问题背景
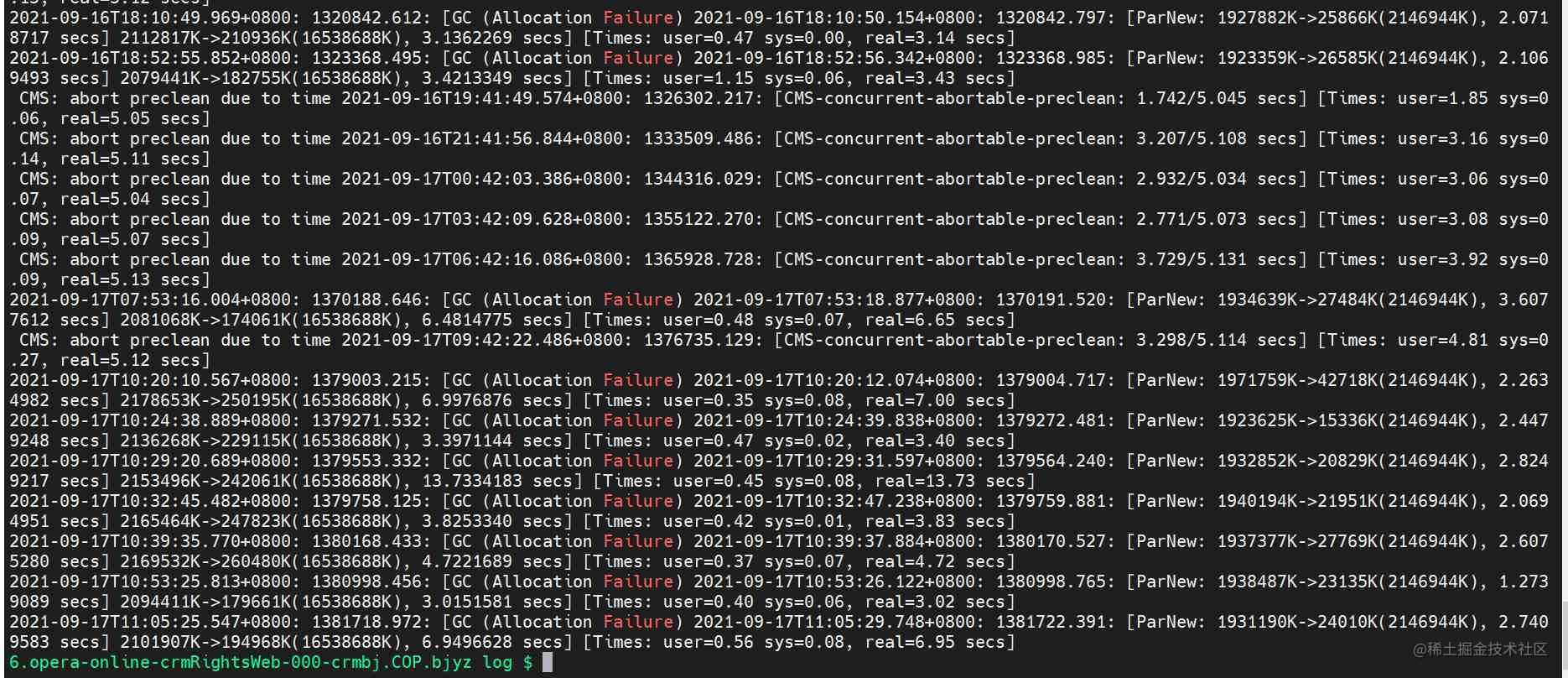
下游用户反馈在某个时间区间内接口响应过慢,通过APM监控发现批量接口出现响应时间过长。可以排除是接口自身问题,考虑排查机器CPU+JVM问题。
 shell : awk -F 'real=| secs\] ' '2>3{print $0}' /home/work/ /var/log/gc.log 把** 换成你们的地址**
shell : awk -F 'real=| secs\] ' '2>3{print $0}' /home/work/ /var/log/gc.log 把** 换成你们的地址**



结论支撑
在生产环境中,Java程序偶尔会因为记录JVM的GC日志,而被后台的IO(例如OS的页缓存回写)操作阻塞,出现长时间的STW停顿,在这些STW停顿过程中,JVM会暂停所有的应用程序线程,此时应用程序会停止对用户请求的响应,这对于要求低延迟的系统来说,因此导致的高延迟是不能接受的。 相关资料表明,导致这些停顿的原因,是当JVM GC(垃圾回收)在写GC时,由于write()系统调用锁造成的,对于这些日志的写入操作,即使是采用异步写模式(例如带缓存的IO或者非阻塞IO)仍然会被OS的页缓存回写等机制阻塞相当长的一段时间。
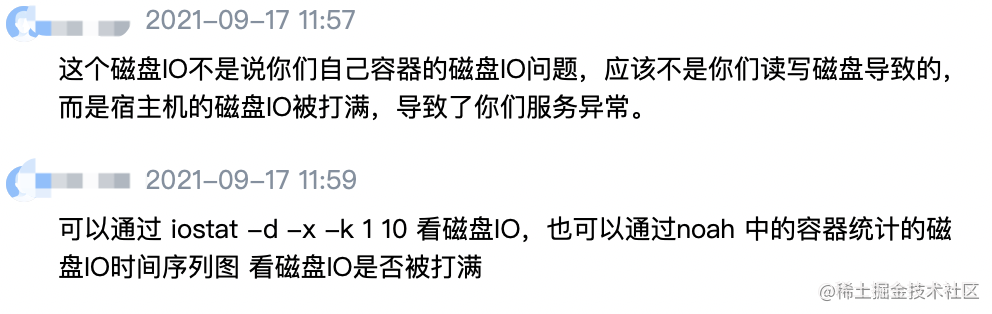
生产环境中的问题
当JVM管理的Java堆空间进行垃圾回收之后,JVM可能会停顿,并对应用程序造成STW停顿,根据在启动Java实例时指定的JVM选项,GC日志文件会记录不同类型的GC和JVM行为。但是通过本例我们发现,后台IO负载也会造成长时间的STW停顿,一些关键的Java应用程序发生许多无法解释的长时间STW停顿(>5s)。这些停顿既不能从应用程序层的逻辑,也无法从JVM GC行为的角度加以解释。如上面的例子,花费较大精力来调查这个问题。发现了问题,就应该找出相应的解决方案。
实验环境复现问题
对于这个导致无法解释的长时间JVM停顿的问题,我们开始尝试在实验环境中重现它。为了使该过程能够得到更好的控制并重复重现,我们设计了一个简单的压测程序,来代替复杂的生产环境应用程序。 我们将在两个场景下运行这个压测程序:含有后台IO行为以及不含有后台IO行为。不含有后台IO的场景我们称之为“基准线(baseline)”,而含有后台IO的场景用来重现问题。
压测程序
