回答
I/O 模型决定了数据如何从输入源(如网络)传输到应用程序,或者如何从应用程序传输到输出目的地。在《UNIX网络编程》中,有 5 种 I/O 模型:
- 阻塞I/O模型
- 应用程序发起一个 I/O 操作后,将一直等待直到操作完成。在这个过程中,应用程序被阻塞,不能执行其他任务。
- 在简单应用中易于理解和实现,但是在高并发场景下效率较低,不推荐。
- 非阻塞I/O模型
- 应用程序发起一个 I/O 操作后不会被阻塞,而是立即返回一个状态。应用程序需要不断地检查这个 I/O 操作是否完成(通常通过轮询实现)。
- 需要应用程序不断轮询检查状态,增加 CPU 的负担。
- I/O复用模型
- 利用 select、poll、epoll 等机制,允许单个线程同时监视多个文件描述符(FD)。当某个 FD 准备就绪(可读、可写、异常等),相应的操作可以进行,无需阻塞等待其他 FD。
- 目前高并发网络编程中最常用的模型,可以有效地支持高并发场景。
- 信号驱动I/O模型
- 应用程序告诉内核启动一个操作,并让内核在 I/O 操作真正可执行时通过信号通知它。应用程序在等待信号时不被阻塞。
- 异步I/O模型
- 应用程序发起一个 I/O 操作后立即返回,继续执行其他任务。当 I/O 操作真正完成时,应用程序会收到一个通知。
- 理论上提高最高的性能,但是实现的复杂性比较高,而且并不是所有平台都能够有效地支持异步 I/O。
详解
操作系统为了能够以一种安全的方式持续运行,它是不允许应用程序随意地访问计算机硬件部分的,比如内存、硬盘、网卡等等。如果应用程序要访问硬件部分,不如读取磁盘上面的文件,就必须要通过操作系统提供的API来访问,以达到安全的访问控制。所以,I/O 对应用程序而言,强调的则是通过向内核发起系统调用完成对I/O的间接访问。图例如下:
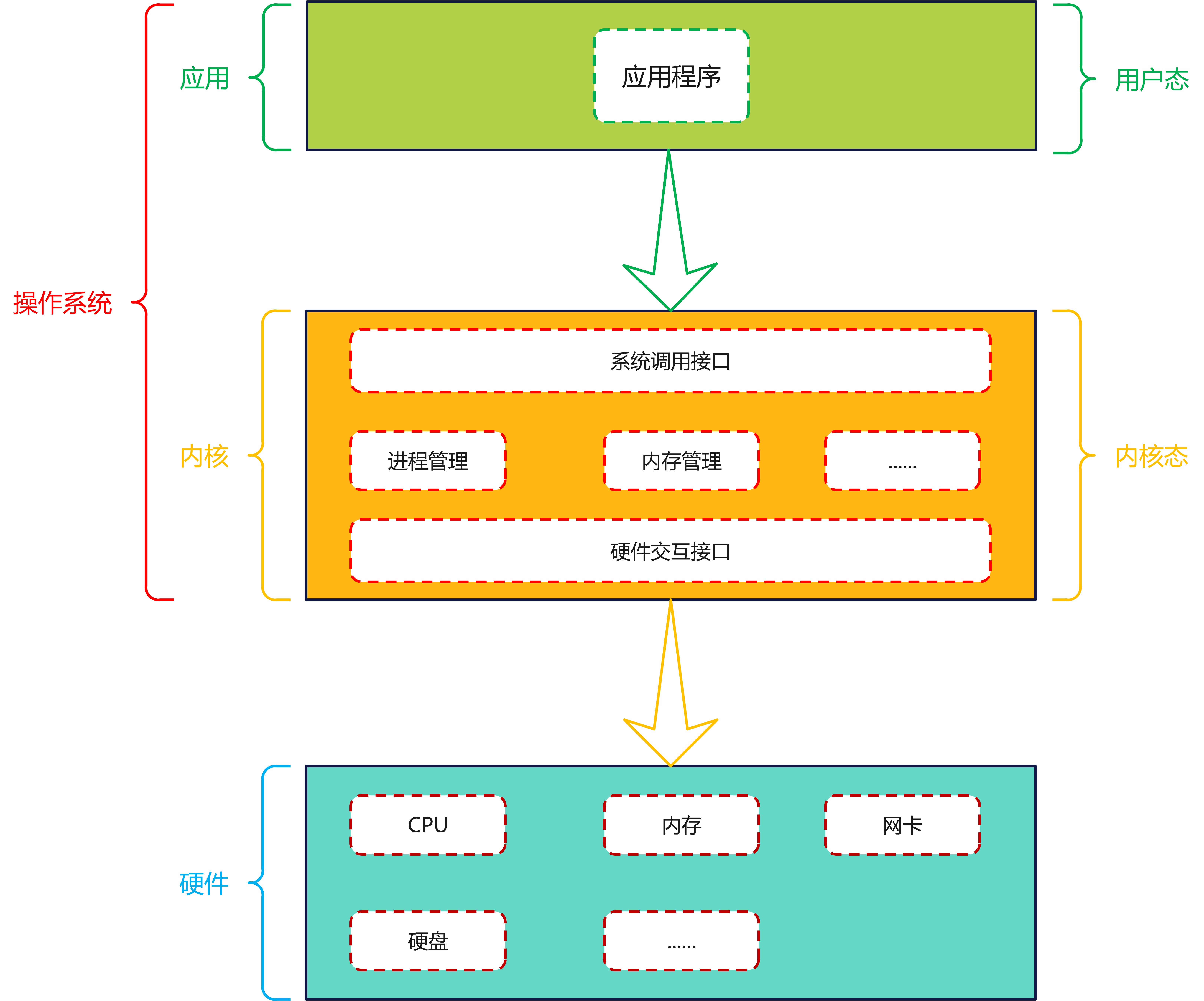
所以,应用程序发起一次IO访问是分为两个阶段的:
- IO 调用阶段:应用程序向内核发起系统调用。
- IO执行阶段:内核执行IO操作并返回。
- 数据准备阶段:内核等待IO设备准备好数据
- 数据拷贝阶段:将数据从内核缓冲区拷贝到用户空间缓冲区
在后面描述的阻塞与非阻塞都是基于这两个阶段
阻塞I/O模型
阻塞 I/O 是最基本、最传统的 I/O 模型。在该模型中,当应用程序发起一个 I/O 操作时,它将会一直等待操作系统完成这个操作。在这个等待过程中,应用程序被“阻塞”,即它不能执行其他任何任务或处理其他 I/O 请求,只能在这里干等着。模型图例:
应用程序发起一个系统调用(recvform),这个时候应用程序会一直阻塞下去,直到内核把数据准备好,并将其从内核复制到用户空间,复制完成后返回成功提示,这个时候应用程序才会继续处理数据。
所以,阻塞IO模型在IO两个阶段都会阻塞。
