回答
Redis 大 key 问题是指某个 key 对应的 value 值很大(注意,不是 key 很大)。大 key 会导致 Redis 性能降低、数据倾斜以及主从同步等问题。一般来说我们应该杜绝大 key,如果遇到了我们就需要对其进行处理,处理过程分为这两个步骤:
- 发现大 key。比如利用
redis-cli --bigkeys或者Redis RDB Tools。 - 大 key 的治理方案一般分为两种:
- 可删除:使用 UNLINK 命令可以安全地删除大 key。
- 不可删除:不可删除的话就将大 key 拆分为多个小 key,或者对 value 进行压缩处理
详解
什么是大 key
首先大 key 不是 key 很大,而是 key 所对应的 value 很大。如果 value 超过某个阈值,那么此时存储这个 value 所对应的 key 就是大 key。
那 value 多大才算大 key 呢?这个阈值没有一个衡量的标准,需要根据具体场景来确定,比如有些场景及时 KB 是大 key,而有些场景需要几十 MB。
通常情况下,Redis 官方提到的大 key 阈值是基于经验值,例如:
- 对于列表、集合、有序集合、 哈希表,在超过 1 万个元素时被认为是大 key。
- 对于字符串,当它的大小达到几百 KB 时可能被认为是大 key。
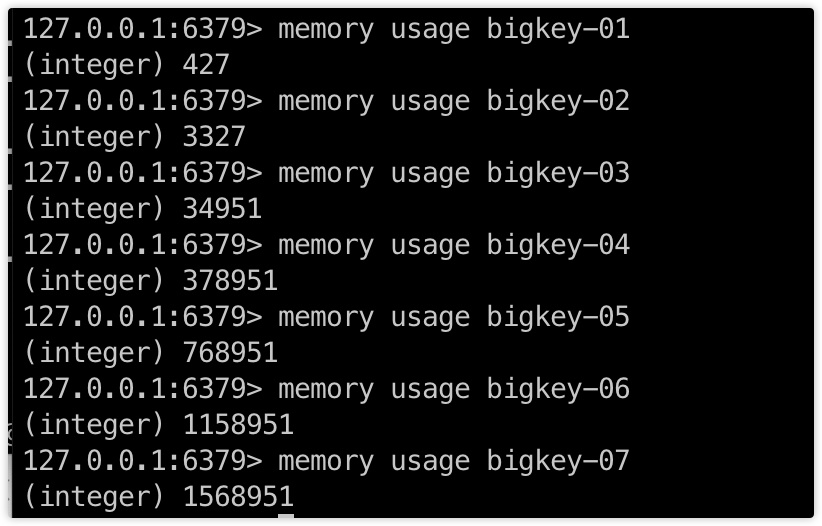
为了后面演示,我们通过程序向 Redis 中插入一批数据,表格如下:
- 字符串
| key | 数据量 |
|---|---|
| bigkey-01 | 30 个 "skjava" 拼接 |
| bigkey-02 | 300 个 "skjava" 拼接 |
| bigkey-03 | 3000 个 "skjava" 拼接 |
| bigkey-04 | 30000 个 "skjava" 拼接 |
| bigkey-05 | 60000个 "skjava" 拼接 |
| bigkey-06 | 90000 个 "skjava" 拼接 |
| bigkey-07 | 120000个 "skjava" 拼接 |
程序如下(数字各位小伙伴就去改下):
@Test
public void bigKeyTest() {
StringBuffer stringBuffer_01 = new StringBuffer();
for (int i = 0; i < 30 ; i++) {
stringBuffer_01.append("skjava-" + i + ";");
}
// 省略
StringBuffer stringBuffer_07 = new StringBuffer();
for (int i = 0; i < 120000 ; i++) {
stringBuffer_07.append("skjava-" + i + ";");
}
Jedis jedis = new Jedis("127.0.0.1",6379);
jedis.set("bigkey-01",stringBuffer_01.toString());
//...
