在上一主题 聊透Spring依赖注入 中,我们站在源码的角度上,详细分析了Spring依赖注入的方式、原理和过程,相信认真看完的小伙伴们一定会有所收获。清楚了Spring依赖注入的来龙去脉之后,本章节我们聊一下和依赖注入密切相关,并且在实际开发中很常见,面试也很喜欢问的一个问题:Spring是怎么解决循环依赖的?
笔者之前就被问过Spring是怎么解决循环依赖的问题,当时年少无知,对Spring源码知之甚少,也没有做足功课。只是支支吾吾的说到:好像是通过多级缓存解决的吧。面试官看我实在窘迫,也没有深问,算是逃过一劫,可在心里总是个羁绊。后来随着对Spring源码的深入阅读和理解,慢慢清楚了Spring解决循环依赖的方式。
后来笔者也一直在想,为什么这么多年了,面试还是喜欢问Spring是怎么解决循环依赖的这种问题呢?除了工作中比较常见,究其原因,可能跟需要你对Spring bean的生命周期和AOP有所了解才能回答好这个问题有关吧,而这两者也能直接反应出你对Spring框架的理解程度,也许这就是面试喜欢问这道题深层的含义吧。
好了,我们不猜面试官的心里了。既然循环依赖这么实用,那本章节我们就一起聊聊Spring循环依赖吧,我们主要分为以下几个部分进行讨论:
什么是循环依赖?
Spring循环依赖的解决之道
一定需要三级缓存来解决循环依赖吗
在哪些场景下是不支持循环依赖的?有解决方法吗
1. 什么是循环依赖
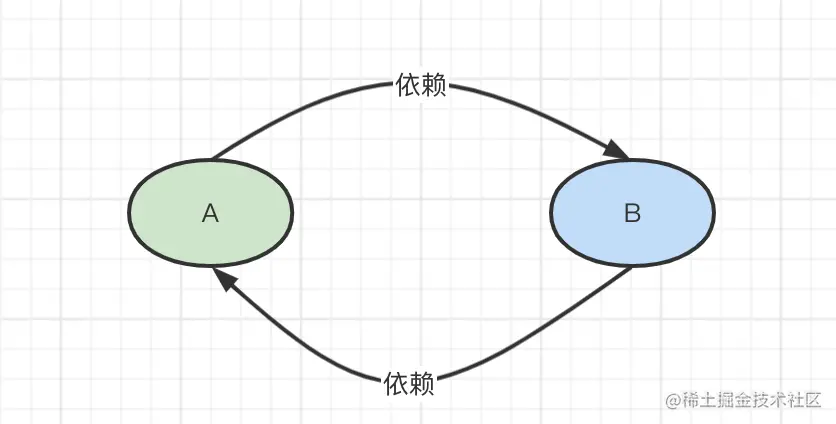
在探讨Spring循环依赖的解决方式以前,我们先来回忆一下什么是循环依赖:A依赖B的同时,B也依赖了A,就构成了循环依赖。依赖关系如下图所示:
体现到代码中为:
@Component
public class A{
// 依赖B
@Autowired
private B b;
public B getB() {
return b;
}
}
@Component
public class B {
// 依赖A
@Autowired
private A a;
public A getA() {
return a;
}
}
//比较特殊的循环依赖
@Component
public class A{