在 Java 中,传统的 I/O 操作(如 java.io.InputStream 和 java.io.OutputStream)是基于阻塞 I/O 模型的,当我们从 InputStream 读取数据或向 OutputStream 写入数据时,相关的方法调用会一直阻塞,直到操作完成。如下代码:
InputStream in = new FileInputStream("example.txt");
byte[] buffer = new byte[1024];
int bytesRead;
// 以下循环会在每次 read() 调用时阻塞,直到有数据可读
while ((bytesRead = in.read(buffer)) != -1) {
// 处理读取到的数据
}
in.close();
它的优点是简单且容易实现,但是它整个过程都是阻塞的,进程一直挂起,程序性能较为低,不适用并发大的应用。
场景:某天,你跟你女朋友(假如你有女朋友)去饭店吃饭,点完餐后,你就做坐那里一直等菜做好后,吃饱喝足才离开。这期间你和你女朋友由于担心不知道菜什么时候才能做好,所以这个期间你们就只能一直在座位上面等着,什么时候也不能干。
非阻塞 IO模型
非阻塞 I/O 模型,I/O 请求的调用会立即返回一个状态,而不是等到操作完全完成。程序继续运行,同时不断地“轮询”检查 I/O 操作是否已完成。图例如下:
应用程序发起recvform系统调用,如果数据报没有准备会则会立即返回一个EWOULDBLOCK错误码,进程并不需要进行等待。进程收到该错误后,判断内核数据还没有准备好,它还可以继续发送 recvform,如果数据报已经准备好了,待数据从内核拷贝到用户空间返回成功指示后,进程则可以处理数据报了。
非阻塞 I/O 模型不会阻塞程序的执行,但是它需要程序通过轮询的方式显示地检查 I/O 操作是否已完成,这个轮询的过程是需要消耗 CPU 资源的。该模型与阻塞 I/O 一样,实现稍微简单些,也不适用于高并发的业务场景。
在 Java NIO 中,它提供了非阻塞 I/O 的支持,如下:
ServerSocketChannel serverChannel = ServerSocketChannel.open();
// 非阻塞
serverChannel.configureBlocking(false);
场景:一个星期后,你跟你女朋友还是去那家餐厅吃饭,点完菜后,你女朋友吸取上次教训,知道要在这里干等,所以还不如去逛逛,买点香水口红啥的。但是呢,由于你们担心会错过上菜,所以你们就每隔一段时间就来问下服务员,你们的菜准备好了没有,来来回回好多回,若干次后,终于问到菜已经准备好了,然后你们就开心的吃起来。
I/O复用模型
在 I/O 复用模型中,应用程序使用一种机制(select、poll或epoll)来监测多个I/O通道,当至少一个I/O通道准备好进行I/O操作(如读取或写入)时,它就通知应用程序。图例如下:
多个进程的I/O注册到一个复用器(select)上,然后用一个进程监听该 select,select 会监听所有注册进来的I/O。如果内核的数据报没有准备好,select 调用进程会被阻塞,而当任一I/O在内核缓冲区中有数据,select调用就会返回可读条件,然后进程再进行recvform系统调用,内核将数据拷贝到用户空间,注意这个过程是阻塞的。
Java NIO 中的 Selector 是 Java NIO 的核心,它允许一个单独的线程监控多个通道的I/O事件。一个Selector实例可以同时检测多个通道上的数据可读、可写、连接就绪等事件。这就是I/O用的体现。
在实际的Java NIO 开发中,我们通常会创建一个Selector,并将多个SelectableChannel(例如SocketChannel)注册到这个选择器上。每个通道都会指定感兴趣的事件(如读、写、连接等)。然后,程序通过循环调用select()方法来检测哪些通道准备好了对应的事件。当select()方法返回后,程序会迭代已选择的键集(selected key set),并根据每个键(Key)的状态执行相应的IO操作。如下:
public class NioServerExample {
public static void main(String[] args) throws Exception {
// 创建Selector和ServerSocketChannel
Selector selector = Selector.open();
ServerSocketChannel serverSocket = ServerSocketChannel.open();
// 绑定端口,并设置为非阻塞模式
serverSocket.bind(new InetSocketAddress(8080));
serverSocket.configureBlocking(false);
// 将ServerSocketChannel注册到Selector,关注OP_ACCEPT事件
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
// 创建一个Buffer用于数据读取
ByteBuffer buffer = ByteBuffer.allocate(256);
while (true) {
// 阻塞等待需要处理的事件
selector.select();
// 获取所有接收事件的SelectionKey实例
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// 接受客户端连接
SocketChannel client = serverSocket.accept();
client.configureBlocking(false);
// 注册读事件
