NameNode负责管理分布式文件系统的元数据,但本身是单点,所以为了保证可用性,我们还需要一个BackupNode节点,从NameNode同步Edits Log日志,并回放日志生成内存文件目录树:
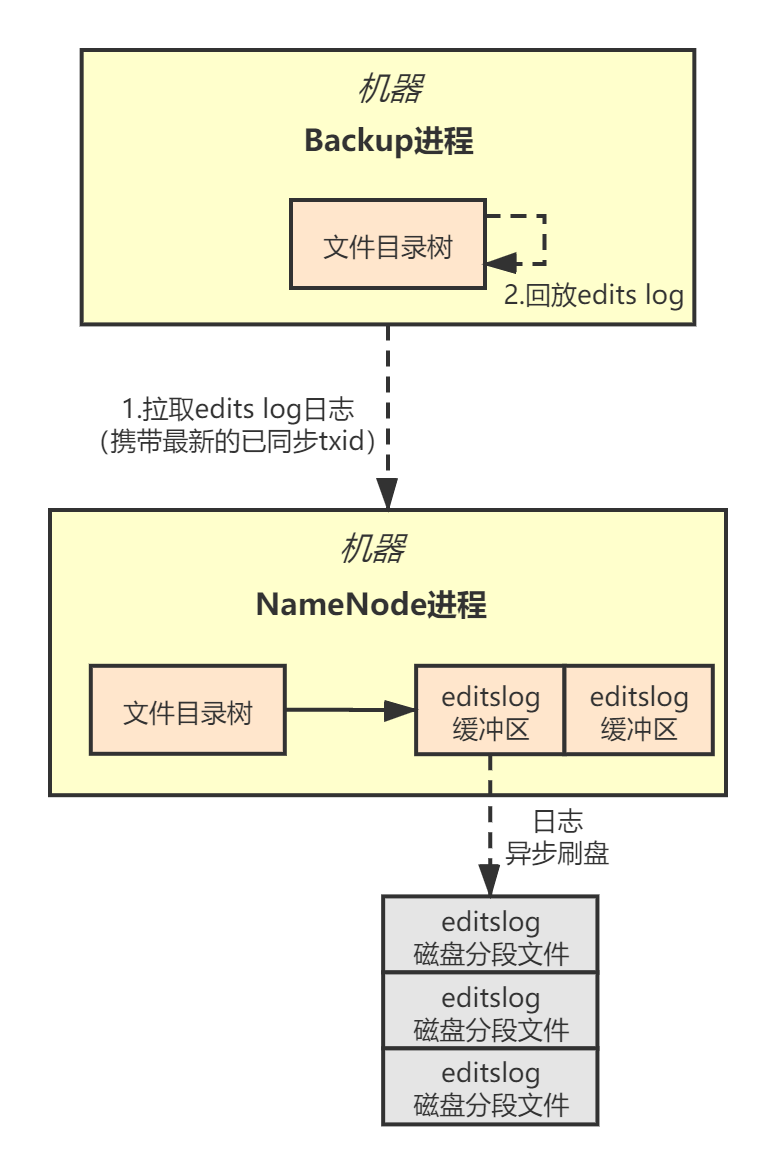
本章,我们先来看BackupNode是如何从NameNode同步Edits Log日志的?在设计BackupNode节点的同步机制时,我们需要考虑以下方面的内容:
- 采用pull模式还是push模式同步edits log;
- 采用gRPC还是自研NIO组件同步edits log;
- 批量拉取机制;
- NameNode侧的缓存机制。
一、设计思路
1.1 pull模型
事实上,大多数分布式中间件都会采用pull模式同步数据,比如Kafka、RokectMQ等,pull模式实现起来相对简单,可以减少对NameNode的影响。如果采用push模式,NameNode主动推数据给BackupNode,BackupNode又恰好宕机了,会导致NameNode的不稳定。
另外,为了减少复杂度,我们直接基于gRPC批量拉取数据,每次批量拉取的数据量根据情况而定,可以配置化,以提升Edits Log同步的性能。
1.2 缓存机制
NameNode会在内存里缓存一批Edits Log数据,BackupNode优先从缓存中拉取,缓存中不存在才从磁盘获取。这样可以避免频繁读取磁盘文件,提升性能。
1.3 锁机制
NameNode节点会异步将Edits Log刷入磁盘文件,与此同时,BackupNode会请求NameNode从磁盘读取Edits Log日志进行同步,所以需要依赖锁机制对并发访问进行控制。为了提升性能,为了提升性能,我们可以考虑采用 写时复制 的方案。
二、BackupNode实现
我们新建一个Maven工程——dfs-backupnode,存放BackupNode的相关代码:

2.1 BackupNode启动类
BackupNode通过gRPC与NameNode通信,所以可以将它看成gRPC客户端。BackupNode启动后会创建一个 EditsLogFetcher 线程,不断从NameNode拉取edits log,然后通过FSNamesystem组件完成日志回放,生成自己的内存文件目录树:
/**
* 启动类
*/
public class BackupNode {
private volatile Boolean isRunning = true;
private FSNameSystem namesystem;
private NameNodeRpcClient namenode;
public static void main(String[] args) {
BackupNode backupNode = new BackupNode();
backupNode.init();
backupNode.start();
}
public void init() {
this.namesystem = new FSNameSystem();
this.namenode = new NameNodeRpcClient();
}
public void start() {
// 定期拉取Edits Log的线程
EditsLogFetcher editsLogFetcher = new EditsLogFetcher(this, namesystem, namenode);
editsLogFetcher.start();
//...
}
public Boolean isRunning() {
return isRunning;
}
}
FSNamesystem组件和NameNode中的FSNamesystem完全一样,我就不赘述贴代码了。
2.2 RPC接口
首先,我们需要在NameNodeServiceProto.proto文件中新增一个接口,然后生成gRPC模板代码:
fetchEditsLog接口:发送请求到NameNode,拉取Edits Log日志。
syntax = "proto3";
option java_multiple_files = true;
option java_outer_classname = "NameNodeServiceProto";
service NameNodeService {
rpc fetchEditsLog(FetchEditsLogRequest) returns (FetchEditsLogResponse){}
}
message FetchEditsLogRequest{
int64 syncedTxid = 1;
}
message FetchEditsLogResponse{
string editsLog = 1;
}
注意上面的接口,BackupNode每次发送pull请求拉取edits log日志时,需要带上已经成功拉取到的最新edits log日志的txid——syncedTxid。gRPC客户端调用NameNode的模板代码我把它封装在组件 NameNodeRpcClient 中:
public class NameNodeRpcClient {
private static final String NAMENODE_HOSTNAME = "localhost";
private static final Integer NAMENODE_PORT = 50070;
private volatile Boolean isRunning = true;
private NameNodeServiceGrpc.NameNodeServiceBlockingStub namenode;
public NameNodeRpcClient() {
