回答
在进行水平分库分表后,我们可能会将一个类型的数据拆分到了多个库中的多个表中去了,比如对于订单表 t_order,为了用户端能够更加方便地查询他的订单,我们一般都会选择用户 id(uid)作为分库分表的键。虽然它方便了用户端查询,但是他给商户端和运营端带来了麻烦(不考虑其他架构的情况下),比如查询分页如何做?假如我们要执行下面这条 SQL 语句:
select * from t_order order by id asc limit 10,5; // 查询第三页的5条数据
为了更好地演示和理解,我们只将 t_order 表拆分为两个表:t_order_1、t_order_2,各自数据如下:
t_order_1 |
t_order_2 |
| 1808407589769134080 | 1808407602666618880 |
| 1808407595582439424 | 1808407608643502080 |
| 1808407623713636352 | 1808407616797229056 |
| 1808407629212368896 | 1808407635197640704 |
| 1808407641526845440 | 1808407642197934080 |
| 1808407645444325376 | 1808407658048208896 |
| 1808407652004216832 | 1808407658798989312 |
| 1808407653170233344 | 1808407661168771072 |
| 1808407672749244416 | 1808407666906578944 |
| 1808407687907459072 | 1808407680739393536 |
| 1808409387955322880 | 1808409393256923136 |
| 1808409394531991552 | 1808409401561645056 |
| 1808409420905775104 | 1808409409736343552 |
| 1808409428212252672 | 1808409413590908928 |
| 1808409435694891008 | 1808409439926943744 |
| 1808409437720739840 | 1808409445203378176 |
| 1808409458457378816 | 1808409451092180992 |
| 1808409459241713664 | 1808409462760734720 |
| 1808409470683774976 | 1808409471371640832 |
| 1808409479642808320 | 1808409478191579136 |
