多线程消费实例
,KafkaConsumer是非线程安全的。它和KafkaProducer不同,后者是线程安全的,因此用户可以在多个线程中放心地使用同一个KafkaProducer实例,事实上这也是社区推荐的producer使用方法,因为通常它比每个线程维护一个KafkaProducer实例效率要高。
但是对于consumer而言,用户无法直接在多个线程中共享一个KafkaConsumer实例,下面给出两种多线程消费的方法以及各自的实例。
1、每个线程维护一个KafkaConsumer
在这个方法中,用户创建多个线程来消费topic数据。每个线程都会创建专属于该线程的KafkaConsumer实例,如下图所示:

consumer group由多个线程的KafkaConsumer组成,每个线程负责消费固定数目的分区。下面给出一个完整的样例,该样例中包含3个类:
- ConsumerRunnable类:消费线程类,执行真正的消费任务
- ConsumerGroup类:消费线程管理类,创建过个线程类执行消费任务
- ConsumerMain类:测试主方法类
ConsumerRunnable.java
public class ConsumerRunnable implements Runnable {
//每个线程维护私有的KafkaConsumer实例
private final KafkaConsumer<String, String> consumer;
public ConsumerRunnable(String brokerList, String groupId, String topic) {
Properties properties = new Properties();
properties.put("bootstrap.servers", brokerList);
properties.put("group.id", groupId);
properties.put("enable.auto.commit", "true");//自动提交offset
properties.put("auto.commit.interval.ms", "1000");
properties.put("session.timeout.ms", "30000");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
this.consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Arrays.asList(topic));
}
@Override
public void run() {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(200);
for (ConsumerRecord<String, String> record : records) {
System.out.println(Thread.currentThread().getName() + " consumed " + record.partition()
+ "th message with offset: " + record.offset() + " value:" + record.value());
}
}
}
}
ConsumerGroup.java
public class ConsumerGroup {
private List<ConsumerRunnable> consumers;
public ConsumerGroup(int consumerNum, String groupId, String topic, String brokerList) {
consumers = new ArrayList<>(consumerNum);
for (int i = 0; i < consumerNum; ++i) {
ConsumerRunnable consumerThread = new ConsumerRunnable(brokerList, groupId, topic);
consumers.add(consumerThread);
}
}
public void execute() {
for (ConsumerRunnable task : consumers) {
new Thread(task).start();
}
}
}
ConsumerMain.java
public class ConsumerMain {
public static void main(String[] args) {
String brokerList = "localhost:9092";
String groupId = "testGroup";
String topic = "testTopic";
int consumerNum = 3;
ConsumerGroup consumerGroup = new ConsumerGroup(consumerNum, groupId, topic, brokerList);
consumerGroup.execute();
}
}
2、单KafkaConsumer实例+多worker线程
此方法与第一种方法的区别在于,我们将消息的获取与消息的处理解耦,把后者放入单独的工作者线程中,即所谓的worker线程中。同时在全局维护一个或若干个consumer实例执行消息获取任务,如图所示。

本例使用全局的KafkaConsumer实例执行消息获取,然后把获取到的消息集合交给线程池中的worker线程执行工作。之后worker线程完成处理后上报位移状态,由全局consumer提交位移。代码中共有如下3个类。
Consumer ThreadHandler类:consumer多线程管理类,用于创建线程池以及为每个线程分配消息集合。另外consumer位移提交也在该类中完成。Consumer Worker类:本质上是一个Runnable,执行真正的消费逻辑并上报位移信息给ConsumerThreadHandler.Main类:测试主方法类。
ConsumerThreadHandler.java
public class ConsumerThreadHandler<K, V> {
private final KafkaConsumer<K, V> consumer;
private ExecutorService executors;
private final Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
public ConsumerThreadHandler(String brokerList, String groupId, String topic) {
Properties properties = new Properties();
properties.put("bootstrap.servers", brokerList);
properties.put("group.id", groupId);
