我们通常习惯用Json、XML等形式的数据存储格式,但相信还有很多人没有听说过Protocol Buffer(简称protobuf)。protobuf是Google开源的一个语言无关、平台无关的通信协议,其小巧、高效和友好的兼容性设计,使其被广泛使用。性能比Json、XML真的强太多了!
而且,随着微服务架构的流行,RPC框架也成为服务框架的重要组成部分。在很多RPC的设计中,都采用了高性能的编解码技术,而protobuf就属于其中的佼佼者。
也就说,要想深入了解微服务架构中的RPC环节底层实现,设计出高效的传输、序列化、编码解码等功能,学习protobuf的使用和原理非常有必要。
protobuf简介
protobuf是一种序列化对象框架(或者说是编解码框架)。它有两部分功能组成:结构化数据(数据存储结构)和序列化&反序列化。
其中数据存储结构的作用与XML、JSON相似;序列化和反序列化的作用与Java自带的序列化、Facebook的Thrift和JBoss Marshalling等相似。
总之:protobuf是通过定义结构化数据,并提供对数据的序列化和反序列化功能,从而实现数据存储/RPC数据交换的功能。
它的特点是:
- 语言无关、平台无关
- 简洁
- 高性能(序列化速度快 & 序列化后的数据体积小)
- 良好的兼容性
可以通过数据直观的看一下不同框架在序列化响应时间上的对比:
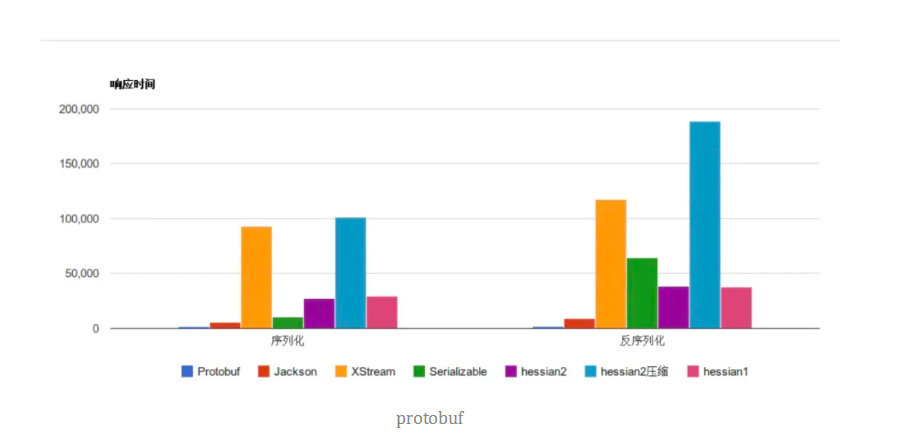 可以看出,protobuf的性能要远高于其他框架。
可以看出,protobuf的性能要远高于其他框架。
protobuf的使用流程
上面介绍了protobuf的功能,但仅仅知道这些功能我们无法知道它是怎么使用的。看了网上很多的文章,要么直接开始写代码要么直接开始分析报文格式,对于新手来说往往会一头雾水。
所以,我们先来梳理一下使用protobuf的步骤。
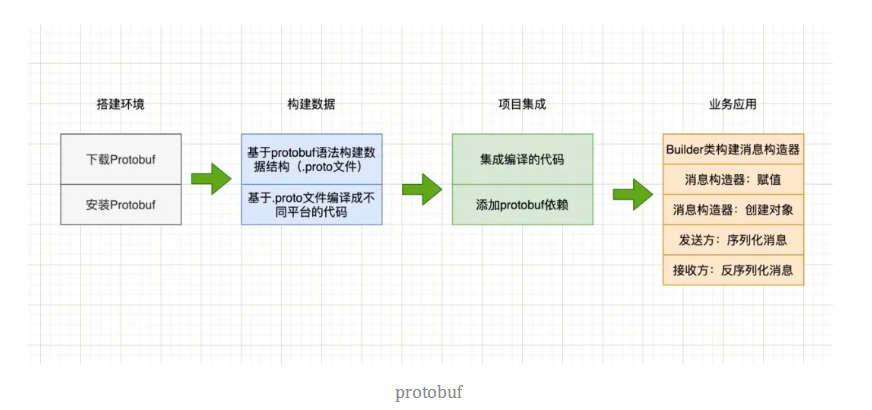 在上图中将protobuf的使用分了四个步骤:
在上图中将protobuf的使用分了四个步骤:
- 步骤一,搭建环境:使用protobuf要定义通信的数据结构,并编译生成不同的编程语言代码,这就需要有这么一个编译器的环境。
- 步骤二,构建数据:使用protobuf是要传输数据的,那么数据包含什么,有哪些项目,整个结构层次是什么样子的。这里基于protobuf的语法来进行数据结构的定义。
- 步骤三,项目集成:集成pom依赖(Java为例)、集成编译的Java类(对照proto文件);
- 步骤四,具体使用:通过集成进来的Java类,来构建消息、赋值,然后基于protobuf进行序列化,接收方进行反序列化操作;
了解了上述步骤,下面就针对具体的步骤来进行实战演示。
这里演示基于Mac OS操作系统和Java编程语言来进行操作。如果你使用的是其他操作系统和编程语言,基本思路一样,在不同的步骤时可针对性的找一下具体操作。
