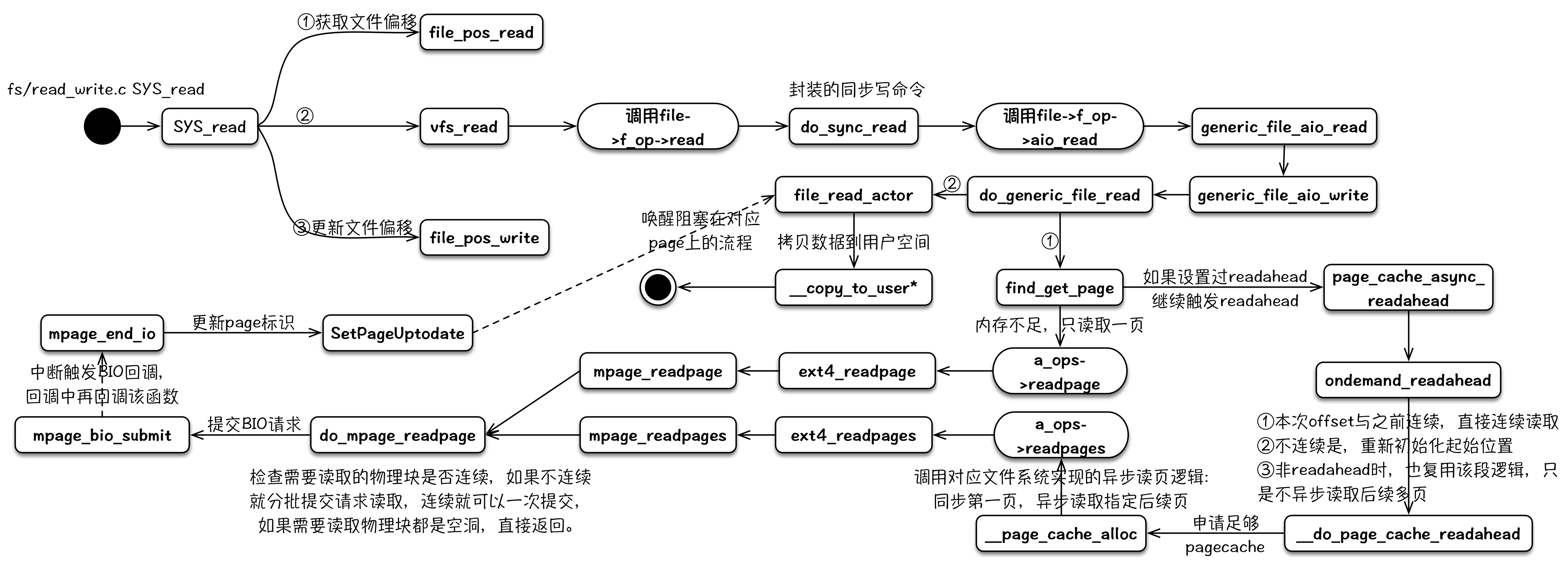
3 总结
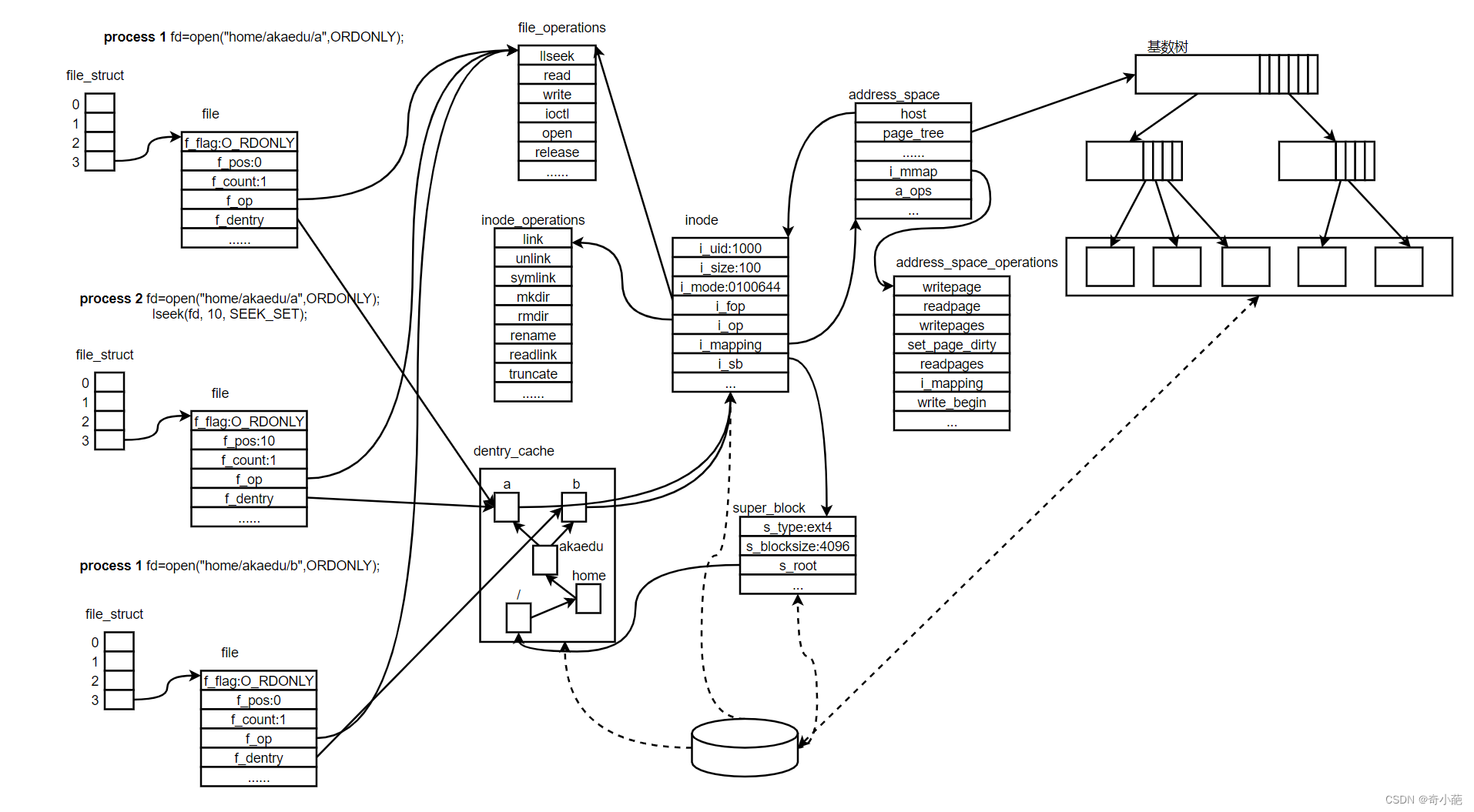
- 进程1和进程2都打开同一文件,但是对应不同的file 结构体,因此可以有不同的File Status Flag和读写位置。file 结构体中比较重要的成员还有f_count,表示引用计数(Reference Count),如dup 、fork 等系统调用会导致多个文件描述符指向同一 个file 结构体,例如有fd1 和fd2 都引用同一个file 结构体,那么它的引用计数就是2,,当close(fd1) 时并不会释放file 结构体,而只是把引用计数减到1,如果再close(fd2) ,引用计数 就会减到0同时释放file 结构体,这才真的关闭了文件。
- 每个file 结构体都有一个指向dentry结构体的指针,“dentry”是directory entry(目录项)的缩写。 我们传给open 、stat 等函数的参数的是一个路径,如/home/akaedu/a ,需要根据路径找到文件 的inode。为了减少读盘次数,内核缓存了目录的树状结构,称为dentry cache,其中每个节点是一 个dentry结构体,只要沿着路径各部分的dentry搜索即可,从根目录/找到home 目录,然后找 到akaedu目录,然后找到文件a。dentry cache只保存最近访问过的目录项,如果要找的目录项 在cache中没有,就要从磁盘读到内存中。
- 每个dentry结构体都有一个指针指向inode 结构体。inode 结构体保存着从磁盘inode读上来的信 息。在上图的例子中,有两个dentry,分别表示/home/akaedu/a 和/home/akaedu/b ,它们都指向同 一个inode,说明这两个文件互为硬链接。inode 结构体中保存着从磁盘分区的inode读上来信息,,例如所有者、文件大小、文件类型和权限位等。每个inode 结构体都有一个指向inode_operations结 构体的指针,后者也是一组函数指针指向一些完成文件目录操作的内核函数。
- 和file_operations 不同,inode_operations所指向的不是针对某一个文件进行操作的函数,而是影响文件和目录布局的函数,例如添加删除文件和目录、跟踪符号链接等等,属于同一文件系统的 各inode 结构体可以指向同一个inode_operations结构体。 inode 结构体有一个指向super_block结构体的指针。super_block结构体保存着从磁盘分区的超级块 读上来的信息,例如文件系统类型、块大小等。super_block结构体的s_root成员是一个指 向dentry的指针,表示这个文件系统的根目录被mount 到哪里,在上图的例子中这个分区 被mount 到/home 目录下。
- address_space结构体,一个address_space管理了一个文件在内存中缓存的所有pages。address_space 结构其中的一个作用就是用于存储文件的 页缓存,一个inode对应一个page cache对象,一个page cache对象包含多个物理page。详细的可以参考Linux内核学习笔记(八)Page Cache与Page回写
host:指向当前 address_space 对象所属的文件 inode 对象(每个文件都使用一个 inode 对象表示)。
page_tree:用于存储当前文件的 页缓存。
tree_lock:用于防止并发访问 page_tree 导致的资源竞争问题。
其对应详细的数据结构如下图所示
4 参考文档
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