ManagedChannel channel = NettyChannelBuilder.forAddress(NAMENODE_HOSTNAME, NAMENODE_PORT)
.negotiationType(NegotiationType.PLAINTEXT).build();
this.namenode = NameNodeServiceGrpc.newBlockingStub(channel);
}
/**
* 拉取edits log
*/
public JSONArray fetchEditsLog(long syncedTxid) {
FetchEditsLogRequest request = FetchEditsLogRequest.newBuilder()
.setSyncedTxid(syncedTxid).build();
FetchEditsLogResponse response = namenode.fetchEditsLog(request);
String editsLogJson = response.getEditsLog();
return JSONArray.parseArray(editsLogJson);
}
public Boolean getRunning() {
return isRunning;
}
public void setRunning(Boolean running) {
isRunning = running;
}
}
2.3 日志拉取线程
BackupNode启动后,会创建一个日志拉取线程 EditsLogFetcher ,调用NameNode的gRPC服务端接口,每次调用会拉取到一批日志,然后回放日志,生成内存文件目录树:
/**
* edits log复制组件
*/
public class EditsLogFetcher extends Thread {
private static final Integer BACKUP_NODE_FETCH_SIZE = 10;
private BackupNode backupNode;
private NameNodeRpcClient namenode;
private FSNameSystem namesystem;
public EditsLogFetcher(BackupNode backupNode, FSNameSystem namesystem, NameNodeRpcClient namenode) {
this.backupNode = backupNode;
this.namenode = namenode;
this.namesystem = namesystem;
}
@Override
public void run() {
System.out.println("edits log同步线程已经启动......");
while (backupNode.isRunning()) {
try {
// 1.如果BackipNode正在进行元数据恢复,则等待其完成
if (!namesystem.isFinishedRecover()) {
System.out.println("当前还没完成元数据恢复,不进行editlog同步......");
Thread.sleep(1000);
continue;
}
// 2.从上一次同步完成的txid开始进行日志拉取
long syncedTxid = namesystem.getSyncedTxid();
JSONArray editsLogs = namenode.fetchEditsLog(syncedTxid);
if (editsLogs.size() == 0) {
System.out.println("没有拉取到任何一条editslog,等待1秒后继续尝试拉取");
Thread.sleep(1000);
continue;
}
if (editsLogs.size() < BACKUP_NODE_FETCH_SIZE) {
Thread.sleep(1000);
System.out.println("拉取到的edits log不足10条数据,等待1秒后再次继续去拉取");
}
// 3.进行日志回放
for (int i = 0; i < editsLogs.size(); i++) {
JSONObject editsLog = editsLogs.getJSONObject(i);
System.out.println("拉取到一条editslog:" + editsLog.toJSONString());
String op = editsLog.getString("OP");
if (op.equals("MKDIR")) {
String path = editsLog.getString("PATH");
try {
namesystem.mkdir(editsLog.getLongValue("txid"), path);
} catch (Exception e) {
e.printStackTrace();
}
}
}
namenode.setRunning(true);
} catch (Exception e) {
namenode.setRunning(false);
}
}
}
}
注意上述代码的第一步,BackupNode启动后,会立即从指定目录加载fsimage文件恢复内存目录树,然后拿到最近一次checkpoint保存的syncedTxid,最后发送日志同步请求拉取syncedTxid之后的edits log。
关于checkpoint机制,我会在下一章讲解。
三、NameNode实现
我们重点来看NameNode服务端接受到日志同步RPC请求后,是如何完成edits log日志读取并响应的:
3.1 gRPC服务实现
NameNodeServiceImpl实现了gRPC的fetchEditsLog接口,并将日志同步的操作委托给了一个名为 EditLogReplicator 的组件:
/**
* NameNode的RPC服务接口
*/
public class NameNodeServiceImpl extends NameNodeServiceGrpc.NameNodeServiceImplBase {
// 负责日志复制的组件
private EditLogReplicator replicator;
private volatile Boolean isRunning = true;
public NameNodeServiceImpl(FSNameSystem namesystem, DataNodeManager datanodeManager,
EditLogReplicator replicator) {
this.namesystem = namesystem;
this.datanodeManager = datanodeManager;
this.replicator = replicator;
}
/**
* Edits Log日志同步
*/
@Override
public void fetchEditsLog(FetchEditsLogRequest request,
StreamObserver<FetchEditsLogResponse> responseObserver) {
if(!isRunning) {
FetchEditsLogResponse response = FetchEditsLogResponse.newBuilder()
.setEditsLog(new JSONArray().toJSONString())
.build();
responseObserver.onNext(response);
responseObserver.onCompleted();
return;
}
// 委托组件EditLogReplicator完成Edits Log日志拉取
long syncedTxid = request.getSyncedTxid();
List<String> list = replicator.fetchEditsLog(syncedTxid);
String result = JSONObject.toJSONString(list);
FetchEditsLogResponse response = FetchEditsLogResponse.newBuilder().setEditsLog(result).build();
responseObserver.onNext(response);
responseObserver.onCompleted();
}
}
3.2 日志读取
我们来看下组件 EditLogReplicator 。EditLogReplicator实现的复杂点在于要考虑各种读取日志的情况,我画了下面这张图,便于读者理解,读者可以结合图阅读代码:

EditLogReplicator自己有一块缓冲区currentBufferedEditsLog,它会从磁盘或者Edits Log双缓冲区读取数据放到自己的缓存里,日志复制时优先从缓冲区读取。
/**
* Edits Log日志复制组件
*/
public class EditLogReplicator {
private static final Integer BACKUP_NODE_FETCH_SIZE = 10;
private FSNameSystem namesystem;
// 缓存的一部分edits log
private List<String> currentBufferedEditsLog = new ArrayList<String>();
// 缓存的edits log中的最大txid
private Long currentBufferedMaxTxid = 0L;
// 缓存对应的磁盘文件
private String bufferedFlushedTxid;
public EditLogReplicator(FSNameSystem nameSystem) {
this.namesystem = nameSystem;
}
/**
* 从缓存或磁盘读取Edits Log日志
*/
public List<String> fetchEditsLog(long syncedTxid) {
// 1.获取已刷入磁盘的日志ID索引
List<String> flushedTxids = namesystem.getEditsLog().getFlushedTxids();
// 2.1 日志还没落磁盘
if (flushedTxids.size() == 0) {
System.out.println("暂时没有任何磁盘文件,直接从内存缓冲中拉取edits log......");
return fetchFromBufferedEditsLog(syncedTxid);
}
// 2.2 日志已经落磁盘
else {
// 2.2.1 缓存中已经有从磁盘读取的数据
if (bufferedFlushedTxid != null) {
// 如果要拉取的数据就在当前缓存的磁盘文件数据里
if (existInFlushedFile(syncedTxid, bufferedFlushedTxid)) {
System.out.println("上一次已经缓存过磁盘文件的数据,直接从磁盘文件缓存中拉取editslog......");
return fetchFromCurrentBuffer(syncedTxid);
