前言
多线程大家肯定都不陌生,理论滚瓜烂熟,八股天花乱坠,但是大家有多少在代码中实践过呢?很多人在实际开发中可能就用用@Async,new Thread()。线程池也很少有人会自己去建,默认的随便用用。在工作中大家对于多线程开发,大多是用在异步,比如发消息,但是对于提效这块最重要的优势却很少有人涉及。因此本篇文章会结合我自己的工作场景带大家去发掘项目中的多线程场景,让你的代码快如闪电。
多线程普及
多线程解决了什么问题?带来了什么问题?
Cpu为了均衡与内存的速度差异,增加了 缓存 --导致了可见性问题
操作系统增加了进程和线程, 分时复用CPU ,进而均衡CPU与IO设备的速度差异--导致了原子性问题
编译程序 优化指令排序 (JVM指令重排序)--导致了有序性问题
可见性 问题--线程A修改共享变量,修改后CPU缓存中的数据没有及时同步到内存,线程B读取了内存中老数据
原子性 问题--多个线程增加数据,有几个线程挂了,这数据就少了
有序性 问题--经典的对象创建三步,堆中分配内存-->初始化-->变量指向内存地址,如果排序重排会出现132,导致没有初始化的对象被创建
JVM提供了什么工具去解决线程不安全问题?Java代码有哪些实现思路?
JVM提供了三个关键词,synchronized、volatile、final和JMM(线程操作内存规范,例如8个happen before原则)
Java代码实践可从三方面入手
- 同步 :synchronized和ReentrantLock
- 非同步 :CAS
- 线程安全 :局部变量(虚拟机栈或者本地方法栈,线程私有)和ThreadLocal(本地线程变量副本,空间换安全,每个线程一份)
如何开启线程?
基础的Thread、runable、callable,进阶的ThreadExecutor和Future,以及JDK8的终极武器ComplableFuture
线程间如何协作?
基础三件套
- join()--Thread的join方法,在b线程中调用a.join(),b会等a执行完毕
- wait() notify() notifyAll()--Object类自带,等待与唤醒
- await() signal() signalAll()--JUC包中Condition类自带,与wait类似,但是增加了条件参数更加自由
进阶的有JDK5开始提供的Semaphore(信号量)、CyclicBarrier、CountDownLatch以及JDK8的ComplableFuture
场景实战
多线程处理场景
并行聚合处理数据
以下案例主要运用CompletableFuture.allOf()方法,将原本串行的操作改为并行。本案例相对比较常规,算是CompletableFuture的基本操作,其他特性就不一一介绍了。
AtomicReference<List<SellOrderList>> orderLists = new AtomicReference<>();
AtomicReference<List<InternationalSalesList>> salesLists = new AtomicReference<>();
AtomicReference<Map<String, BigDecimal>> productMap = new AtomicReference<>();
.........
