jemalloc内存分配算法简介
为什么要讲这个呢,因为netty的池化内存分配就是这个的改进版,要想更好的了解改进版,当然要先知道他的原版是怎么样的啦,要知道为什么他要用这个分配算法,能解决什么问题。首先这个是一篇论文里提出来的构想,还有他的源码[github]。(https://github.com/jemalloc/jemalloc),是C/C++的版本的,我们的JVM虚拟机貌似就是用这个分配内存的,netty就是在他的上面做了改进然后是Java版的。
解决的问题
主要是解决多处理器或者说是多线程对同一个内存修改时候的锁竞争问题,比如说缓存行,如果多个处理器对同一个缓存行的不同数据做操作,那就会涉及缓存锁,其中一个线程就得等了,而且轮到他的时候缓存失效了,还得去加载,然后修改,但是明明他们操作的是不同的对象呀。就像下面这样:
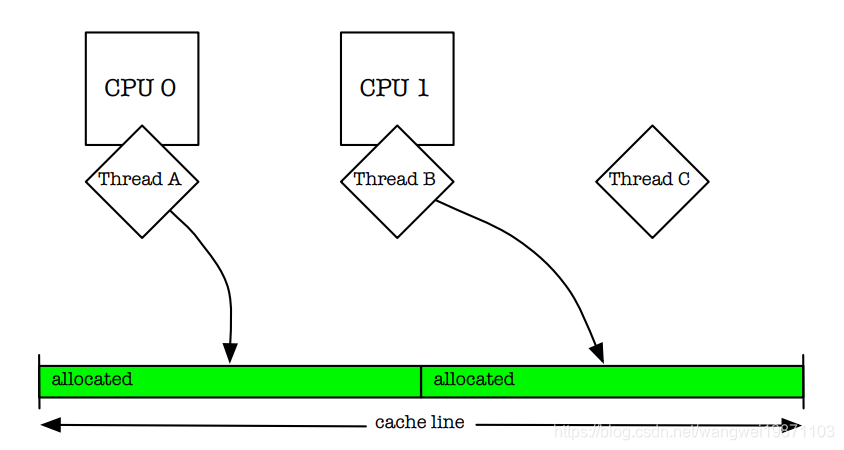
这种情况有一种传统的方式就是用 填充将缓存行填满 ,只留一个线程的数据,另外一个线程在另一个缓存行,但是这种做法很浪费空间,其实就等于说是有内部碎片,比如缓存行32字节,我只放了16个字节的,那还有16字节就用其他东西填满了,这样不是很浪费么。那jemalloc做法就是让不同线程在不同的区域里分配内存,避免竞争,所以他会有内存分配算法去做这个事情,尽量的减少内部碎片,减少线程竞争。比如这样:
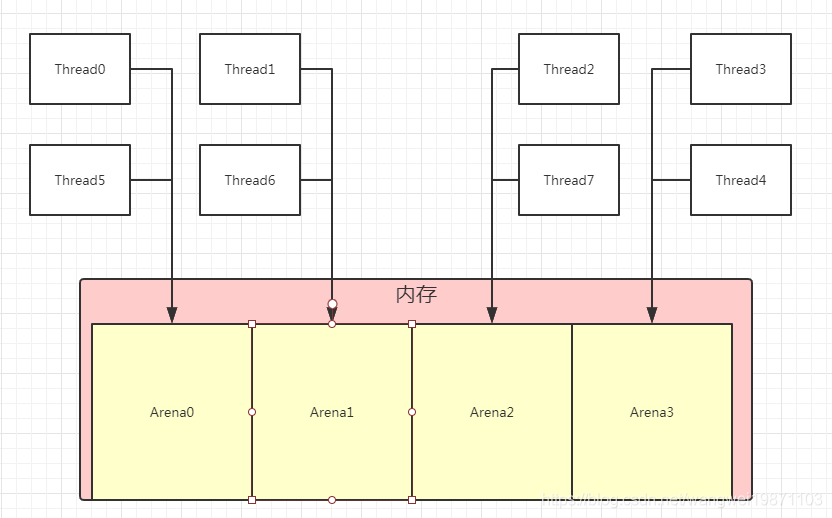
他根据处理器的核数把空间分为若干个Arena区域,然后把线程根据轮询的分配策略,就最简单的无限从到尾分配到相应的区域里。这样可以避免多个线程竞争激烈的情况,初期话的时候基本就是一个线程一个区域,后面可能多个线程一个区域。
所以这个空间和时间之间总需要平衡啊,一味追求哪一个都可能会牺牲另外一个。
更加细粒度的分配