jedis.set("bigkey-07",stringBuffer_07.toString());
}
各个 key 大小如下图:
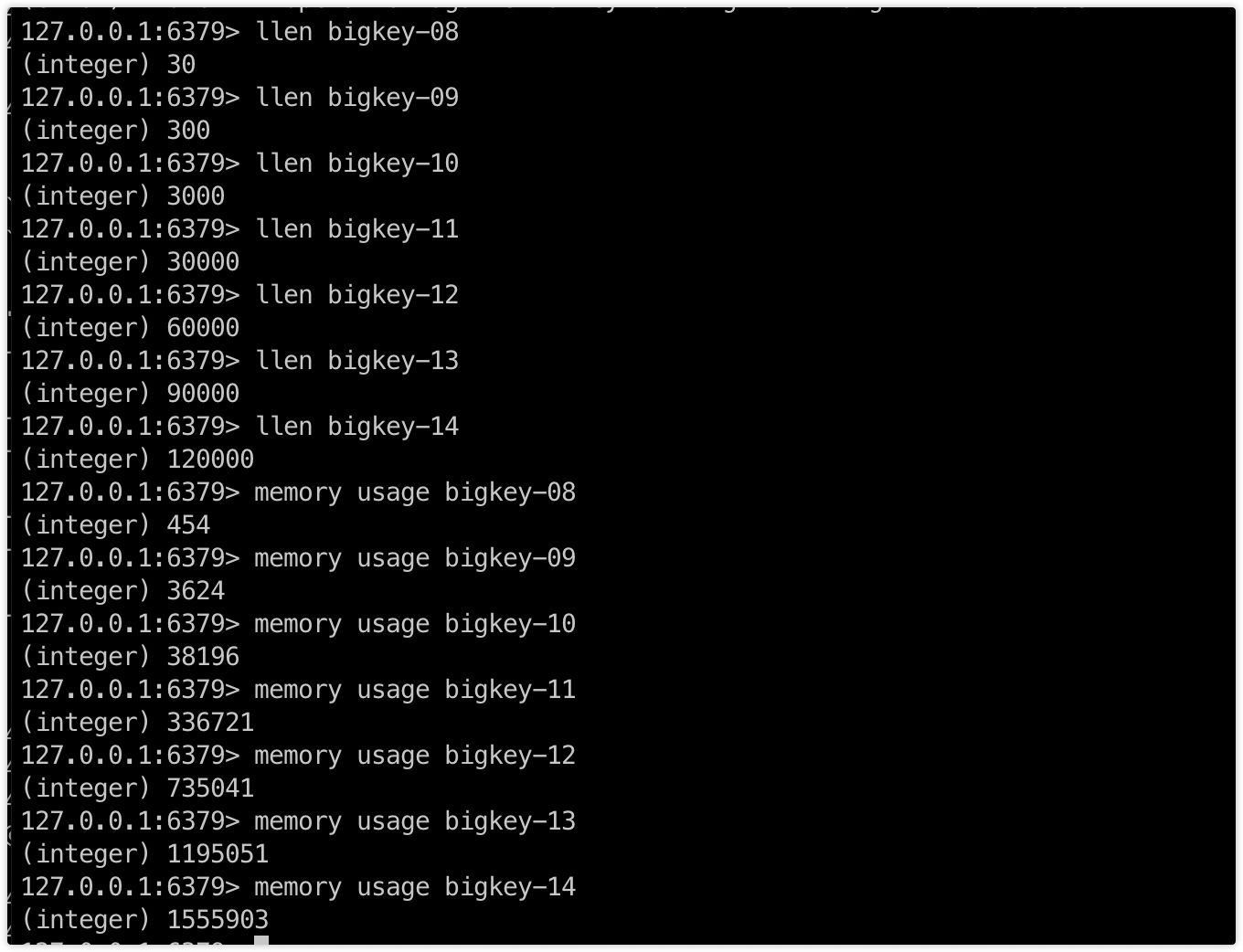
- 列表
| key | 数据量 |
|---|---|
| bigkey-08 | 30 个 "skjava" |
| bigkey-09 | 300 个 "skjava" |
| bigkey-10 | 3000 个 "skjava" |
| bigkey-11 | 30000 个 "skjava" |
| bigkey-12 | 60000个 "skjava" |
| bigkey-13 | 90000 个 "skjava" |
| bigkey-14 | 120000个 "skjava" |
代码
@Test
public void bigKeyTest() {
List<String> list_08 = new ArrayList<>();
for (int i = 0 ; i < 30 ; i++) {
list_08.add("skjava-" + i);
}
// ...
