上一章学习了伙伴系统的设计思路和其申请和释放API的使用方式,本章主要是梳理下伙伴系统分配是如何分配出连续的物理页面的。内核中常用的分配物理内存页面的接口是alloc_pages,用于分配一个或者多个连续的物理页面,分配的页面个数只能是2^n。相对于多次离散的物理页面,分配连续的物理页面有利于提高系统内存的碎片化。
1. 页的分配
对于所有的内存分配接口,最后都会调用alloc_pages_node,这个是伙伴系统最重要的接口,其定义如下:
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask,
unsigned int order)
{
if (nid == NUMA_NO_NODE)
nid = numa_mem_id();
return __alloc_pages_node(nid, gfp_mask, order);
}
这个函数只是执行了一个简单的检查,防止申请的过大的内存。如果指定节点不存在,内核自动使用当前执行CPU对应的节点ID,最终调用__alloc_pages_nodemask,这个函数使伙伴系统的核心函数,下面来看看这个函数处理流程,
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW;
gfp_t alloc_mask = gfp_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = {
.high_zoneidx = gfp_zone(gfp_mask),
.zonelist = zonelist,
.nodemask = nodemask,
.migratetype = gfpflags_to_migratetype(gfp_mask),
};
...
}
struct alloc_context数据结构是伙伴系统分配函数中用于保存相关参数的数据结构,对于该结构gfp_zone()函数从分配掩码中计算出zone的zoneidx,并放到high_zoneidx成员中。
static inline enum zone_type gfp_zone(gfp_t flags)
{
enum zone_type z;
int bit = (__force int) (flags & GFP_ZONEMASK);
z = (GFP_ZONE_TABLE >> (bit * GFP_ZONES_SHIFT)) &
((1 << GFP_ZONES_SHIFT) - 1);
VM_BUG_ON((GFP_ZONE_BAD >> bit) & 1);
return z;
}
首先flags&GFP_ZONEMASK,是将与GFP_XXX无关的其他位清零, 内核通过标志判断从哪个zone分配内存。而对于该结构体中,通过gfpflags_to_migratetype函数将gpf_mask分配掩码转换成MIGRATE_TYPES类型,例如分配的掩码为GFP_KERNEL,那么其类型为MIGRATE_UNMOVABLE;如果分配的掩码为GFP_HIGHUSER_MOVABLE,那么类型就是MIGRATE_MOVABLE,其定义为
static inline int gfpflags_to_migratetype(const gfp_t gfp_flags)
{
VM_WARN_ON((gfp_flags & GFP_MOVABLE_MASK) == GFP_MOVABLE_MASK);
BUILD_BUG_ON((1UL << GFP_MOVABLE_SHIFT) != ___GFP_MOVABLE);
BUILD_BUG_ON((___GFP_MOVABLE >> GFP_MOVABLE_SHIFT) != MIGRATE_MOVABLE);
if (unlikely(page_group_by_mobility_disabled))
return MIGRATE_UNMOVABLE;
/* Group based on mobility */
return (gfp_flags & GFP_MOVABLE_MASK) >> GFP_MOVABLE_SHIFT;
}
然后进入到should_fail_alloc_page函数,检查内存分配是否可行,如果不可行就直接返回,即以失败告终,否则就继续执行内存分配,之后就是一些判断条件,然后进入到真正尝试分配物理页面,其处理流程如下:
* may get reset for allocations that ignore memory policies.
*/
ac.preferred_zoneref = first_zones_zonelist(ac.zonelist,
ac.high_zoneidx, ac.nodemask);
if (!ac.preferred_zoneref->zone) {
page = NULL;
/*
* This might be due to race with cpuset_current_mems_allowed
* update, so make sure we retry with original nodemask in the
* slow path.
*/
goto no_zone;
}
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
首先通过first_zones_zonelist()从给定的zoneidx开始查找,这个给定的zoneidx就是highidx,之前通过gfp_zone()函数转换得来的。
static inline struct zoneref *first_zones_zonelist(struct zonelist *zonelist,
enum zone_type highest_zoneidx,
nodemask_t *nodes)
{
return next_zones_zonelist(zonelist->_zonerefs,
highest_zoneidx, nodes);
}
first_zones_zonelist()函数会调用next_zones_zonelist()函数来计算zoneref,最后返回zone数据结构
struct zoneref *__next_zones_zonelist(struct zoneref *z,
enum zone_type highest_zoneidx,
nodemask_t *nodes)
{
/*
* Find the next suitable zone to use for the allocation.