// 依赖B
@Autowired
private A a;
}
当然也有一些链路较长,隐藏的比较深的循环依赖,比如:A -> B -> C -> D -> ... -> B这种,无论如何,都要形成一个环才能被称为循环依赖。
Spring的循环依赖过程,跟bean的生命周期密切相关,在实例化bean的时候,会完成依赖注入。所以就会出现:实例化A -> 属性填充注入B ->B还没有实例化,需要先进行实例化B(A等待) -> 实例化B -> 注入A -> A实例化未完成,无法注入 -> 实例化B失败 -> 实例化A失败。这个问题类似于我们常见的死锁,颇有点有点窈窕淑女,求之不得的味道。
有没有办法解决呢?当然有,英文Spring就解决了嘛。就是在实例化过程中,提前把bean暴露出来,虽然此时还是个半成品(属性未填充),但是我们允许先注入,这样确实能解决问题。我们梳理一下: 实例化A -> 暴露a对象(半成品)-> 属性填充注入B ->B还没有实例化,需要先进行实例化B(A等待) -> 实例化B -> 注入A(半成品) -> 实例化B成功 -> 实例化A成功。通过提前把半成品的对象暴露出来,支持别的bean注入,确实可以解决循环依赖的问题,实际上,Spring也确实是这么做的。沿着这个思路,下文我们详细分析Spring的处理方式。
什么,你问b对象中注入的a属性还是半成品怎么办?大兄弟,难道你忘了java对象的传递,本质是传递引用的吗,内存中是同一个对象啊,对象的修改是相互影响的啊。有朝一日,对象a完整了,b对象中的a属性,肯定也 码生 完整了。
2. Spring循环依赖解决之道
2.1 Spring通过三级缓存解决依赖注入
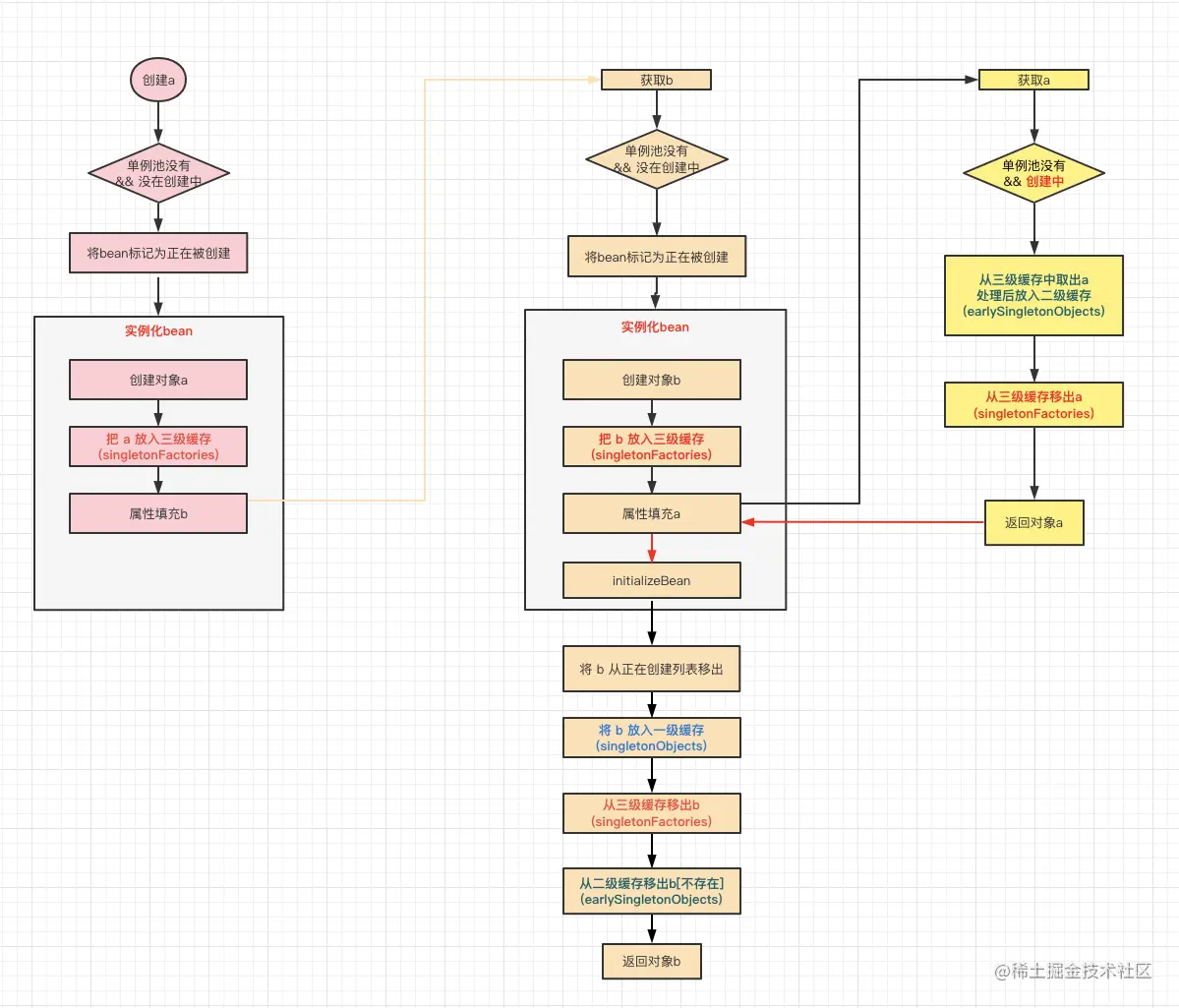
Spring究竟是不是通过上述我们说的方式解决的呢,其实思路是一致的,只是Spring处理的更加严谨。Spring是通过三级缓存来解决循环依赖的,提前暴露的对象存放在三级缓存中,二级缓存存放过渡bean,一级缓存存放最终形态的bean。下面我们还是用A -> B -> A的场景,看一下Spring是如何解决循环依赖的。我们按照过程一步步来分析,首先是实例化A的过程:
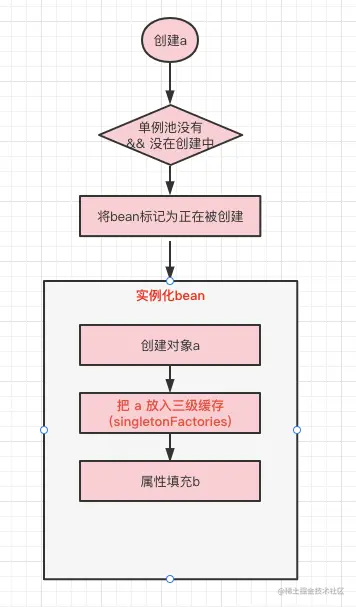
此时执行到属性填充环节,需要注入b,因为Spring管理的bean默认是单例的,为防止重复创建,Spring会先去容器中查找b,如果查找不到,再进行创建。此时容器中是没有b的,所以需要先实例化b,流程和实例化a一致。
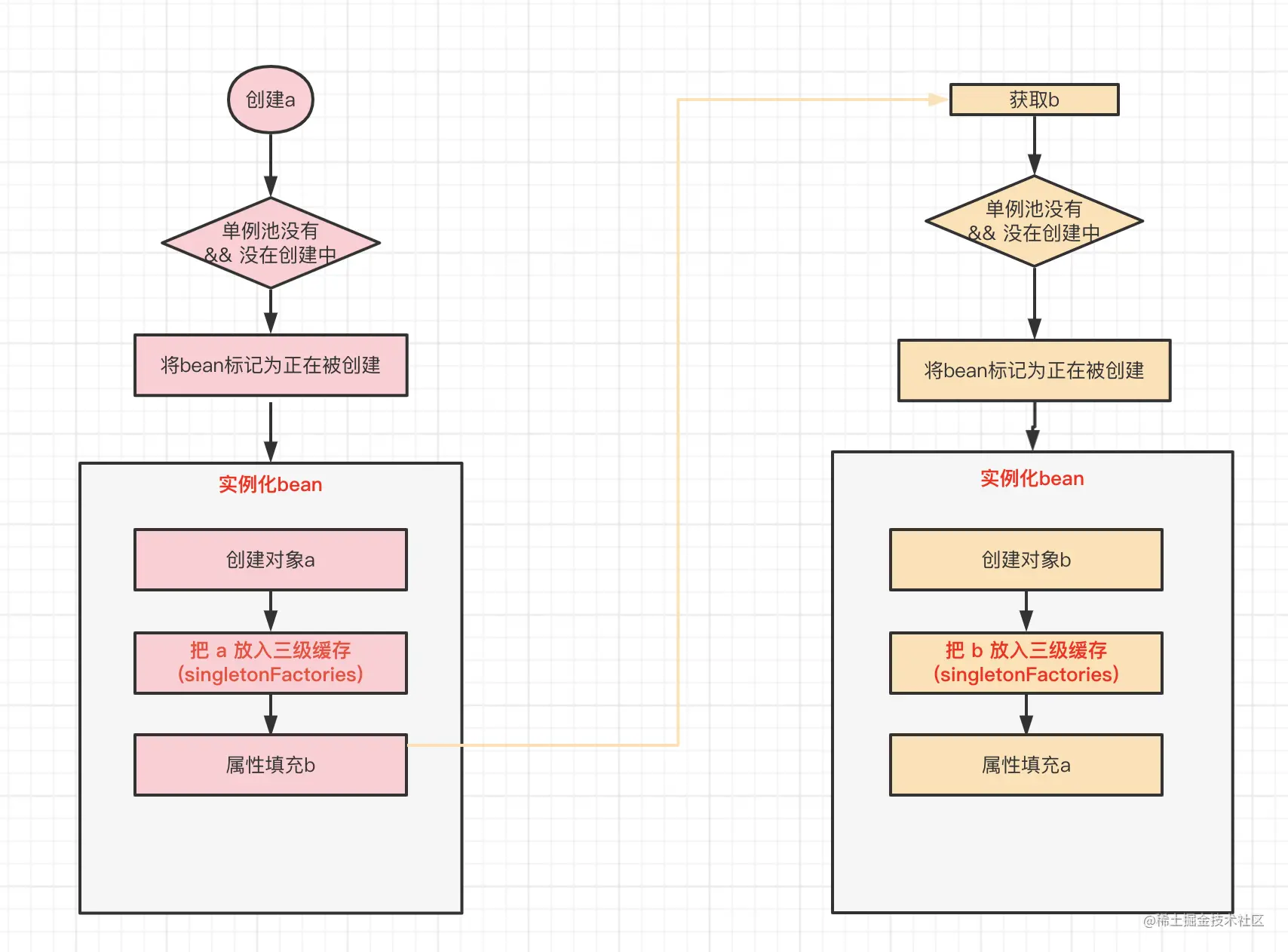
此时B也执行到属性填充的环节了,有意思的地方开始了,此时又需要注入a,此时还是会先去容器中查找a,此时的a虽然没在单例池中,但是因为在创建中,并且也在三级缓存中了。所以此时获取a的流程就发生了变化:不再是直接创建,而是会从三级缓存中获取a,三级缓存存放的并不是bean对象,而是生成bean的ObjectFactory,在获取时会经过AbstractAutowireCapableBeanFactory#getEarlyBeanReference()的处理,才能获取到bean,然后放入二级缓存中,同时返回a进行依赖注入。
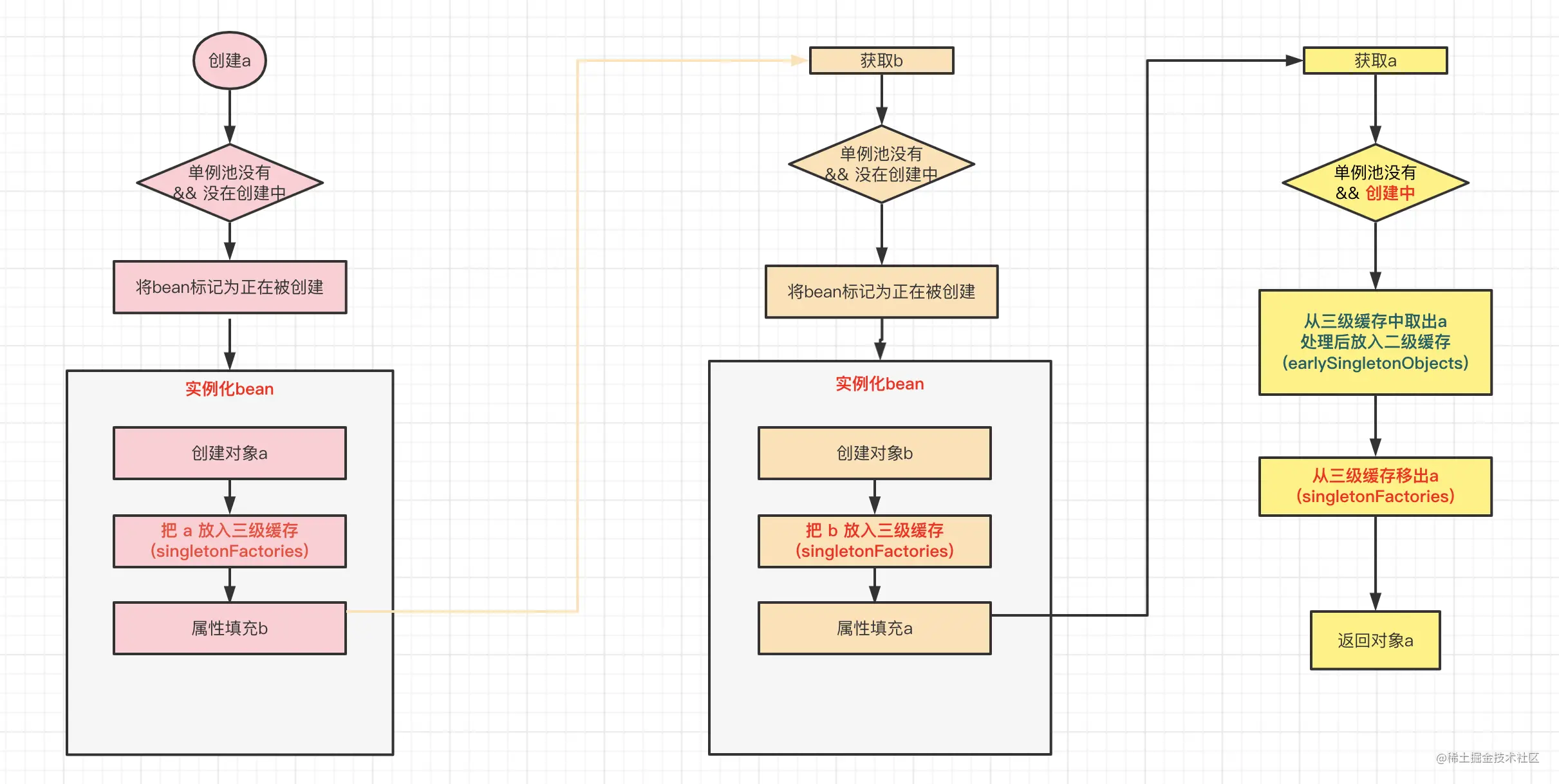
这里小伙伴可能有疑问:为什么三级缓存中存放的是ObjectFactory而不是bean呢? 而AbstractAutowireCapableBeanFactory#getEarlyBeanReference()的处理又起什么作用,为什么三级缓存要经过它的处理之后,才能放入二级缓存呢?这些问题请小伙伴们稍安勿躁,后面我们会详细说明的。
截止到目前,通过提前暴露对象到多级缓存,已经成功将实例b中的属性a注入了,那后面的流程自然一路畅通:继续执行b的实例化initializeBean() -> 将b从正在创建列表移出 -> 将b放入一级缓存(同时将b在二级缓存和三级缓存中删除) ->返回b。
在b实例化完成并返回后,a的实例化流程也从等待着苏醒,继续执行,后续流程和b的完全一致。
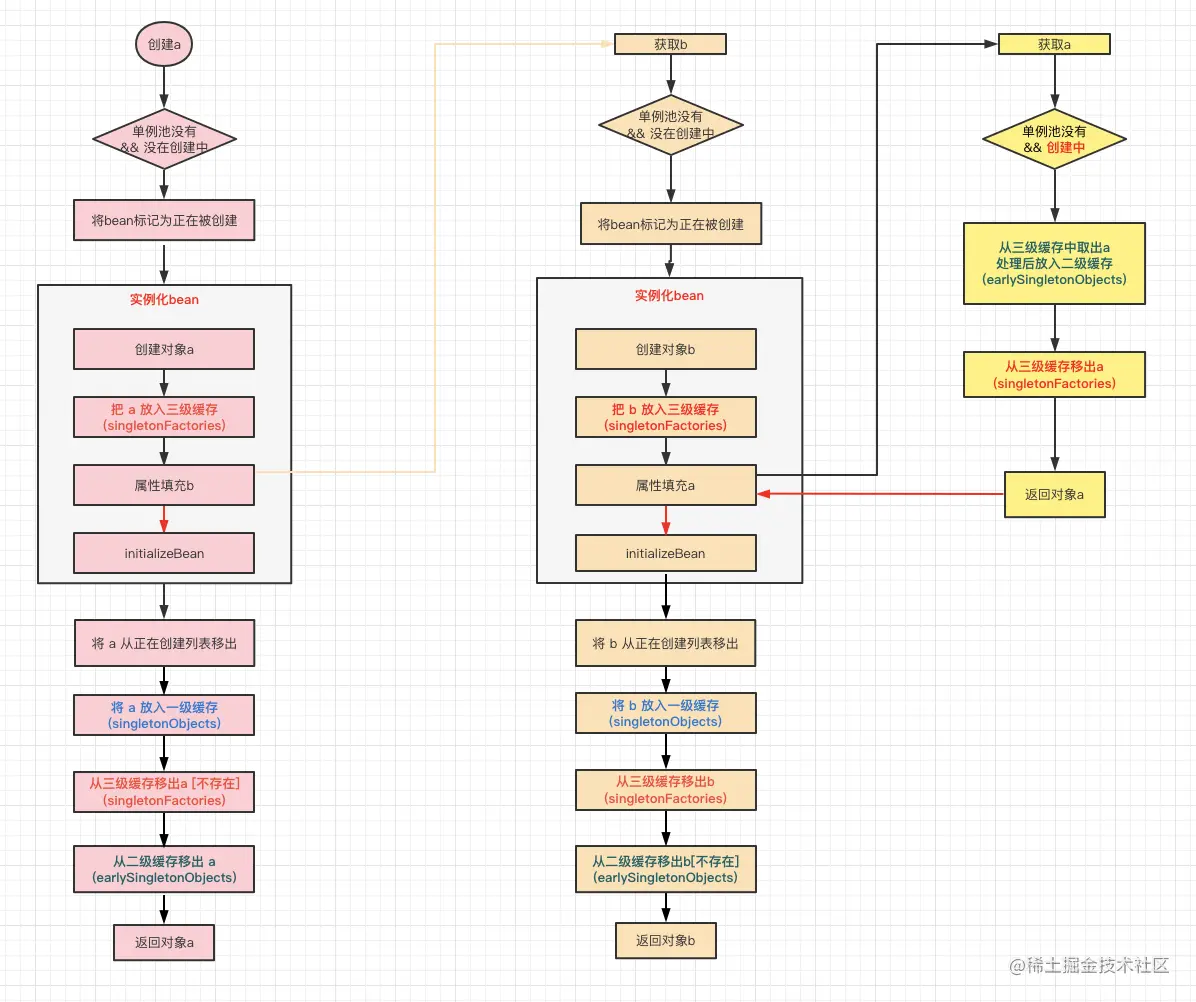
其实这就是Spring解决循环依赖的流程,其核心思路就是:先将bean提前暴露到三级缓存中,后续有依赖注入的话,先将这个半成品的bean进行注入。之所以说这个bean是半成品,是因为暴露在三级缓存和二级缓存中的bean虽然已经创建成功,但是属性还没有进行填充,Aware回调等流程也没有执行,所以说它是一个不完整的bean对象。