} else {
String nextFlushedTxid = getNextFlushedTxid(flushedTxids, bufferedFlushedTxid);
if (nextFlushedTxid != null) {
System.out.println("上一次缓存的磁盘文件找不到要拉取的数据,从下一个磁盘文件中拉取editslog......");
return fetchFromFlushedFile(syncedTxid, nextFlushedTxid);
}
// 如果没有找到下一个文件,此时就需要从Edits Log缓冲区读取
else {
System.out.println("上一次缓存的磁盘文件找不到要拉取的数据,而且没有下一个磁盘文件,尝试从内存缓冲中拉取editslog......");
return fetchFromBufferedEditsLog(syncedTxid);
}
}
}
// 2.2.2 第一次尝试从磁盘读取
else {
List<String> result = null;
boolean fechedFromFlushedFile = false;
for (String flushedTxid : flushedTxids) {
// 如果要拉取的下一条数据就是在某个磁盘文件里
if (existInFlushedFile(syncedTxid, flushedTxid)) {
System.out.println("尝试从磁盘文件中拉取editslog,flushedTxid=" + flushedTxid);
result = fetchFromFlushedFile(syncedTxid, flushedTxid);
fechedFromFlushedFile = true;
break;
}
}
// 执行到这里,磁盘中没找到,说明你要拉取的txid已经比磁盘文件里的全部都新了,只能从Edits Log中去找
if (!fechedFromFlushedFile) {
System.out.println("所有磁盘文件都没找到要拉取的editslog,尝试直接从内存缓冲中拉取editslog......");
result = fetchFromBufferedEditsLog(syncedTxid);
}
return result;
}
}
}
/**
* 尝试从缓存中获取日志
*/
private List<String> fetchFromBufferedEditsLog(long syncedTxid) {
// fetchTxid表示当前要拉取的日志ID
long fetchTxid = syncedTxid + 1;
// 1.缓存中有数据
if (fetchTxid <= currentBufferedMaxTxid) {
System.out.println("尝试从内存缓冲拉取时,发现上一次内存缓存有数据可供拉取......");
return fetchFromCurrentBuffer(syncedTxid);
}
// 2.缓存中没有数据,从Edits Log加载到缓存
currentBufferedEditsLog.clear();
// 从Edits Log双缓冲区读取数据并缓存
String[] bufferedEditsLog = namesystem.getEditsLog().getBufferedEditsLog();
if (bufferedEditsLog != null) {
for (String editsLog : bufferedEditsLog) {
currentBufferedEditsLog.add(editsLog);
currentBufferedMaxTxid = JSONObject.parseObject(editsLog).getLongValue("txid");
}
bufferedFlushedTxid = null;
// 再次从缓存中读取
return fetchFromCurrentBuffer(syncedTxid);
}
return new ArrayList<String>(1);
}
/**
* 从缓存中读取edits log
*/
private List<String> fetchFromCurrentBuffer(long syncedTxid) {
List<String> result = new ArrayList<String>();
int fetchCount = 0;
long fetchTxid = syncedTxid + 1;
for (int i = 0; i < currentBufferedEditsLog.size(); i++) {
String log = currentBufferedEditsLog.get(i);
Long txid = JSON.parseObject(log).getLong("txid");
if (txid.equals(fetchTxid)) {
result.add(log);
fetchTxid++;
fetchCount++;
}
if (fetchCount == BACKUP_NODE_FETCH_SIZE) {
break;
}
}
return result;
}
/**
* 获取下一个磁盘文件对应的txid范围
*/
private String getNextFlushedTxid(List<String> flushedTxids, String bufferedFlushedTxid) {
for (int i = 0; i < flushedTxids.size(); i++) {
if (flushedTxids.get(i).equals(bufferedFlushedTxid)) {