* Only filter based on nodemask if it's set
*/
if (likely(nodes == NULL))
while (zonelist_zone_idx(z) > highest_zoneidx)
z++;
else
while (zonelist_zone_idx(z) > highest_zoneidx ||
(z->zone && !zref_in_nodemask(z, nodes)))
z++;
return z;
该函数提供3个参数,对于处理如下
- highest_zoneidx是gfp_zone()函数计算分配掩码得来
- z是通过node_zonelist,主要是node_zonelists,zone在系统处理时会初始化这个数组,具体函数在
build_zonelists_node()中, 分配物理页面时会优先考虑ZONE_HIGHMEM,因为ZONE_HIGHMEM在zonelist中排在ZONE_NORMAL前面 ; - nodes,一般为NULL
如果我们分配gfp_zone(GFP_KERNEL)函数返回0,那么highest_zoneidx为0,而这个节点在内存第按高到低排列,那么第一个zone是ZONE_HIGHMEM,其zone编号zone_index的值为1,因此最终next_zones_zonelist中,z++,那么返回的是ZONE_NORMAL;而如果分配的时gfp_zone(GFP_HIGHUSER_MOVABLE),那么这个highest_zoneidx返回的时2,所以zone_index的值小于highest_zoneidx,那么就直接返回ZONE_HIGHMEM。
/* First allocation attempt */
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
no_zone:
/*
* Runtime PM, block IO and its error handling path can deadlock
* because I/O on the device might not complete.
*/
alloc_mask = memalloc_noio_flags(gfp_mask);
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
if (unlikely(ac.nodemask != nodemask))
ac.nodemask = nodemask;
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
- 首先
get_page_from_freelist()会去尝试分配物理页面,这里是快速分配,是以alloc_flags = ALLOC_WMARK_LOW为参数,以low为标准,遍历zonelist,尝试获取2^order个连续的页框,在遍历zone时,如果zone的当前空闲内存减去需要申请的内存之后,空闲内存是低于low阀值,那么此zone会进行快速内存回收 - 如果这里分配失败,就会调用到
__alloc_pages_slowpath()函数,这里是慢速分配,并且同样分配时不允许进行IO操作 ,这个函数会尝试唤醒页框回收线程,后面会详细分析。
2. Alloc fast path
首先我们来看看快速分配get_page_from_freelist()接口函数,其主要流程如下
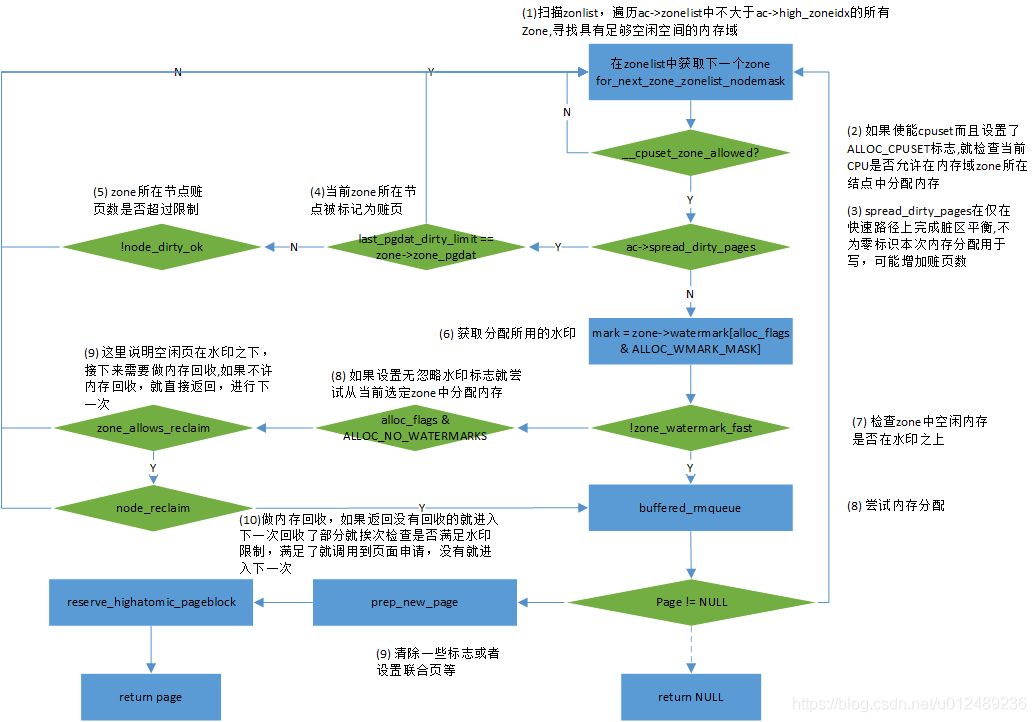
从流程中,当判断当前的zone空闲页面低于WMARK_LOW水位后,会调用node_reclaim函数进行页面回收;而当空闲页面充足时候,会调用buffered_rmqueue函数从伙伴系统中分配物理页面
static inline
struct page *buffered_rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
unsigned long flags;
struct page *page;
bool cold = ((gfp_flags & __GFP_COLD) != 0);
if (likely(order == 0)) { ------------------(1)
struct per_cpu_pages *pcp;
struct list_head *list;
local_irq_save(flags);//禁止本地CPU中断,禁止前先保存中断状态
do {
pcp = &this_cpu_ptr(zone->pageset)->pcp; //获取此zone的每CPU高速缓存
list = &pcp->lists[migratetype];//根据迁移类型,得到高速缓存区的freelist
if (list_empty(list)) {//高速缓存没有数据;这可能是上次获取的cpu高速缓存迁移
pcp->count += rmqueue_bulk(zone, 0,
pcp->batch, list,