2.2 多级缓存
2.2.1 多级缓存的作用
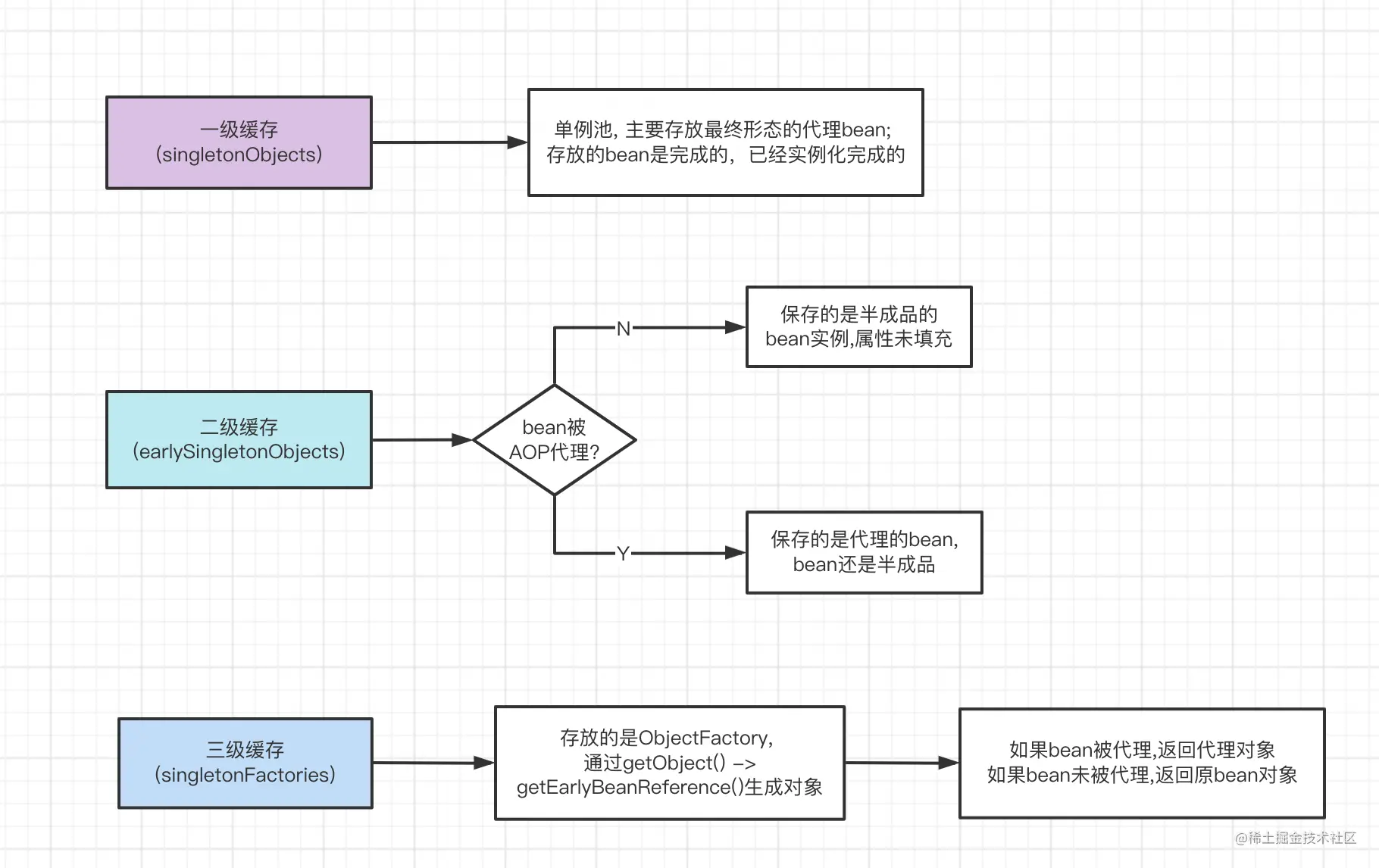
通过上述对Spring解决循环依赖的分析,我们知道Spring采用了三级缓存,这里我们重点看一下每级缓存中存放的都是什么内容:
三级缓存(singletonFactories)
其存放的对象为ObjectFactory类型,主要作用是产生bean对象。Spring在这里存放的是一个匿名内部类,调用getObject()最终调用的是getEarlyBeanReference()。该方法的主要作用是:如果有需要,产生代理对象。如果bean被AOP切面代理,返回代理bean对象;如果未被代理,就返回原始的bean对象。
getEarlyBeanReference()调用的
SmartInstantiationAwareBeanPostProcessor,其实是Spring留得拓展点,本质是通过BeanPostProcessor定制bean的产生过程。绝大多数AOP(比如@Transactional)单例对象的产生,都是在这里进行了拓展,进而实现单例对象的生成。
二级缓存(earlySingletonObjects)
主要存放过渡bean,也就是三级缓存中ObjectFactory产生的对象。主要作用是防止bean被AOP切面代理时,重复通过三级缓存对象ObjectFactory创建对象。被代理情况下,每次调用ObjectFactory#getObject()都是会产生新的代理对象的。这明显不满足spring单例的原则,所以需要二级缓存进行缓存。
同时需要注意:二级缓存中存放的bean也是半成品的,此时属性未填充。
一级缓存(singletonObjects)
也被称为单例池, 主要存放最终形态的bean(如果存在代理,存放的代理后的bean)。 一般情况我们获取bean都是从这里获取的,但是并不是所有的bean都在单例池里面,一些特殊的,比如原型的bean就不在里面。
2.2.2 一定需要三级缓存吗?二级缓存行不行?
