1. Lucene 是什么
Lucene 是一个开源的、成熟的全文索引与信息检索(IR)库,采用Java实现。信息检索式指文档搜索、文档内信息搜索或者文档相关的元数据搜索等操作。Lucene是apache软件基金会项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。全文检索(Full-Text Retrieval)是指以文本作为检索对象,找出含有指定词汇的文本。全面、准确和快速是衡量全文检索系统的关键指标。
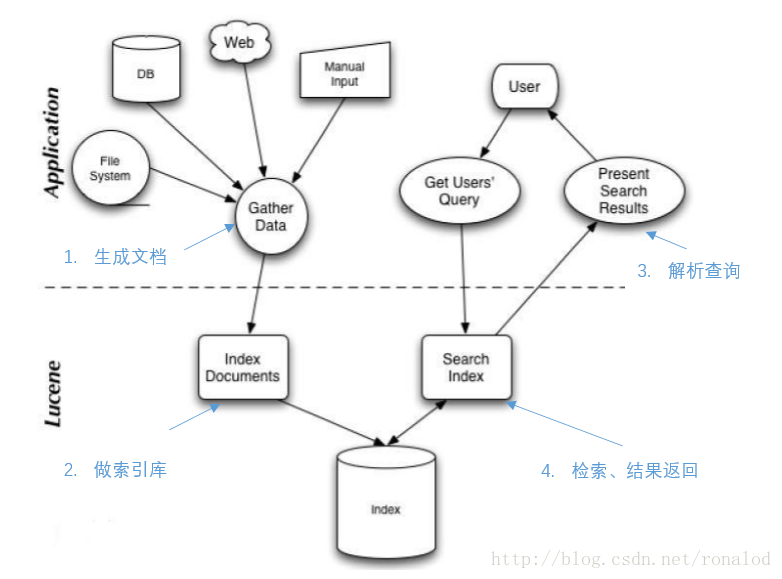
Lucene整体使用如图所示:
2. 历史
Lucene最初是由Doug Cutting开发的,在SourceForge的网站上提供下载。在2001年9月做为高质量的开源Java产品加入到Apache软件基金会的 Jakarta家族中。随着每个版本的发布,这个项目得到明显的增强,也吸引了更多的用户和开发人员
3. Lucene能做什么
Lucene使你可以为你的应用程序添加索引和搜索能力。Lucene可以索引并能使得可以转换成文本格式的任何数据能够被搜索。
同样,利用Lucene你可以索引存放于数据库中的数据,提供给用户很多数据库没有提供的全文搜索的能力。
Lucene作为一个全文检索引擎,其具有如下突出的优点:
- 索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
- 在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
- 优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
- 设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
- 已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询、分组查询等等。
4. Lucene 原理
4.1 索引原理
全文检索技术由来已久,绝大多数都基于倒排索引来做,曾经也有过一些其他方案如文件指纹。倒排索引,顾名思义,它相反于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成——词典和倒排表。
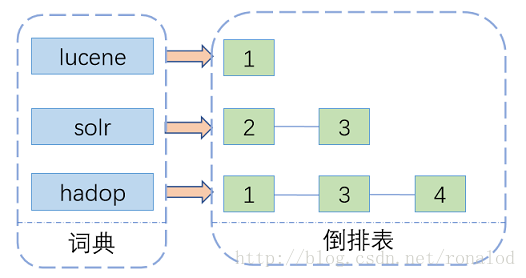
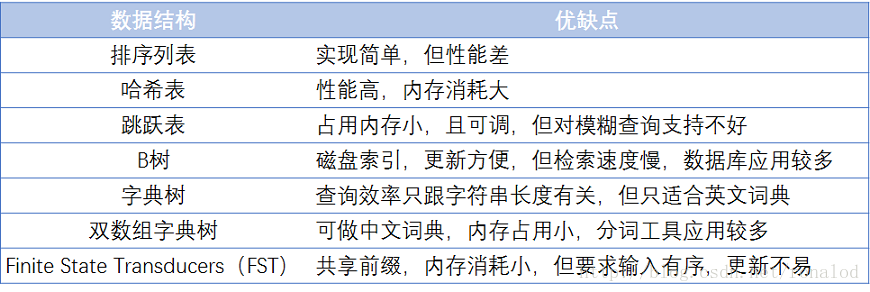
其中词典结构尤为重要,有很多种词典结构,各有各的优缺点,最简单如排序数组,通过二分查找来检索数据,更快的有哈希表,磁盘查找有B树、B+树,但一个能支持TB级数据的倒排索引结构需要在时间和空间上有个平衡,下图列了一些常见词典的优缺点:
4.2 Lucene 原理
Lucene的检索算法属于索引检索,即用空间来换取时间,对需要检索的文件、字符流进行全文索引,在检索的时候对索引进行快速的检索,得到检索位置,这个位置记录检索词出现的文件路径或者某个关键词。
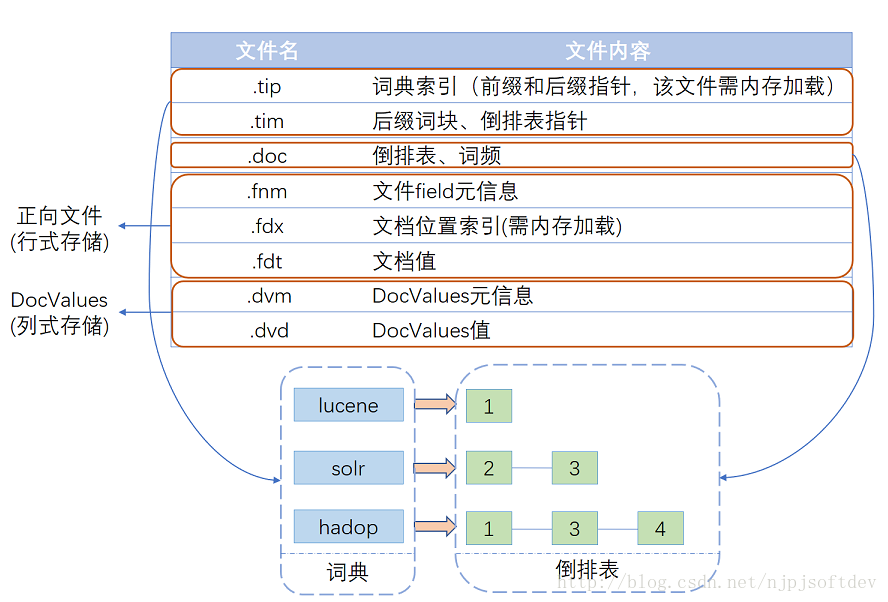
Lucene经多年演进优化,现在的一个索引文件结构如图所示,基本可以分为三个部分:词典、倒排表、正向文件、列式存储DocValues。
5. 索引组件
