一、基础知识
1)为什么要学习 Java8
Java 8 所做的改变,在许多方面比Java 历史上任何一次改变都更加深远,这些改变会让你的编程更加容易
例子:
传统写法:
List<Person> personList = Arrays.asList(new Person(21,50),new Person(22,55),new Person(23,60));
Collections.sort(personList, new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getWeight().compareTo(o2.getWeight());
}
});
Java 8写法:
personList.sort(Comparator.comparing(Person::getWeight));
熟悉 Linux 操作的同学对这个指令应该不默认:
cat testFile | tr "[A-Z]" "[a-z]" | sort | tail -3
这种操作便是基于流式操作,cat 会把文件转换创建成一个流,然后tr会转换流中字符,sort会对流中的行进行排序,tail -3则会输出流的最后三行。这种就像是流水线操作,经过每个中转站,将处理完的结果转入下一个处理中心,最后得到最终结果。
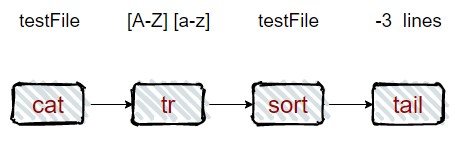
Java 8 的第一个编程思想就是 流处理 ,流式一系列数据项,一次只生成一项,程序可以从输入流中一个一个读取数据项,然后以同样的方式将数据项写入输出流。一个程序的输出流很可能就是另一个程序的输入流。
函数传递
已知一个集合中有以下几种花:
List<Flower> flowerList = Arrays.asList(new Flower("red", 6), new Flower("yellow", 7), new Flower("pink", 8));
这个时候如果我想要红花,那么传统写法是这样子的:
List<Flower> resList = new ArrayList<>();
for (Flower flower : flowerList) {
if (StringUtils.equals("red", flower.getColor())) {
resList.add(flower);
}
}
那么如果我想要8块钱以下的花,那么写法就是这样的:
List<Flower> resList = new ArrayList<>();
for (Flower flower : flowerList) {
if (flower.getPrice() < 8) {
resList.add(flower);
}
}
其实代码写法大部分都是一样的,只是判断的条件不一样,那么我们进行第一版优化 :
我们将判断方法抽取出来:
public static boolean isRed(Flower flower) {
return StringUtils.equals("red", flower.getColor());
}
public static boolean isLowPrice(Flower flower) {
return flower.getPrice() < 8;
}
借助函数式接口Predicate,将我们自定义的方法传递进去:
public static List<Flower> filterFlower(List<Flower> flowers, Predicate<Flower> p) {
List<Flower> resList = new ArrayList<>();
for (Flower flower : flowers) {
if (p.test(flower)) {
resList.add(flower);
}
}
return resList;
}
使用:
filterFlower(flowerList,Flower::isRed);
filterFlower(flowerList,Flower::isLowPrice);
我们也可以借助 Lambda 流来传递函数,就可以不用事先写好判断函数了:
filterFlower(flowerList, (Flower f) -> StringUtils.equals("red", f.getColor()));
filterFlower(flowerList, (Flower f) -> f.getPrice() < 8);
默认方法
在 Java 8 之前我们可以实现一个接口然后被强制重写这个接口的方法,那么隐含着很多问题:如果动物类新增一个fly()方法,那么其实dog这个类是不需要fly这个方法的,但是如果不重写就会编译报错。因此在 Java 8 之后也设计了默认方法这一种方式巧妙的解决了这种问题。
interface Animal {
void eat();
void fly();
}
class bird implements Animal {
@Override
public void eat() {}
@Override
public void fly() {
System.out.println("bird fly");
}
}
class dog implements Animal {
@Override
public void eat() {}
}
Java 8 之后可以这样写:
interface Animal {
void eat();
default void fly() {
System.out.println("animal fly");
}
}
class bird implements Animal {
@Override
public void eat() {}
@Override
public void fly() {
System.out.println("bird fly");
}
}
class dog implements Animal {
@Override
public void eat() {}
}
以上便是 Java 8 的部分特性,那么接下来就让我们来了解 Java 8的使用
2)行为参数化
开发中,我们需要应对不断的需求,怎么样才能做到自适应可扩展就是我们要关注的地方。
需求1:筛选出红色的花
public static List<Flower> filterFlower(List<Flower> flowers) {
List<Flower> resList = new ArrayList<>();
for (Flower flower : flowers) {
if (StringUtils.equals("red", flower.getColor())) {
resList.add(flower);
}
}
}
需求2:筛选出绿色的话
聪明的你肯定想到了我们可以通过传递一个颜色参数来过滤花朵,而不用每一次都修改主要代码。
public static List<Flower> filterFlowerByColor(List<Flower> flowers, String color) {
List<Flower> resList = new ArrayList<>();
for (Flower flower : flowers) {
if (StringUtils.equals(color, flower.getColor())) {
resList.add(flower);
}
}
}
需求3:筛选出价格小于8块钱的花
这样子我们只能再写一个方法来实现这个需求,为了防止后续价格的变化,聪明的我们提前将价格设置成可变参数。
public static List<Flower> filterFlowerByPrice(List<Flower> flowers, Integer price) {
List<Flower> resList = new ArrayList<>();
for (Flower flower : flowers) {
if (flower.getPrice() < price) {
resList.add(flower);
}
}
}
为了保持代码的整洁,我们被迫重写了一个方法来实现上述的需求:
public static List<Flower> filterFlower(List<Flower> flowers, String color, Integer price, Boolean flag) {
List<Flower> resList = new ArrayList<>();
for (Flower flower : flowers) {
if ((flag && flower.getPrice() < price) ||
(!flag && StringUtils.equals(color, flower.getColor()))) {
resList.add(flower);
}
}
return resList;
}
通过flag来控制要筛选价格类型的花还是颜色类型的花,但是这种写法实在是不美观。
那么,我们既然都能把花的属性作为参数进行传递,那么我们能不能我们能不能把过滤花的这种行为也作为一个参数进行传递,想着想着,你就动起了手:
首先定义一个过滤行为的接口:
interface FilterPrecidate {
boolean test(Flower flower);
}
然后自定义两个行为过滤类继承这个接口:
class RedColorFilterPredicate implements FilterPrecidate {
@Override
public boolean test(Flower flower) {
return StringUtils.equals("red", flower.getColor());
}
}
class LowPriceFilterPredicate implements FilterPrecidate {
@Override
public boolean test(Flower flower) {
return flower.getPrice() < 8;
}
}
然后重写我们的过滤方法,通过将行为作为参数传递:
public static List<Flower> filterFlower(List<Flower> flowers, FilterPrecidate filter) {
List<Flower> resList = new ArrayList<>();
for (Flower flower : flowers) {
if (filter.test(flower)) {
resList.add(flower);
}
}
return resList;
}
/***** 使用 *****/
filterFlower(flowerList,new RedColorFilterPredicate());
filterFlower(flowerList,new LowPriceFilterPredicate());
这样子我们的代码已经很明了,但是我们再观察一下上面的方法,filterFlower()这个方法只能传递对象作为参数,而FilterPrecidate对象的核心方法也只有test(),如果我们有新的行为就需要新建一个类继承FilterPrecidate接口实现test()方法。那么我们有没有办法直接将test()这一个行为作为参数传递,答案是有的:Lombda.