migratetype, cold);//从伙伴系统中获取batch个页框加入到这个链表中
if (unlikely(list_empty(list)))
goto failed;
}
if (cold)//需要冷的高速缓存,则从每CPU高速缓存的双向链表的后面开始分配
page = list_last_entry(list, struct page, lru);
else//需要热的高速缓存,则从每CPU高速缓存的双向链表的前面开始分配,
page = list_first_entry(list, struct page, lru);
list_del(&page->lru);//从每CPU高速缓存链表中拿出来
pcp->count--;
} while (check_new_pcp(page));
} else { ------------------(2)
/*
* We most definitely don't want callers attempting to
* allocate greater than order-1 page units with __GFP_NOFAIL.
*/
//申请多个页框时是有可能会发生失败的情况的,而分配时又表明__GFP_NOFAIL不允许发生失败
WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));
spin_lock_irqsave(&zone->lock, flags);
do {
page = NULL;
if (alloc_flags & ALLOC_HARDER) {//放宽限制,即如果当前阶无可用内存时,可以向分配更高阶的内存区
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (page)
trace_mm_page_alloc_zone_locked(page, order, migratetype);
}
if (!page)//从伙伴系统中获取连续页框,返回第一个页的页描述符
page = __rmqueue(zone, order, migratetype);
} while (page && check_new_pages(page, order));
spin_unlock(&zone->lock);
if (!page)
goto failed;
__mod_zone_freepage_state(zone, -(1 << order),
get_pcppage_migratetype(page));//统计,减少zone的free_pages数量统计,因为里面使用加法,所以这里传进负数
}
__count_zid_vm_events(PGALLOC, page_zonenum(page), 1 << order); ------------------(3)
zone_statistics(preferred_zone, zone, gfp_flags);
local_irq_restore(flags);
VM_BUG_ON_PAGE(bad_range(zone, page), page);
return page;
failed:
local_irq_restore(flags);
return NULL;
}
这里根据order数值分为两种情况,一种情况是order等于0的情况,也就是分配一个物理页面。直接从zone->per_cpu_pageset列表中分配;另外一种情况是order大于0的情况,就从伙伴系统中分配。
- 1.分配的页面数为1,那么就不需要从buddy系统中获取,因为per-cpu的页缓存提供了一种更快分配和释放的机制。在伙伴系统中每个CPU都对应高速缓存,里面保持着migratetype分类的单页框的双向链表,当申请内存只需要一个页框时,内核从CPU的高速缓存中相应类型的单页框链表中获取一个页框交给申请者,这样好处是,释放单个页框时会放入CPU高速缓存链表,这样的页框就称为热页。
- 2.需要多个页框,从伙伴系统中分配,如果分配标志位中设置了ALLOC_HARDER,则从
free_list[MIGRATE_HIGHATOMIC]的链表中进行页面分配,分配成功则返回;前两个条件都不满足,则在正常的free_list[MIGRATE_*]中进行分配,分配成功则直接则返回

内核经常请求和释放单个页框,为了提升系统性能,每个内存管理区定义了一个"每CPUI"页框的高速缓存,所有“每CPU”高速缓存包含了一些预先分配的页框,它们被用于满足本地CPU发出的单一内存请求。
为每个内存管理区和每CPU提供两个高速缓存,在内存管理区中,分配单页使用per-cpu机制,分配多页使用伙伴算法
热高速缓存,它存放页框中所包含的内容很可能就在CPU硬件高速缓存中
冷高速缓存
zone结构体中pageset成员指向内存域per-CPU管理结构
struct zone { ... #ifdef CONFIG_NUMA //若定义了CONFIG_NUMA宏,pageset为二级指针,否则为数组 struct per_cpu_pageset *pageset[NR_CPUS]; #else struct per_cpu_pageset pageset[NR_CPUS]; #endif ... }