我们这个Java压测程序只是不断地生成10KB的对象,并放到一个队列中。当对象数量达到100000时,会从队列中删除一半的对象。因此堆中存放的对象最大数量就是100000个,大概会占用1GB的空间。这个过程会持续一段固定的时间(例如5分钟)。 这个程序的源代码和后台IO的生成脚本,都位于我们考虑的主要性能指标是长时间JVM GC停顿的数量。
网上博客的一篇复现过程借鉴学习一下
后台IO我们通过一个bash脚本,不断地复制大文件来模拟。后台程序会生成150MB/s的写入负载,可以使一个普通磁盘的IO变得足够繁忙。为了更好理解生成的IO负载的压力大小,我们使用“sar -d -p 2”来收集await(磁盘处理IO请求的平均时间(以毫秒计)),tps(每秒发往物理设备的传输总数)和wr_sec-per-s(写入设备的扇区数)。它们分别的平均数值为:await=421 ms, tps=305, wr_sec-per-s=302K。
系统准备
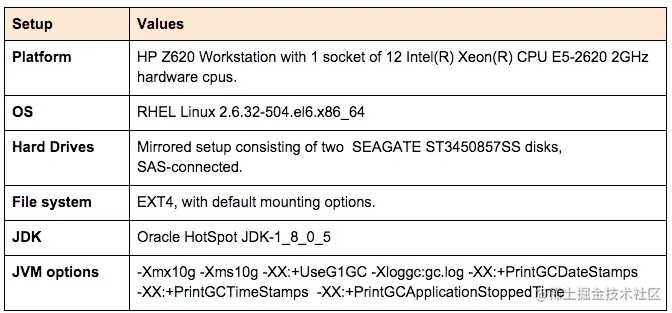
情景1 (不含后台IO负载)
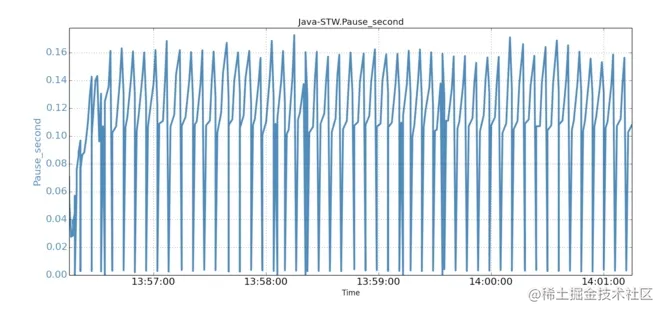
运行基准线测试不需要有后台IO。所有JVM GC 停顿的时间序列数据如下图所示。没有观察到超过250ms的停顿。
情景2 (含有后台IO负载)
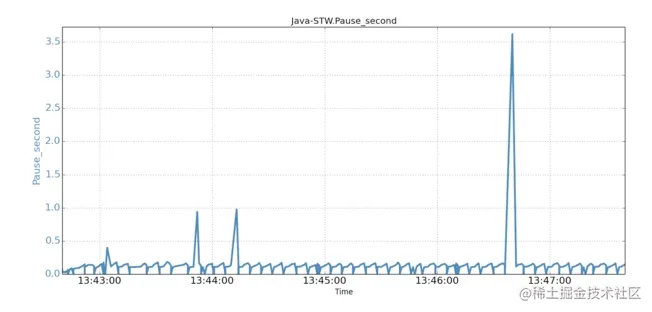
当后台IO开始运行后,在只有5分钟的运行时间内,压测程序就出现了一次超过3.6秒的STW停顿,以及3次超过0.5秒的停顿!
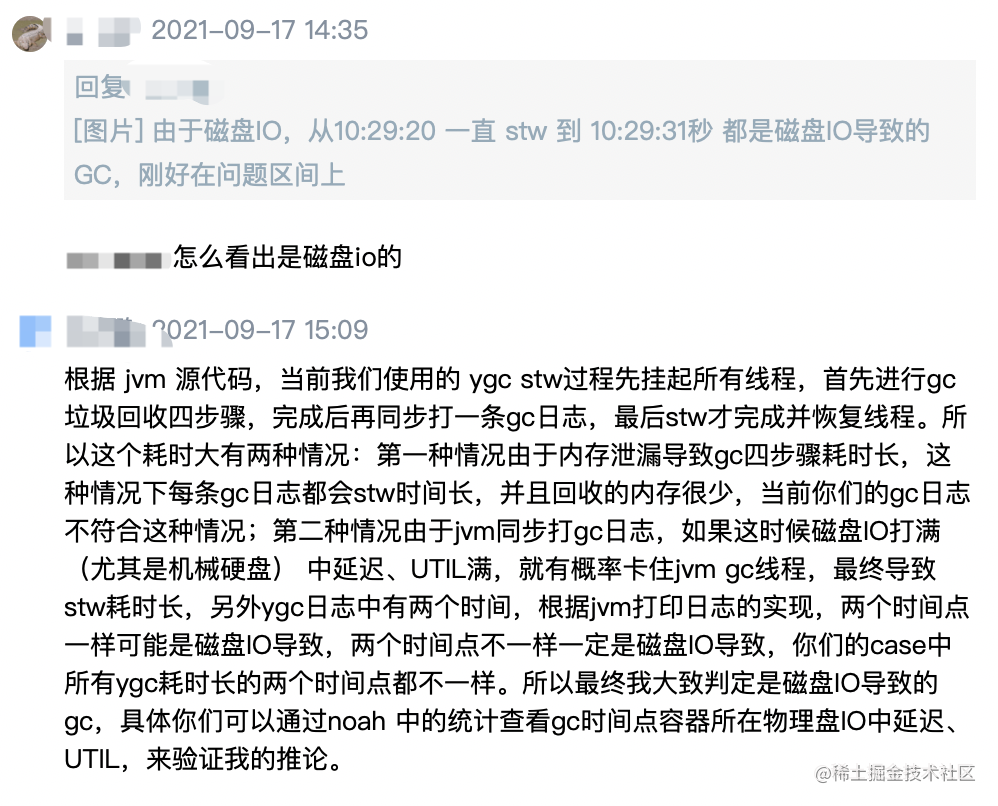
 为了了解是哪个系统调用引起了STW停顿,我们使用了strace来分析JVM实例产生的系统调用。 我们首先确认了JVM将GC信息记录到文件,使用的是异步IO的方式。我们又跟踪了JVM从启动后产生的所有系统调用。GC日志文件在异步模式下打开,并且没有观察到fsync()调用。 16:25:35.411993 open("gc.log", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3 <0.000073> 所捕获的用于打开GC日志文件的JVM系统调用open()。但是,跟踪结果显示,JVM发起的几个异步系统调用write()出现了不同寻常的长时间执行情况。通过检查系统调用和JVM停顿的时间戳,我们发现它们恰好吻合。在下图中,我们分别对比展示了两分钟内系统调用和JVM停顿的时间序列。