//逻辑A
CompletableFuture<Void> orderListCom =
CompletableFuture.runAsync(() -> {
orderLists.set(sellOrderListService.lambdaQuery()
.ge(SellOrderList::getOrderCreateDate, startDate)
.le(SellOrderList::getOrderCreateDate, endDate)
.eq(SellOrderList::getIsDelete, 0).list());
});
CompletableFuture<Void> productCom = CompletableFuture.runAsync(() -> {
//逻辑B});
CompletableFuture<Void> euLineCom = CompletableFuture.runAsync(() -> {
//逻辑C});
//汇总线程操作
CompletableFuture.allOf(orderListCom, productCom, euCloudCom).handle((res, e) -> {
if (e != null) {
log.error("客户订单定时任务聚合数据异常", e);
} else {
try {
//获取全部数据后处理数据
aggregateData(customerList, saleMonth, orderLists, salesLists, productMap, euLineList, asLineList,
euCloudList, asCloudList, itemMap, deliveryMap, parities);
} catch (Exception ex) {
log.error("客户订单处理数据异常", ex);
}
}
return null;
});
修改for循环为并行操作
这里借鉴了parallelStream流的思路,将串行的for循环分割成多个集合后,对分割后的集合进行循环。这应该是最普遍的多线程应用场景了,需要注意的是线程池需要自定义大小、不安全的集合例如ArrayList并行add时需要加锁,加好日志就完事了。
//自建线程池,ForkJoinPool默认的太小,一般是逻辑CPU数量-1
int logicCpus = Runtime.getRuntime().availableProcessors();
ForkJoinPool forkJoinPool = new ForkJoinPool(logicCpus * 80);
//指定集合大小,避免频繁扩容
List<RedundantErpSl> slAddList = new ArrayList<>(50000);
//谷歌提供工具类切分集合--import com.google.common.collect.Lists;
List<List<SlErpDTO>> partition = Lists.partition(slErpList, 1000);
int finalLastStatus = lastStatus;
CompletableFuture<Void> handle = CompletableFuture.allOf(partition.stream().map(addPartitionList ->
CompletableFuture.runAsync(() -> {
for (SlErpDTO slErp : addPartitionList) {
//TODO 逻辑处理
synchronized (slAddList) {
//ArrayList线程不安全,多线程会出现数据覆盖,体现为数据丢失