前面说的Arena区域为了更好的控制内存分配大小,减少内部碎片,还会把这个区域分成很多个chunk也就是块。默认是2M,chunk还会根据不同的尺寸要求被分割或者组合成不同的尺寸,如下图:
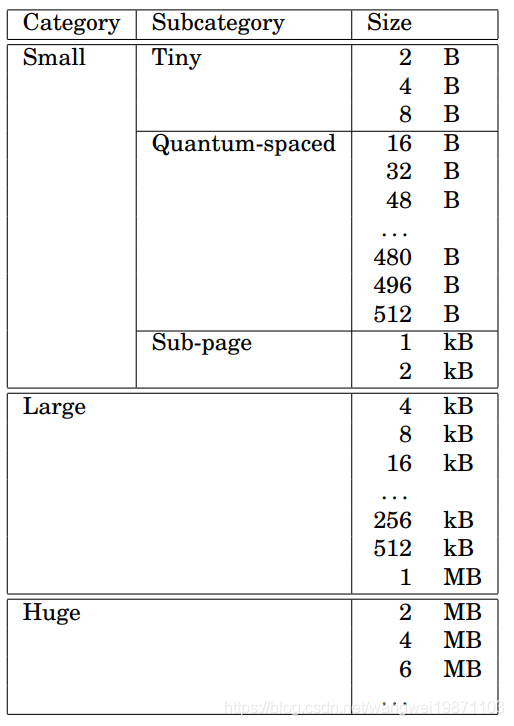
基本有5类分配尺寸,要分配的尺寸如果没有对应的大小,就向上取最近的大小,比如我要5M的空间,但是这里没有,那就向上取最近的6M。
Huge基本上是每次按2M的增量递增的,所以基本就是多个chunk组成。Small是2B-2kB大小的还分为三种。Tiny是2B-8B,每次乘以2,总共3种尺寸。Quantum-spaced是16B-512B,每次增加16B,总共32种尺寸。Sub-page是1KB-2KB,总共2种尺寸。Large是4KB-1MB,每次乘以2,总共9种尺寸。
另外操作系统将物理内存分页,默认page是4K。chunk就是由很多个page组成的,只是在逻辑上又分了上面那么多的区域,便于减少内存碎片。而chunk内部还有可以由多个page组成的另外一种形式,叫做page run。page run内部又可以分成多个region。最终分给我们用的,就是region,page run必须是page大小(默认4KB)的整数倍,而page run里面有很多尺寸相同的region ,region的尺寸是8B-14KB,对应的尺寸种类:
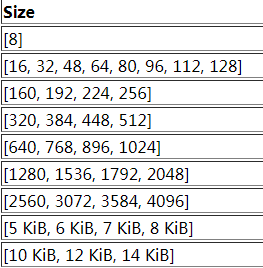
画个内存分配的结构示意图大致就是这样:

或者换种形式:

大致知道他会这样分配内存就可以了,当然具体的还有很多分配的算法后面会说到。
根据内存使用率将chunk分类
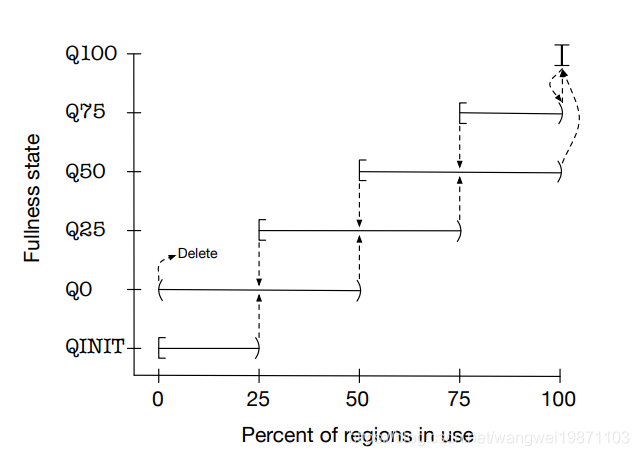
论文里还说了,会对chunk中的内存使用率来进行分类管理,大致有6类:
QINIT:[0-25)
Q0:(0-50)
Q25:[25-75)
Q50:[50-100)
Q75:[75-100)
Q100:100