纵观Spring解决循环依赖的过程,好像二级缓存没啥实际作用啊,不要二级缓存貌似也能搞定循环依赖啊?确实,在没有AOP的情况下,二级缓存没有实际作用,只通过三级缓存和一级缓存就可以搞定,我们看一下:
- 首先实例化A,实例化前先将半成品暴露在三级缓存中。
- 填充属性B,发现B还没有实例化,先去实例化B。
- 实例化B的过程中,需要填充属性A,从三级缓存中通过
ObjectFactory#getObject()直接获取A(在没有AOP的场景下,多次获取的是同一个bean),进行依赖注入,并完成实例化流程。 - 获取到b,实例化A的流程继续,注入到b到a中,进而完成a的实例化。
那如果bean被AOP代理了,情况就会大不一样,最核心的区别点:就是每次调用ObjectFactory#getObject()都会产生一个新的代理对象,我们用存在事务的场景测试一下:
@Component
@EnableTransactionManagement // 开启事务
public class A {
@Autowired
private B b;
@Transactional //增加事务注解,会对bean生成代理对象
public B getB() {
System.out.println(Thread.currentThread().getName());
return b;
}
}
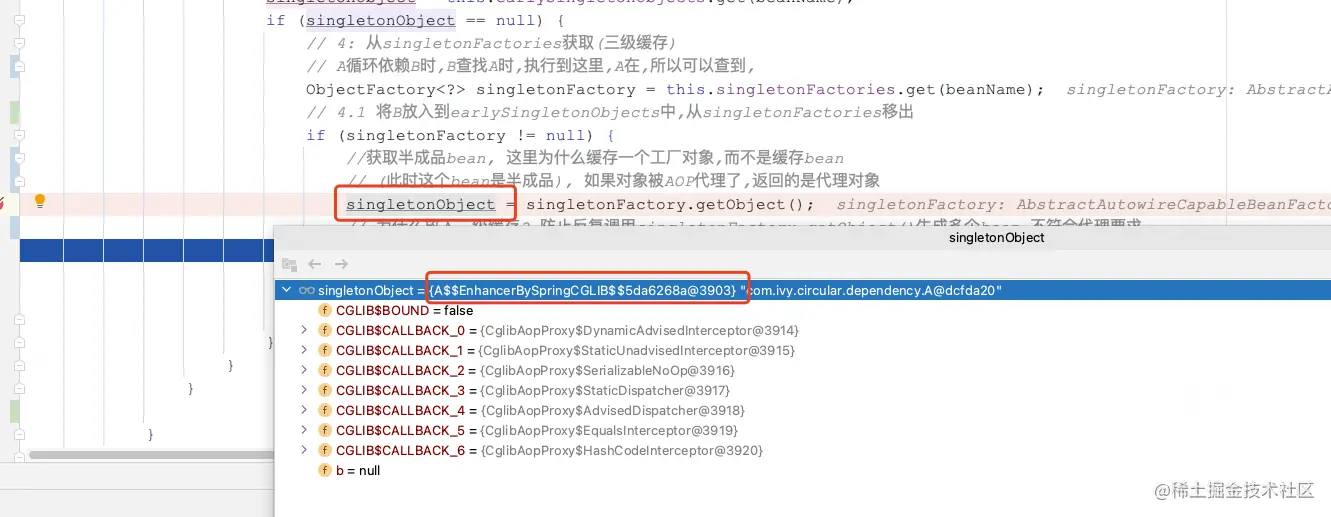
测试方法很简单:我们给A的getB()加上事务注解@Transactional,此时A就会被AOP代理,生成的实例a也是代理对象了。我们debug验证一下,就会发现此时A确实被CGLIB代理了:
我们在验证一下二级缓存存在的必要的条件:是不是bean被AOP代理后,多次调用ObjectFactory#getObject(),产生的代理对象不是同一个:
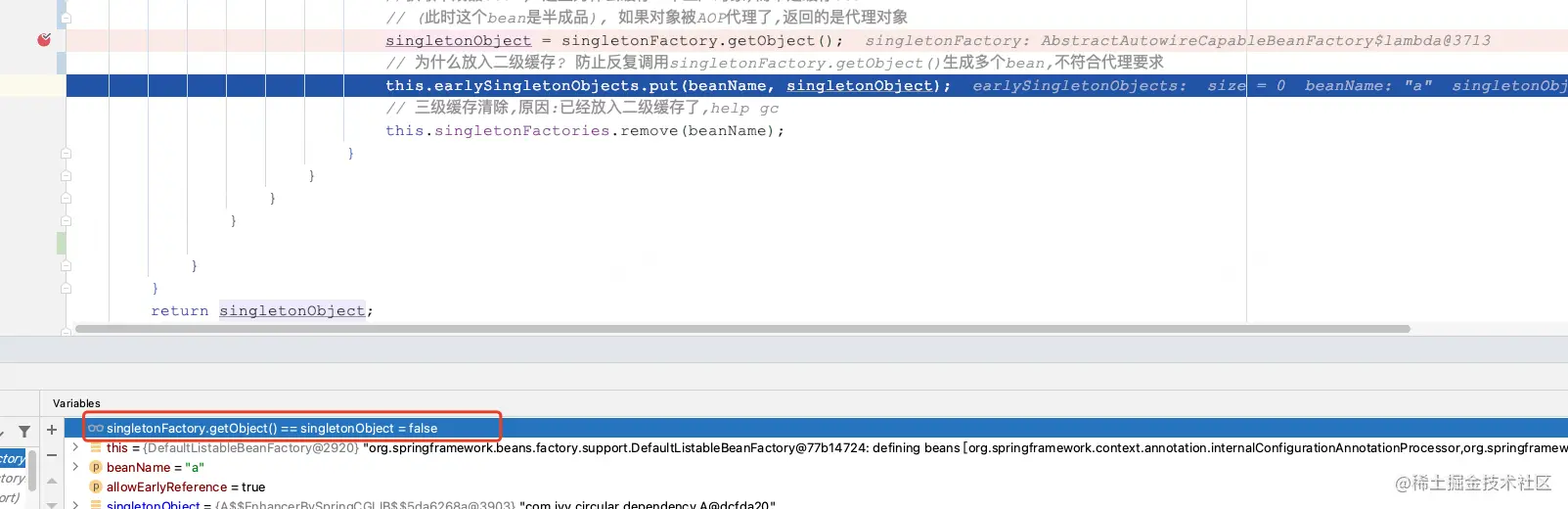
经过singletonFactory.getObject() == singletonObject为false的测试,我们可以确认,确实不是同一个。
这和代理对象的生成有关,后续我们讲到AOP的时候,再详细介绍
那么问题来了:A是单例的,也就是要保证,在Spring中,使用到该bean的地方,都是同一个bean才行。但是每次执行singletonFactory.getObject()都会产生新的代理对象。假设只有一级和三级缓存,每次从三级缓存中获取代理对象,都会产生新的代理对象,忽略性能不说,是不符合单例原则的。
所以这里我们要借助二级缓存来解决这个问题,将singleFactory.getObject()产生的对象放到二级缓存中去,后面直接从二级缓存中拿,保证始终只有一个代理对象。现在我们已经明白为什么Spring采用三级缓存了吧,我们再总结一下各个缓存存放的内容:
3. 不支持循环依赖的情况
3.1 非单例的bean无法支持循环依赖
//AbstractAutowireCapableBeanFactory.java
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// 省略部分代码
// 是否支持循环依赖
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 做循环依赖的支持 将早期实例化bean的ObjectFactory,添加到单例工厂(三级缓存)中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
}
在上述支持循环依赖的讨论中,都有一个前提:提前把半成品bean暴露到三级缓存中。在Spring源码中,这里的暴露有前置条件:mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName),我们一起分析一下这些条件:
mbd.isSingleton():要求bean是单例的。this.allowCircularReferences:是否允许循环依赖,默认为true,即默认支持循环依赖。isSingletonCurrentlyInCreation(beanName):判断当前bean是否正在创建中,默认是成立的,因为在创建bean的时候,会先设置该标志。