slAddList.add(sl);
}
}
}, forkJoinPool)).toArray(CompletableFuture[]::new))
.whenComplete((res, e) -> {
if (e != null) {
log.error("多线程组装数据失败", e);
} else {
try {
//进一步处理循环后的结果
slService.batchSchedule(versionNum, slAddList);
} catch (Exception ex) {
log.error("批量插入失败", ex);
}
}
});
handle.join();
多线程新增
我个人在开发中会使用一些小工具来提高开发效率,接下来公开一个我常用的批量插入的小工具,这个小工具最开始是同事给我的,然后我做了优化和扩充,主要是扩充了多线程以及service块的代码。
总览
该工具类用于生成复制可用的代码,这里需要提前指定一些固定变量。除了entity和serviceName需要根据实际情况变化之外,方法名和参数名可以不变。生成了四个方法,分别是mapper类中的方法、mapper.xml中的foreach批量插入代码、普通无事务的多线程批量插入代码、多线程事务代码
//批量方法名,对应mapper和xml中id
String methodName = "batchSchedule";
//mapper参数名称
String paramName = "addList";
//实际代码里面的service命名
String serviceName = "baseInfoService";
Class<?> entity = BudgetBase.class;
//批量插入
printMapper(entity.getSimpleName(), methodName, paramName);
printXml(entity, methodName, paramName);
//普通多线程批量插入,无事务
printSave(entity.getSimpleName(), serviceName, paramName, 1000);
//多线程事务,慎用
printAddTransaction(entity.getSimpleName(), paramName, 1000);
mapper方法

xml批量插入语句
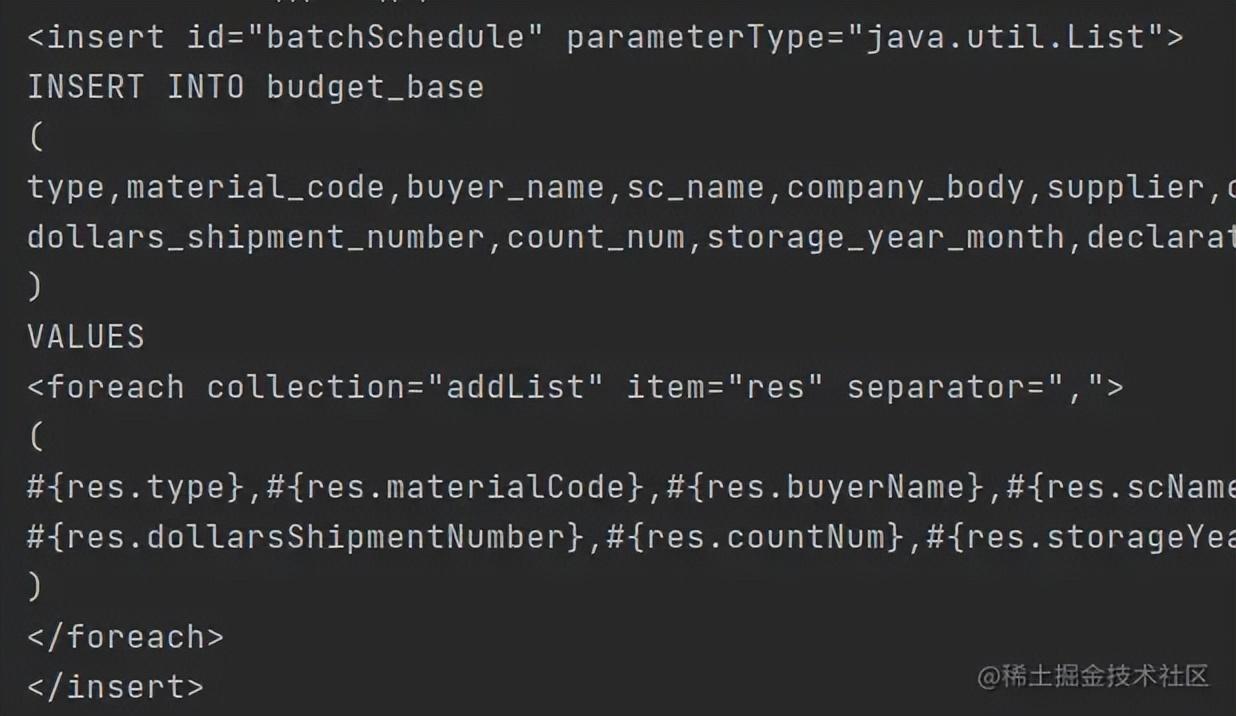
多线程批量插入
这个多线程插入其实就是我上面多线程处理场景中for循环改造的变种,将集合拆分进行并行批量插入
if (CollectionUtils.isNotEmpty(addList)) {
List<List<BudgetBase>> partition = Lists.partition(addList, 1000);
CompletableFuture.allOf(partition.stream().map(addPartitionList ->
CompletableFuture.runAsync(() -> baseInfoService.getBaseMapper().batchSchedule(addPartitionList)))
.toArray(CompletableFuture[]::new))
.exceptionally(e -> {
log.error("多线程处理异常", e);
return null;
});
}
花里胡哨-多线程事务提交
这个才是本文的重点,接下来我会详细介绍我在开发中遇到的坑和知识点,敲黑板了啊,重点来了!
