微服务架构的雪崩效应
什么是微服务中的雪崩效应?
首先介绍两个概念:扇入和扇出。
对于微服务中某个服务来说,调用它的服务请求称为扇入,它调用其它服务的请求称为扇出。
微服务中,⼀个请求可能需要多个微服务接口才能实现,会形成复杂的调用链路。这就带来⼀个问题,假设微服务A调⽤微服务B和微服务C,微服务B和微服务C⼜调⽤其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调⽤响应时间过⻓或者不可⽤,对微服务A的调⽤就会占⽤越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。
雪崩效应的解决方案
服务熔断
熔断机制是应对雪崩效应的⼀种微服务链路保护机制。当扇出链路的某个微服务不可⽤或者响应时间太⻓时,熔断该节点微服务的调⽤,进⾏服务的降级,快速返回错误的响应信息。当检测到该节点微服务调⽤响应正常后,恢复调⽤链路。【通常与服务降级一起使用】
服务降级
服务降级是从系统整体考虑,当某个服务熔断之后,服务器不再被调⽤时,客户端可以为发送的请求准备⼀个本地的fallback回调,返回⼀个与方法返回值类型相同的缺省值,这样做,虽然服务水平下降,但整体仍然可用,比直接熔断要好。
服务限流
当服务为系统的核心功能,不能使用熔断与降级降低服务时,可以使用服务限流。
限流措施也很多,如:
- 限制总并发数(比如数据库连接池、线程池)
- 限制瞬时并发数(如nginx限制瞬时并发连接数)
- 限制时间窗⼝内的平均速率(如Guava的RateLimiter、nginx的limit_req模块,限制每秒的平均速率)
- 限制远程接⼝调⽤速率、限制MQ的消费速率等
Hystrix介绍
Hystrix(豪猪--->身上很多刺--->保护自己),宣⾔“defend your app”,是由Netflflix开源的⼀个延迟和容错库,⽤于隔离访问远程系统、服务或者第三⽅库,防⽌级联失败,从而提升系统的可⽤性与容错性。
Hystrix主要通过以下几点实现延迟和容错。
-
包裹请求:使⽤HystrixCommand包裹对依赖的调⽤逻辑。 ⾃动投递微服务⽅法(@HystrixCommand 添加Hystrix控制) ——调⽤简历微服务跳闸机制:当某服务的错误率超过⼀定的阈值时,Hystrix可以跳闸,停⽌请求该服务⼀段时间。
-
资源隔离:Hystrix为每个依赖都维护了⼀个⼩型的线程池(舱壁模式)(或者信号量)。如果该线程池已满, 发往该依赖的请求就被⽴即拒绝,⽽不是排队等待,从⽽加速失败判定。
-
监控:Hystrix可以近乎实时地监控运⾏指标和配置的变化,例如成功、失败、超时、以及被拒绝 的请求等。
-
回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执⾏回退逻辑。回退逻辑由开发⼈员 ⾃⾏提供,例如返回⼀个缺省值。
-
⾃我修复:断路器打开⼀段时间后,会⾃动进⼊“半开”状态。
Hystrix的设计理念
- Give protection from and control over latency and failure from dependencies accessed (typically over the network) via third-party client libraries.
- 给依赖于第三方库的应用程序提供给保护
- Stop cascading failures in a complex distributed system.
- 在复杂的分布式系统当中避免级联失败
- Fail fast and rapidly recover.
- 快速失败并且快速恢复
- Fallback and gracefully degrade when possible.
- 在可能的情况下提供回退和优雅降级的能力
- Enable near real-time monitoring, alerting, and operational control.
- 通过近乎实时的指标,监控和警报来优化发现故障的时间。
Hystrix-隔离
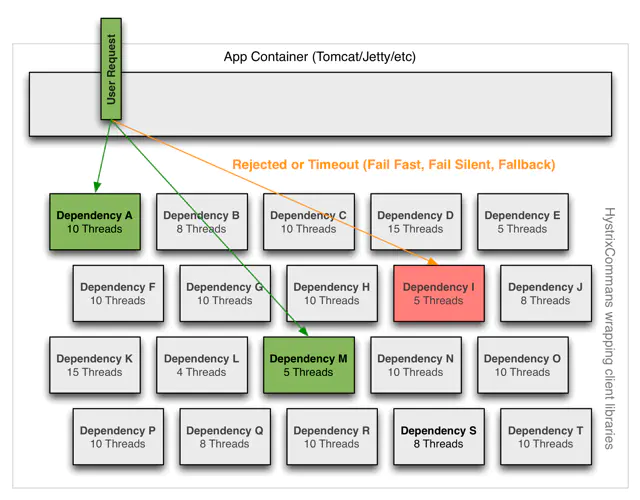
Hystrix的隔离主要是为每个依赖组件提供一个隔离的线程环境,提供两种模式的隔离:
- 线程池隔离模式:使用一个线程池来存储当前的请求,线程池对请求作处理,设置任务返回处理超时时间,堆积的请求堆积入线程池队列。这种方式需要为每个依赖的服务申请线程池,有一定的资源消耗,好处是可以应对突发流量(流量洪峰来临时,处理不完可将数据存储到线程池队里慢慢处理)
- 信号量隔离模式:使用一个原子计数器(或信号量)来记录当前有多少个线程在运行,请求来先判断计数器的数值,若超过设置的最大线程个数则丢弃改类型的新请求,若不超过则执行计数操作请求来计数器+1,请求返回计数器-1。这种方式是严格的控制线程且立即返回模式,无法应对突发流量(流量洪峰来临时,处理的线程超过数量,其他的请求会直接返回,不继续去请求依赖的服务)
| 线程池隔离 | 信号量隔离 | |
|---|---|---|
| 线程 | 与调用线程不相同线程 | 与调用线程相同 |
| 开销 | 排队、调度、上下文开销等 | 无线程切换,开销低 |
| 异步 | 支持 | 不支持 |
| 并发支持 | 支持(最大线程池大小) | 支持(最大信号量上限) |
Hystrix-熔断器

ystrix的熔断器其实可以理解为就是一个统计中心,统计一定时间窗口内访问次数,成功次数,失败次数等数值判定是否发生熔断。
发生电路熔断的过程如下:
- 假设电路上的音量达到一定阈值(HystrixCommandProperties.circuitBreakerRequestVolumeThreshold)
- 并假设错误百分比超过阈值错误百分比(HystrixCommandProperties.circuitBreakerErrorThresholdPercentage)
- 然后断路器从CLOSED转换到OPEN。
- 它是开放的,它使所有针对该断路器的请求短路。
- 经过一段时间(HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds),下一个单个请求是通过(这是HALF-OPEN状态)。 如果请求失败,断路器将在睡眠窗口持续时间内返回到OPEN状态。 如果请求成功,断路器将转换到CLOSED,逻辑1.重新接管。
Hystrix工作流程
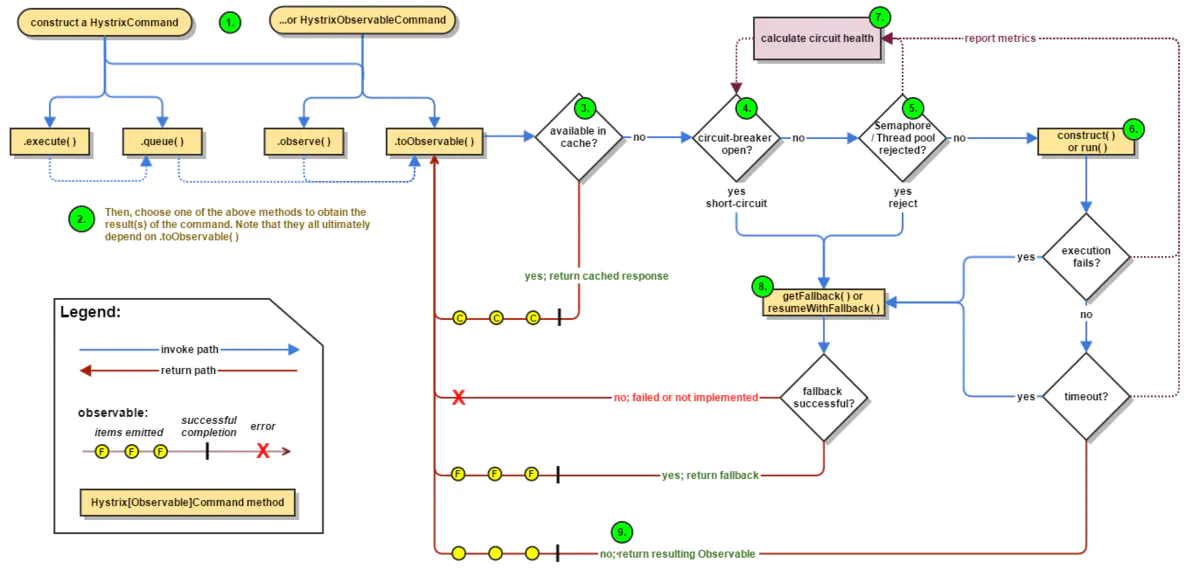
- 构建一个HystrixCommand或者HystrixObservableCommand 对象。
- 执行Command
- 响应是否有缓存?如果为该命令启用请求缓存,并且如果缓存中对该请求的响应可用,则此缓存响应将立即以“可观察”的形式返回。
- 熔断器是否打开?如果电路打开(或“跳闸”),则Hystrix将不会执行该命令,但会将流程路由到(8)获取回退。如果电路关闭,则流程进行到(5)以检查是否有可用于运行命令的容量。
- 线程池/队列/信号量是否已经满负载?如果与命令相关联的线程池和队列(或信号量,如果不在线程中运行)已满,则Hystrix将不会执行该命令,但将立即将流程路由到(8)获取回退。
- 执行真正的命令部分,HystrixObservableCommand.construct() 或者 HystrixCommand.run(),在这里Hystrix通过您为此目的编写的方法调用对依赖关系的请求。如果run或construct方法超出了命令的超时值,则该线程将抛出一个TimeoutException, 在这种情况下,Hystrix将响应通过8进行路由。获取Fallback,如果该方法不取消/中断,它会丢弃最终返回值run()或construct()方法。
- 计算Circuit 的健康,Hystrix向断路器报告成功,失败,拒绝和超时,该断路器维护了一系列的计算统计数据组。它使用这些统计信息来确定电路何时“跳闸”,此时短路任何后续请求直到恢复时间过去,在首次检查某些健康检查之后,它再次关闭电路。
- 获取Fallback,当命令执行失败时,Hystrix试图恢复到你的回退:当construct或run抛出异常时[6],当命令由于电路断开而短路时[4],当命令的线程池和队列或信号量处于容量[5],或者当命令超过其超时长度时[6]。
- 返回成功的响应,如果 Hystrix command成功,如果Hystrix命令成功,它将以Observable的形式返回对呼叫者的响应或响应。