在之前的文章中,我们学习了RocketMQ的原理;RocketMQ中 命名服务 ServiceName 的运行流程;以及消息生产、发送的原理和模式。这一篇,就让我们从消息消费的角度去进一步的学习。
1 消息消费
消息的消费主要是由如下几个核心能力组成的:
- 消费方式:Push(推) 或者 Pull(拉)
- 消费模式:广播模式和集群模式
- 消息消费反馈
- 流量控制(包括消费并发线程数设置)
- 消息的过滤(Tag, Key),过滤标签 TagA||TagB||TagC
1.1 消费方式Push or Pull
RocketMQ消息订阅有方式:
- Push方式(MQPushConsumer),MQ Server主动向消费端推送;
这种模式不考虑消费端是否有能力处理消费数据,实时性比较高,能够及时推送数据,适合大部分业务场景。但同时存在一个问题,如果遇到峰值期,瞬间推送过多消息,会导致积压,甚至客户端雪崩。 - Pull方式(MQPullConsumer),消费端在有需要时,主动从MQ Server拉取数据。
消费端比较灵活,可以根据自己的吞吐能力,消费的节奏,主动安排消息拉取。适合消费和计算耗时比较大的消费场景。
缺点就是如何从代码层面精准地控制拉取的频率,过短对消费端有压力,并且有可能空拉照成资源拉菲;过长可能对消息及时性有影响,可以采用长轮询的方式进行处理。 - Push模式与Pull模式的区别
Push方式的做法是,Consumer封装了长轮询的操作,并注册MessageListener监听器,当MessageListener监听到有新的消息的时候,消费端便被唤醒,读取消息进行消费。从用户角度上,订阅消息并消费感觉消息是推过来的。
Pull方式的做法是,消费端主动去拉取数据,获取相应的Topic的,遍历MessageQueue集合,取数,重新标记offset,再取数,直至消费完成。
1.2 消费模式 集群 or 广播
RocketMQ 目前支持集群模式和广播消费模式,其中集群模式使用范围比较大,即点对点,消息消费了即完成。
- 集群负载均衡消费模式(默认)
集群模式是一个主题下的单条消息只允许被同一消费组内的一个消费者消费,消费完即完成,即P2P。
在集群模式下,消息队列负载的模式:一个MessageQueue集合同一个时间内只允许被同一消费组内的单个消费者消费一次(这种模式不允许重复消费,如付款,订单提交),单个Consumer可以消费多个遍历MessageQueue集合。 - 广播消费模式
广播模式指的是当前主题下的消费组所有消费者都可以消费并处理消息一次,达到广播的目的。很多业务场景,比如航班延迟的消息通知,告知客户端缓存信息过期需要重新拉起等。
1.3 消费进度反馈
RocketMQ客户端消费数据之后,需要向Broker反馈消息的消费进度,Broker获取到消费进度记录下来。这样保证 队列rebalance和客户端消费者重启动的时候,可以获取到准确的消费进度。
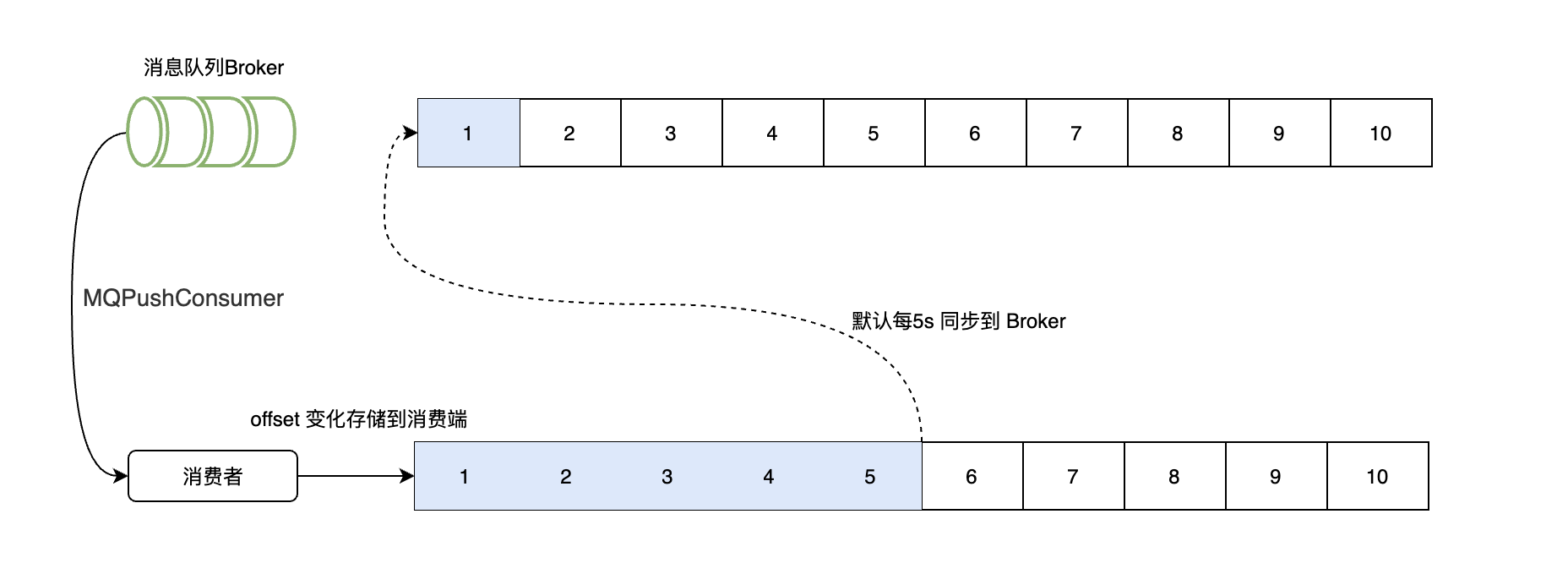
消息消费以及进度反馈的主步骤如下:
- 消费线程池消费完数据之后,将消息消费进度缓存在内存中。
- 定时调度任务 5s 一次将消息队里的消费 offset 提交至Broker。
- Broker接受到消息之后,存储在内存中,如果有新的过来,可以更行,同样的每5s将offset持久化下来。
- 消费客户端从Broker拉取消息时,同步将MessageQueue的消费偏移量提交到Broker。
综合上面的内容,需要注意的点如下:
- RocketMQ以Consumer Group(消费者小组)和 Queue(队列)为标准对消费刻度进行管理的
- Consumer Offset标记消费组在消息队列(Queue)上的消费进度。
- 消费成功后,消费进度暂时更新到本地缓存,调度任务会定时(默认5s)将进度同步到broker(需注意如果宕机,消费进度未提交则可能导致被重复消费),Broker最终将消费进度持久化到磁盘。
- RocketMQ支持并发消费,所以是多个线程并行处理,每次记录消费进度的时候,把线程中最小的offset值作为消费进度值,这样避免了消息丢失,但有重复消费的风险,业务中需保证操作幂等性。
- offset存储模式:集群模式,消息进度存储于Broker上;广播模式,消息消费进度在消费端即可。
1.4 消费端流量控制
可以在DefaultMQPushConsumer 对象中配置各种属性来对消费流量进行控制:
-
PullInterval: 配置消费端拉取MQ消息的间隔时间。间隔时间是按照上次消费完成之后(比如rocketMQ收到Ack回复消息之后)。
PullInterval=20s,比如上次rocketMq服务收到Ack消息是12:15:15,则 12:15:35再去拉消息。 -
PullBatchSize: 消费端每个队列一次拉取多少个消息,若该消费端分赔了N个监控队列,每次拉取M个,那么消费端每次去rocketMq拉取的消息为N * M。
消费端每次pull到消息总数=PullBatchSize * 监听队列数,如 PullBatchSize = 2, 监听队列=5,则 消息总数量 = 2 * 5 = 10。 -
ThreadMin和ThreadMax: 消费端消费pull到的消息需要的线程数量。
- ThreadMin:消费端拉取到消息后分配消费的线程数
- ThreadMax:最大消费线程,如果默认队列满了,则启用新的线程