我写的这个多线程事务本质就是根据2PC理论手写了一个分布式事务,涉及到 多线程、Spring事务、ThreadLocal、LockSupport 这些知识点,在线上一定要慎重使用,最好不用,可作炫技用,秀就完了。
深刻理解Spring事务、ThreadLocal
从头说起,既然是多线程事务,那自然不能使用注解@Transactional去开启事务,Spring事务采用ThreadLocal来做线程隔离,ThreadLocalMap内部key为当前线程的ThreadLocal对象,也可以当作以当前线程为key,value也是个map,看源码可以知道,map里面key为数据源,value为数据库连接。
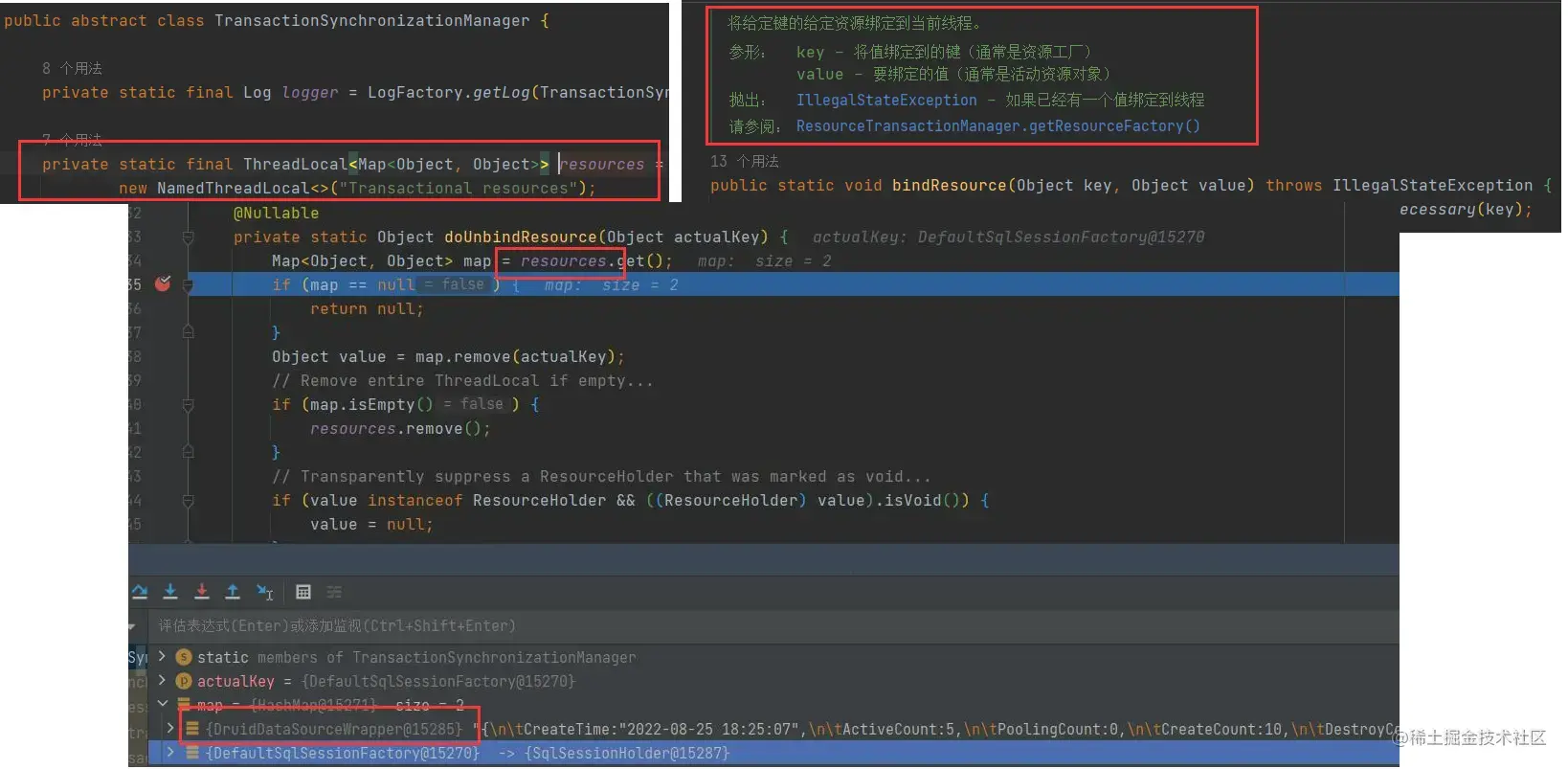
当然上来看源码,肯定认识不够深刻,接下来是一段错误代码示范,充分展示了理解上面那段话的重要性。我的第一次失败就是如下一段代码,首先肯定是能运行的,不能运行的例子我就不给了,先来看看这段代码。
//存储事务集合
List<TransactionStatus> traStatusList = new ArrayList<>();
//最外部更新或者删除时手动创建一个新事务
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
def.setIsolationLevel(TransactionDefinition.ISOLATION_READ_COMMITTED);
TransactionStatus statusStart = transactionManager.getTransaction(def);
traStatusList.add(statusStart);
//外部DML操作
lambdaUpdate().set(RedundantErpSl::getIsDelete, 1).set(RedundantErpSl::getUpdateTime, new Date())
.eq(RedundantErpSl::getVersionNum, versionNumber).eq(RedundantErpSl::getIsDelete, 0).update();
List<List<RedundantErpSl>> partition = Lists.partition(RedundantErpSlList, 1000);
try {
CompletableFuture<Void> future = CompletableFuture.allOf(partition.stream().map(addPartitionList ->
CompletableFuture.runAsync(() -> {
//Spring事务内部由ThreadLocal存储事务绑定信息,因此需要每个线程新开一个事务
DefaultTransactionDefinition defGo = new DefaultTransactionDefinition();
defGo.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
defGo.setIsolationLevel(TransactionDefinition.ISOLATION_READ_COMMITTED);
TransactionStatus statusGo = transactionManager.getTransaction(defGo);
//ArrayList线程不安全,多线程会出现数据覆盖,体现为数据丢失
synchronized (traStatusList) {
traStatusList.add(statusGo);
}
getBaseMapper().batchSchedule(addPartitionList);