安装Protocol Buffers
安装protobuf是为了进行数据结构的定义和对应编程语言代码的生成。通常有两种方式:本地安装和IDE插件。我们先来看本地安装。
protobuf的代码是托管在GitHub上的,对应地址为:https://github.com/protocolbuffers/protobuf 。
点击项目右边的release链接可看到对应版本:https://github.com/protocolbuffers/protobuf/releases 。
 这里包含了各种编程语言、环境的版本。本文选protobuf-java-3.17.3.zip版本。
这里包含了各种编程语言、环境的版本。本文选protobuf-java-3.17.3.zip版本。
在Mac操作系统下,需要先安装一下依赖组件,才能够对protobuf进行编译和安装。
安装依赖组件:
// 安装 Protocol Buffer依赖
// 注:Protocol Buffer依赖于autoconf、automake、libtool、curl
brew install autoconf automake libtool curl
解压protobuf-java-3.17.3.zip,进入根目录,执行以下命令:
// 运行autogen.sh脚本
./autogen.sh
// 运行configure.sh脚本
./configure
// 编译未编译的依赖包
make
// 检查依赖包是否完整
make check
// 开始安装Protocol Buffer
make install
安装完成,检验版本:
$protoc --version
libprotoc 3.14.0
输出版本信息,说明安装成功。
这里的protoc命令就是Protocol Buffer的编译器,可以将 .proto文件编译成对应平台的头文件和源代码文件。
另外一种方式就是安装IDE插件,这里以IDEA为例,搜索插件:
 关于protobuf的插件比较多,选择适合自己就行。
关于protobuf的插件比较多,选择适合自己就行。
然后gRPC官方推荐了一种更优雅的使用姿势,可以通过maven轻松搞定(需安装上图中的“Protobuf Support”插件)。也就是引入grpc的一些组件,然后在maven的build中进行配置,编译proto文件成为Java代码。此种方式暂时不展开,后续可直接看项目集成部分的源代码。
构建数据
在Java中,如果通过JSON来传输一个数据,我们首先要定义一个对象,这里以Person为例:
public class Person {
private String name;
private Integer id;
// ... getter/setter
}
那么,如果用protobuf来定义Person这个对象的数据结构是什么样呢?