List<String> list_14 = new ArrayList<>();
for (int i = 0 ; i < 120000 ; i++) {
list_14.add("skjava-" + i);
}
Jedis jedis = new Jedis("127.0.0.1",6379);
jedis.lpush("bigkey-08", list_08.toArray(new String[list_08.size()]));
// ...
jedis.lpush("bigkey-14", list_14.toArray(new String[list_14.size()]));
}
列表长度及大小:
大 key 有什么危害
- 数据倾斜
大 key 所在的 Redis 服务器,会比其他 Redis 服务器占用更多的内存,这种数据倾斜的现象明显违背 Redis-Cluster 的设计思想。
- 占用内存过高
大 key 会占用更多的内存,可能会导致内存不足,甚至导致内存耗尽,Redis实例崩溃,影响系统的稳定性。
同时,频繁对大 key 进行修改可能会导致内存碎片化,进一步影响性能。
- 性能下降
大 key 会占用大量的内存,导致内存碎片增加,进而影响Redis的性能。同时,对大 key 的读写操作消耗的时间都会比较长,这会导致单个操作阻塞 Redis 服务器,影响整体性能。
尤其是执行像 HGETALL、SMEMBERS、ZRANGE、LRANGE 等命令时,如果操作的是大 key,可能会导致明显的延迟。
- 主从同步延迟
