回答
主要是因为 MySQL 使用 B+ 树作为索引结构,当数据量较小时,B+ 树的的高度较低,查询时需要访问的节点较少,性能也就高些。当数据量增加到千万级别,B+ 树的高度就会增加,树的高度增加会导致每次查询需要访问更多的磁盘页,增加了磁盘 I/O 操作次数,导致查询性能下降。
扩展
MySQL 的 B+ 树高度计算
Mysql的默认存储引擎是InnoDB,InnoDB 将表的数据存储在数据页中,每个数据页的默认大小是 16KB。
B+树的叶子节点存的是数据,非叶子节点存的是键值+指针,索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中查找所需的数据。如下:
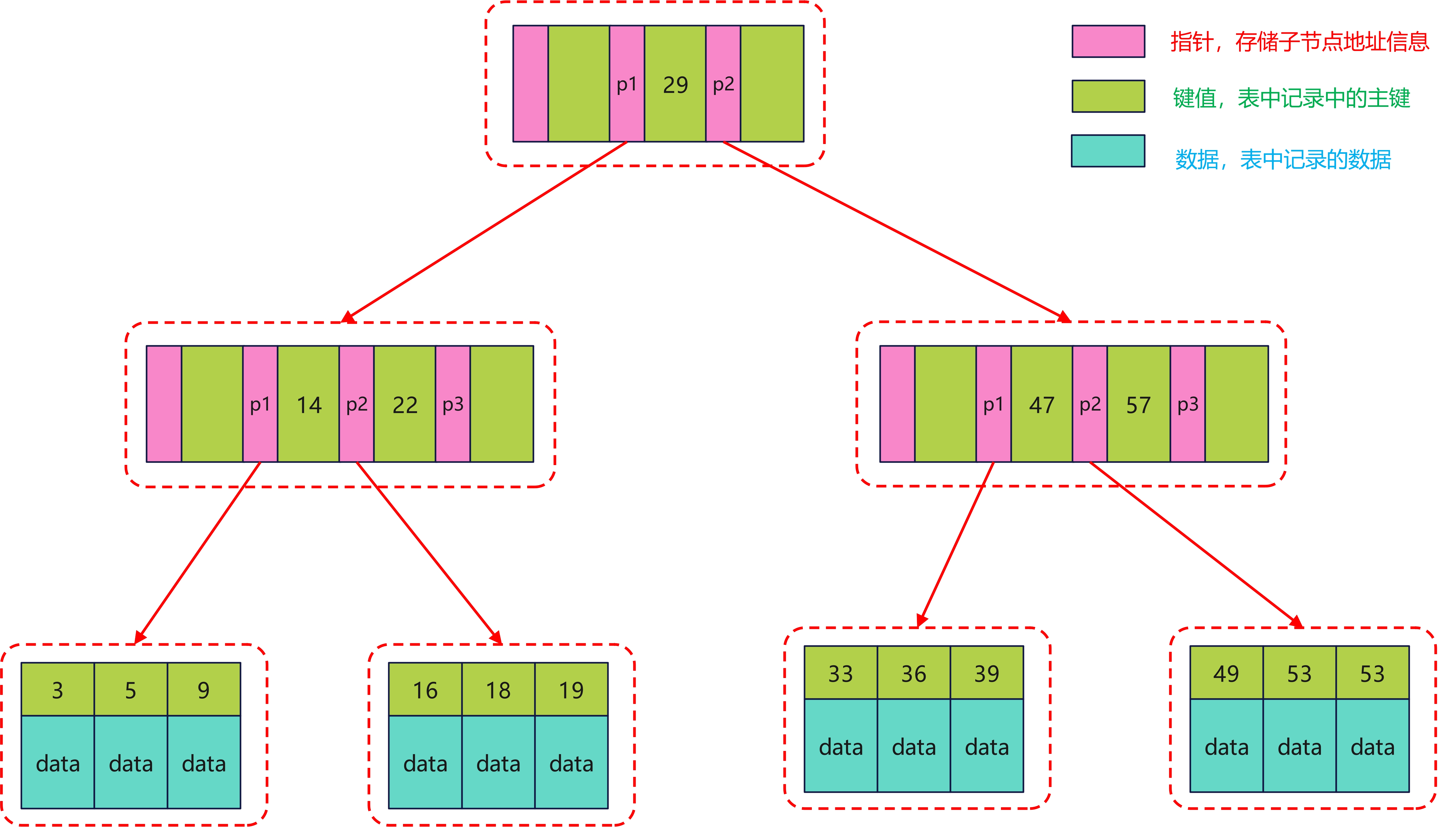
假设我们有一张表,其主键类型为 bigint(长度为 8 字节),在 InnoDB 中,指针的大小为 16 字节,所以非叶子节点能够存储的数据个数为 16KB / 14B = 1170,所以 2 层的话就能代表 1170 * 1170 个叶子页。
加入我们一行数据为 1KB,那么单个叶子页就能存储 16 条数据,所以:
- 一颗高度为 2 的 B+ 树,能够存储的数据为
1170 * 16 = 18720条数据 - 一颗高度为 3 的 B+ 树,能够存储的数据为
1170 * 1170 * 16 = 21902400条数据
所以,一个层数为 3 的B+ 树,大致可以存放 2000 万条数据。在一般情况下,B+树高度一般为 1-3 层,如果层数到达 4 层,或者超过 4 层,则在查询的时候会有更多的磁盘 IO 次数,会降低 MySQL 的性能。
当然,上面仅仅只是一个理论值,叶子节点数据的大小不同,会导致每页存储的数据量也不同,上面是 1KB,如果大小为 5KB 呢?,又或者远远小于 1KB 呢,这两种情况都会导致在第 3 层存储的数据两与 2000 万都不一样。
所以,我们在实际生产环境中不要生搬硬套,不一定偏要到了千万级别就去分库分表,又或者到了千万级别我们也不一定要去分库分表,都是根据实际情况来的,要灵活多变。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