为了了解是哪个系统调用引起了STW停顿,我们使用了strace来分析JVM实例产生的系统调用。 我们首先确认了JVM将GC信息记录到文件,使用的是异步IO的方式。我们又跟踪了JVM从启动后产生的所有系统调用。GC日志文件在异步模式下打开,并且没有观察到fsync()调用。 16:25:35.411993 open("gc.log", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3 <0.000073> 所捕获的用于打开GC日志文件的JVM系统调用open()。但是,跟踪结果显示,JVM发起的几个异步系统调用write()出现了不同寻常的长时间执行情况。通过检查系统调用和JVM停顿的时间戳,我们发现它们恰好吻合。在下图中,我们分别对比展示了两分钟内系统调用和JVM停顿的时间序列。
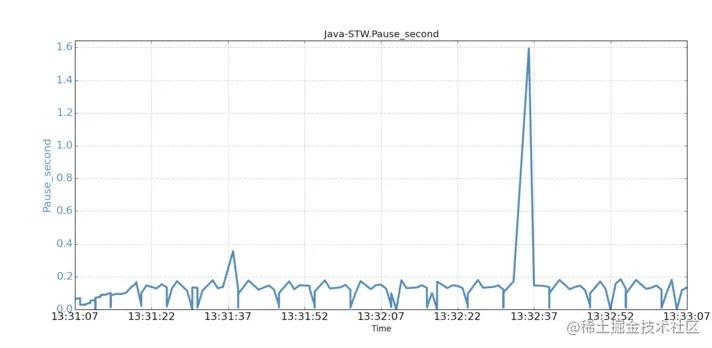 时间序列对比(JVM STW停顿)
时间序列对比(JVM STW停顿)
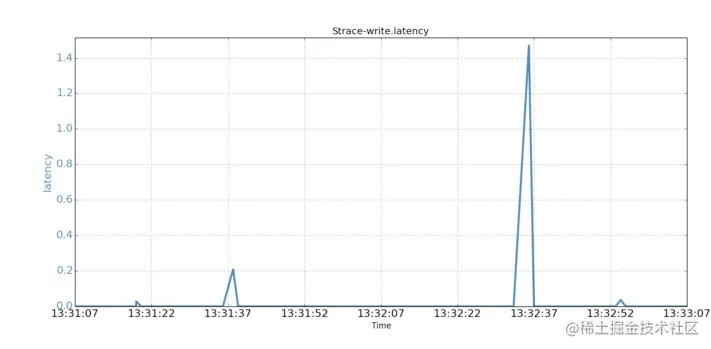 时间序列对比(系统调用write())
时间序列对比(系统调用write())
我们集中注意来看,位于13:32:35秒时最长达1.59秒的这次停顿,相应的GC日志和strace输出显示如下:
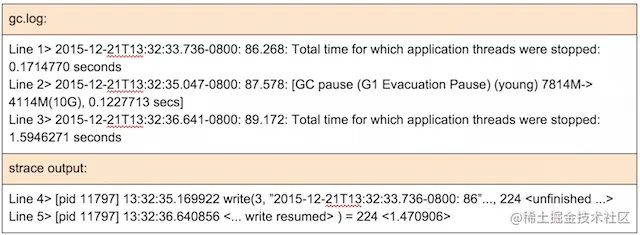 GC日志和strace输出 我们来试着理解一下发生了什么。
GC日志和strace输出 我们来试着理解一下发生了什么。
- 在35.04时(第2行),一次young GC开始了,并且经过0.12秒完成。
- 这次young GC完成于时间35.17,并且JVM试图通过一次系统调用 write()(第4行),将young GC的统计信息输出到gc日志文件中。
- write()调用被阻塞了1.47秒,最后于时间36.64(第5行)完成,花费了1.47秒的时间。
- 当write()调用于时间36.64返回JVM时,JVM记录下这次用时1.59秒的STW停顿(例如,0.12+0.47)(第3行)。
复现结论