client.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
// 读取数据
//....
}
keyIterator.remove();
}
}
}
}
场景:还是那家餐厅,开始的时候,大家都是在那里等,服务员只需要等菜做好,端上来就可以了,某天有些小伙伴发现你跟你女朋友竟然利用等菜的空闲时间去逛街(虽然累,但好歹也买了几件东西对吧),然后他们也采用了这种方式,这个时候服务员就受不了了,你们隔一段时间就来问,隔一段时间就来问,烦都烦死了,于是他想了一个办法,说,你们派一个人来问就可以了,我这边做了由他来告诉你们菜是否已经做了好。
关于 I/O 多路复用,可以阅读这篇文章:请说下你对 Netty 中Reactor 模式的理解
信号驱动IO模型
模型图例如下:
在信号驱动IO模型中,应用程序首先会设置一个信号处理器。这就是在告诉操作系统,当 I/O 操作准备好执行时,操作系统应该向应用程序发送一个特定的信号。应用程序发起一个非阻塞的IO操作(调用 sigaction),非阻塞意味着立刻返回,所以应用程序发送完请求后就可以继续执行其他任务。
一旦 I/O 操作准备好后,操作就会向应用程序发送一个信号(SIGIO),应用程序预先定义的信号处理函数随后被调用。这个处理函数通常会执行实际的IO操作。
该模型在等待数据阶段是不会阻塞的,适用于高并发场景。但是它的模型比较复杂,实现起来有困难,同时不同操作系统对信号的处理可能有所不同,这可能会导致应用程序在不同系统间移植时遇到问题。
场景:有人帮你问,其实也不是那么好,因为你还是要等他来告诉你,而且他是只要你们当中有一个人的菜做好了就告诉你们所有人。于是,你们又想了一种方案,我点完菜后,我告诉服务员,我留我的微信在你这里,菜做好后,你告诉我就可以了。这样你女票就可以利用这个空余时间逛更久了。
异步IO模型
异步IO模型是一个完完全全的异步操作了。当应用程序发起一个 I/O 请求后,可以立即继续执行其他任务,而不需要等待IO操作的完成。当IO操作实际完成时,应用程序会收到通知。图例如下:
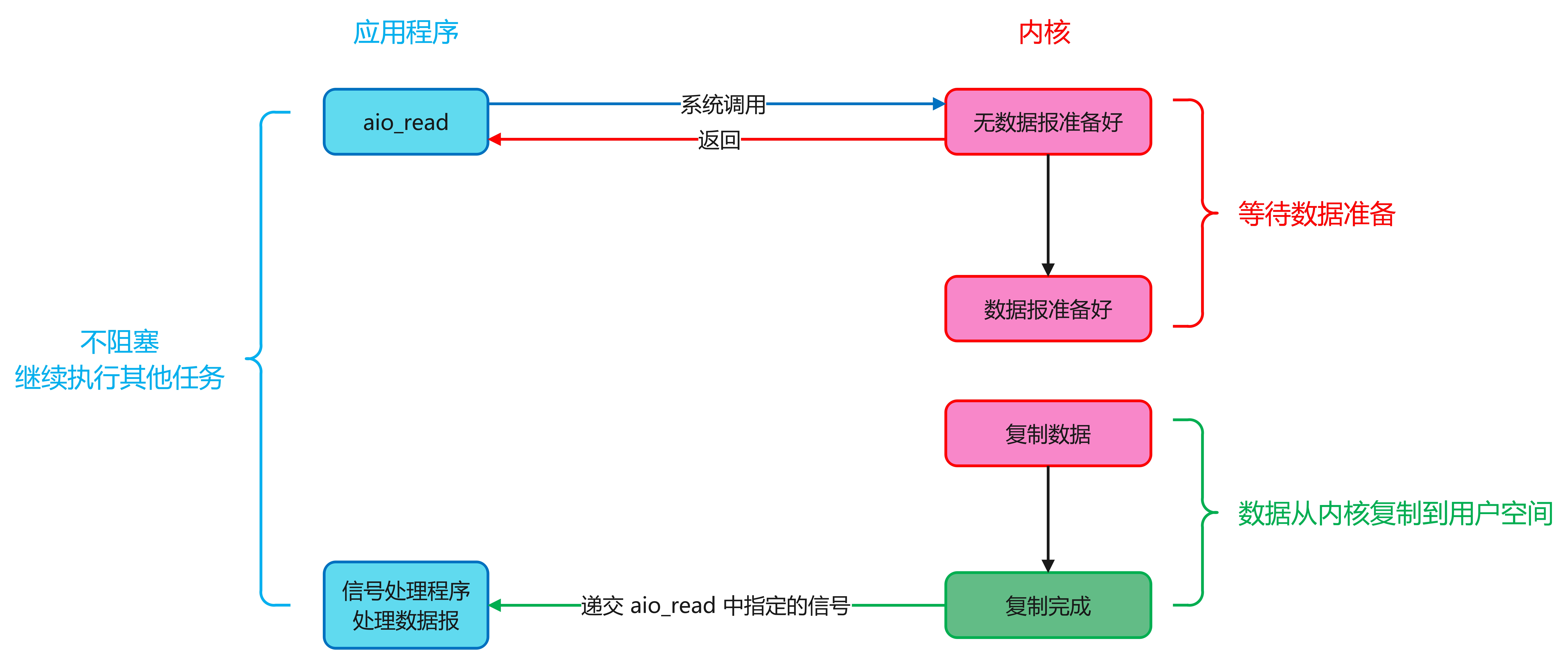
该模型整个过程完全异步,不阻塞,能够更好地利用系统资源,提供了程序的整体效率,但是它的模型复杂,实现难度大。
场景:虽然留电话的方式不错,你只需要留一个微信就可以了,瞬间解放了,后面你又发现了一个问题,你到了餐厅后,还不能立刻吃饭,因为他们还要上菜,这个过程你还是要等,如果你到店后立刻就可以吃难道不是更爽么?所以你服务员沟通说,你做好菜后,直接上,完成后再微信通知你,你到店后就直接吃了。这样你是不是更加爽了?
最后
五种IO模型,层层递进,一个比一个性能高,当然模型的复杂度也一个比一个复杂。最后用一张图来总结下:
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