QINIT是初始化状态,不会被删除,Q0状态下,如果为0了,就会被删除。
Buddy伙伴算法简介
什么是伙伴呢,就是一块内存一分为二,分出来的两个就互为伙伴。那这个算法其实就是一种分配和回收的算法。每次分配的空间都是2的幂次。比如有一块1MB的内存,如果用伙伴算法分配和回收是这样的。先看请求申请的内存是否大于内存的一半且小于可分配内存,如果满足就分配1MB内存给他,如果不是,就把1MB内存一分为二,分为两个512KB,再判断是否大于分后的内存的一半,如果满足就分配,不满足就继续一分为二,直到最后分到不能分的最小单位为止,直接就分配最小单位给他了。当然释放的时候,会去判断相邻的未分配内存块是否是伙伴关系,是的话就可以合并回大的。
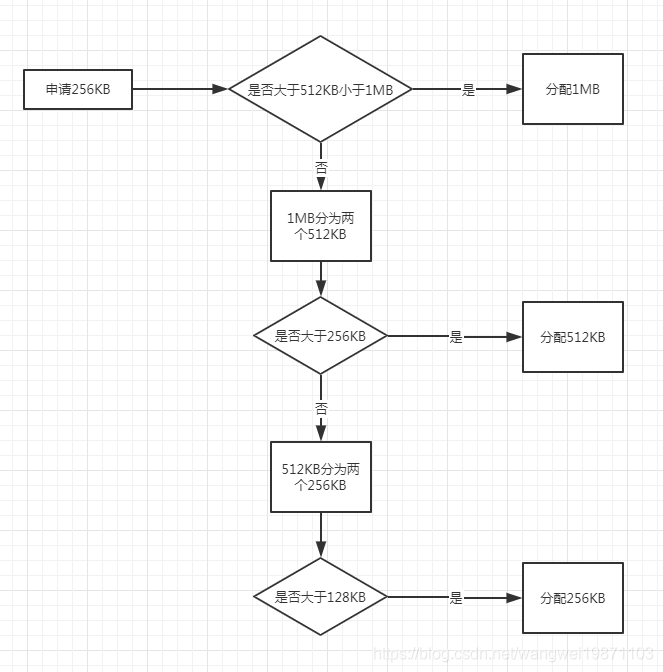
举个具体的例子,比如我有1MB的空间,有个要申请256K的请求。那我的流程就是这样,然后分配了256KB的内存:
我的内存区域已经分成这样了:
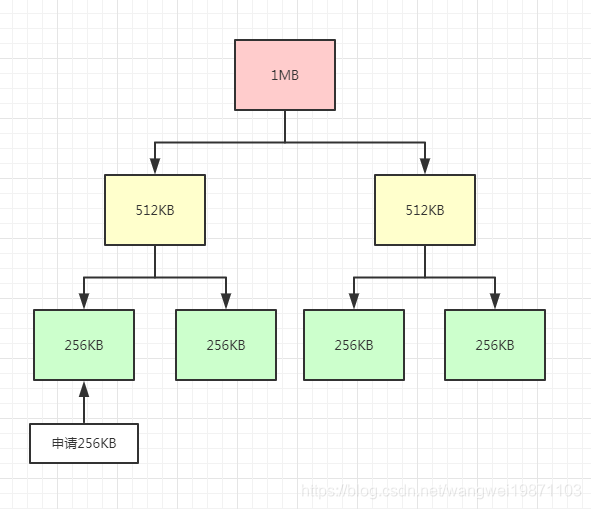
这不是一棵满二叉树么,对的,其实就可以用这种结构来分割,netty里面就有使用这个,先了解下即可。
或者换个形式看分配的过程,其实是一样的:

再举个分配和回收一起的例子,还是1M数据,有256KB,50KB,100KB的申请顺序和释放顺序,具体步骤和内存分配情况看下图:
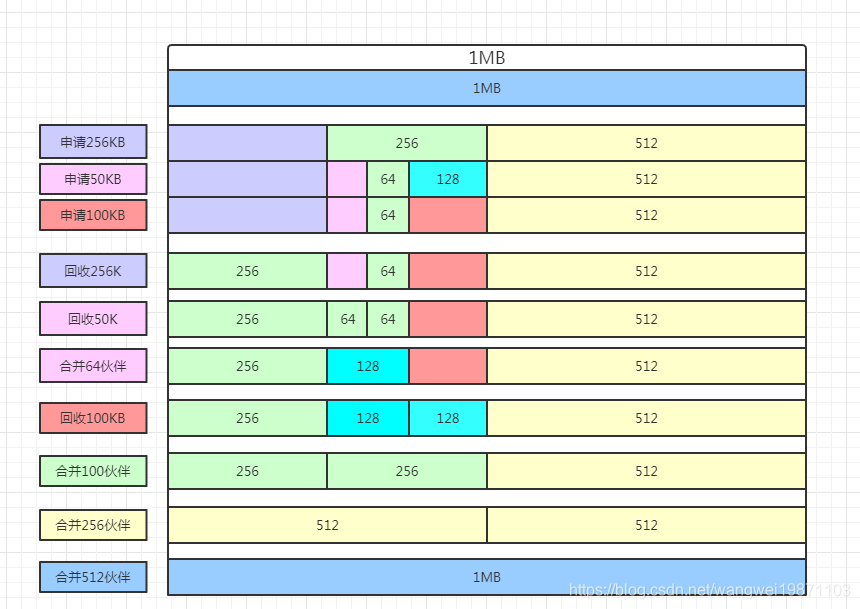
可以看到分配之后的最后全回收了又回来了。可以看到分配的内存基本没有外部碎片,全部可以分配出去,但是这样分配也会有大量内存碎片,具体优缺点暂时不研究了,现在大致了解这个原理就好。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,部分图片来自网络,侵删。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
