前段时间我们接入了 ELK 公司出品的 Elastic-APM 作为全链路监控平台,终结了我好几年前撸的字节码注入全链路监控平台。前段时间有一个业务在启动过程中,会概率性出现大量线程阻塞,导致可对外提供服务的 HTTP 线程非常少,流量进来以后马上出现 HTTP 线程耗尽,健康检查接口请求失败,服务被 k8s 杀死。
堆栈分析
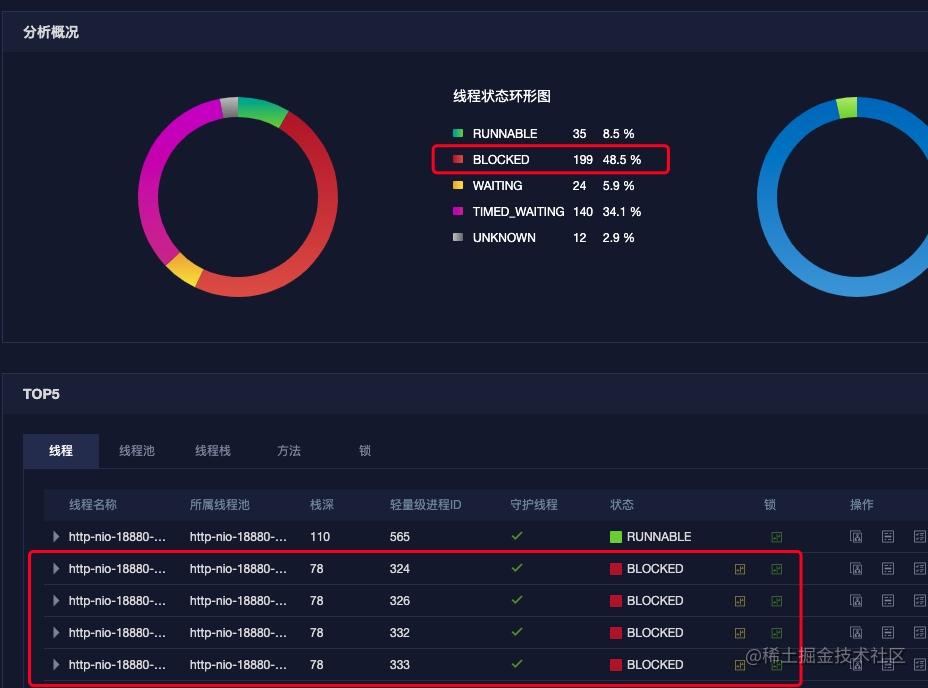
既然是线程的问题,当然想到的是 dump 线程堆栈,人肉阅读也可以,上传到 PerfMa XSheepdog 会更加简单。在锁的这一栏的截图如下所示。
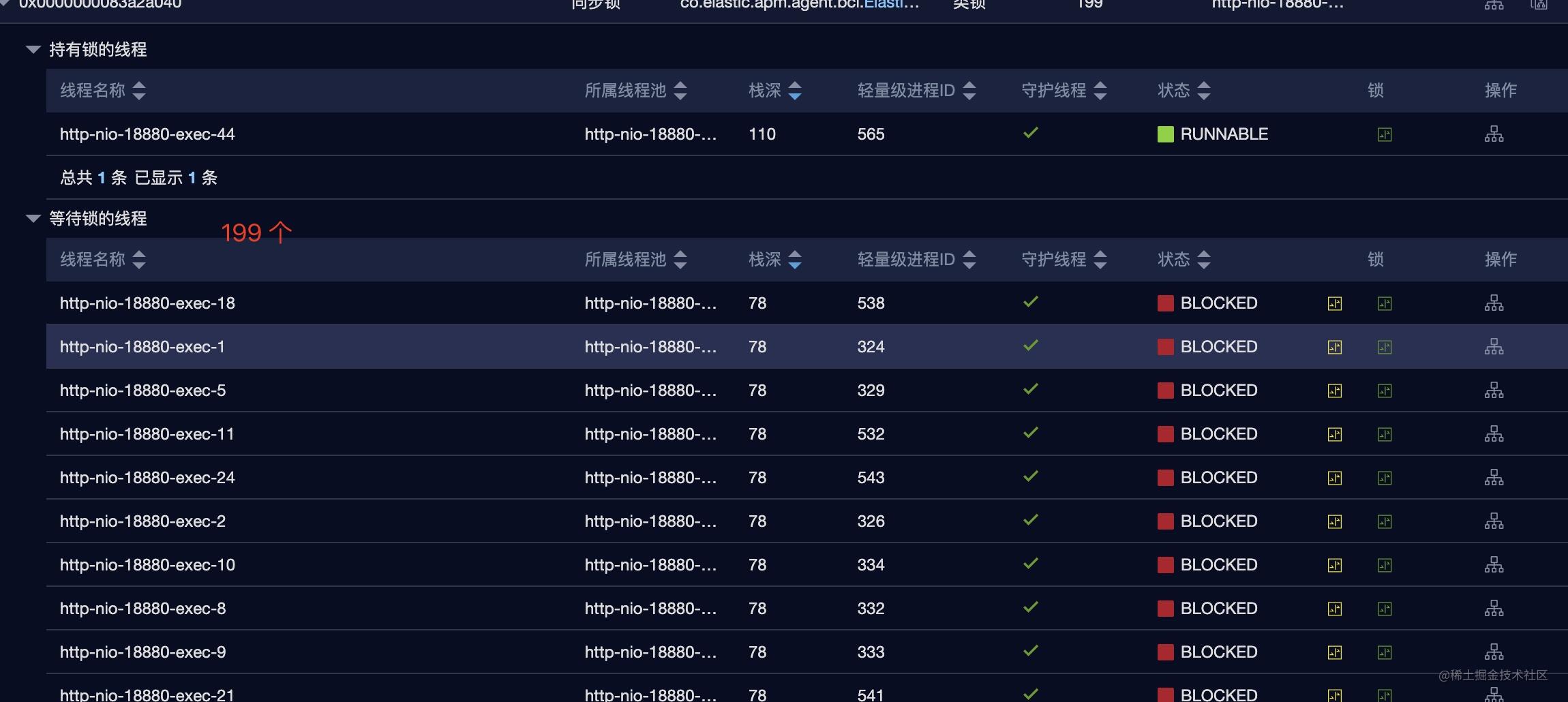
可以看到 http-nio-18880-exec-44 线程持有了一个锁,这个锁被其它的 199 个线程等待。持有锁的线程堆栈如下图所示。

上层的调用方法是 co.elastic.apm.agent.bci.ElasticApmAgent#ensureInstrumented,这段逻辑背后是在调用 bytebuddy 利用 ASM 进行 class 的转换注入。
