如果本文有错,希望在下面的留言区指正。
最近在看书的时候,看到说使用 BloomFilter 来进行判断一个元素是否 最有可能 属于一个集合,或者它是 绝对不属于 这个集合。BloomFilter 不适合“零错误”的场合,只能在能容忍地错误率的场合下使用,BloomFilter 通过极少的错误换取了存储空间的极大节省。
在Java中并不提供 BloomFilter 集合框架,使用者需要导入google guava jar包,提供了 BloomFilter。
BloomFilter 是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。
原理
BloomFilter 的数据结构是由两部分构成:
- 一堆散列函数
- 一个位数组
如下所示,定义一个10位的数组:
[0,0,0,0,0,0,0,0,0,0]
在添加元素,先对添加的元素使用 k 个hash函数,来计算出 k 个在数组中的位置,然后,将这些位置的 bit 置为 1。
例如,把输入的x经过两次hash,给出的位置分别是0和4,将这两个位置bit置为1。
[1, 0, 0, 0, 1, 0, 0, 0, 0, 0]
为什么会出现可能出错
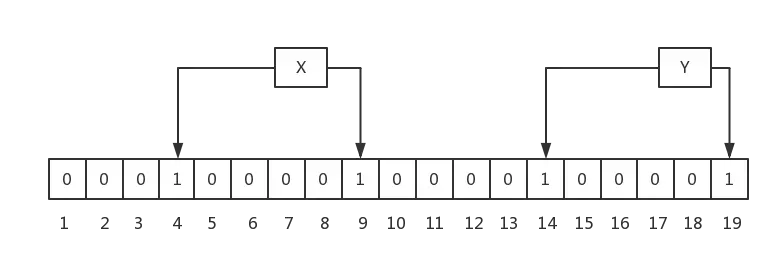
如下图所示,现在输入 x 和 y 两个数,分别把相应的位置置为1,当我们输入下一个元素 a 是,经过 hash 函数,得出的位置 3 和 13(下标从0开始),在数组中,其实不存在 a,但是这两个位置分别是 x和y的某个hash位置,所以就会出现开始所说的,某个元素可能存在集合中。
删除不可取
在 Bloomfilter 中不可删除元素,如果删除元素,会导致其他的一些元素不能被找到,当这些元素的某些下标和被删元素相同。