对于这样的数据,我们期望得到的数据为:
1808407645444325376
1808407652004216832
1808407653170233344
1808407658048208896
1808407658798989312
那要怎样才能得到这样的 5 条数据呢?目前有如下三种方案。
1、全局查询法
我们将上面 SQL 语句在 t_order_1、t_order_2 中分别执行:
select * from t_order_1 order by id asc limit 10,5;
select * from t_order_2 order by id asc limit 10,5;
得到的结果分别为:
-- t_order_1
1808409387955322880
1808409394531991552
1808409420905775104
1808409428212252672
1808409435694891008
-- t_order_2
1808409393256923136
1808409401561645056
1808409409736343552
1808409413590908928
1808409439926943744
你会发现结果集肯定是不对的。因为我们的结果是站在全局的角度去看的,而我们执行的 SQL 是单表的角度,从全局角度上看,这两张表都失去了全局视野。所以,不管我们从哪个表里面查询第三页的数据,都不一定是全局排序的第3页数据,所以我们需要拿到 t_order_1 和 t_order_2 中的前三页数据,然后在内存中进行排序提取。所以,SQL 脚本应该是:
select * from t_order_1 order by id asc limit 0,15;
select * from t_order_2 order by id asc limit 0,15;
得到前三页的数据后,我们再在代码中排序、提炼:
List table1List = getTable1List();
List table2List = getTable2List();
table1List.add(table2List);
table2List.stream()
.sorted(createTime) // 排序
.skip(10)
.limit(5) // 提炼第三页数据
.collect(Collectors.toList())
这种方案虽然可以解决问题且方案也足够简单,但是它有一个致命的问题,那就是分页的页码不能很多,如果我们要查询第 10000 页数据,那两个数据库都要返回 50000 万条数据过来,极大地增加了网络传输量,也占用了应用程序的内存。同时,应用程序也需要进行二次排序和提炼,消耗了 CPU。而且这种情况是随着表、页码的增加会成倍数地降低系统性能。