if (i + 1 < flushedTxids.size()) {
return flushedTxids.get(i + 1);
}
}
}
return null;
}
/**
* 是否存在于刷到磁盘的文件中
*/
private Boolean existInFlushedFile(Long syncedTxid, String flushedTxid) {
String[] flushedTxidSplited = flushedTxid.split("_");
long startTxid = Long.valueOf(flushedTxidSplited[0]);
long endTxid = Long.valueOf(flushedTxidSplited[1]);
// fetchTxid表示当前要拉取的日志ID
long fetchTxid = syncedTxid + 1;
if (fetchTxid >= startTxid && fetchTxid <= endTxid) {
return true;
}
return false;
}
/**
* 从已经刷入磁盘的文件里读取edits log,同时缓存这个文件数据到内存
*/
private List<String> fetchFromFlushedFile(Long syncedTxid, String flushedTxid) {
try {
String[] flushedTxidSplited = flushedTxid.split("_");
long startTxid = Long.valueOf(flushedTxidSplited[0]);
long endTxid = Long.valueOf(flushedTxidSplited[1]);
String currentEditsLogFile = "C:\\Users\\ressmix\\Desktop\\edits-"
+ startTxid + "-" + endTxid + ".log";
List<String> editsLogs = Files.readAllLines(Paths.get(currentEditsLogFile), StandardCharsets.UTF_8);
currentBufferedEditsLog.clear();
for (String editsLog : editsLogs) {
currentBufferedEditsLog.add(editsLog);
currentBufferedMaxTxid = JSONObject.parseObject(editsLog).getLongValue("txid");
}
// 缓存了某个刷入磁盘文件的数据
bufferedFlushedTxid = flushedTxid;
return fetchFromCurrentBuffer(syncedTxid);
} catch (Exception e) {
e.printStackTrace();
}
return new ArrayList<>(1);
}
}
上面整个流程的第一步我这里专门解释下:Edits Log刷盘时会记录已刷入磁盘的txid的索引(DoubleBuffer中实现),这里用了一个CopyOnWriteArrayList来提升性能:
/**
* Edits Log双缓冲区
*/
public class DoubleBuffer {
// 已经刷入磁盘的txid范围
private List<String> flushedTxids = new CopyOnWriteArrayList<>();
/**
* 将syncBuffer缓冲区中的数据刷入磁盘
*/
public void flush() throws Exception {
syncBuffer.flush();
syncBuffer.clear();
}
/**
* 获取已经刷入磁盘的txid索引
*/
public List<String> getFlushedTxids() {
return flushedTxids;
}
/**
* 单块edits log缓冲区
*/
class EditLogBuffer {
/**
* 将当前缓存区的数据刷入磁盘
*/
public void flush() throws Exception {
byte[] data = buffer.toByteArray();
ByteBuffer dataBuffer = ByteBuffer.wrap(data);
// 这里可配置化,我直接写本地
String editsLogFilePath ="C:\\Users\\Ressmix\\Desktop\\editslog\\edits-" + startTxid +
"-" + endTxid + ".log";
flushedTxids.add(startTxid + "_" + endTxid);
//...
}
}
}
四、总结
本章,我对Edits Log的日志同步机制进行了讲解,BackupNode会不断发送RPC请求到NameNode拉取Edits Log,然后进行回放生成内存文件目录树。在设计edits log同步机制时,我们需要重点考虑pull模型、缓存、锁等方面的设计。
BackupNode生成内存文件目录树后,需要定期将目录树持久化到磁盘(fsimage快照),然后发送给NameNode,这样即使NameNode宕机了,也可以通过内存快照快速恢复数据。下一章,我就来讲解fsimage快照和checkpoint机制。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
