前言
在之前我们讲解了关于 NIO 原生的ByteBuffer和Netty封装好的ByteBuf的区别以及ByteBuf的动态扩容机制
在本篇, 我们将讲解关于ByteBuf的堆内内存, 堆外内存和复合缓冲区
本篇文章将添加于我的
Netty专栏 欢迎大家关注
ByteBuf 的优点
- 支持池化
- 支持引用计数
- 容量可以动态扩容
- 读写采用不同索引
- 通过内置的复合缓冲区实现零拷贝
- 网络通信会涉及到字节序列的移动
- 在读写切换时不需要调用
ByteBuffer的flip()方法
ByteBuf 的使用模式
-
直接内存, 也叫堆外内存, (零拷贝实现)
- 不在
JVM的堆中分配内存, 而是在JVM外通过本地方法调用分配虚拟机内存
- 不在
-
堆内内存:将数据存储在JVM的堆空间中. 能够在没有使用池化技术的情况下提供高速的分配和释放, 可以通过hasArray()来判断ByteBuf是否由数组支撑, 如果不是, 则为直接缓冲区 -
复合缓冲区
- 是一种试图, 不实际存储数据, 由 多个堆缓冲区和直接缓冲区 复合组成
ByteBuf 的池化
ByteBuf有两种分配方式
-
一种是通过
ByteBufAllcator类, 它可以分配池化或者池化的ByteBUf示例PooledByteBufAllocator: 池化UnpooledByteBufAllocator: 未池化
-
第二种是利用
Unpooled类的静态方法, 可以创建非池化的ByteBuf示例buffer()返回一个未池化的基于堆内存存储的ByteBufdirectBuffer()返回一个未池化的基于直接内存存储的ByteBufwrappedBuffer()返回一个包装了给定数据的ByteBufcopiedBuffer()返回一个复制了给定数的ByteBuf
池化最大的意义在于可以重用ByteBuf:
- 有池化可以重用池中的
ByteBuf, 并且采用了与jemalloc类似的内存分配算法提高分配效率 - 没有池化, 每次都要新建
ByteBuf示例, 会增加 GC 压力 - 高并发时使用池化功能能够更节约内存, 减少内存溢出的问题
开启池化功能
可以通过下述环境变量来设置
-Dio.netty.allocator.type={ unpooled | pooled }
复制代码
ByteBuf 的组成
从结构来讲, ByteBuf是由一串字节数组构成, 数组中每个字节都用来存放信息
在ByteBuf中有以下几个重要属性:
capacity: 容量0: 缓冲区开始位置readIndex: 下一个读位置writeIndex: 下一个写位置
根据下标位置的不同可将ByteBuf分为以下几个区域:
已读区域(废弃区域):[ 0, readIndex )可读区域:[ readIndex, writeIndex )可写区域:[ writeIndex, capacity )
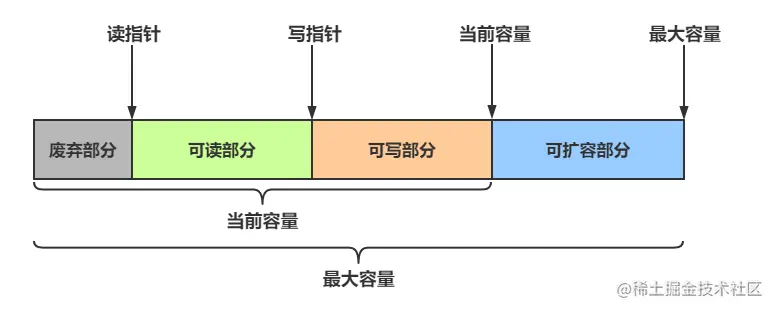
图片来源于网络
扩容机制可看我之前的文章ByteBuf 和 ByteBuffer 的区别, ByteBuf 动态扩容源码分析 - 掘金 (juejin.cn)
本文内容到此结束了
如有收获欢迎点赞?收藏?关注✔️,您的鼓励是我最大的动力。
如有错误❌疑问?欢迎各位大佬指出。
我是 宁轩 , 我们下次再见