故而,这种方案一般不推荐。
2、禁止跳页查询法
全局查询法是把前面页码所有的数据都拿到内存中来统一处理,这样就会导致处理的数据量很大。遇到这种情况,我们可以使用禁止跳页查询,即在查询页面我们只提供[下一页]、[上一页],当然这种方案是一种妥协、折中的方案,但是它却能极大的降低业务复杂度。比如上例,第一页的数据为:
1808407589769134080
1808407595582439424
1808407602666618880
1808407608643502080
1808407616797229056
那么当我们点击下一页的时候,我们需要将上一页的最大值作为查询条件传递给后端,这个时候 SQL 语句转化为下面的:
select * from t_order_1 where id > 1808407616797229056 order by id asc limit 5;
select * from t_order_2 where id > 1808407616797229056 order by id asc limit 5;
这个时候我们可以得到如下数据:
-- t_order_1
1808407623713636352
1808407629212368896
1808407641526845440
1808407645444325376
1808407652004216832
-- t_order_1
1808407635197640704
1808407642197934080
1808407658048208896
1808407658798989312
1808407661168771072
拿到数据后,同样是在应用程序里面排序、提炼 5 条数据出来。
这种方案与全局查询法是一样的,但是它每次每个表都只需要返回一个页的数据,这会极大地降低了网络带宽、CPU 和内存资源。但是,它的不方便之处就在于它无法跳页,只能一页一页地点击,当然,在实际业务过程中,这种方案也是可以妥协的,如果业务实在是不同意那就没办法了。
3、二次查询法
PS:此方案有一个前提,数据分布均匀!!!
上面这两种方案或多或少都有一点缺点,那有没有什么方案即可以满足业务需要跳页,性能又高的方案呢?终极武器:二次查询法。
为了更好地理解,我们增加 t_order_3 表,3 张整体数据如下:
t_order_1 |
t_order_2 |
t_order_3 |
|---|---|---|
| 1808407589769134080 | 1808407602666618880 | 1808407620544475276 |
| 1808407595582439424 | 1808407608643502080 | 1808407707121622358 |