static struct page *__rmqueue(struct zone *zone, unsigned int order,
int migratetype)
{
struct page *page;
page = __rmqueue_smallest(zone, order, migratetype);//直接从migratetype类型的链表中获取了2的order次方个页框
if (unlikely(!page)) {// 如果page为空,没有在需要的migratetype类型中分配获得页框,说明当前需求类型(migratetype)的页框没有空闲
if (migratetype == MIGRATE_MOVABLE)
page = __rmqueue_cma_fallback(zone, order);//从CMA中获取内存
if (!page)
page = __rmqueue_fallback(zone, order, migratetype);//根据fallbacks数组从其他migratetype类型的链表中获取内存
}
trace_mm_page_alloc_zone_locked(page, order, migratetype);
return page;
}
根据传递的分配阶、用于获取页的内存域、迁移类型,__rmqueue_smallest扫描页的列表,直至找到适当的连续内存块。如果指定的迁移列表不能满足分配请求,就会看migratetype类型是MIGRATE_MOVABLE,就首先从CMA中分配;如果分配失败,则调用 _ _rmqueue_fallback尝试其他的迁移列表,作为应急措施。
__rmqueue_smallest本质上,由一个循环组成,按照递增顺序遍历内存域的各个特定迁移类型的空闲页列表,直至找到合适的一项为止。
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/// 循环遍历这层之后的空闲链表
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
if (!page)//获取空闲链表中第一个结点所代表的连续页框
continue;
list_del(&page->lru);//将页框从空闲链表中删除
rmv_page_order(page);//将首页框的private设置为0
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);//将current_order阶的页拆分成小块并重新放到对应的链表中去
set_pcppage_migratetype(page, migratetype);//设置页框的类型与migratetype一致
return page;
}
return NULL;
}
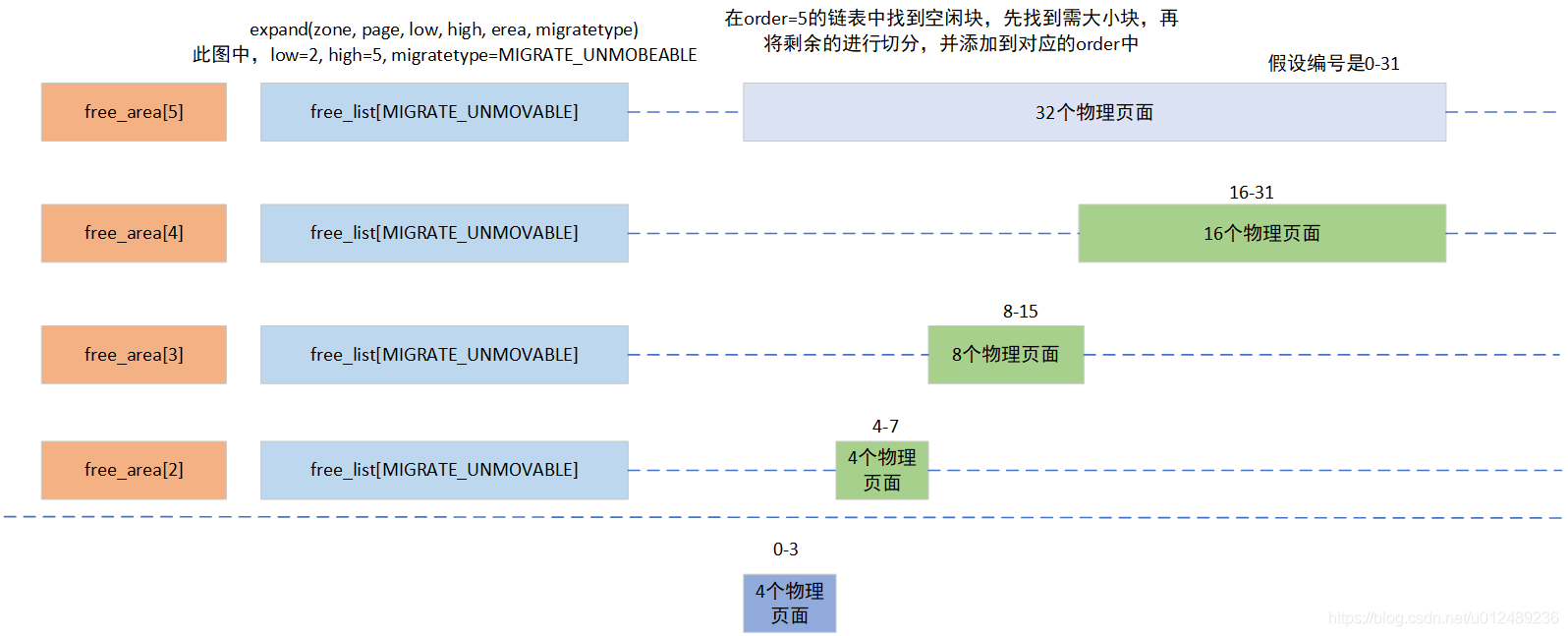
__rmqueue_smallest()函数中只会对migratetype类型的链表进行操作,并且会从需要的order值开始向上遍历,直到成功分配连续页框或者无法分配连续页框为止,比如order为8,页就是需要连续的256个页框,那么尝试从order为8的空闲页框链表中申请内存,如果失败,order就会变成9,从连续512个页框的空闲页框块链表中尝试分配,如果还是失败,就以此寻找和尝试分配…当分配到内存的order与最初的order不相等,比如最初传入的值是8,而成功分配是10,那么就会连续页框进行拆分,这时候就会拆分为256、256、512这三块连续页框,并把512放入order为9的free_list,把一个256放入order为8的free_list,剩余一个256用于分配。
如果需要分配的内存块长度小于所选择的连续页范围,即如果因为没有更小的适当内存块可用,而从较高的分配阶分配一块内存,那么该内存块必须按照伙伴系统的原理分裂成小的块,其过程主要是在expand中实现
static inline void expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area,
int migratetype)
{
unsigned long size = 1 << high;
//如果high大于 low说明在需要拆分高阶页块来满足本次内存分配
while (high > low) {//循环拆分大页块直到与low一样大
area--;
high--;
size >>= 1;
VM_BUG_ON_PAGE(bad_range(zone, &page[size]), &page[size]);
/*
* Mark as guard pages (or page), that will allow to
* merge back to allocator when buddy will be freed.
* Corresponding page table entries will not be touched,