-
RocketMq 逻辑消费队列数量的配置
rocketMq 可以配置消费队列,如 queue Read1 ,queue Read2,配置数量决定每次pull到的消息总数。Rocket MQ 提供了读写队列数量的配置。 -
消费端节点部署数量
多节点消费端线程数量要比单节点消费线程数量多,理论上消费速度大于单节点,分治思维。
1.5 消息的过滤
在过滤消息的时候,标签模式简单而是用,可以筛选出你需要的数据。如下:
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("groupTest");
consumer.subscribe("testTopic", MessageSelector.byTag("Tag1 || Tag2 || Tag3").bySql("sex = 'male' AND name = 'brand'));
这种情况下,消息中带有 Tag1 、Tag2、Tag3 标签就会被过滤出来,但是单个消限制息只能有一个标签,这就远远满足不了各种复杂的并交集场景的需要了。
这时候Rocket MQ可以在消息中设置一些属性,再使用SQL表达式筛选属性来过滤出需要的数据。 如下
------------
| message |
|----------| sex = male AND name = 'brand' , Gotten
| name = 'brand' |
| sex = 'male'|
| age = 21|
------------
------------
| message |
|----------| sex = male AND name = 'brand', Gotten , Missed
| name = 'Anny' |
| sex = 'female'|
| age = 20 |
------------
1.8 提高Consumer的处理能力 :看情况
- 提高消费并行度
在同一个ConsumerGroup下(Clustering方式),可以通过增加Consumer实例的数量来提高并行度。
通过加机器,或者在已有机器中启动多个Consumer进程都可以增加Consumer实例数。
注意:总的Consumer数量不要超过Topic下Read Queue数量,超过的Consumer实例接收不到消息。
此外,通过提高单个Consumer实例中的并行处理的线程数,可以在同一个Consumer内增加并行度来提高吞吐量(设置方法是修改consumeThreadMin和consumeThreadMax)。 - 以批量方式进行消费
某些业务场景下,多条消息同时处理的时间会大大小于逐个处理的时间总和,比如消费消息中涉及update某个数据库,一次update10条的时间会大大小于十次update1条数据的时间。
可以通过批量方式消费来提高消费的吞吐量。实现方法是设置Consumer的consumeMessageBatchMaxSize这个参数,默认是1,如果设置为N,在消息多的时候每次收到的是个长度为N的消息链表。 - 检测延时情况,跳过非重要消息
Consumer在消费的过程中,如果发现由于某种原因发生严重的消息堆积,短时间无法消除堆积,这个时候可以选择丢弃不重要的消息,使Consumer尽快追上Producer的进度。
2 消息消费的模式
2.1 基本信息消费
消费者的基本实现,连接 NameServer的地址,指定Topic和Tag,读取到需要消费的数据,然后轮询并处理。
public class SimpleConsumerApplication {
public static void main(String[] args) throws MQClientException {
// 1.创建消费者Consumer,并指定消费者组名为 testConsumGroup
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("testConsumGroup");
// 2.指定NameServer的地址,以获取Broker路由地址
consumer.setNamesrvAddr("192.168.139.1:9876");
// 3.指定Topic和Tag 信息。* 代表所有
consumer.subscribe("testTopic", "*");
// 4.设置回调函数,用来处理读取到的消息, MessageListenerOrderly 用单个线程处理处理队列的数据
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgList, ConsumeOrderlyContext context) {
for (MessageExt msg : msgList) {
System.out.println("线程 " + Thread.currentThread().getName() + " : " + msg.getBody().toString());
// Todo,具体的业务逻辑
}
return ConsumeOrderlyStatus.SUCCESS;
}
});
// 5.消费者开始执行消费任务
consumer.start();
}
}
2.2 顺序消费
相比与基本消费,多了一个 ConsumeFromWhere的设置。代表消费者从哪个位置开始消费,枚举如下:
- CONSUME_FROM_LAST_OFFSET:第一次启动从队列最后位置消费,非第一次启动接着上次消费的进度继续消费
- CONSUME_FROM_FIRST_OFFSET:第一次启动从队列初始位置消费,非第一次启动接着上次消费的进度继续消费
- CONSUME_FROM_TIMESTAMP:第一次启动从指定时间点位置消费,非第一次启动接着上次消费的进度继续消费
以上所说的第一次启动是指从来没有消费过的消费者,如果该消费者消费过,那么会在broker端记录该消费者的消费位置,消费者挂了再启动,则从上次消费进度继续执行。
public class SimpleOrderApplication {
public static void main(String[] args) throws MQClientException {
// 1.创建消费者Consumer,并指定消费者组名为 testConsumGroup
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("testConsumGroup");
// 2.指定NameServer的地址,以获取Broker路由地址
consumer.setNamesrvAddr("192.168.139.1:9876");
/**
* 设置Consumer第一次启动是从队列头部、队列尾部、还是指定时间戳节点开始消费
* 非第一次启动接着上次消费的进度继续消费
*/
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
// 3.指定Topic和Tag 信息。* 代表所有
consumer.subscribe("testTopic", "*");
// 4.设置回调函数,用来处理读取到的消息, MessageListenerOrderly 用单个线程处理处理队列的数据
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgList, ConsumeOrderlyContext context) {
for (MessageExt msg : msgList) {
System.out.println("线程 " + Thread.currentThread().getName() + " : " + msg.getBody().toString());
// Todo,具体的业务逻辑
}
return ConsumeOrderlyStatus.SUCCESS;
}
});
// 5.消费者开始执行消费任务
consumer.start();
}
}
2.3 过滤消息消费
可以使用MessageSelector.byTag来进行标签筛选;或者使用MessageSelector.bySql 来进行消息属性筛选;或者混合使用。
参考下面代码,注释说明的比较清楚。
public class FilterConsumerApplication {
public static void main(String[] args) throws MQClientException {
// 1.创建消费者Consumer,并指定消费者组名为 testConsumGroup
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("testConsumGroup");
// 2.指定NameServer的地址,以获取Broker路由地址
consumer.setNamesrvAddr("192.168.139.1:9876");
// 3.指定Topic和Tag 信息。只有订阅的消息有 sex 和 name 属性, 并且年龄为 18 岁以上的男性
// consumer.subscribe("testTopic", MessageSelector.byTag("userTag1 || userTag2"));
consumer.subscribe("testTopic", MessageSelector.bySql("sex = 'male' AND age > 18"));
// 4.设置回调函数,用来处理读取到的消息, MessageListenerOrderly 用单个线程处理处理队列的数据
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgList, ConsumeOrderlyContext context) {
for (MessageExt msg : msgList) {
System.out.println("线程 " + Thread.currentThread().getName() + " : " + msg.getBody().toString());
// Todo,具体的业务逻辑
}
return ConsumeOrderlyStatus.SUCCESS;
}
});
// 5.消费者开始执行消费任务
consumer.start();
}
}
3 总结
- 消费方式:Push(推) 或者 Pull(拉)
- 消费模式:广播模式和集群模式
- 消息消费反馈
- 流量控制(包括消费并发线程数设置)
- 消息的过滤(Tag, Key),过滤标签 TagA||TagB||TagC
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