等待锁的线程恰好 block 也在这个方法,如下图所示。
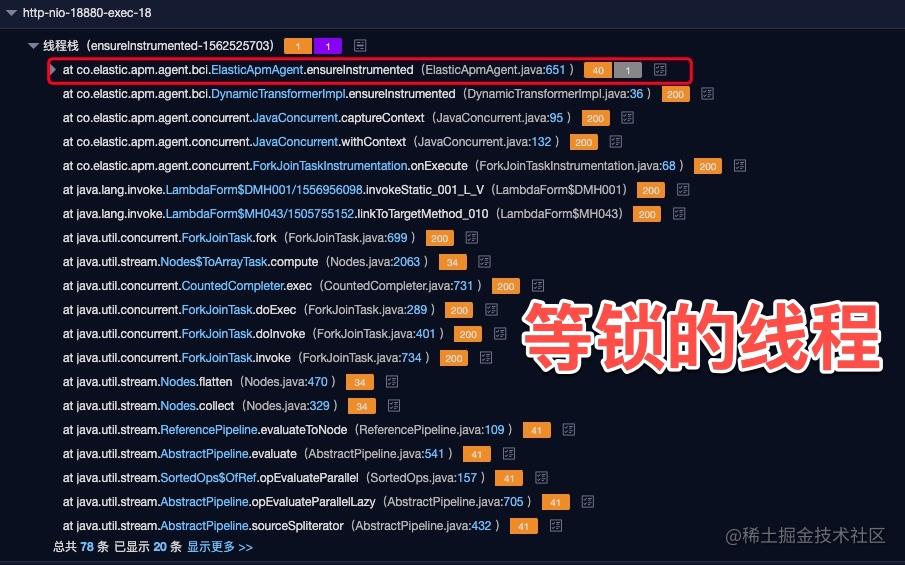
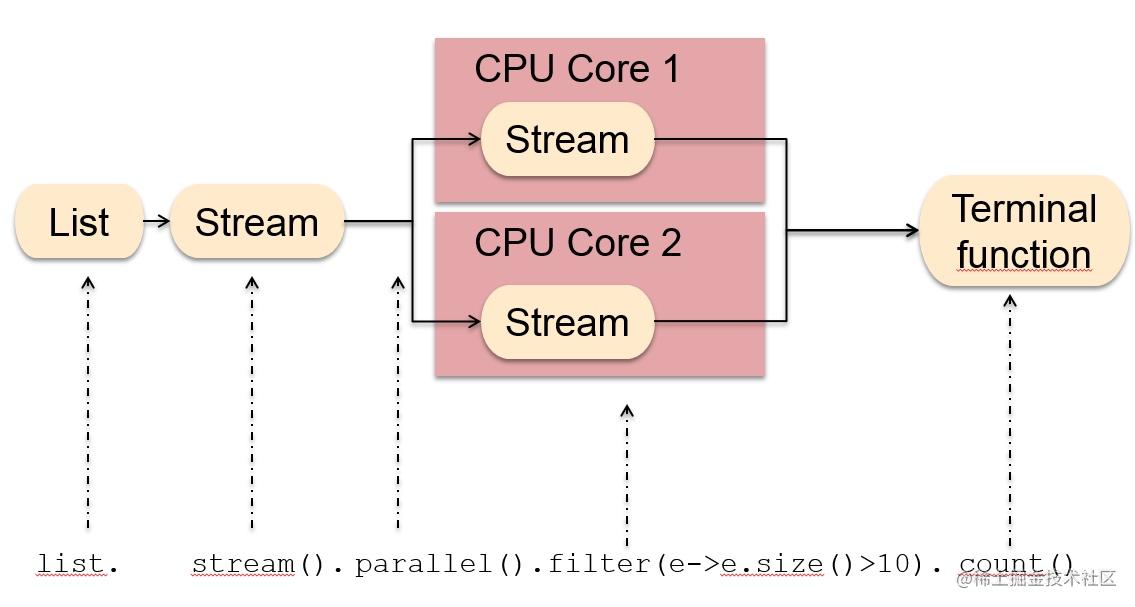
通过堆栈分析,这个问题的出现与我们业务代码用了 ParallelStream 有关。Java 中的 Stream 是一个比较好用的东西,在函数式编程、流式数据处理上写起来比较简单。除了串行化的流式处理,Java 也提供了并行流 parallelStream 可以使用多核多线程并行处理,如下图所示。
我们的业务代码是这样的:
private List<TaskRule> getTaskRules(Task task, List<TaskRule> taskRules) {
return taskRules.parallelStream()
.filter(taskRule -> taskRule.getTaskId().equals(task.getId()))
.sorted(Comparator.comparing(TaskRule::getLower))
.collect(Collectors.toList());
}
parallelStream 背后的男人是 ForkJoin,采用分治的方式将任务分解为小任务,然后通过 ForkJoinPool 线程池来实现并行化。
ES-APM 为了突破跨线程链路追踪,对多线程相关的类做了注入,apm-java-concurrent-plugin 插件会注入所有 ForkJoinTask 的子类,ForkJoin 底层实现用到的很多类都继承了 ForkJoinTask,比如下面这些:
java.util.stream.Nodes$CollectorTaskjava.util.stream.Nodes$ToArrayTask$OfRefjava.util.stream.ReduceOps$ReduceTaskjava.util.concurrent.CountedCompleter- ...