| 1808407623713636352 | 1808407616797229056 | 1808407707358625415 |
| 1808407629212368896 | 1808407635197640704 | 1808407824312069931 |
| 1808407641526845440 | 1808407642197934080 | 1808407941207151148 |
| 1808407645444325376 | 1808407658048208896 | 1808408002825739943 |
| 1808407652004216832 | 1808407658798989312 | 1808408070646169155 |
| 1808407653170233344 | 1808407661168771072 | 1808408081824152101 |
| 1808407672749244416 | 1808407666906578944 | 1808408247557764341 |
| 1808407687907459072 | 1808407680739393536 | 1808408333079986889 |
| 1808409387955322880 | 1808409393256923136 | 1808408416187362193 |
| 1808409394531991552 | 1808409401561645056 | 1808408440395460190 |
| 1808409420905775104 | 1808409409736343552 | 1808408546442273362 |
| 1808409428212252672 | 1808409413590908928 | 1808408653688731020 |
| 1808409435694891008 | 1808409439926943744 | 1808408655733976809 |
| 1808409437720739840 | 1808409445203378176 | 1808408773219311211 |
| 1808409458457378816 | 1808409451092180992 | 1808408937585864682 |
| 1808409459241713664 | 1808409462760734720 | 1808409228263489230 |
| 1808409470683774976 | 1808409471371640832 | 1808409302566298654 |
| 1808409479642808320 | 1808409478191579136 | 1808409342782953414 |
如果我们要查询第 101 页数,则 SQL 语句如下:
select * from t_order_1 order by id asc limit 500,5;
第一步:改写 SQL
将上面的 SQL 改写为下面 SQL:
select * from t_order_1 order by id asc limit 166,5;
这个 166 是怎么的来的呢?原先的 offset 是 500,我们称它为全局 offset,那 166 是如何计算来的呢?它等于全局 offset / 分表个数,即 500 / 3 = 166。
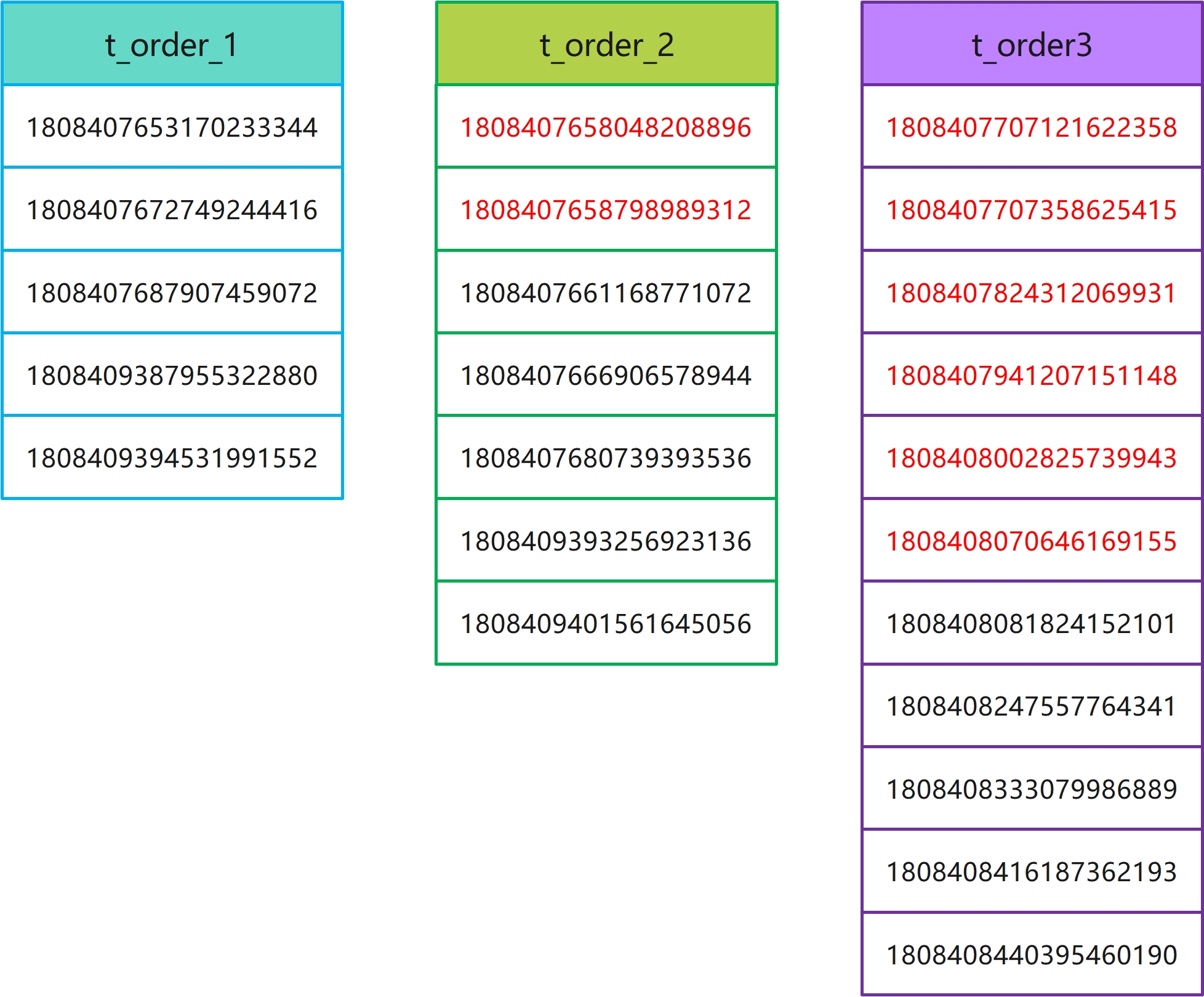
假如上面改写 SQL 在三张表里执行结果如下图:

第二步:拿到返回结果数据中的最小值
t_order_1表中的最小值:1808407653170233344
t_order_2表中的最小值:1808407661168771072
t_order_3表中的最小值:1808407824312069931
三个表中最小值为 t_order_1 中的 1808407653170233344。
第三步:第二次改写 SQL
第二次改写 SQL,则是使用 between语句。between语句的小值为第二步中的最小值,这里是 1808407653170233344,然后大值为第一步中结果集中的最大值。
所以,第二次的改写 SQL 如下:
-- t_order_1
select * from t_order_1 where id between 1808407653170233344 and 1808409394531991552 order by id;
-- t_order_2
select * from t_order_1 where id between 1808407653170233344 and 1808409394531991552 order by id;
-- t_order_3
select * from t_order_1 where id between 1808407653170233344 and 1808409394531991552 order by id;
由于第二次改写 SQL 的查询条件放宽了,所以查询的数据相对第一次会多些,结果为:
第四步:在每个结果集中虚拟一个 id_min 记录,找到 id_min 在全局的 offset
在第三步的结果集中,我们需要新一个 id_min 的记录出来,然后往前推算最小记录的 offset,如下:
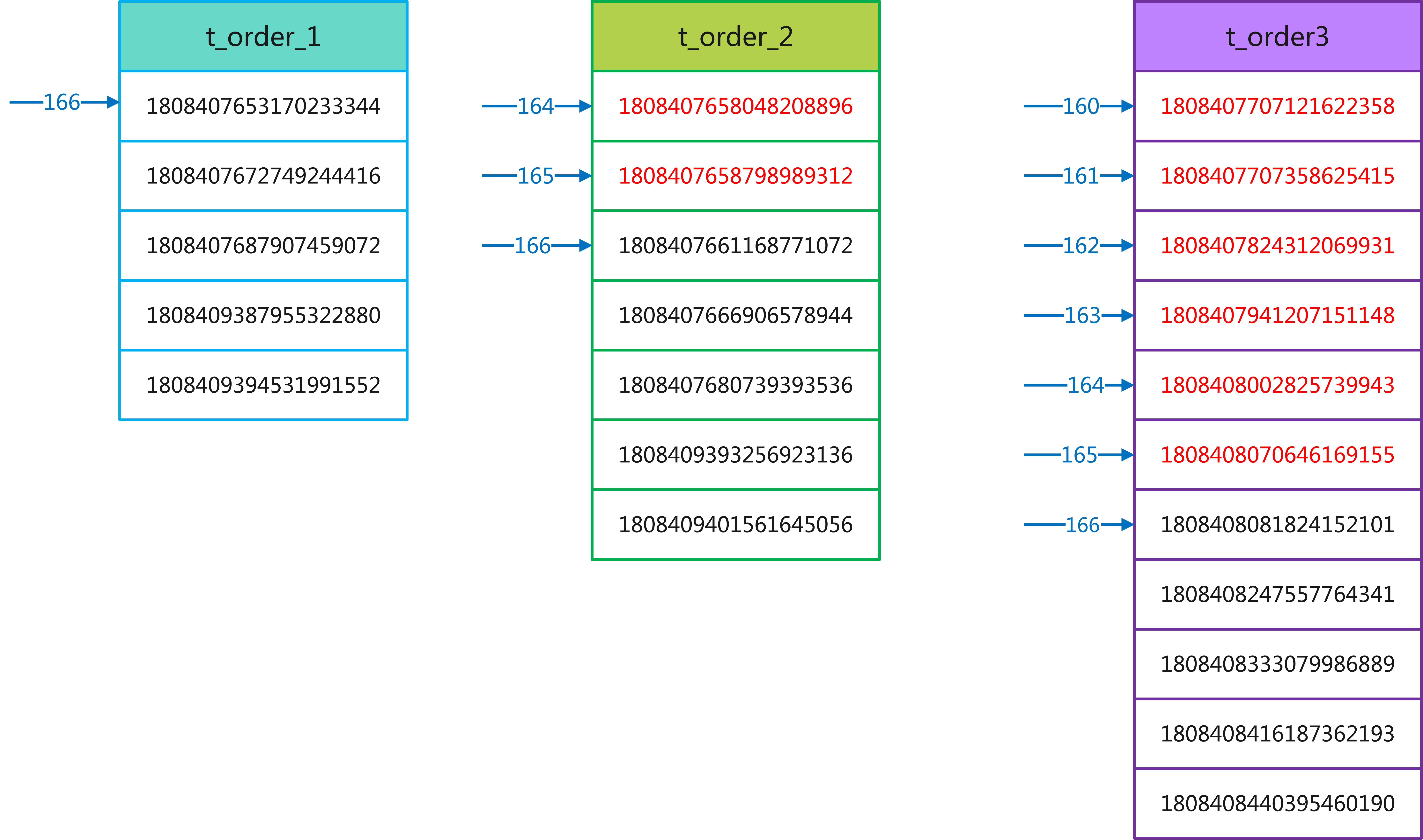
t_order_1,id_min为1808407653170233344,offset为166t_order_2,id_min为1808407658048208896,offset为164t_order_3,id_min为1808407707121622358,offset为160