* pages will stay not present in virtual address space
*/
if (set_page_guard(zone, &page[size], high, migratetype))
continue;
//将大块拆分成两块,将后半块重新放到伙伴系统中
list_add(&page[size].lru, &area->free_list[migratetype]);
area->nr_free++;//增加统计计数
set_page_order(&page[size], high);//设置页块阶数
}
}
当在大的order链表中申请到了内存后,剩余部分会插入到其他的order链表中,实例如下:
如果在特定的迁移类型列表上没有连续内存区可用,则__rmqueue_smallest返回NULL指针,说明zone的mirgratetype类型的连续页框不足以分配本次1 << order个连续页框。内核接下来根据备用次序,尝试使用其他迁移类型的列表满足分配请求,那么就会调用_ _rmqueue_fallback()进行分配,在__rmqueue_fallback()函数中,主要根据fallbacks表,尝试将其他migratetype类型的pageblock中的空闲页移动到目标类型的mirgratetype类型的空闲页框块链表中
static inline struct page *
__rmqueue_fallback(struct zone *zone, unsigned int order, int start_migratetype)
{
struct free_area *area;
unsigned int current_order;
struct page *page;
int fallback_mt;
bool can_steal;
//这是和指定迁移类型的遍历不一样,这里是从最大阶开始遍历,找到最大可能的内存块,就是为了防止内存碎片
for (current_order = MAX_ORDER-1;
current_order >= order && current_order <= MAX_ORDER-1;
--current_order) {
area = &(zone->free_area[current_order]);//得到高阶空闲数组元素
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);//检查是否有合适的fallback空闲页框
if (fallback_mt == -1)//如果没有找到适合就查找下一个order
continue;
page = list_first_entry(&area->free_list[fallback_mt],
struct page, lru);
if (can_steal)//调用steal_suitable_fallback进行真正的page的迁移
steal_suitable_fallback(zone, page, start_migratetype);
/* Remove the page from the freelists */
area->nr_free--;
list_del(&page->lru);
rmv_page_order(page);//设置page->_mapcount = -1 并且 page->private = 0
expand(zone, page, order, current_order, area,
start_migratetype);//如果有多余的页框,则把多余的页框放回伙伴系统中
/*
* The pcppage_migratetype may differ from pageblock's
* migratetype depending on the decisions in
* find_suitable_fallback(). This is OK as long as it does not
* differ for MIGRATE_CMA pageblocks. Those can be used as
* fallback only via special __rmqueue_cma_fallback() function
*/
set_pcppage_migratetype(page, start_migratetype);
trace_mm_page_alloc_extfrag(page, order, current_order,
start_migratetype, fallback_mt);
return page;
}
return NULL;
}
内核定义了一个二维数组来描述迁移的规则,其定义如下:
static int fallbacks[MIGRATE_TYPES][4] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
#ifdef CONFIG_CMA
[MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */
#endif
#ifdef CONFIG_MEMORY_ISOLATION
[MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */
#endif
};
- 不可移动的备用迁移类型优先级顺序:MIGRATE_RECLAIMABLE > MIGRATE_MOVABLE
- 可回收的备用迁移类型优先级顺序: MIGRATE_UNMOVABLE > MIGRATE_MOVABLE
- 可移动的备份迁移类型优先级顺序: MIGRATE_RECLAIMABLE > MIGRATE_UNMOVABLE
int find_suitable_fallback(struct free_area *area, unsigned int order,
int migratetype, bool only_stealable, bool *can_steal)
{
int i;
int fallback_mt;
if (area->nr_free == 0)
return -1;
*can_steal = false;
for (i = 0;; i++) {
fallback_mt = fallbacks[migratetype][i]; ------------------(1)
if (fallback_mt == MIGRATE_TYPES)
break;
if (list_empty(&area->free_list[fallback_mt])) ------------------(2)
continue;
if (can_steal_fallback(order, migratetype)) ------------------(3)
*can_steal = true;
if (!only_stealable)
return fallback_mt;
if (*can_steal)
return fallback_mt;
}
return -1;
}
此函数主要的用途是找到合适的迁移类型,其主要完成以下工作
- 1.根据当前的迁移类型获取到一个备份的迁移类型,如果迁移类型MIGRATE_TYPES,则break
- 2.如果当前的迁移类型的freelist的链表为空,说明备份的迁移类型没有可用的页,则去下一级获取页
- 3.can_steal_fallback来判断此迁移类型释放可以作为备用迁移类型,如果则返回true
static void steal_suitable_fallback(struct zone *zone, struct page *page,
int start_type)
{
unsigned int current_order = page_order(page);
int pages;
/* Take ownership for orders >= pageblock_order */
if (current_order >= pageblock_order) {//如果选定的页块大于pageblock_order,就改变整页块的迁移类型
change_pageblock_range(page, current_order, start_type);
return;
}
//统计页块在伙伴系统中的页和不在伙伴系统中并且类型为MOVABLE的页数量并且删除在伙伴系统中的页
pages = move_freepages_block(zone, page, start_type);
/* Claim the whole block if over half of it is free */
if (pages >= (1 << (pageblock_order-1)) ||
page_group_by_mobility_disabled)
set_pageblock_migratetype(page, start_type);//通过修改页块在zone-> pageblock_flags中对应bit来修改页块的迁移类型
}
到此,对于当申请一个page的时候,去对应order的freelist的迁移类型链表中找对应的page,如果没有找到对应的page,则就会去对应类型的备用类型的freelist去获取page,将此page挂载到之前需要申请的freelsit中,然后进行retry再通过__rmqueue_smallest申请一次即可。
3. Alloc slowpath
当前面快速分配内存没有成功,就会通过各种途径尝试分配所需的内存,对于慢速分配,里面涉及的流程太过于复杂,涉及到的内存压缩(同步和异步)、直接内存回收和kswapd线程唤醒,放到后面章节。
4. 总结
到这里,伙伴系统的分配流程已经完毕,本章只是对分配内存的流程进行了梳理,学习了alloc_pages,大致清楚了伙伴系统是如何分配出连续的页面的整个过程。
5. 参考文档:
https://www.cnblogs.com/tolimit/p/4610974.html
深入理解linux架构
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