在复现的过程中,可以看出实际的STW停顿时间包括两部分(1) GC时间(ygc等)(2)GC记录日志的时间(调用write()的时间)。这些数据说明, GC记录日志的过程发生在JVM的STW停顿过程中 ,并且 记录日志所用的时间也属于STW停顿时间的一部分 。特别需要说明,整个应用程序的停顿主要由两部分组成:由于JVM GC行为造成的停顿,以及为了记录JVM GC日志,系统调用write()被OS阻塞的时间。下面这张图展示了二者之间的关系。
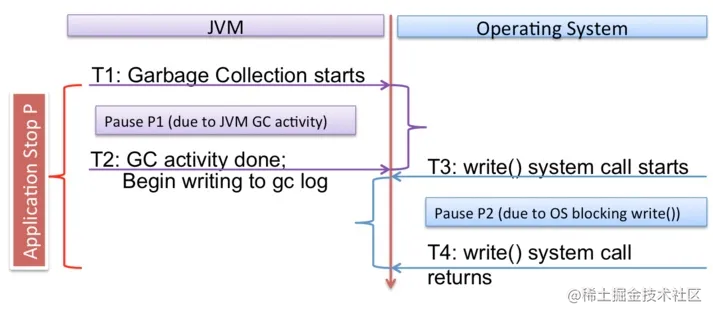 如果记录GC日志的过程(例如write()调用)被OS阻塞,阻塞时间也会被计算到STW的停顿时间内。新的问题是,为什么带有缓存的写入会被阻塞?在深入了解各种资料,包括操作系统内核的源代码之后,我们意识到带有缓存的写入可能被内核代码所阻塞。这里面有多重原因,包括:(1)“stable page write”和(2)“journal committing”。Stable page write: JVM对GC日志文件的写入,首先会使得相应的文件缓存页“变脏”。即使缓存页稍后会通过OS的回写机制被持久化到磁盘文件,但是在内存中使缓存页变脏的过程,由于“stable page write”仍然会受到页竞争的影响。在“stable page write”下,如果某页正处于OS回写过程中,那么对该页的write()调用就不得不等待回写完成。为了避免只有一部分新页被持久化到磁盘上,内核会锁定该页以确保数据一致性。 Journal committing: 对于带有日志(journaling)的文件系统,在写文件时都会生成相应的journal日志。当JVM向GC日志文件追加内容时,会产生新的块,因此文件系统则需要先将journal日志数据提交到磁盘。在提交journal日志的过程中,如果OS还有其他的IO行为,则提交可能需要等待。如果后台的IO行为非常繁重,那么等待时间可能会非常长。注意,EXT4文件系统有一个“delayed allocation”功能,可以将journal数据提交延迟到OS回写后再进行,从而降低等待时间。还要注意的是,将EXT4的数据模式从默认的“ordered”改成“writeback”并不能解决这个问题,因为journal数据需要在write-to-extend调用返回之前被持久化。