如果配置了主从同步,大 key 会导致主从同步延迟,由于大 key 占用的内存比较大,当主节点上的大 key 发生变化时,同步到从库时,会导致网络和处理上的延迟。
如何找到大 key
1、--bigkeys
在使用redis-cli命令链接 Redis 服务的时候,加上 --bigkeys 参数,就可以找出每种数据类型的最大 key 及其大小。
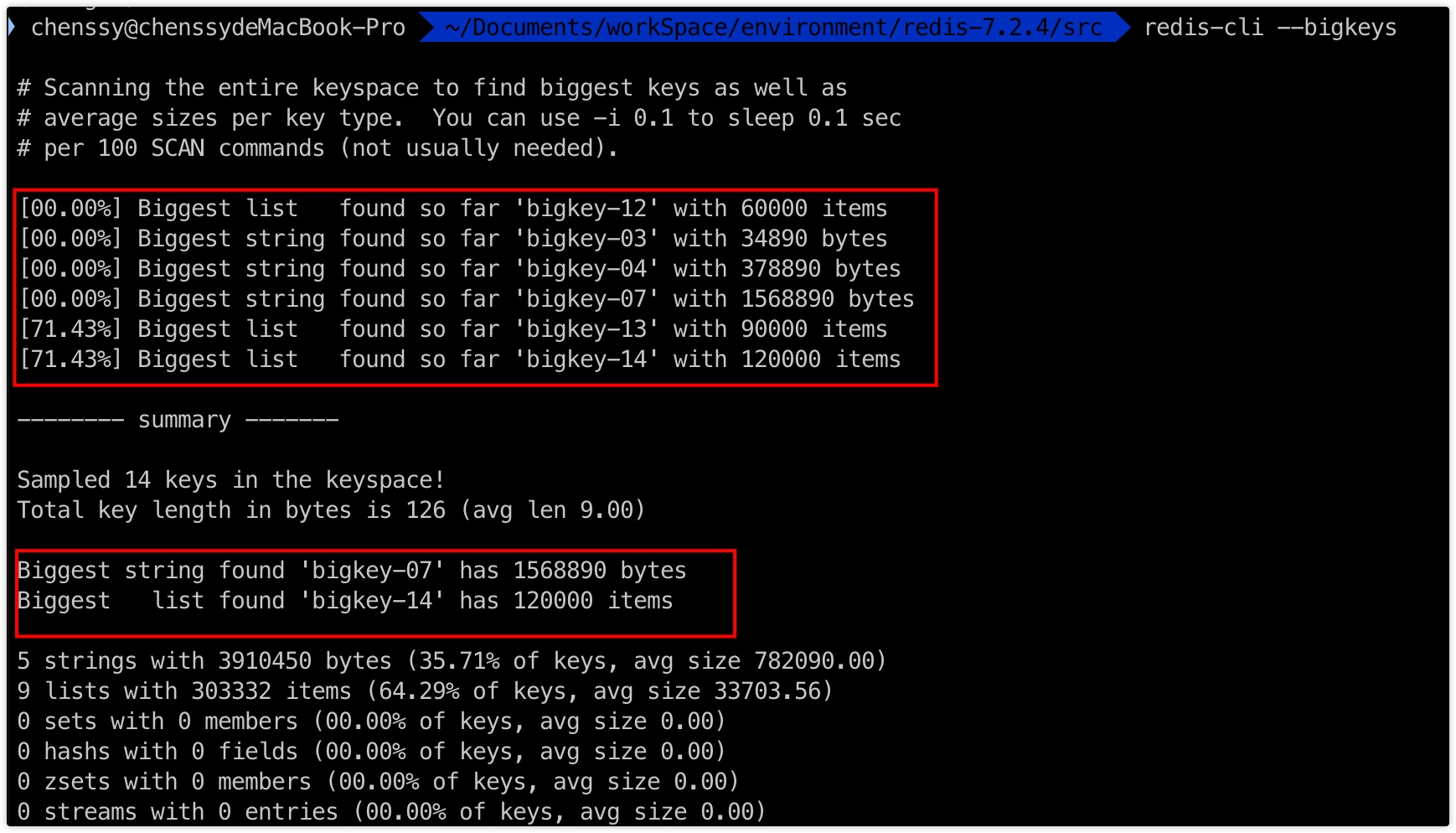
bigkeys 使用的是 SCAN 来迭代 Redis 中所有的 key,对于每种数据类型(字符串、列表、集合、有序集合、哈希表),它都会记录下占用最多内存的 key。但是该操作是资源密集型的,不建议直接在生产上面执行,建议在从节点或者低流量时段执行。
这种方式对集合类型来说不是特别友好,因为它只统计集合元素的多少,而不是实际占用内存,但是集合元素多,并不代表占用内存大。
2、SCAN命令
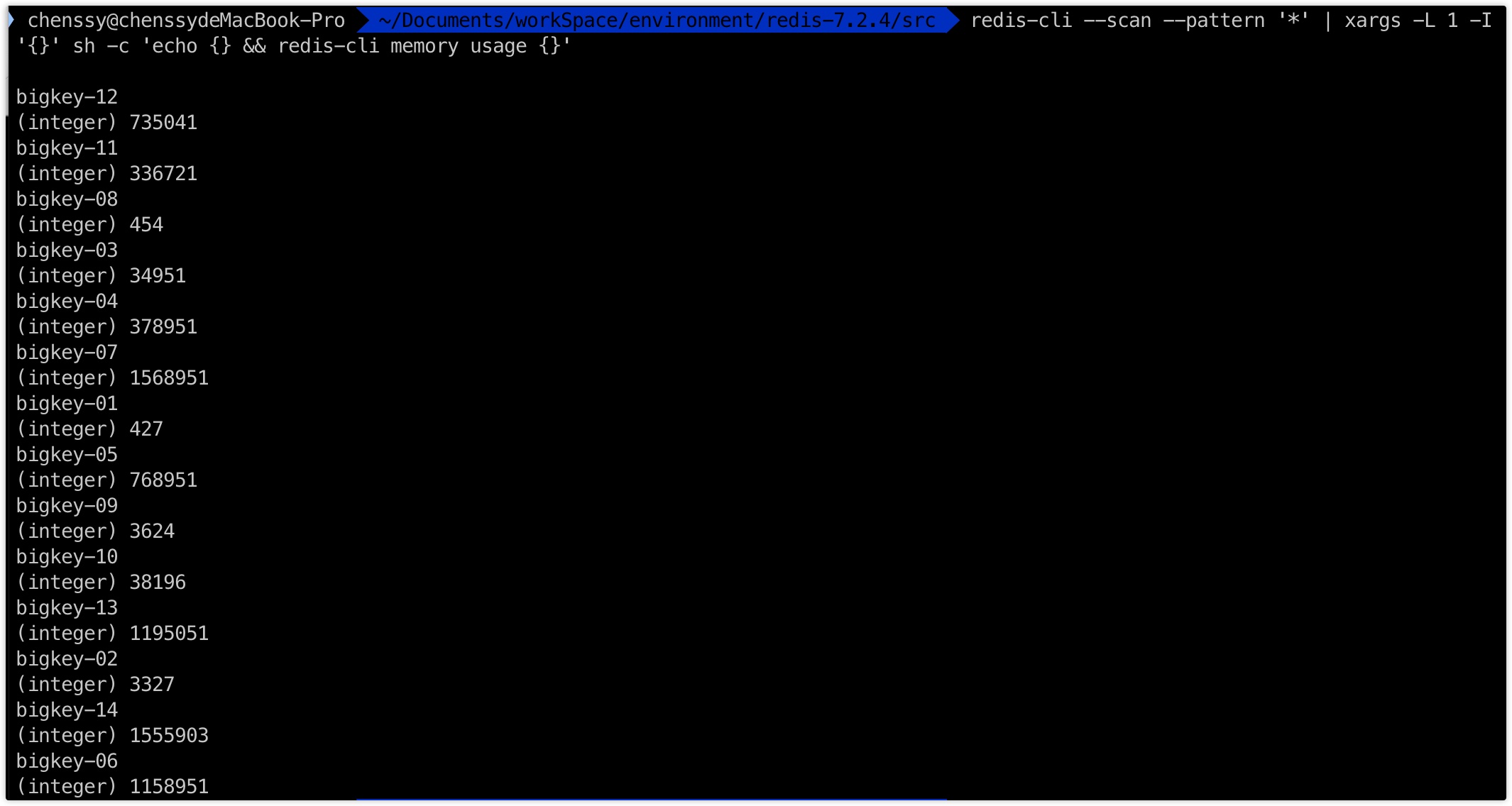
用 SCAN 命令结合 MEMORY USAGE。SCAN 可以迭代数据库中的 key,然后结合 MEMORY USAGE 命令检查每个 key 的大小。
redis-cli --scan --pattern '*' | xargs -L 1 -I '{}' sh -c 'echo {} && redis-cli memory usage {}'
这个命令会显示每个 key 的内存使用量:
redis-cli --scan --pattern '*':遍历所有的 key。xargs -L 1 -I '{}' sh -c 'echo {} && redis-cli memory usage {}':对于每个 key,首先打印 key 的名称(echo {}),然后打印其内存使用情况(redis-cli memory usage {})
3、Redis RDB Tools工具
RdbTools 是一个用于分析 Redis 数据库文件(.rdb 文件)的工具。它可以帮助我们理解 Redis 内存使用情况,找出大 key,并以此优化 Redis 实例。
例如,我们要找出占用内存最多的 5 个 key:
rdb --command memory --largest 5 dump.rdb

再如,获取字节数大于 10000 的 key:
rdb --command memory --bytes 10000 dump.rdb
关于Redis RDB Tools 的安装与使用:https://www.cnblogs.com/zyf98/p/15627047.html
如何处理大 key
如何处理大 key 呢?方案有如下两类:
1、可删除
如果这些大 key 可以删除,则我们可以使用 UNLINK 删除这些大 key。UNLINK 是异步的,不会像 DEL 命令一样会阻塞 Redis 服务,这种特性使得它比较适合大型的列表、集合、散列或有序集合的删除。
2、不可删除
对于不可删除的大 key,我们一般有两种方式出路:
- 分解。将大 key 拆分为多个小 key,降低单key的大小,读取可以用mget批量读取。
- 压缩。如果是 String 类型,我们可以采用压缩算法对其进行压缩处理。
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