通过这个前置条件,我们可以得出结论,只有单例bean才有支持循环依赖的可能,非单例的bean不支持循环依赖。
3.2 constructor注入导致无法支持循环依赖
如果存在循环依赖 A -> B -> A,且都是通过构造函数依赖的,无法支持循环依赖,我们来看一下这种场景:
@Component
public class A{
// 依赖B
private B b;
public A(B b){
this.b = b;
}
public B getB() {
return b;
}
}
@Component
public class B {
// 依赖A
private A a;
public A(A a){
this.a = a;
}
public A getA() {
return a;
}
}
这种情况下,A实例创建时 -> 构造注入B -> 查找B,容器中不存在,先实例化创建B -> 构造注入A -> 容器中不存在A(此时A还没有添加到三级缓存中) -> 异常UnsatisfiedDependencyException。因为暴露对象放入三级缓存的过程在实例创建之后,通过构造方法注入时,还没有放入三级缓存呢,所以无法支持构造器注入类型的循环依赖。
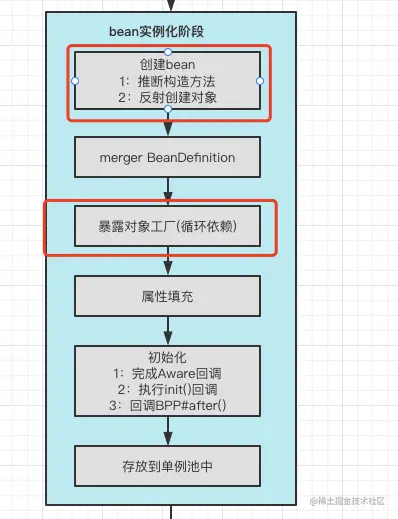
我们简单看一下bean的生命周期。关于bean的生命周期,后续我们会出单独的章节讲解,这里先简单了解一下:
3.3 @Async导致无法支持循环依赖
当循环依赖遇到@Async,会出现无法支持的情况,我们先来看一下这种情况:
@Component
@EnableAsync //开启异步
public class A {
@Autowired
private B b;
@Async // 标注方法异步处理
public B getBService() {
System.out.println(Thread.currentThread().getName());
return b;
}
}
@Component
public class B {
@Autowired
private A a;
public A getAService() {
return a;
}
}
// 输出信息:
org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Bean with name 'a' has been injected into other beans [b] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:616)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:480)
...
奇了怪了,我们知道@Async和@Transactional的底层原理,都是被AOP拦截生成代理对象,进行功能的增强,那为什么一个支持循环依赖,一个不支持呢?我们还是从源码中找找答案吧。
这里先介绍一些基础知识,AOP的代理对象的生成是借助BeanPostProcessor后置处理器触发的,@Transactional借助的是InfrastructureAdvisorAutoProxyCreator这个后置处理器,@Async借助的是AsyncAnnotationBeanPostProcessor这个后置处理器,我们先来一下这两个后置处理器在类图上有什么不同:
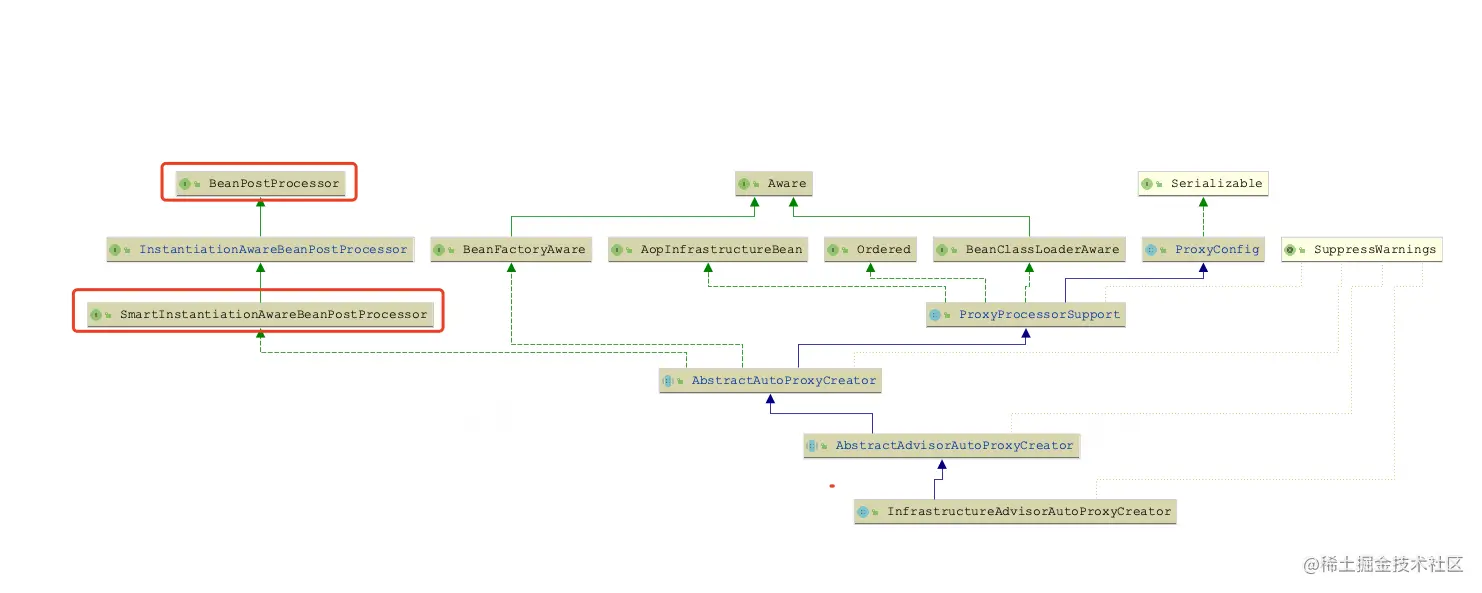
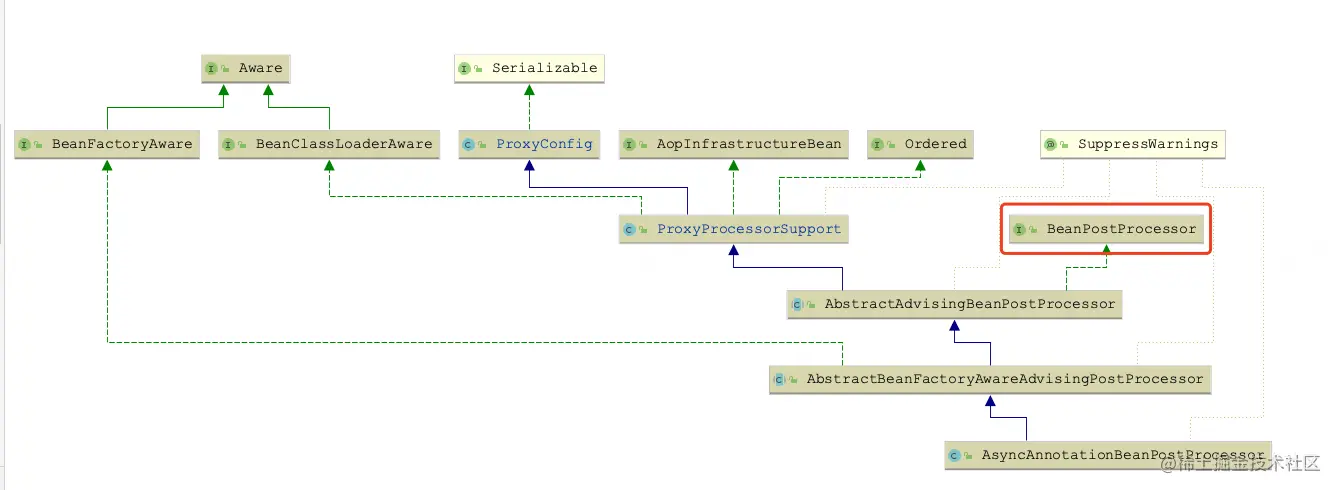
我们仔细观察BeanPostProcessor这条链路上的继承关系,发现虽然两者都是BeanPostProcessor的子类,但是InfrastructureAdvisorAutoProxyCreator还实现了SmartInstantiationAwareBeanPostProcessor,而AsyncAnnotationBeanPostProcessor没有。乍一看是不是觉得没啥,然而这就是造成两者不同的核心原因?,是不是一脸问号。

