protocolbuffer (以下简称PB)是google 的一种数据交换的格式,它独立于语言,独立于平台。google 提供了多种语言的实现:java、c#、c++、go 和 python,每一种实现都包含了相应语言的编译器以及库文件。由于它是一种二进制的格式,比使用 xml 进行数据交换快许多。可以把它用于分布式应用之间的数据通信或者异构环境下的数据交换。作为一种效率和兼容性都很优秀的二进制数据传输格式,可以用于诸如网络传输、配置文件、数据存储等诸多领域。
1.ProtoBuf协议说明
proto文件定义了协议数据中的实体结构(message ,field)
- 关键字message: 代表了实体结构,由多个消息字段(field)组成。
- 消息字段(field): 包括数据类型、字段名、字段规则、字段唯一标识、默认值
- 数据类型:如下图所示
- 字段规则:
required:必须初始化字段,如果没有赋值,在数据序列化时会抛出异常
optional:可选字段,可以不必初始化。
repeated:数据可以重复(相当于java 中的Array或List)
字段唯一标识:序列化和反序列化将会使用到。
- 默认值:在定义消息字段时可以给出默认值。
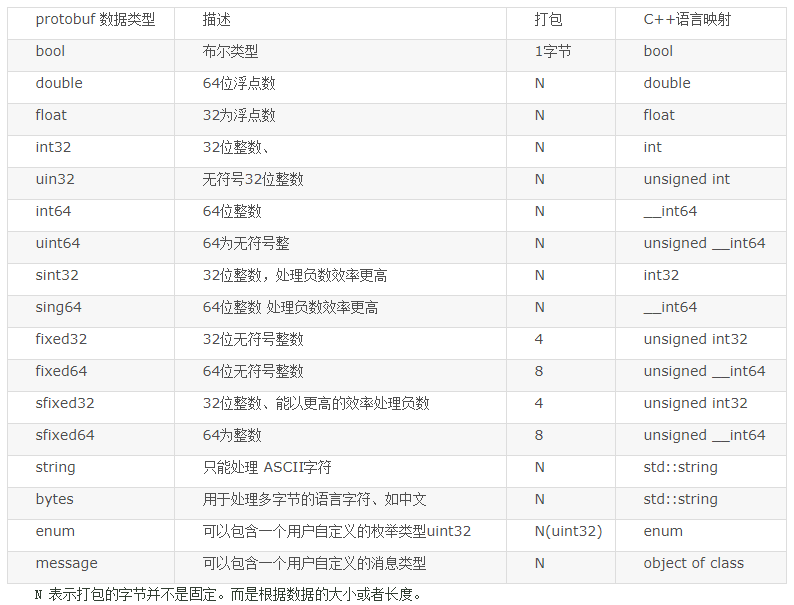
数据类型
2.ProtoBuf的使用流程
1.定义.proto文件
首先我们需要编写一个 proto 文件,定义我们程序中需要处理的结构化数据,在 protobuf 的术语中,结构化数据被称为 Message。proto 文件非常类似 java 或者 C 语言的数据定义。下面代码显示了例子应用中的 proto 文件内容:
package lm;
message helloworld
{
required int32 id = 1; // ID
required string str = 2; // str
optional int32 opt = 3; //optional field
}
一个比较好的习惯是认真对待 proto 文件的文件名。比如将命名规则定于如下:
packageName.MessageName.proto
在上例中,package 名字叫做 lm,定义了一个消息 helloworld,该消息有三个成员,类型为 int32 的 id,另一个为类型为 string 的成员 str。opt 是一个可选的成员,即消息中可以不包含该成员。
2.编译.proto文件
写好 proto 文件之后就可以用 Protobuf 编译器将该文件编译成目标语言了。可以根据不同的语言来选择不同的编译方式
在项目中我使用到的是分别是JavaScript和Java,前者是客户端脚本语言,后者服务端语言。将proto文件编译生成java文件,这里有一个很好的案例:《Protobuf协议的Java应用例子》,当然在项目中一般是不会这么干的,
3.序列化和反序列化
public class Test {
public static void main(String[] args) throws IOException {
//模拟将对象转成byte[],方便传输
PersonEntity.Person.Builder builder = PersonEntity.Person.newBuilder();
builder.setId(1);
builder.setName("ant");
builder.setEmail("ghb@soecode.com");
PersonEntity.Person person = builder.build();
System.out.println("before :"+ person.toString());
System.out.println("===========Person Byte==========");
for(byte b : person.toByteArray()){
System.out.print(b);
}
System.out.println();
System.out.println(person.toByteString());
System.out.println("================================");
//模拟接收Byte[],反序列化成Person类
byte[] byteArray =person.toByteArray();
Person p2 = Person.parseFrom(byteArray);
System.out.println("after :" +p2.toString());
}
}
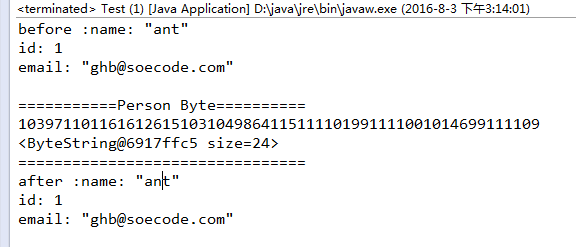
输出结果图
从上面可以总结出protobuf的使用过程可以分为以下三个,准备好数据,通过build()方法来组装成protobuf包,然后通过toByteArray()来将protobuf转换成二进制序列流文件(序列化)。
反序列化的过程刚好与之相反,接收到的二进制数据转换成二进制数组byte[],然后调用protobuf的parseFrom()方法即可实现反序列化。
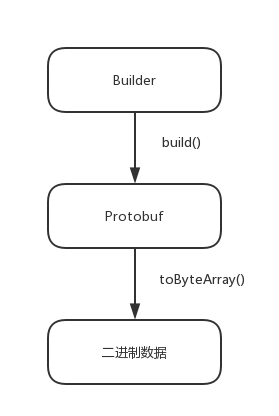
序列化流程图
3.protoBuf数据协议的优势
- 平台无关,语言无关,可扩展;
- 提供了友好的动态库,使用简单;
- 解析速度快,比对应的XML快约20-100倍;
- 序列化数据非常简洁、紧凑,与XML相比,其序列化之后的数据量约为1/3到1/10。
说明:
数据量小是因为,Protobuf 序列化后所生成的二进制消息非常紧凑,这得益于 Protobuf 采用的非常巧妙的little-endian编码方法。
转换速度快。首先我们来了解一下 XML 的封解包过程。XML 需要从文件中读取出字符串,再转换为 XML 文档对象结构模型。之后,再从 XML 文档对象结构模型中读取指定节点的字符串,最后再将这个字符串转换成指定类型的变量。这个过程非常复杂,其中将 XML 文件转换为文档对象结构模型的过程通常需要完成词法文法分析等大量消耗 CPU 的复杂计算。
反观 Protobuf,它只需要简单地将一个二进制序列,按照指定的格式读取到 C++ 对应的结构类型中就可以了。从上一节的描述可以看到消息的 decoding 过程也可以通过几个位移操作组成的表达式计算即可完成。速度非常快。