先创建一个person.proto文件,然后定义如下的结构:
syntax = "proto3"; // 声明为protobuf 3定义文件
package tutorial;
option java_package = "com.choupangxia.protobuf.message"; // 声明生成消息类的java包路径
option java_outer_classname = "Person"; // 声明生成消息类的类名
message PersonProto {
string name = 1;
int32 id = 2;
}
上面每项语法的具体说明可参看注释部分。当然Person的结构可以更丰富,这里只是出于演示需要,做了最简单的示例,更多语法可参看官方文档。
编译protot文件
定义完成之后,我们可以通过两种方式来生成目标Java类。这里先采用本机安装的编译器来进行操作。
执行protoc命令之前,可先执行-h命令来查看protoc的使用说明:
protoc -h
进入person.proto文件所在目录,执行以下命令进行编译:
protoc --java_out=../java ./person.proto
--java_out参数指定了Java类的输出路径,第二个参数执行的要编译的文件为当前目录下的person.proto文件。
执行命令,会发现com.choupangxia.protobuf.message下生成了名为Person的类。注意proto中定义的message名称不要与Java类名重复,否则会出现命令执行失败的状况。
对应的Person类比较复杂,甚至有一些语法层面的错误或改进,如果需要,进行对应的改进优化即可。
 此时将生成的Java复制到对应的包下即可。
此时将生成的Java复制到对应的包下即可。
业务应用
一切准备就绪,现在就来写个例子使用对应的代码了。
public class Test {
public static void main(String[] args) throws InvalidProtocolBufferException {
Person.PersonProto sourcePersonProto = Person.PersonProto.newBuilder().setId(123).setName("Tom").build();
// 序列化
byte[] binaryInfo = sourcePersonProto.toByteArray();
System.out.println("序列化字节码内容:" + Arrays.toString(binaryInfo));
System.out.println("序列化字节码长度:" + binaryInfo.length);
System.out.println("-----------以下为接收方反序列化操作-------------");
// 反序列化
Person.PersonProto targetPersonProto = Person.PersonProto.parseFrom(binaryInfo);
System.out.println("反序列化结果:" + targetPersonProto.toString());
}
}
上述代码就是基于生成的Person类的基本使用。首先通过,Person类中的内部类和Builder方法进行参数的封装,然后调用其toByteArray方法,即可将报文信息进行序列化。接收方呢,有同样的一套代码,先获得Person.PersonProto对象,然后执行parseFrom方法即可进行反序列化操作。
为什么protobuf比较高效
单从序列化后的数据体积角度来分析。与XML、JSON这类文本协议相比,ProtoBuf通过T-(L)-V(TAG-LENGTH-VALUE)方式编码,不需要", {, }, :等分隔符来结构化信息。同时在编码层面使用varint压缩,所以描述同样的信息,protobuf序列化后的体积要小很多,在网络中传输消耗的网络流量更少,进而对于网络资源紧张、性能要求非常高的场景,ProtoBuf协议是不错的选择。
做一个简单直观的例子:
{"id":1,"firstName":"Chris","lastName":"Richardson","email":[{"type":"PROFESSIONAL","email":"aicchrrdson@email.com"}]}
对于上面的JSON数据,使用JSON序列化后的数据大小为118byte,而使用protobuf序列化后的数据大小为48byte。如果数据量更多,层次结构更复杂,差距还是很明显的。
从序列化/反序列化速度角度,与XML、JSON相比,protobuf序列化/反序列化的速度更快,比XML要快20-100倍。
但protobuf是基于二进制的协议,编码后的数据可读性差,如果没有idl文件,就无法理解二进制数据流,对调试不友好。
小结
本文带大家从0到1学习了protobuf的使用步骤。很多文章之所以看不懂,就是因为没有梳理清楚使用protobuf的整个核心逻辑。只要掌握了如何搭建环境、如何编写数据结构、如何编译、如何集成到项目中并运用。那么,protobuf的其他知识点逐步在实践中补充即可。
随着微服务的不断发展,RPC框架为了追求高效的通信,使用像protobuf这类框架也必然是趋势。也是想更好的学习微服务架构的底层的必备知识。