小伙伴不要着急,我们一起来看一下这神奇的操作是怎么产生的。小伙伴们还记得三级缓存存放的是ObjectFactory吧,在注入前通过getObject()生成对象进行注入,同时存放到二级缓存中。前文我们反复提过,getObject()其实调用的是AbstractAutowireCapableBeanFactory#getEarlyBeanReference(),这里其实只会处理SmartInstantiationAwareBeanPostProcessor触发的代理对象的生成。也就是说@Transactional代理对象,在这一步会生成,而@Async代理对象,这里并不会生成(在之后生成,所以注入的不是代理对象)。我们去源码中验证一下:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
// 只会处理SmartInstantiationAwareBeanPostProcessor类型的代理bean
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
so what,这和循环依赖又有什么关系呢。我们回到正题,知道了这个前提,我们可以得出结论:在循环依赖A -> B -> A,并且A中的getB()被@Async标识的情况下,实例b在属性填充阶段,填充的属性a的值,是没有被代理的原始对象。我们debug证明一下:
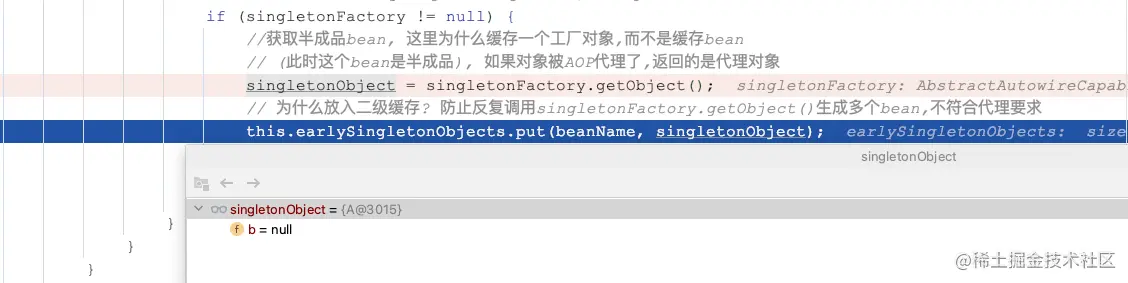
三级缓存中ObjectFactory通过getObject()生成对象后,放入二级缓存的同时,返回了a,之后直接注入给属性了,所以这种情况下,二级缓存中的和属性注入的值,都是原始对象。
但是我们知道,a最终肯定是要被代理的,因为@Async异步执行的能力,只有增强后的bean才会有。那问题就浮出水面了:容器中最终形态的a是代理后的bean,而实例b中注入的未被代理的bean,两者是不一致的。这种情况在Spring中被允许吗,当然不,Spring会尽量控制这种情况的发生,这也就是这个循环依赖无法支持的原因。我们看一下源码中是怎么检测的。
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException {
// 1: 创建对象
instanceWrapper = createBeanInstance(beanName, mbd, args);
// 2: 完成Merged,这里主要是完成@Autowired @Resource属性的查找
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// 3:做循环依赖的支持 将早期实例化bean的ObjectFactory,添加到单例工厂(三级缓存)中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
//4: 属性填充
populateBean(beanName, mbd, instanceWrapper);
// 5: 初始化bean,@Async在该步骤生成了代理对象,exposedObject为代理对象
exposedObject = initializeBean(beanName, exposedObject, mbd);
// 默认支持单例bean的循环依赖,条件成立
if (earlySingletonExposure) {
// 从二级缓存获取早期bean,针对@Async的情况,此时获取到的是原始对象(不是单例对象)
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
// 针对@Aysnc而言:exposedObject是被代理过的对象, 而bean是原始对象,所以此处不相等
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
// allowRawInjectionDespiteWrapping: 是否允许Bean的原始类型被注入到其它Bean里面,即使自己最终会被包装(代理),
// 默认是false表示不允许,如果改为true表示允许,就不会报错啦。这是其中一个解决方案;
//dependentBeanMap: 记录着每个Bean它所依赖的Bean的Map~~~~
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