filterFlower(flowerList, (Flower flower) -> flower.getPrice() > 8);
我们甚至可以将多种行为作为作为一个参数传递:
filterFlower(flowerList, (Flower flower) -> flower.getPrice() > 8 && StringUtils.equals("red", flower.getColor()));
可以看到,行为参数化是一个很有用的模式,它能够轻松地使用不断变化的需求,这种模式可以把一个行为封装起来,并通过传递和使用创建的行为将方法的行为参数化。
它可以替代匿名类
如果我们将一个鲜花的集合按照价格进行排序,我们会这样做:
Collections.sort(flowerList, new Comparator<Flower>() {
@Override
public int compare(Flower o1, Flower o2) {
return o1.getPrice().compareTo(o2.getPrice());
}
});
那么通过行为参数化我们可以这样写:
Collections.sort(flowerList,(o1, o2) -> o1.getPrice().compareTo(o2.getPrice()));
也可以这样写:
Collections.sort(flowerList, Comparator.comparing(Flower::getPrice));
甚至可以这样写:
flowerList.sort(Comparator.comparing(Flower::getPrice));
对比一下传统写法,你是不是已经开始爱上这种方式的写法了
3)初识 Lambda
Lambda可以理解为是一种简洁的匿名函数的表示方式:它没有名称,但它有参数列表,函数主体,返回类型,还可以有一个可以抛出的异常。
Lambda表达式鼓励采用行为参数化的风格。利用Lambda表达式我们可以自定义一个Comparator对象
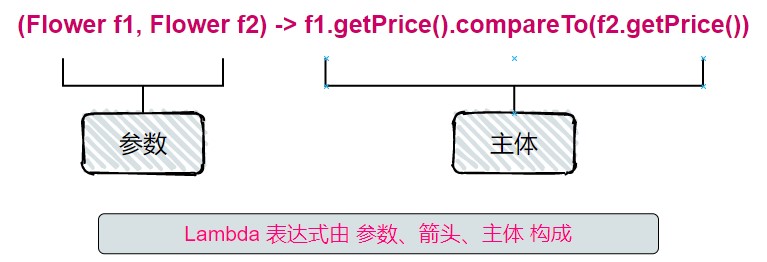
Lambda 例子
-
(String s)-> s.length():从一个对象中抽取值,具有一个 String 类型的参数,返回一个 int 类型的值, Lambda 表达式没有 return 语句,已经隐含了 return -
(Flower f) -> f.getPrice() > 8:布尔表达式,具有一个 Flower 类型的参数,返回一个 boolean 类型的值 -
(String s) -> {System.out.print(s);}:消费一个对象,具有一个 String 类型的参数,没有返回值(void) -
() -> new Flower("red",8):创建一个对象,没有传入参数,返回一个 int 类型的值(1)
函数式接口
函数式接口就是只定义一个抽象方法的接口,并使用@FunctionalInterface标记。
例如 :
public interface Comparator<T>{
int compare(T o1, T o2);
}
public interface Runnable{
void run();
}
public interface ActionListener extends EventListener{
void actionPerformed(ActionEvent e);
}
public interface Callable<V>{
V call();
}
Lambda 表达式可以允许直接以内联的形式为函数式接口的抽象方法提供实现,并把整个表达式作为函数式接口的示例(Lambda表达式就是函数式接口一个具体实现的示例)。
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("这是传统的写法");
}
};
Runnable r = () -> System.out.println("这是使用 Lambda 的写法");
使用函数式接口
Predicate
这个接口中定义了一个test()的抽象方法,它接受泛型 T 对象,并返回一个 boolean。你如果需要 表示一个涉及类型 T 的布尔表达式时,就可以使用这个接口。
public static List<Flower> filterFlower(List<Flower> flowers, Predicate<Flower> p) {
List<Flower> resList = new ArrayList<>();
for (Flower flower : flowers) {
if (p.test(flower)) {
resList.add(flower);
}
}
return resList;
}
/***** 使用方式 *****/
filterFlower(flowerList, (Flower flower) -> flower.getPrice() > 8);
Consumer
这个接口定义了一个accept()的抽象方法,它接受泛型 T 对象,没有返回(void)。你如果需要访问类型 T 的对象,并对其执行某些操作,就可以使用这个接口。
List<Integer> nums = Arrays.asList(1,2,3,4);
nums.forEach(integer -> System.out.println(integer));
Function
这个接口定义了一个apply()的抽象方法,它接受泛型 T 对象,并返回一个泛型 R 的对象。你如果需要定义一个Lambda,将输入对象的信息映射输出,就可以使用这个接口。
(String s) -> s.length()
Supplier
这个接口定义了一个get()的抽象方法,它没有传入参数,会返回一个泛型 T 的对象,如果你需要定义一个 Lambda,输出自定义的对象,就可以使用这个接口。
Callable<Integer> call = () -> 1 ;
类型检查
以这个为例子:
filter(flowerList, (Flower flower) -> flower.getPrice() > 8);
-
首先找出 filter 方法的声明
-
要求第二个参数是 Predicate 类型的对象
-
Predicate 是一个函数式接口,定义了一个
test()的抽象方法,并返回一个boolean 类型的值
类型推断
filterFlower(flowerList, (Flower flower) -> flower.getPrice() > 8);
我们可以继续将这个代码简化为:
filterFlower(flowerList, f -> f.getPrice() > 8);
使用局部变量
Lambda 表达式不仅能够使用主体里面的参数,也能够使用自由变量(在外层作用域中定义的变量)。
int tmpNum = 1;
Runnable r = () -> System.out.println(tmpNum);
注意点: Lambda 表达式对于全局变量和静态变量可以没有限制的使用,但是对于局部变量必须显示声明为 final
因为实例变量是存储在堆中,而局部变量是存储在栈中,属于线程私有的。而 Lambda 是在一个线程中使用的,访问局部变量只是在访问这个变量的副本,而不是访问原始值。
方法引用
方法引用就是让你根据已有的方法实现来创建 Lambda表达式。可以看做是单一方法的 Lambda 的语法糖。
例子 :
List<Flower> flowerList = Arrays.asList(new Flower("red", 6), new Flower("yellow", 7), new Flower("pink", 8));
-
(Flower f)->f.getPrice();==>Flower::getPrice -
flowerList.stream().map(t -> t.getPrice()).collect(Collectors.toList());===>flowerList.stream().map(Flower::getPrice).collect(Collectors.toList());
List<Integer> nums = Arrays.asList(1, 2, 3, 4);
nums.forEach(integer -> System.out.println(integer));===>nums.forEach(System.out::println);
如何构建方法引用