在服务启动后,大量的 HTTP 请求进来调用 getTaskRules 这个方法,HTTP 线程、ForkJoinPool 中的线程都会调用到 ES-APM 的代码,判断这些类有没有被字节码注入。ES-APM 判断类有没有被转换的代码如下:
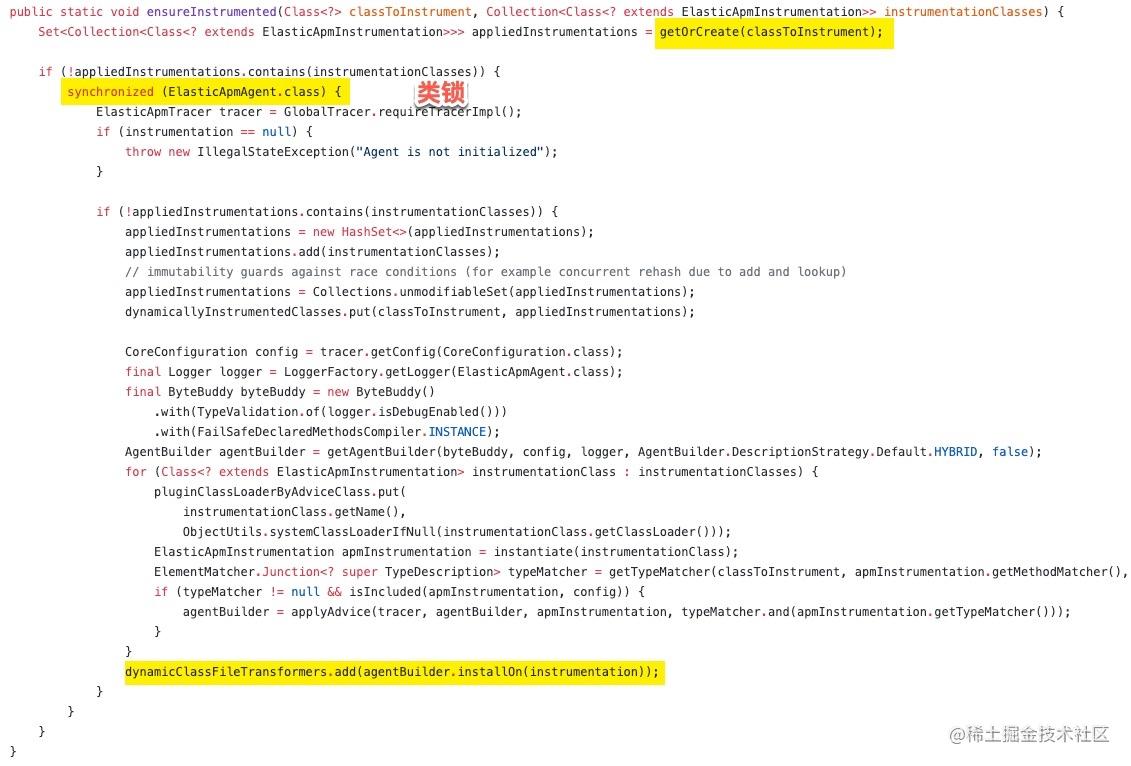
上面的代码有一个明显的并发问题,这里的逻辑是首先查询类有没有被转换,如果没有,则进入到一个类锁,做相关类的字节码注入。
在并发量高的情况下,HTTP 线程、ForkJoinPool 中的线程调用了 getOrCreate 方法,这时因为类还没有转换,返回了一个空的 set,然后有一个幸运儿抢到了 ElasticApmAgent 类锁,其它所有的线程都 block 住了。
当幸运儿执行完类的转换,下一个抢到类锁的线程还会再对类转换一遍(可怕)。其它的没抢到的还要继续 block。不仅如此,因为 ForkJoinPool 线程池中的线程也会 block 在这个,导致 http 请求也会 block,很快整个 tomcat 线程池就被耗尽了。
这还没完,其实如果处理的非常快,也没有什么太大的问题,只是同一个类,每经过一次改写,就会变复杂,文件变得更大,下次类的字节码注入花的时间就更长。
使用 arthas 去注入 Bytebuddy 的 AgentBuilder$Default$ExecutingTransformer.transform 方法,这个方法的签名如下。
private byte[] transform(JavaModule module,
ClassLoader classLoader,
String internalTypeName,
Class<?> classBeingRedefined,
ProtectionDomain protectionDomain,
byte[] binaryRepresentation) {
}
其中 internalTypeName 表示要转换的类的类名,binaryRepresentation 表示当前转换类最新的字节码数据。
启动 arthas,开启 unsafe:
options unsafe true
然后使用 watch 命令观察入参
watch co.elastic.apm.agent.shaded.bytebuddy.agent.builder.AgentBuilder$Default$ExecutingTransformer transform "{params}" -x 2
ts=2020-10-22 03:41:52; [cost=0.358887ms] result=@ArrayList[
@Object[][
null,
null,
@String[java/util/concurrent/CountedCompleter],
@Class[class java.util.concurrent.CountedCompleter],
null,
@byte[][isEmpty=false;size=4379],
],
]
...