// 获取依赖当前bean的bean名称,B依赖了A,所以beanName为a时,所以此处值为["b"]
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
// 对所有的依赖进行一一检查
for (String dependentBean : dependentBeans) {
/**
* 此处会有问题, 首先b在alreadyCreated里面,因为他已经创建完成了,所以返回false。
* b都实例化完成了,属性a肯定也赋值完成了,这里有个隐藏逻辑:属性a赋值的一定是从二级缓存中获取到的那个原始对象。
* 而这里的要返回,最终放入一级缓存的是exposedObject,也就是代理对象。
* 所以B里面引用的a和主流程我这个A竟然不相等,那肯定就有问题(说明不是最终的)。
* 这里Spring将A真正的依赖,加入到actualDependentBeans里面去
*/
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
// 发现actualDependentBeans不为空,报错
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
return exposedObject;
}
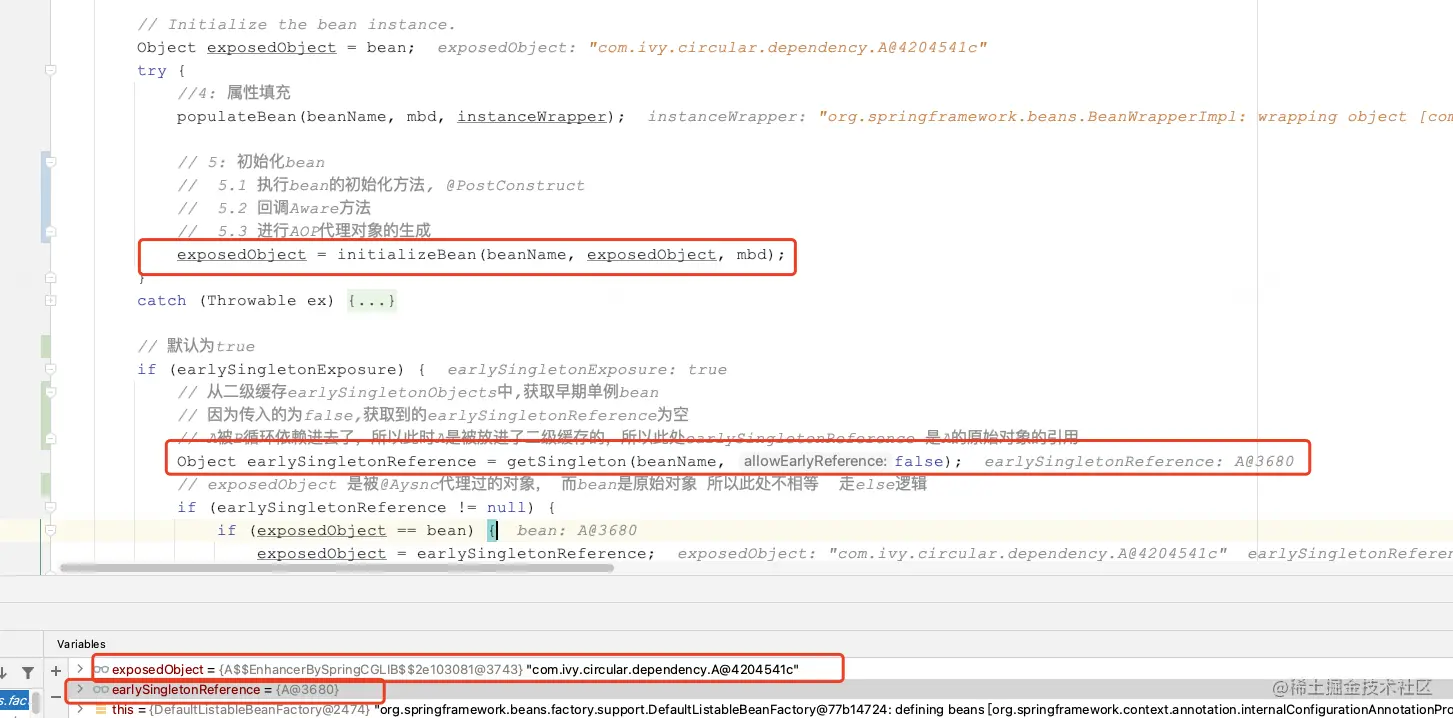
通过源码跟踪和debug,证实了我们的猜想:Spring管理的bean是单例的,所以Spring默认要保证使用该bean的地方,指向的都是一个地址,也就是都是最终版本的bean。像带有@Async的循环依赖,会导致在b中注入的a和最终放到容器的a不一致,所以Spring提供了这样的自检机制,防止这种问题的发生。
关于自检机制,我们在代理注释中详细进行了说明,不过小伙伴们可能有个疑惑:Spring发现二级缓存准获取的和最终暴露的不一致后,直接获取到依赖当前bean(这里是a)的bean集合,然后遍历判断:如果这些bean创建完成了,就说明注入的a有问题,抛出异常的逻辑依据是什么?
其实有这个疑问的小伙伴可能对前面我们说的注入过程还不够清楚。注入过程发生在属性填充阶段,流程是:从三级缓存取出ObjectFactory -> 调用getObject()生成对象-> 先放入了二级缓存 -> 反射注入给依赖它的属性,所以注入到其他依赖者进行属性填充的对象,和二级缓存中的同一个对象。二级缓存中对象和最终暴露的不一致,注入属性的对象当然和最终暴露的也不一致了。
还有一点需要小伙伴们注意,属性一旦注入后,是不会自动刷新的。所以:创建完成 -> 属性注入肯定完成 -> 注入的一定不是最终对象,这个条件是成立的,当然这样判断自然也是可以的。
啰嗦了这么久,相比大家应该知道为什么带有@Async的循环依赖的循环依赖无法支持了吧。其实就是从设计上就不想支持,是的,现实就是这么残忍。
3.3.1 @Async无法支持循环依赖的解决方案
- 把
allowRawInjectionDespiteWrapping设置为true
修改该参数的配置后,容器启动将不再报错了,但是:a的@Aysnc修饰的方法将不起作用了,因为b里面依赖的a是个原始对象,所以它最终没法执行异步操作( 即使容器内的a是个代理对象 )。 - 使用
@Lazy或者@ComponentScan(lazyInit = true)
@Component
public class B {
@Autowired
@Lazy
private A a;
public A getAService() {
return a;
}
}
本方案只需要在类B的依赖属性A a上加上@Lazy即可(因为是B希望依赖进来的是最终的代理对象进来,所以B加上即可,A上并不需要加)。但是需要稍微注意的是:此种情况下B里持有A的引用和Spring容器里的A并不是同一个,虽然两者都是代理对象。至于为什么,后面我们在讲解@Lazy的时候,再详细解释吧。等我哦
- 不要让
@Async的Bean参与循环依赖
显然该方案是解决它的最优方案,奈何它却是现实情况中最为难达到的方案。因为在实际业务开发中像循环依赖、类内方法调用等情况并不能避免,除非重新设计、按规范改变代码结构,因此 此种方案就见仁见智吧~