Zookeeper概述
ZooKeeper是一个分布式的、开放源码的分布式协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。由于Hadoop生态系统中很多项目都依赖于zookeeper,如Pig,Hive等, 似乎很像一个动物园管理员,于是取名为Zookeeper。
Zookeeper 特点
- 顺序一致性
- 从同一个客户端发起的事务请求,将会严格按照其发起顺序被应用到zookeeper中
- 原子性
- 所有事物请求的处理结果在整个集群中所有机器上的应用情况是一致的,要么整个集群中所有机器都成功应用了某一事务,要么都没有应用某一事务,不会出现集群中部分机器应用了事务,另一部分没有应用的情况。
- 单一视图
- 无论客户端连接的是哪个zookeeper服务端,其获取的服务端数据模型都是一致的。
- 可靠性
- 一旦服务端成功的应用了一个事务,并完成对客户端的响应,那么该事务所引起的服务端状态变更将会一直保留下来,直到有另一个事务又对其进行了改变。
- 实时性
- 一旦服务端成功的应用了一个事物,那客户端立刻能看到变更后的状态
Zookeeper 使用场景
- 名字服务
- 配置管理
- 集群管理
- 集群选举
- 分布式锁
- 队列管理
- 消息订阅
Zookeeper 核心机制
zookeeper节点角色
在zookeeper中,节点分为下列几种角色:
- 领导者(leader),负责进行投票的发起和决议,更新系统状态,在Zookeeper集群中,只有一个Leader节点。
- 学习者(learner),包括跟随者(follower)和观察者(observer)。
- follower用于接受客户端请求并想客户端返回结果,在选主过程中参与投票,在Zookeeper集群中,follower可以为多个。
- Observer可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度(不参与投票降低选举的复杂度)
在一个zookeeper集群,各节点之间的交互如下所示:
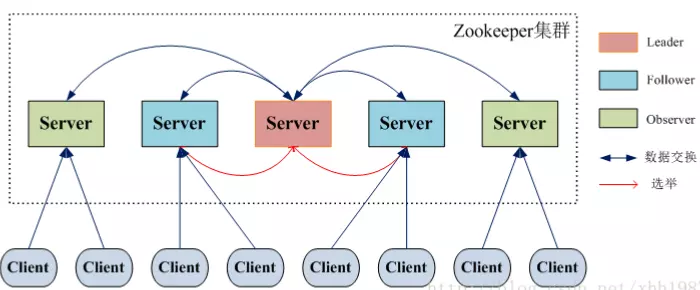
注:几乎所有现代基于分布式架构的中间件都是采用类似做法,例如kafka、es等。
从上可知,所有请求均由客户端发起,它可能是本地zkCli或java客户端。 各角色详细职责如下。
- Leader
eader的职责包括:
-
恢复数据;
-
维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
-
Leader的工作流程简图如下所示,在实际实现中,启动了三个线程来实现功能。
-
Follower
follower的主要职责为:
- 向Leader发送请求;
- 接收Leader的消息并进行处理;
- 接收Zookeeper Client的请求,如果为写清求,转发给Leader进行处理