-
指向静态方法的方法引用(Integer的sum方法 ==
Integer::sum) -
指向任意类型示例方法的方法引用(String的length方法 ==
String::length) -
指向现有对象的示例方法的方法引用(flower实例的getPrice方法 ==
flower::getPrice)
复合 Lambda 表达式
比较器复合
我们有一组鲜花集合如下:
List<Flower> flowerList = Arrays.asList(new Flower("red", 6), new Flower("yellow", 7), new Flower("pink", 8), new Flower("white", 8));
按鲜花的价格进行排序:
flowerList.sort(Comparator.comparing(Flower::getPrice));
这样子默认是使用升序进行排列的,那么我们如果想进项降序:使用 reversed()
flowerList.sort(Comparator.comparing(Flower::getPrice).reversed());
这里的粉花和白花的价格一样,那我们在价格排序完后再按照颜色排序那应该怎么做:使用 thenComparing()
flowerList.sort(Comparator.comparing(Flower::getPrice).thenComparing(Flower::getColor));
谓词复合
用于Predicate接口
negate:非
Predicate<Flower> redFlower = (t) -> StringUtils.equals("red",t.getColor());
Predicate<Flower> notRedFlower = redFlower.negate();
and:且
Predicate<Flower> redFlower = (t) -> StringUtils.equals("red", t.getColor());
Predicate<Flower> lowPriceFlower = (t) -> t.getPrice() < 8;
Predicate<Flower> redAndLowPriceFlower = redFlower.and(lowPriceFlower);
or:或
Predicate<Flower> redFlower = (t) -> StringUtils.equals("red", t.getColor());
Predicate<Flower> lowPriceFlower = (t) -> t.getPrice() < 8;
Predicate<Flower> redOrLowPriceFlower = redFlower.or(lowPriceFlower);
函数复合
用于Function接口
andThen
Function<Integer, Integer> addRes = a1 -> a1 + 1;
Function<Integer, Integer> mulRes = a1 -> a1 * 2;
Function<Integer, Integer> andThenResult = addRes.andThen(mulRes);
Integer apply = andThenResult.apply(1); // 结果为 4 ==> (1 + 1) * 2
compose
Function<Integer, Integer> addRes = a1 -> a1 + 1;
Function<Integer, Integer> mulRes = a1 -> a1 * 2;
Function<Integer, Integer> composeResult = addRes.compose(mulRes);
Integer apply = composeResult.apply(1); // 结果为 3 ==> (1 * 2) + 1
两者的区别就是操作的顺序不一样
二、函数式数据处理
1)流的使用
集合是 Java 中使用最多的API。流是 Java API 的新成员,它允许以声明式方式处理数据集合,可以看作是遍历数据集的高级迭代器。而且,刘海可以透明地并行处理,这样就可以无需多写任何多线程代码了。
现在有一组花的集合如下:
List<Flower> flowerList = Arrays.asList(new Flower("red", 10), new Flower("yellow", 7), new Flower("pink", 8), new Flower("white", 8), new Flower("black", 12));
需求:获取10块钱以下并且按照价格排序的花的颜色
传统写法:
List<Flower> lowPriceFlowers = new ArrayList<>();
for (Flower flower : flowerList) {
if (flower.getPrice() < 10) {
lowPriceFlowers.add(flower);
}
}
Collections.sort(lowPriceFlowers, new Comparator<Flower>() {
@Override
public int compare(Flower o1, Flower o2) {
return o1.getPrice().compareTo(o2.getPrice());
}
});
List<String> lowPriceFlowerColor = new ArrayList<>();
for (Flower priceFlower : lowPriceFlowers) {
lowPriceFlowerNames.add(priceFlower.getColor());
}
为了完成这个需求不仅代码量大,还多定义了lowPriceFlowers 这个临时变量,真的是糟糕透了! Java 8 之后,代码才应该有它该有的样子:
List<String> colorList = flowerList.stream().filter(t->t.getPrice()<10).sorted(Comparator.comparing(Flower::getPrice)).map(Flower::getColor).collect(Collectors.toList());
通过filter筛选出10元以下的花,然后通过sorted按照花的价格进行排序,再通过map映射出花的颜色,最后通过collect将流归约成一个集合。filter 处理的结果传给了 sorted 方法,再传给 map 方法,最后传给 collect 方法。
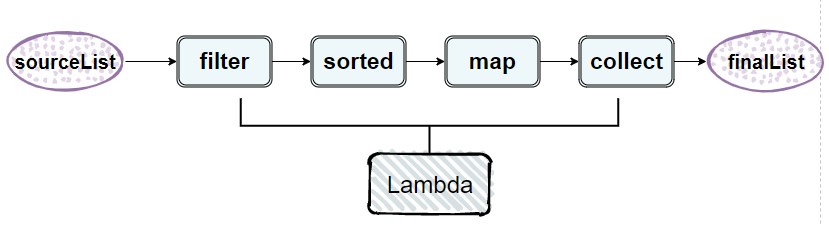
甚至我们还可以利用多核架构并行执行这段代码,只需要把stream()换成parallelStream()
flowerList.parallelStream().filter(t->t.getPrice()<10).sorted(Comparator.comparing(Flower::getPrice)).map(Flower::getColor).collect(Collectors.toList());
因为 filter 、sorted 、map 和 collect 等操作是与具体线程模型无关的高层次构件,所以它们的内部实现可以是单线程的,也可能透明地充分利用你的多核架构!在实践中,这意味着你用不着为了让某些数据处理任务并行而去操心线程和锁。
2)流和集合
集合与流之间的差异就在于什么时候进行计算。集合是一个内存中的数据结构,它包含数据结构中目前所有的值——集合中的每个元素都得先算出来才能添加到集合中。流则是在概念上固定的数据结构(你不能添加或删除元素),其元素则是按需计算的。从另一个角度来说,流就像是一个延迟创建的集合:只有在消费者要求的时候才会计算值。
只能遍历一次:和迭代器类似,流只能遍历一次。遍历完之后,这个流已经被消费掉了。你可以从原始数据源那里再获得一个新的流来重新遍历一遍。
List<String> color = Arrays.asList("red", "yellow", "pink");
Stream<String> s = title.stream();
s.forEach(System.out::println); //在这里 流已经被消费了
s.forEach(System.out::println); //如果这里再消费流则会报错!