})).toArray(CompletableFuture[]::new))
.exceptionally(e -> {
log.error("批量导入出现异常", e);
//向外抛出异常,确保最外面catch回滚
throw new PtmException(e.getMessage());
});
future.join();
for (TransactionStatus status : traStatusList) {
transactionManager.commit(status);
}
} catch (Exception e) {
log.error("批量导入出现异常回滚开始", e);
for (TransactionStatus status : traStatusList) {
transactionManager.rollback(status);
}
}
先说说这个错误例子我当时开发的思路,手动开启事务后,在每个线程操作开始的时候都创建一个事务,Spring事务传播级别用的
TransactionDefinition.PROPAGATION_REQUIRES_NEW,即默认创建新事务。隔离级别一开始没改,然后我就尝试着操作了一下,好家伙批量新增的时候直接锁了。
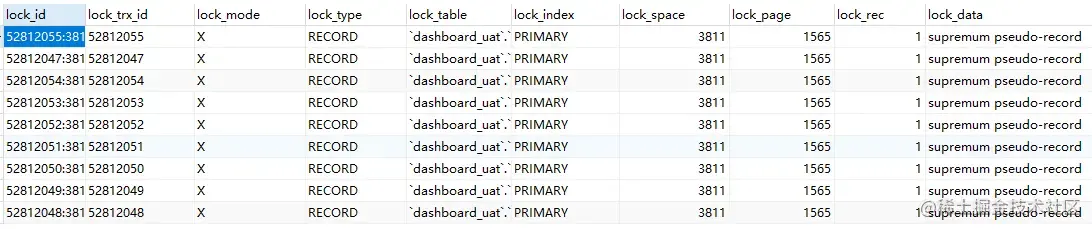
查看正在锁的事务 SELECT * FROM
INFORMATION_SCHEMA.INNODB_LOCKS;
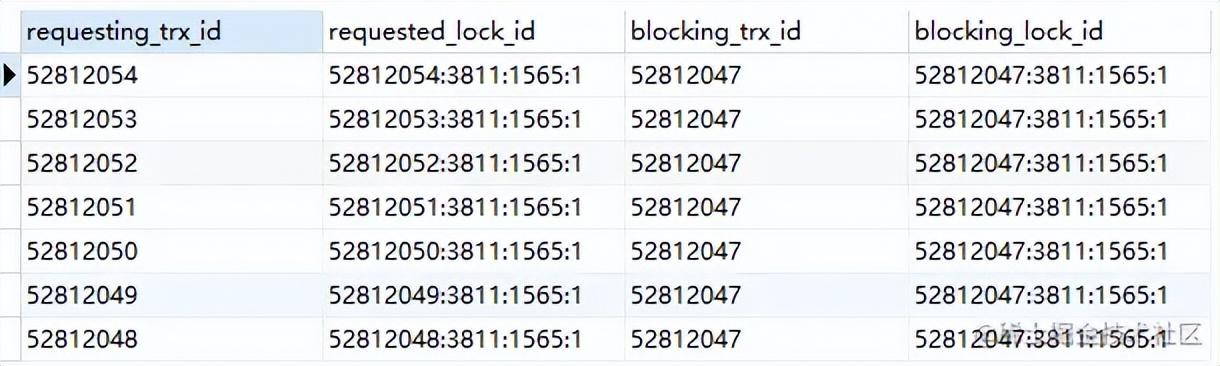
查看等待锁的事务 SELECT * FROM
INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
异常如下图,锁超时异常

第一次看见下图这个错的时候,我是疑惑的,没有当回事,以为是多数据源的问题。我项目里有直连Oracle和MySQL两种关系型数据库,当时怀疑是多数据源事务没有正确解绑导致的问题。
PS:事实上这个坑给足了我提示,根本原因就是多线程事务解绑失败,但是我理解出现了偏差,为后文埋下了伏笔。

我当时一看有锁,这我能惯着,马上修改事务隔离级别为
TransactionDefinition.ISOLATION_READ_COMMITTED读已提交(MySQL默认事务隔离级别为可重复读,这里下调了一级,总共四级)。
顺利插入但还是报上面这个错,错误位置是下面这个循环提交时报的,第二次循环的时候一定会报错。
for (TransactionStatus status : traStatusList) {
transactionManager.commit(status);
}
当时一度以为是多数据源的问题,但是Debug后发现resource里面只有一个数据源key,解绑一次后就没了,第二个循环解绑的时候就报上面这个错,因为找不到可以解绑的key了。我就很疑惑,为啥就一个数据源key,我不是在别的线程开了事务嘛,按理说开了多少个线程就有多少个事务,这个问题困扰了我大概一天左右的时间。然后我想到了Spring事务的实现原理ThreadLocal,然后联想到我的多线程开启事务,再看到我在主线程里面进行傻叉循环解绑,我瞬间为梦想窒息。
所以破案了,我在主线程是操作不了子线程事务,这也是代码报key找不到的原因,因为用主线程做key在ThreadLocal里肯定是拿不到子线程信息的,只能拿到主线程自己的。
多线程事务提交方案