ts=2020-10-22 03:47:26; [cost=1021.689119ms] result=@ArrayList[
@Object[][
null,
@String[java/util/concurrent/CountedCompleter],
@Class[class java.util.concurrent.CountedCompleter],
null,
@byte[][isEmpty=false;size=88422],
],
]
ts=2020-10-22 03:50:27; [cost=1419.025166ms] result=@ArrayList[
@Object[][
null,
@String[java/util/concurrent/CountedCompleter],
@Class[class java.util.concurrent.CountedCompleter],
null,
@byte[][isEmpty=false;size=102910],
],
]
可以看到 CountedCompleter 类经过多次转换,从几 k 大小变为了 100k 以上,继续转换还变得更大,代码变得更复杂,ASM 注入字节码的时间会变得越来越长,表现出来的现象就是:
- 持有锁的线程花在转换类的时间会越来越长
- 相应的,等待锁的线程将要等待更久的时间
我在代码中加了一些打印,time 后面的两个数字,第一个是 ensureInstrumented 整个方法的耗时,第二个是 Bytebuddy 字节码注入的耗时,单位都是毫秒。
[06:15:32][http-nio-18880-exec-49]done:class java.util.stream.Nodes$CollectorTask time:313 306
[06:15:33][http-nio-18880-exec-45]done:class java.util.stream.Nodes$ToArrayTask$OfRef time:496 233
...
[06:15:50][http-nio-18880-exec-17]done:class java.util.stream.Nodes$ToArrayTask$OfRef time:18317 1075
...
[06:16:54][http-nio-18880-exec-27]done:class java.util.stream.Nodes$ToArrayTask$OfRef time:81713 5481
...
[06:22:51][http-nio-18880-exec-59]done:class java.util.stream.Nodes$CollectorTask time:438733 24975
...
可以看到等锁的线程,有的等了 400 多秒,bytebuddy 字节码注入的时间也在快速增大,后面甚至要几分钟。
验证
为了侧面印证前面的分析过程,可以验证这样的情况:第一次只有一个请求,没有用户造成的并发情况,让并发相关的类都快速注入完成,再来做压测,看看还会不会出问题。步骤如下:
- 第一步,等服务启动完,使用 curl 请求,先请求一次接口。
- 然后使用 ab 或者 jmeter 疯狂来压那个接口,看看接口的响应情况。
结果如预料中的一样,接口响应时间正常了,jstack 查看现场的堆栈,也没有任何线程阻塞等在 ElasticApmAgent 的类锁上了。
解决办法
最简单的解决是业务暂时去掉 parallelStream,有坑先绕过。还有一个不成熟的改法,也不知道对不对:把 synchronized 同步块里的鸡肋二次判断 contains 前面加一行获取最新 appliedInstrumentations 的逻辑,如下所示,如果已经转换过了,就可以跳过后面的逻辑了。
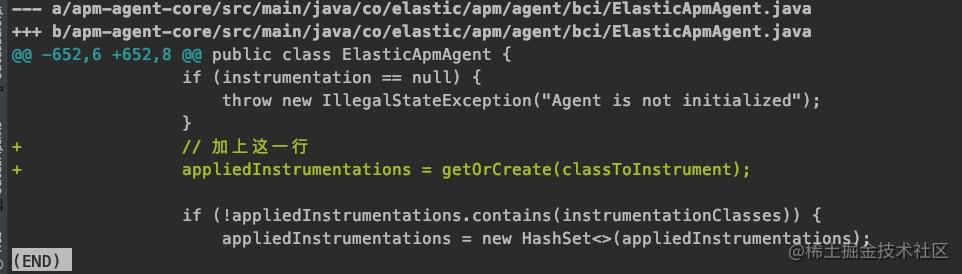
经过重新打包 ES-APM 进行测试,确实解决了这个场景下的问题。
小结
出问题的时候,不要怀疑自己,大胆的怀疑框架吧,ES-APM 这个调用超级频繁的代码中有一个类锁性能好不到哪里去,有很大的改善空间。好了,落班。