properties.put("enable.auto.commit", "false");//手动提交offset
properties.put("auto.offset.reset", "earliest");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
this.consumer = new KafkaConsumer<K, V>(properties);
consumer.subscribe(Arrays.asList(topic), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
consumer.commitSync(offsets);//提交位移
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
offsets.clear();
}
});
}
/**
* 消费方法
* @param threadNumber 线程池中的线程数
*/
public void consume(int threadNumber) {
executors = new ThreadPoolExecutor(
threadNumber,
threadNumber,
0L,
TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(1000),
new ThreadPoolExecutor.CallerRunsPolicy());
try {
while (true) {
ConsumerRecords<K, V> records = consumer.poll(1000L);
if (!records.isEmpty()) {
executors.submit(new ConsumerWorker<>(records, offsets));
}
commitOffsets();
}
} catch (WakeupException e) {
} finally {
commitOffsets();
consumer.close();
}
}
private void commitOffsets() {
//尽量降低synchronized块对offsets锁定的时间
Map<TopicPartition, OffsetAndMetadata> unmodfiedMap;
synchronized (offsets) {
if (offsets.isEmpty()) {
return;
}
unmodfiedMap = Collections.unmodifiableMap(new HashMap<>(offsets));
offsets.clear();
}
consumer.commitSync(unmodfiedMap);
}
public void close() {
consumer.wakeup();
executors.shutdown();
}
}
ConsumerWorker.java
public class ConsumerWorker<K, V> implements Runnable {
private final ConsumerRecords<K, V> records;
private final Map<TopicPartition, OffsetAndMetadata> offsets;
public ConsumerWorker(ConsumerRecords<K, V> records, Map<TopicPartition, OffsetAndMetadata> offsets) {
this.records = records;
this.offsets = offsets;
}
@Override
public void run() {
for (TopicPartition partition : records.partitions()) {
//获取指定分区的记录
List<ConsumerRecord<K, V>> partitionRecords = this.records.records(partition);
for (ConsumerRecord<K, V> record : partitionRecords) {
//处理记录
System.out.println(Thread.currentThread().getName() + " consumed " + record.partition()
+ "th message with offset: " + record.offset() + " value:" + record.value());
}
//提交offset
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
synchronized (offsets) {
if (!offsets.containsKey(partition)) {
offsets.put(partition, new OffsetAndMetadata(lastOffset + 1));
} else {
long curr = offsets.get(partition).offset();
if (curr <= lastOffset + 1) {
offsets.put(partition, new OffsetAndMetadata(lastOffset + 1));
}
}
}
}
}
}
Main.java
public class Main {
public static void main(String[] args) {
String brokerList = "localhost:9092";
String topic = "testTopic";
String groupId = "testGroup";
final ConsumerThreadHandler<byte[], byte[]> handler = new ConsumerThreadHandler<>(brokerList, groupId, topic);
final int cpuCount = Runtime.getRuntime().availableProcessors();
Runnable runnable = new Runnable() {
@Override
public void run() {
handler.consume(cpuCount);
}
};
new Thread(runnable).start();
try{
Thread.sleep(20000L);
} catch (InterruptedException e) {
}
System.out.println("Starting to close the consumer....");
handler.close();
}
}
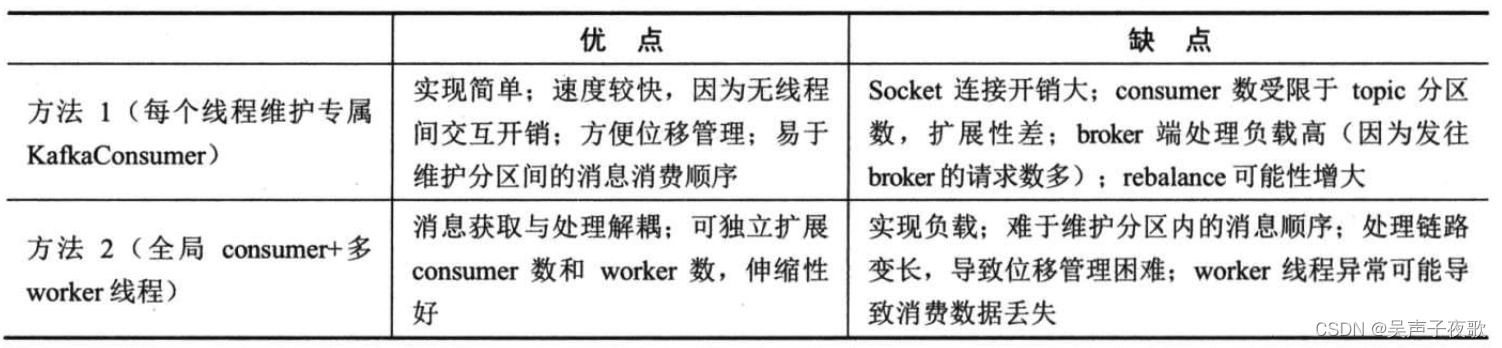
3、两种方法对比
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