如果记录GC日志的过程(例如write()调用)被OS阻塞,阻塞时间也会被计算到STW的停顿时间内。新的问题是,为什么带有缓存的写入会被阻塞?在深入了解各种资料,包括操作系统内核的源代码之后,我们意识到带有缓存的写入可能被内核代码所阻塞。这里面有多重原因,包括:(1)“stable page write”和(2)“journal committing”。Stable page write: JVM对GC日志文件的写入,首先会使得相应的文件缓存页“变脏”。即使缓存页稍后会通过OS的回写机制被持久化到磁盘文件,但是在内存中使缓存页变脏的过程,由于“stable page write”仍然会受到页竞争的影响。在“stable page write”下,如果某页正处于OS回写过程中,那么对该页的write()调用就不得不等待回写完成。为了避免只有一部分新页被持久化到磁盘上,内核会锁定该页以确保数据一致性。 Journal committing: 对于带有日志(journaling)的文件系统,在写文件时都会生成相应的journal日志。当JVM向GC日志文件追加内容时,会产生新的块,因此文件系统则需要先将journal日志数据提交到磁盘。在提交journal日志的过程中,如果OS还有其他的IO行为,则提交可能需要等待。如果后台的IO行为非常繁重,那么等待时间可能会非常长。注意,EXT4文件系统有一个“delayed allocation”功能,可以将journal数据提交延迟到OS回写后再进行,从而降低等待时间。还要注意的是,将EXT4的数据模式从默认的“ordered”改成“writeback”并不能解决这个问题,因为journal数据需要在write-to-extend调用返回之前被持久化。
后台IO行为
从JVM垃圾回收的角度来看,通常的生产环境都无法避免后台的IO行为。这些IO行为有几个来源:(1)OS活动;(2)管理和监控软件;(3)其他共存的应用程序;(4)同一个JVM实例的IO行为。首先,OS包含许多机制(例如,”/proc“文件系统)会引起向底层磁盘写入数据。其次,像CFEngine这样的系统级软件也会进行磁盘IO操作。第三,如果当前节点上还存在其他共享磁盘的应用程序,那么这些应用程序都会争抢IO。第四,除了GC日志之外,JVM实例也可能以其他方式使用磁盘IO。
解决方案
由于当前HotSpot JVM实现(包括其他实现)中,GC日志会被后台的IO行为所阻塞,所以有一些解决方案可以避免写GC日志文件的问题。 首先,JVM实现完全可以解决掉这个问题。显然,如果将写GC日志的操作与可能会导致STW停顿的JVM GC处理过程分开,这个问题自然就不存在了。例如,JVM可以将记录GC日志的功能放到另一个线程中,独立来处理日志文件的写入,这样就不会增加STW停顿的时间了。