因此解决方案就很简单,子线程的事务自己操作,那么多线程事务处理哪家强,JDK里找CompletableFuture!当然这里使用CountDownLatch也是可行的,网上也有案例。多线程事务在处理逻辑上其实和分布式事务很像,因此我这里采用2PC的思想,一阶段所有子线程全部开启事务并执行SQL,然后阻塞等待,二阶段判断是否全部成功,是就唤醒所有线程提交事务,否就全部回滚。
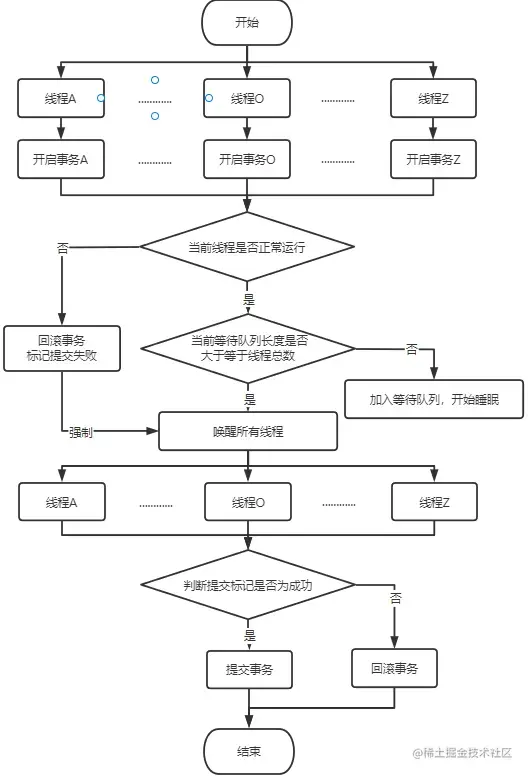
-----------需要注入Bean,一个是Spring Boot事务管理,一个是线程池-----------
@Autowired
private PlatformTransactionManager transactionManager;
@Autowired
@Qualifier("ioDenseExecutor")
private ThreadPoolTaskExecutor ioDense;
-----------多线程事务新增操作-----------
private void batchSchedule(List<BudgetBase> addList) {
if (!CollectionUtils.isEmpty(addList)) {
//定义局部变量,是否成功、顺序标识、等待线程队列
AtomicBoolean isSuccess = new AtomicBoolean(true);
AtomicInteger cur = new AtomicInteger(1);
List<Thread> unfinishedList = new ArrayList<>();
//切分新增集合
List<List<BudgetBase>> partition = Lists.partition(addList, 1000);
int totalSize = partition.size();
//多线程处理开始
CompletableFuture<Void> future =
CompletableFuture.allOf(partition.stream().map(addPartitionList -> CompletableFuture.runAsync(() -> {
//Spring事务内部由ThreadLocal存储事务绑定信息,因此需要每个线程新开一个事务
DefaultTransactionDefinition defGo = new DefaultTransactionDefinition();
defGo.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
TransactionStatus statusGo = transactionManager.getTransaction(defGo);
int curInt = cur.getAndIncrement();
try {
log.info("当前是第{}个线程开始启动,线程名={}", curInt, Thread.currentThread().getName());
baseInfoService.getBaseMapper().batchSchedule(addPartitionList);
log.info("当前是第{}个线程完成批量插入,开始加入等待队列,线程名={}", curInt, Thread.currentThread().getName());
//ArrayList线程不安全,多线程会出现数据覆盖,体现为数据丢失
synchronized (unfinishedList) {
unfinishedList.add(Thread.currentThread());
}
log.info("当前是第{}个线程已加入队列,开始休眠,线程名={}", curInt, Thread.currentThread().getName());