综上,上述 id_min 的全局 offset = 166 + 164 + 160 = 490。
第五步:根据第四步得到的全局 offset 和 第二次改写得到的数据获取结果集
第四步难道全局 offset 后,我们就有了全局视野,这个时候我们把第二次改写 SQL 的结果集重新排序,拿 limit 500,5 的数据,如下:
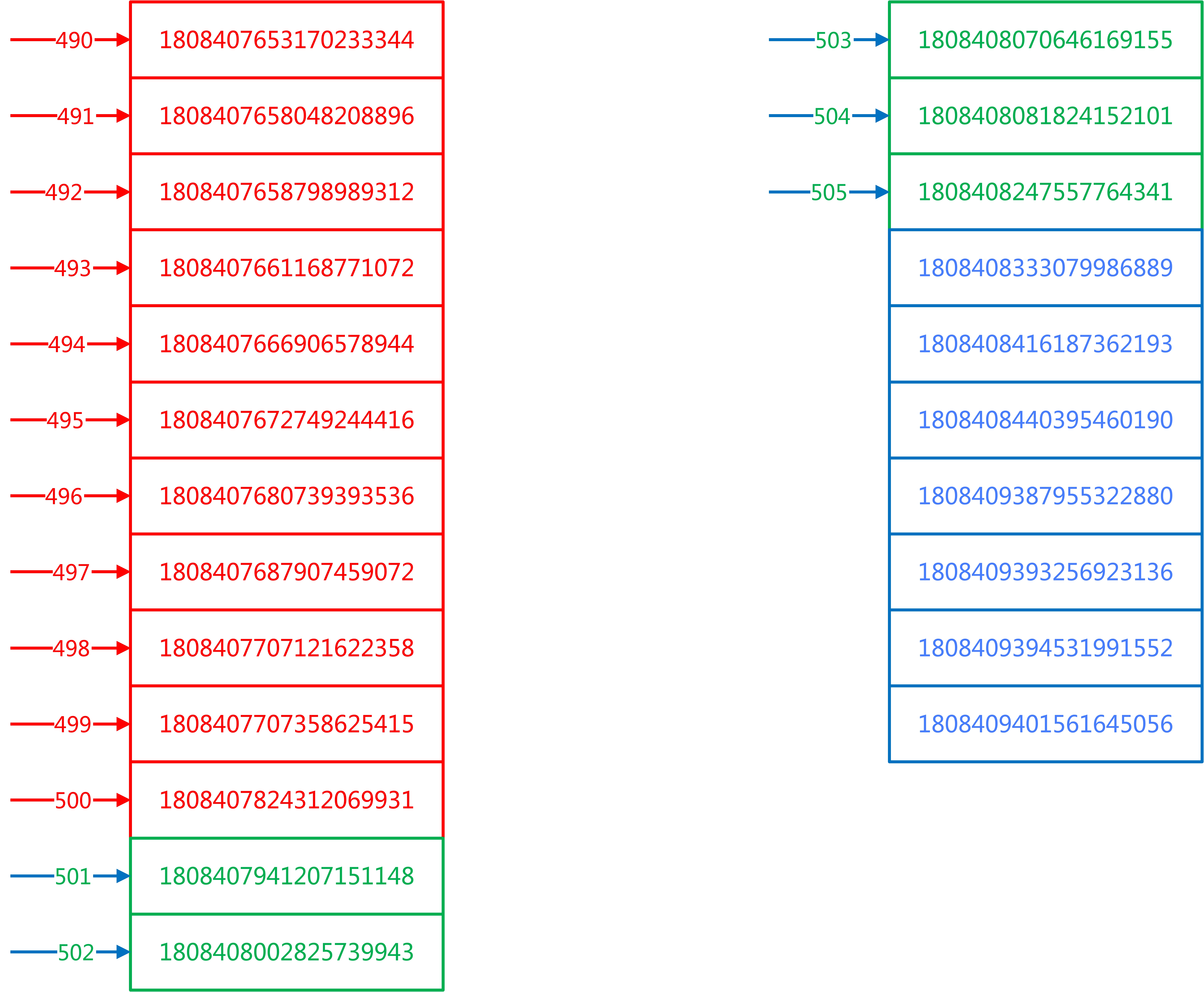
绿色部分就是我们需要的数据。
这种方案能够得到精确的业务,每次查询的数据量也不是很大,性能较高。但是它需要查询两次。而且这种方案有一个前提就是它数据的分布是比较均衡的,否则是无法查询到精确的数据的。
4、终极方案
- 比如把分页查询的数据提前聚合到 ES 中,分页查询直接在 ES 中查询就可以了
- 搭建数据中心,将所有子库数据的数据全部汇聚到数据中心,后面所有的分页数据全部都从数据中获取
Java 面试宝典是大明哥全力打造的 Java 精品面试题,它是一份靠谱、强大、详细、经典的 Java 后端面试宝典。它不仅仅只是一道道面试题,而是一套完整的 Java 知识体系,一套你 Java 知识点的扫盲贴。
它的内容包括:
- 大厂真题:Java 面试宝典里面的题目都是最近几年的高频的大厂面试真题。
- 原创内容:Java 面试宝典内容全部都是大明哥原创,内容全面且通俗易懂,回答部分可以直接作为面试回答内容。
- 持续更新:一次购买,永久有效。大明哥会持续更新 3+ 年,累计更新 1000+,宝典会不断迭代更新,保证最新、最全面。
- 覆盖全面:本宝典累计更新 1000+,从 Java 入门到 Java 架构的高频面试题,实现 360° 全覆盖。
- 不止面试:内容包含面试题解析、内容详解、知识扩展,它不仅仅只是一份面试题,更是一套完整的 Java 知识体系。
- 宝典详情:https://www.yuque.com/chenssy/sike-java/xvlo920axlp7sf4k
- 宝典总览:https://www.yuque.com/chenssy/sike-java/yogsehzntzgp4ly1
- 宝典进展:https://www.yuque.com/chenssy/sike-java/en9ned7loo47z5aw
目前 Java 面试宝典累计更新 400+ 道,总字数 42w+。大明哥还在持续更新中,下图是大明哥在 2024-12 月份的更新情况:

想了解详情的小伙伴,扫描下面二维码加大明哥微信【daming091】咨询

同时,大明哥也整理一套目前市面最常见的热点面试题。微信搜[大明哥聊 Java]或扫描下方二维码关注大明哥的原创公众号[大明哥聊 Java] ,回复【面试题】 即可免费领取。