但是,这种采用其他线程来处理的方式,可能会导致在JVM崩溃时丢失最后的GC日志信息。最好的方式,可能是提供一个JVM选项,让用户来选择适合的方式。 由于后台IO造成的STW停顿时间,与IO的繁重程度有关,所以我们可以采用多种方式来降低后台IO的压力。例如,不要在同一节点上安装其他IO密集型的应用程序,减少其他类型的日志行为,提高日志回滚频率等等。 对于低延迟应用程序(例如需要提供用户在线互动的程序),长时间的STW停顿(例如>0.25秒)是不可忍受的。因此,必须进行有针对性的优化。如果要避免因为OS导致的长时间STW停顿,首要措施就是要避免因为OS的IO行为导致写GC日志被阻塞。 一个解决办法是将GC日志文件放到tmpfs上(例如,-Xloggc:/tmpfs/gc.log)。因为tmpfs没有磁盘文件备份,所以tmpfs文件不会导致磁盘行为,因此也不会被磁盘IO阻塞。但是,这种方法存在两个问题:(1)当系统崩溃后,GC日志文件将会丢失;(2)它需要消耗物理内存。补救的方法是周期性的将日志文件备份到持久化存储上,以减少丢失量。 另一个办法是将GC日志文件放到SSD(固态硬盘,Solid-State Drives)上,它通常能提供更好的IO性能。根据IO负载情况,可以选择专门为GC日志提供一个SSD作为存储,或者与其他IO程序共用SSD。不过,这样就需要将SSD的成本考虑在内。 与使用SSD这样高成本的方案相比,更经济的方式是将GC日志文件放在单独一个HDD磁盘上。由于这块磁盘上只有记录GC日志的IO行为,所以这块专有的HDD磁盘应该可以满足低停顿的JVM性能要求。实际上,我们之前演示的场景一就可以看做为这一方案,因为在记录GC日志的磁盘上没有任何其他的IO行为。
结论
有低延迟要求的Java应用程序需要极短的JVM GC停顿。但是,当磁盘IO压力很大时,JVM可能被阻塞一段较长的时间。 我们对该问题进行了调查,并且发现如下原因:
- JVM GC需要通过发起系统调用write(),来记录GC行为。
- write()调用可以被后台磁盘IO所阻塞。
- 记录GC日志属于JVM停顿的一部分,因此write()调用的时间也会被计算在JVM STW的停顿时间内。
我们提出了一系列解决该问题的方案。重要的是,我们的发现可以帮助JVM实现来改进该问题。对于低延迟应用程序来说,最简单有效的措施是将GC日志文件放到单独的HDD或者高性能磁盘(例如SSD)上,来避免IO竞争。