3)流的操作
流可以拆成三大操作:
获取流 -> 中间操作 -> 终端操作
List<String> colorList = flowerList.stream() //获取流
.filter(t->t.getPrice()<10) //中间操作
.limit(3) //中间操作
.map(Flower::getColor) //中间操作
.collect(Collectors.toList());//终端操作
中间操作:
| 操作 | 返回类型 | 操作参数 |
|---|---|---|
| filter | Stream | Predicate |
| map | Stream | Funcation<T,R> |
| limit | Stream | |
| sorted | Stream | Comparator |
| distinct | Stream | |
| skip | Stream | long |
| limit | Stream | long |
| flatMap | Stream | Funcation<T,Steam> |
终端操作
| 操作 | 返回类型 | 操作参数 |
|---|---|---|
| forEach | void | Consumer |
| count | long | |
| collect | R | Collector<T,A,R> |
| anyMatch | boolean | Predicate |
| noneMatch | boolean | Predicate |
| allMatch | boolean | Predicate |
| findAny | Optional | |
| findFirst | Optional | |
| reduce | Optional | BinaryOperator |
(1)使用流
筛选 :filter
List<String> colorList = flowerList.stream().filter(t->t.getPrice()<10).collect(Collectors.toList());
筛选去重 :distinct
List<Integer> numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream().filter(i -> i % 2 == 0).distinct().forEach(System.out::println);
筛选截断 :limit
List<String> colorList = flowerList.stream().filter(t->t.getPrice()<10).limit(3).collect(Collectors.toList());
筛选跳跃 :skip
List<String> colorList = flowerList.stream().filter(t->t.getPrice()<10).skip(2).collect(Collectors.toList());
(2)映射
流支持 map() 方法,它会接受一个函数作为参数,这个行数会被应用到每个元素上,并将其映射成一个新的元素。
List<String> colors = flowerList.stream().map(Flower::getColor).collect(Collectors.toList());
它是创建一个新的集合,而不是修改原有的集合
(3)流的扁平化
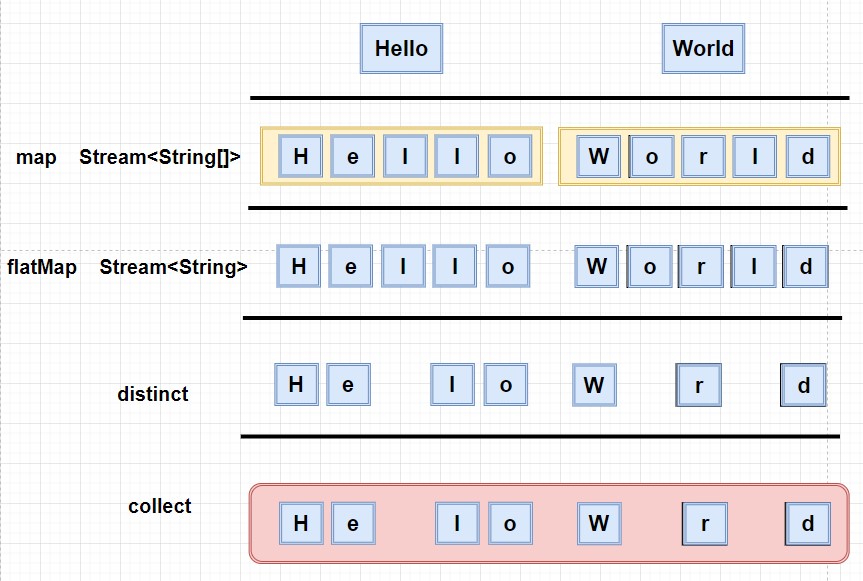
将一个单词的集合,拆分成各个字母的集合:
[Hello,World] ===> [H, e, l, o, W, r, d]
首先我们尝试使用map看能不能解决问题:
List<String> words = Arrays.asList("Hello","World");
words.stream().map(t->t.split("")).distinct().collect(Collectors.toList());
/***** 结果 *****
[[Ljava.lang.String;@2cdf8d8a, [Ljava.lang.String;@30946e09]
**/
可以看到,这样处理后的结果是一个数组的集合,并不是我们想要的结果,这是因为map返回的流实际上是Stream类型的。但是我们想要的是
Stream来表示一个字符流。
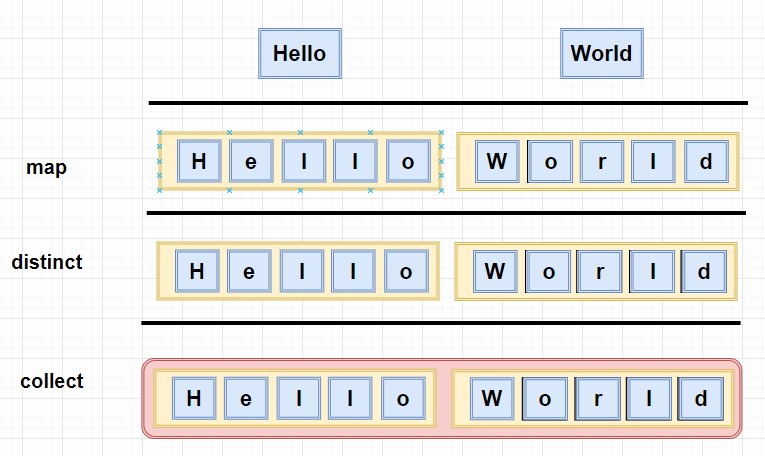
既然需要Stream的字符流,那我们使用Arrays.stream()来处理试一下:
words.stream().map(t -> t.split("")).map(Arrays::stream).distinct.collect(Collectors.toList());
/***** 结果 *****
[java.util.stream.ReferencePipeline$Head@1698c449, java.util.stream.ReferencePipeline$Head@5ef04b5]
**/
这是返回了一个Stream的集合,貌似只要将这个集合处理合并一下就可以解决问题了。所以flatMap()出现了。
words.stream().map(t->t.split("")).flatMap(t -> Arrays.stream(t)).distinct().collect(Collectors.toList());
/***** 结果 *****
[H, e, l, o, W, r, d]
**/
果然,已经成功解决了问题,flatMap方法就是让你把一个流中的每个值都转成另一个流,然后把所有的流连接起来成为一个流。
(4)匹配
anyMatch()
流中是否有一个元素能够匹配所给定谓词,只有有一个匹配上就返回 true
boolean res = flowerList.stream().anyMatch(t -> t.getPrice() < 8);
allMatch()
流中的元素是否都能匹配给定的谓词,所有匹配上才能返回 true
boolean res = flowerList.stream().allMatch(t -> t.getPrice() < 8);
noneMatch()
流中没有任何元素与给定的谓词相匹配,有一个匹配就会返回 false
boolean res = flowerList.stream().noneMatch(t -> t.getPrice() < 8);
(5)查找
findAny
返回当前流中的任意元素
flowerList.stream().filter(t->t.getPrice()<8).findAny();
findFirst
返回当前流中的第一个元素