为了快速搜索大量的文本,你必须首先简历针对文本索引,将文本内容转换成能够进行快速搜索的格式,从而消除慢速顺序扫描处理所带来的影响。这个过程就叫做索引操作,它的输出就叫做索引。
Lucene 采用的是一种称为反向索引(inverted index)的机制。反向索引就是说我们维护了一个词/短语表,对于这个表中的每个词/短语,都有一个链表描述了有哪些文档包含了这个词/短语。这样在用户输入查询条件的时候,就能非常快的得到搜索结果。
整个索引过程包括:
- 获取内容
- 建立文档
- 文档分析
- 文档索引
6. 搜索组件
搜索是在一个索引中查找单词来找出它们所出现的文档的过程。搜索质量主要由查准率和查全率来衡量。查全率用来衡量搜索系统朝赵相关文档的能力;而查准率用来衡量搜索系统过滤费相关文档的能力。
搜索引擎的典型组件:
- 用户搜索界面
- 建立查询
- 搜索查询
- 展现结果
7. 一些概念
7.1 Analyzer
Analyzer是分析器,它的作用是把一个字符串按某种规则划分成一个个词语,并去除其中的无效词语,这里说的无效词语是指英文中的“of”、“the”,中文中的“的”、“地”等词语,这些词语在文章中大量出现,但是本身不包含什么关键信息,去掉有利于缩小索引文件、提高效率、提高命中率。
分词的规则千变万化,但目的只有一个:按语义划分。这点在英文中比较容易实现,因为英文本身就是以单词为单位的,已经用空格分开;而中文则必须以某种方法将连成一片的句子划分成一个个词语。
7.2 Document
用户提供的源是一条条记录,它们可以是文本文件、字符串或者数据库表的一条记录等等。一条记录经过索引之后,就是以一个Document的形式存储在索引文件中的。用户进行搜索,也是以Document列表的形式返回。
7.3 Field
一个Document可以包含多个信息域,例如一篇文章可以包含“标题”、“正文”、“最后修改时间”等信息域,这些信息域就是通过Field在Document中存储的。
Field有两个属性可选:存储和索引。通过存储属性你可以控制是否对这个Field进行存储;通过索引属性你可以控制是否对该Field进行索引。这看起来似乎有些废话,事实上对这两个属性的正确组合很重要,。
面举例说明:还是以刚才的文章为例子,我们需要对标题和正文进行全文搜索,所以我们要把索引属性设置为真,同时我们希望能直接从搜索结果中提取文章标题,所以我们把标题域的存储属性设置为真,但是由于正文域太大了,我们为了缩小索引文件大小,将正文域的存储属性设置为假,当需要时再直接读取文件;我们只是希望能从搜索解果中提取最后修改时间,不需要对它进行搜索,所以我们把最后修改时间域的存储属性设置为真,索引属性设置为假。上面的三个域涵盖了两个属性的三种组合,还有一种全为假的没有用到,事实上Field不允许你那么设置,因为既不存储又不索引的域是没有意义的。
7.4 Term
term是搜索的最小单位,它表示文档的一个词语,term由两部分组成:它表示的词语和这个词语所出现的field。
7.5 Tocken
tocken是term的一次出现,它包含trem文本和相应的起止偏移,以及一个类型字符串。一句话中可以出现多次相同的词语,它们都用同一个term表示,但是用不同的tocken,每个tocken标记该词语出现的地方。
7.6 Segment
添加索引时并不是每个document都马上添加到同一个索引文件,它们首先被写入到不同的小文件,然后再合并成一个大索引文件,这里每个小文件都是一个segment。