notifyAllThread(unfinishedList, totalSize, false);
LockSupport.park();
if (isSuccess.get()) {
log.info("当前是第{}个线程提交,线程名={}", curInt, Thread.currentThread().getName());
transactionManager.commit(statusGo);
} else {
log.info("当前是第{}个线程回滚,线程名={}", curInt, Thread.currentThread().getName());
transactionManager.rollback(statusGo);
}
} catch (Exception e) {
log.error("当前是第{}个线程出现异常,线程名={}", curInt, Thread.currentThread().getName(), e);
transactionManager.rollback(statusGo);
isSuccess.set(false);
notifyAllThread(unfinishedList, totalSize, true);
}
}, ioDense)).toArray(CompletableFuture[]::new));
future.join();
}
}
private void notifyAllThread(List<Thread> unfinishedList, int totalSize, boolean isForce) {
if (isForce || unfinishedList.size() >= totalSize) {
log.info("唤醒当前所有休眠线程,线程数={},总线程数={},是否强制={}", unfinishedList.size(), totalSize, isForce);
for (Thread thread : unfinishedList) {
log.info("当前线程={}被唤醒", thread.getName());
LockSupport.unpark(thread);
}
}
}
方案详解
为什么用LockSupport的park()和unpark()而不用Thread.sleep()、Object.wait()、Condition.await()?
- 更简单,不需要获取锁,能直接阻塞线程。
- 更直观,以thread为操作对象更符合阻塞线程的直观定义;
- 更精确,可以准确地唤醒某一个线程(notify随机唤醒一个线程,notifyAll唤醒所有等待的线程);
- 更灵活 ,unpark方法可以在park方法前调用。
第4点很重要,如果不能提前使用unpark()的话,按照代码逻辑最后一个线程会被永久阻塞。
为什么要自建线程池?
CompletableFuture默认的线程池ForkJoinPool.commonPool()偏向于计算密集型任务处理,核心线程数和逻辑CPU数少1,对于多线程事务这种IO密集型任务来说核心线程数偏少。并且上述方法在操作中都是阻塞线程,无法一次性开启全部线程的话,会导致notifyAllThread方法无法执行,老线程阻塞新线程无法开启,就尬住了。
ForkJoinPool基于工作窃取算法,所以最适合的是计算密集型任务,这里我们开启一个参数调整为IO密集型(多核心少队列)的ThreadPoolTaskExecutor线程池即可。
注意MySQL/Druid等数据库的最大连接数
使用多线程的时候也别忘了调整其他组件的最大连接数。Druid线程池这个代码配置可以调,MySQL5.7默认151得用配置文件调整。