flowerList.stream().filter(t->t.getPrice()<8).findFirst();
(6)归约
reduce 接收两个参数,一个是初始值,一个是将集合中所有元素结合的操作
reduce也支持一个参数,将集合中所有元素结合的操作,不过返回的是一个 Option ,Option 下面会讲到
List nums = Arrays.asList(1,2,3,4,5,6,7,8,9);
元素求和
传统写法:
int res = 0;
for (Integer num : nums) {
res += num;
}
改进后:
// 两个参数版
int res = nums.stream().reduce(0,(a, b) -> a + b);
int res = nums.stream().reduce(0,Integer::sum);
// 一个参数版
Optional<Integer> o = nums.stream().reduce(Integer::sum);
最大值和最小值
传统写法:
int max = 0;
int min = Integer.MAX_VALUE;
for (Integer num : nums) {
if (num > max) {
max = num;
}
if (num < min) {
min = num;
}
}
改进后:
// 两个参数版
int max = nums.stream().reduce(0,Integer::max);
int min = nums.stream().reduce(Integer.MAX_VALUE,Integer::min);
// 一个参数版
Optional<Integer> maxOption = nums.stream().reduce(Integer::max);
Optional<Integer> minOption = nums.stream().reduce(Integer::min);
(7)小练习(出于网上)
(1) 找出2011年发生的所有交易,并按交易额排序(从低到高)。 (2) 交易员都在哪些不同的城市工作过? (3) 查找所有来自于剑桥的交易员,并按姓名排序。 (4) 返回所有交易员的姓名字符串,按字母顺序排序。 (5) 有没有交易员是在米兰工作的? (6) 打印生活在剑桥的交易员的所有交易额。 (7) 所有交易中,最高的交易额是多少? (8) 找到交易额最小的交易
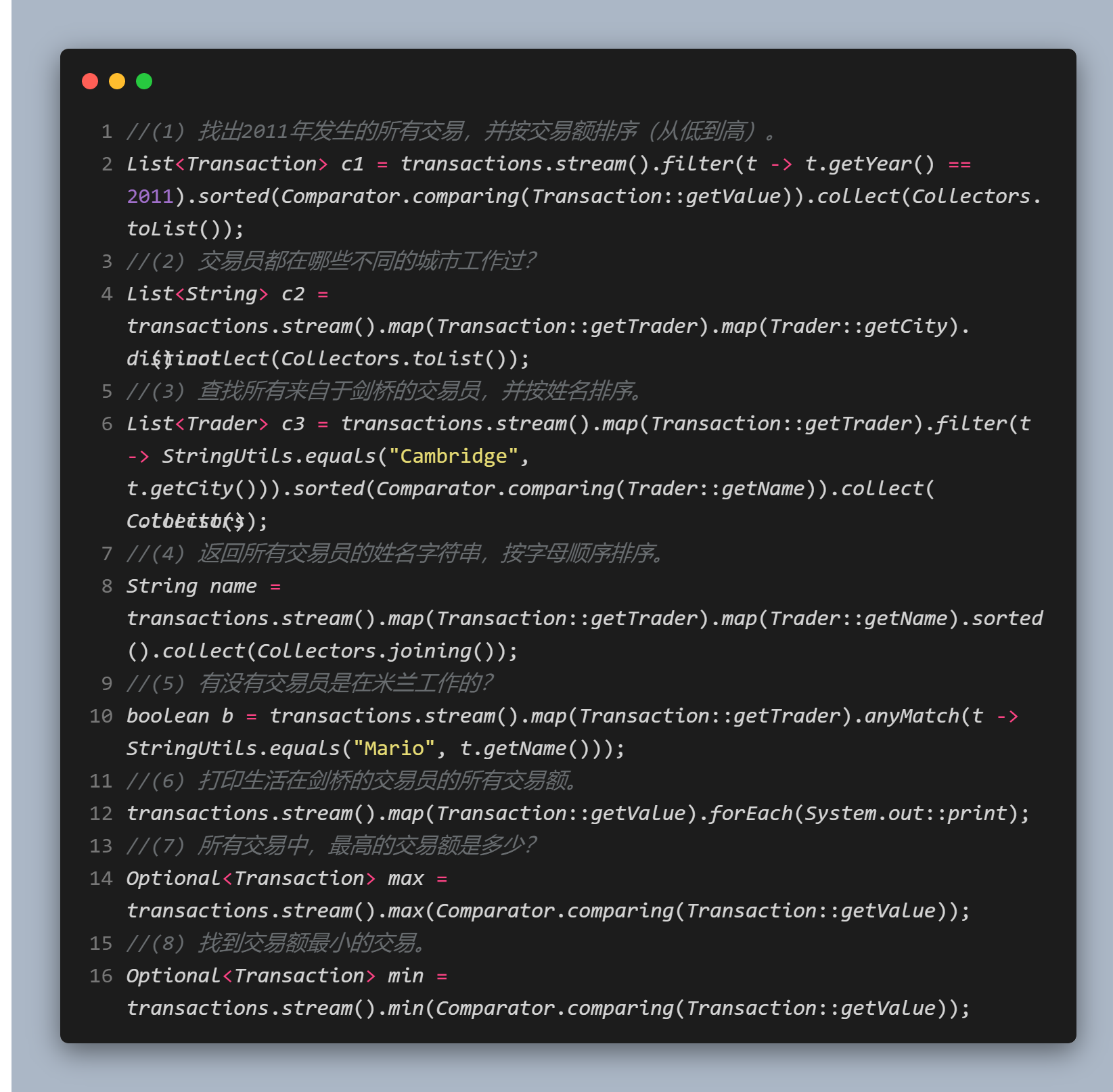
答案:
4)流的构建
- 由值创建流:
Stream.of()/Stream.empty()
Stream<String> stream = Stream.of("hello","world");
Stream<String> emptyStream = Stream.empty();
- 由数组创建流:
Arrays.stream()
int[] numbers = {2, 3, 5, 7, 11, 13};
int sum = Arrays.stream(numbers).sum();
- 由文件生成流:
File.lines()
long uniqueWords = 0;
try(Stream<String> lines =
Files.lines(Paths.get("data.txt"), Charset.defaultCharset())){
uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" ")))
.distinct()
.count();
}catch(IOException e){
}
// 使用 Files.lines 得到一个流,其中的每个元素都是给定文件中的一行。然后,你可以对 line 调用 split 方法将行拆分成单词
5)收集器的使用
如今有一组花的集合如下:
List<Flower> flowerList = Arrays.asList(new Flower("red", 10), new Flower("yellow", 7), new Flower("pink", 8), new Flower("yellow", 8), new Flower("red", 12));
这个时候我想按照花的颜色进行分类,获取一个Map>
传统写法:
Map<String, List<Flower>> listMap = new HashMap<>();
for (Flower flower : flowerList) {
if (null == listMap.get(flower.getColor())) {
List<Flower> flowers = new ArrayList<>();
listMap.put(flower.getColor(), flowerList);
}
listMap.get(flower.getColor()).add(flower);
}
相信以上代码是比较常见的,那么当我们学习了 Java 8之后有没有什么比较好的写法呢:
Map<String,List<Flower>> map = flowerList.stream().collect(Collectors.groupingBy(Flower::getColor));
一行代码解决,Java 8 真的是秀啊!
函数式变成的一个主要优势就是,我们只要告诉它 “做什么”,而不用关心*“怎么做”*。就像是上一个例子中,我们需要的是按颜色分组,所以我们只要跟收集器说 按照颜色分组就行collect(Collectors.groupingBy(Flower::getColor))。我们上面也比较经常用到的是collect(Collectors.toList(),它的作用就是将我们需要的结果收集成一个集合。
用来计算总数:
Long c1 = flowerList.stream().collect(Collectors.counting());
//也可以直接用 count() 方法来计数
Long c2 = flowerList.stream().count();
用来查找最大值和最小值:
Optional<Flower> max = flowerList.stream().collect(Collectors.maxBy(Comparator.comparing(Flower::getPrice)));
Optional<Flower> min = flowerList.stream().collect(Collectors.minBy(Comparator.comparing(Flower::getPrice)));
用来求和:
Integer sum = flowerList.stream().collect(Collectors.summingInt(Flower::getPrice));
用来求平均数:
Double avg = flowerList.stream().collect(Collectors.averagingInt(Flower::getPrice));
用来连接字符串:
String color = flowerList.stream().map(Flower::getColor).collect(Collectors.joining(", "));
6)分组的使用
如今有一组花的集合如下:
List<Flower> flowerList = Arrays.asList(new Flower("red", 10), new Flower("yellow", 7), new Flower("pink", 8), new Flower("yellow", 8), new Flower("red", 12));
/***** 结果 *****
{red=[Flower(color=red, price=10), Flower(color=red, price=12)], pink=[Flower(color=pink, price=8)], yellow=[Flower(color=yellow, price=7), Flower(color=yellow, price=8)]}
**/
按照颜色分组:Map>
Map<String,List<Flower>> color = flowerList.stream().collect(Collectors.groupingBy(Flower::getColor));
/***** 结果 *****
{red=[Flower(color=red, price=10), Flower(color=red, price=12)], pink=[Flower(color=pink, price=8)], yellow=[Flower(color=yellow, price=7), Flower(color=yellow, price=8)]}
**/
统计每种颜色的数量:Map
Map<String, Long> longMap = flowerList.stream().collect(Collectors.groupingBy(Flower::getColor, Collectors.counting()));
/***** 结果 *****
{red=2, pink=1, yellow=2}
**/
也可以支持多级分组
先按颜色分组,再按价格分组:Map>>
Map<String, Map<String, List<Flower>>> collect = flowerList.stream().collect(Collectors.groupingBy(Flower::getColor, Collectors.groupingBy(t -> {
if (t.getPrice() < 8) {
return "LOW_PRICE";
} else {
return "HIGHT_PRICE";
}
})));
/***** 结果 *****
{red={HIGHT_PRICE=[Flower(color=red, price=10), Flower(color=red, price=12)]}, pink={HIGHT_PRICE=[Flower(color=pink, price=8)]}, yellow={HIGHT_PRICE=[Flower(color=yellow, price=8)], LOW_PRICE=[Flower(color=yellow, price=7)]}}
**/
先按颜色分组,再找每个颜色中最贵的花:Map
Map<String, Flower> f = flowerList.stream().collect(Collectors.groupingBy(Flower::getColor, Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparingInt(Flower::getPrice)), Optional::get)));
/***** 结果 *****
{red=Flower(color=red, price=12), pink=Flower(color=pink, price=8), yellow=Flower(color=yellow, price=8)}
**/
这个工厂方法接受两个参数——要转换的收集器以及转换函数,并返回另一个收集器。
这个收集器相当于旧收集器的一个包装, collect 操作的最后一步就是将返回值用转换函数做一个映射。在这里,被包起来的收集器就是用 maxBy 建立的那个,而转换函数 Optional::get 则把返回的 Optional 中的值提取出来。
Collectors 的常用方法
| 方法 | 返回类型 | 用途 |
|---|---|---|
| toList | List | 把流中所有项目都收集到一个List |
| toSet | Set | 把流中所有项目都收集到一个Set,删除重复项 |
| toCollection | Collection | 把流中所有项目收集到给定的供应源创建的集合 |
| counting | Long | 计算流中元素的个数 |
| summingInt | Integer | 对流中项目的一个整数属性求和 |
| averagingInt | Double | 计算流中项目Integer属性的平均值 |
| joining | String | 连接对流中每个项目调用toString方法所生成的字符串 |
| maxBy | Optional | 一个包裹了流中按照给定比较器选出最大元素的Optional,如果为空则为Optional.empty() |
| minBy | Optional | 一个包裹了流中按照给定比较器选出最小元素的Optional,如果为空则为Optional.empty() |
| reducing | 归约操作产生的类型 | 从一个作为累加器的初始值开始,利用BinaryOperator与流中的元素组个结合,从而将流归约成单个值 |
| collectingAndThen | 转换函数返回的类型 | 包裹另一个收集器,对其结果应用转换函数 |
| groupingBy | Map<K,List> | 根据项目的一个属性的值对流中的项目作为组,并将属性值作为结果Map的键 |
三、学会使用Optional
开发中最经常遇到的异常某过于NullPointException了吧。因为这就是我们为了方便甚至不可避免的像 null 引用这样的构造所付出的代价。Java 8之后仿佛出现了转机,那就是用Optional来代替null。
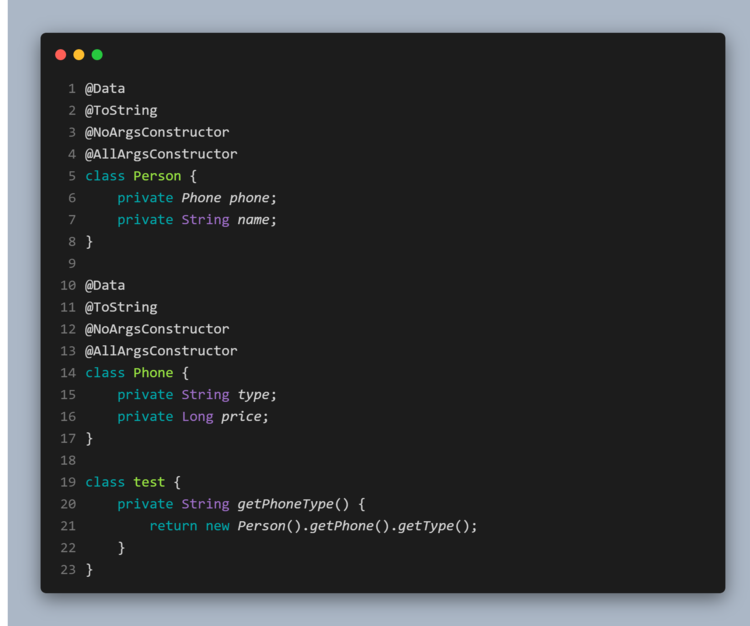
上面这段代码乍看之下应该没啥问题,平时开发的时候也很有可能会情不自禁的写出类似这种的代码。但是问题也就来了,真的是每个人都有手机吗,如果new Person().getPhone()获取不到手机,那么调用getType()是不是就会出现熟悉的NullPointException异常了。
1)防御式检查
为了避免空指针异常,Java 8出现的Optional为我们很好的避免了。
经典预防方式
private String getPhoneType(Person person) {
if (person != null) {
Phone phone = person.getPhone();
if (phone != null) {
return phone.getType();
}
}
return "";
}
每次引用都做一次判空操作,效果想必也不赖,也可以避免空指针异常。当时每一次判空都得添加一个 if 判断,真实让人头大。
Optional 预防
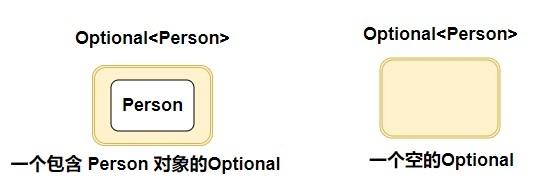
从图中可以看出 Optional相当于是一个容器,里面可以装 T 类型的对象。当变量不存在的时候,缺失的值就会被建模成一个“空”的Optional对象,由方法Optional.empty()返回。这就是Optional.empty()和null的区别,如果引用一个 null,那结果肯定是会触发NullPointException异常,但是引用Optional.empty()则没事。
上述代码可修改为:
private String getPhoneType(Person person) {
return Optional.ofNullable(person).map(Person::getPhone).map(Phone::getType).orElse("");
}
一行代码搞定,干净利落。
2)学会使用Option
创建Optional对象
创建一个空的Optional
Optional personOpt = Optional.empty()
创建一个非空的Optional
Optional personOpt = Optional.of(person)
Optional.of()不接受空值。如果 person 是一个空值则会抛出 NullPointException 异常,而不是等你试图访问 person 的属性才抛出异常。
创建一个可接受空值的Optional
Optional personOpt = Optional.ofNullable(Person)
如果 person 是 null ,那么得到的 Optional 对象就是个空对象。
使用map
Optional 中的 map()方法和流中的map()相似,都是从Optional对象中提取和转换值。
Optional<String> name = Optional.ofNullable(person).map(Person::getName);
获取到的是一个Optional对象是为了防止获取到一个 null,我们可以通过Optional.get()来获取值。
默认行为
我们可以使用get()方法来获取 Optional 的值,也可以使用orElse()来定义一个默认值,遭遇到空的Optional值的时候,默认值会作为该方法的调用返回值。以下是Optional的常用方法:
get()
最简单但又是最不安全的方法,如果变量存在,则直接返回封装的变量值,反之则抛出NullpointException异常。
orElse(T other)
允许自己定义一个默认值在Optional为空的时候返回。
orElseGet(Supplier other)
是orElse()方法的延迟调用版,在Optional对象不含值的时候执行调用。
orElseThrow(Supplier excetionSupplier)
和get()方法类似,在Optional对象为空的时候会抛出一个异常,但是这个异常我们可以自定义。
ifPresent(Consumer)
在Optional对象存在的执行的方法,反之不操作。也接受一个空参数的,如果
| 方法 | 描述 |
|---|---|
| empty | 返回一个空的Optional实例 |
| filter | 如果值存在并且满足提供的谓词,就会返回包含该值的Optional对象;否则返回一个空的Optional对象 |
| get | 如果值存在,将该值用Optional封装返回,否则抛出一个NullPointException异常 |
| ifPresent | 如果值存在,就执行使用该值的方法调用,否则什么也不做 |
| ifPresent | 如果值存在就返回true,否则返回false |
| map | 如果值存在,就对该值执行提供的mapping函数调用 |
| of | 将指定值用Optional封装后返回,如果该值为null,则抛出一个NullPointException异常 |
| ofNullable | 将指定值用Optional封装之后返回,如果该值为null,则返回一个空的Optional对象 |
| orElse | 如果有值则将其返回,否则返回一个默认值 |
| orElseGet | 如果有值则将其返回,否则返回一个由指定的Supplier接口生成的值 |
| orElseThrow | 如果有值则将其放回,否则抛出一个由指定的Supplier接口生成的异常 |
四、新的日期和时间
在 Java 8之前,我们对日期和时间的支持智能依赖 java.util.Date类,这个类无法表示日期,只能以毫秒的精度表示时间。而且它的表现方式也不是那么直观,在Java1.0的Date这个类中,年份的起始是 1900 年,月份的起始是 0 开始,如果我们这个时候想要构造一个 2020年7月18号的日期,我们就得这样做:
Date date = new Date(120, 6, 18);
System.out.println(date); // Sat Jul 18 00:00:00 CST 2020
这种的构造方式简直是糟糕透了不是吗,对于不了解Date 的来说太不友好了。在java1.1 后出现了Calender这个类,而Date中大部分方法都被废弃了,但是Calender这个类中也有类似的问题和设计缺陷,而且两个日期类的出现,我们有时候也难以选择使用哪一个。
LocalDate
创建一个 LocalDate 对象
LocalDate nowDate = LocalDate.of(2020,7,18); //2020-07-18
int year = nowDate.getYear(); //2020
Month month = nowDate.getMonth(); //07
int day = nowDate.getDayOfMonth(); //18
DayOfWeek dayOfWeek = nowDate.getDayOfWeek(); //SATURDAY
int days = nowDate.lengthOfMonth(); //31
LocalDate nowdate = LocalDate.now(); //获取当前时间>2020-07-18
也可以使用 TemporalField 读取 LocalDate 的值
LocalDate nowDate = LocalDate.of(2020,7,18); //2020-07-18
int year = nowDate.get(ChronoField.YEAR); //2020
int month = nowDate.get(ChronoField.MONTH_OF_YEAR); //07
int day = nowDate.get(ChronoField.DAY_OF_MONTH); //18
LocalTime
创建一个 LocalTime 对象
LocalTime nowTime = LocalTime.of(19, 34, 32); //19:34:32
int hour = nowTime.getHour(); //19
int minute = nowTime.getMinute(); //34
int second = nowTime.getSecond(); //32
同样也可以使用 TemporalField 读取 LocalTime 的值
LocalTime nowTime = LocalTime.of(19, 34, 32); //19:34:32
int hour = nowTime.get(ChronoField.HOUR_OF_DAY); //19
int minute = nowTime.get(ChronoField.MINUTE_OF_HOUR); //34
int second = nowTime.get(ChronoField.SECOND_OF_MINUTE); //32
LocalDateTime
LocalDateTime 相当于合并了日期和时间,以下是创建的几种方式:
LocalDate nowDate = LocalDate.of(2020,7,18); //2020-07-18
LocalTime nowTime = LocalTime.of(19, 45, 20); //19:34:32
LocalDateTime dt1 = LocalDateTime.of(2020, Month.JULY, 18, 19, 45, 20);
LocalDateTime dt2 = LocalDateTime.of(nowDate, nowTime);
LocalDateTime dt3 = nowDate.atTime(19, 45, 20);
LocalDateTime dt4 = nowDate.atTime(nowTime);
LocalDateTime dt5 = nowTime.atDate(nowDate);
LocalDate date1 = dt1.toLocalDate(); //2020-07-18
LocalTime time1 = dt1.toLocalTime(); //19:45:20
时间点的日期 时间类的通用方法:
| 方法名 | 是否静态方法 | 描述 |
|---|---|---|
| from | 是 | 依据传入的Temporal对象创建对象实例 |
| now | 是 | 依据系统时钟创建Temporal对象 |
| of | 是 | 由Temporal对象的某个部分创建该对象的实例 |
| parse | 否 | 由字符串创建Temporal对象的实例 |
| atOffset | 否 | 将Temporal对象和某个时区偏移相结合 |
| atZone | 否 | 将Temporal对象和某个时区相结合 |
| format | 否 | 使用某个指定的格式器将Temporal对象转换为字符串(Instant类不提供该方法) |
| get | 否 | 读取Temporal对象的某一部分的值 |
| minus | 否 | 创建Temporal对象的一个副本,通过将当前Temporal对象的值减去一定的时长创建该副本 |
| plus | 否 | 创建Temporal对象的一个副本,通过将当前Temporal对象的值加上一定的时长创建该副本 |
| with | 否 | 以该Temporal对象为模板,对某些状态进行修改创建该对象的副本 |
Duration和Period
这两个类是用来表示两个时间内的间隔的
Duration d1 = Duration.between(time1, time2);
Duration d1 = Duration.between(dateTime1, dateTime2);
Duration threeMinutes = Duration.ofMinutes(3);
Duration threeMinutes = Duration.of(3, ChronoUnit.MINUTES);
Period tenDays = Period.ofDays(10);
Period threeWeeks = Period.ofWeeks(3);
Period twoYearsSixMonthsOneDay = Period.of(2, 6, 1);
日期 - 时间类中表示时间间隔的通用方法:
| 方法名 | 是否静态方法 | 方法描述 |
|---|---|---|
| between | 是 | 创建两个时间点之间的interval |
| from | 是 | 由一个临时时间点创建interval |
| of | 是 | 由它的组成部分创建interval的实例 |
| parse | 是 | 由字符串创建interval的实例 |
| addTo | 否 | 创建该interval的副本,并将其叠加到某个指定的temporal对象 |
| get | 否 | 读取该interval的状态 |
| isNegative | 否 | 检查该interval是否为负值,不包含零 |
| isZero | 否 | 检查该interval的时长是否为零 |
| minus | 否 | 通过减去一定的时间穿件该interval的副本 |
| multipliedBy | 否 | 将interval的值乘以某个标量创建该interval的副本 |
| negated | 否 | 以忽略某个时长的方式创建该interval的副本 |
| plus | 否 | 以增加某个指定的时长的方式创建该interval的副本 |
| subtractFrom | 否 | 从指定的temporal对象中减去该interval |