本文为《深入学习 JVM 系列》第十七篇文章
我们来继续讲解 Java 虚拟机中的即时编译。
Profiling
上篇文章中介绍了关于分层编译的交互关系图,这里再贴一遍。
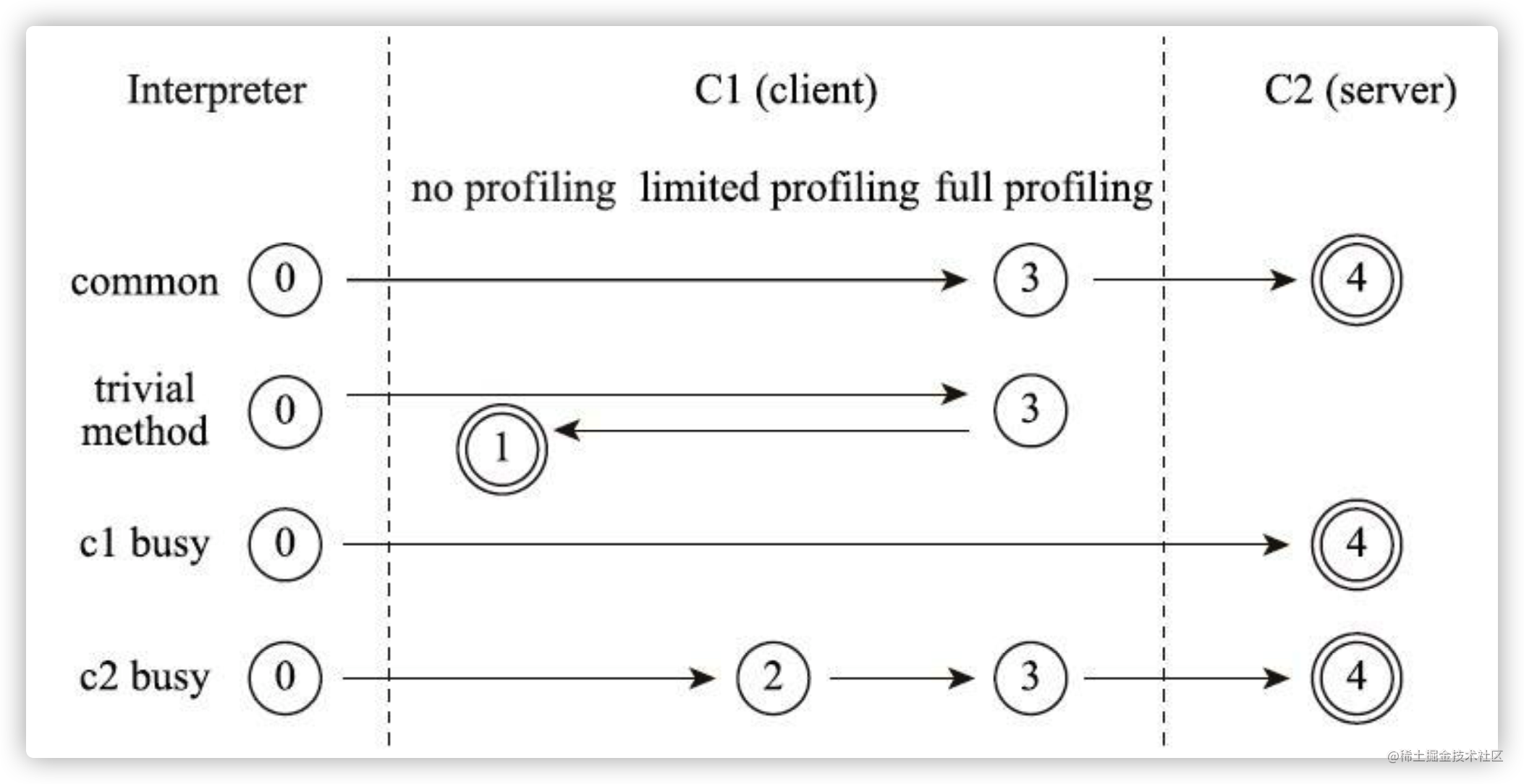
对于图片中描述的四种编译途径做过详细介绍,这里就不重复介绍了,其中提到了如下内容:分层编译中的 0 层、2 层和 3 层都会进行 profiling,收集能够反映程序执行状态的数据。其中,最为基础的便是 2层进行的 profiling,它只需要统计方法的调用次数以及循环回边的执行次数,当统计之和超过阈值就会触发即时编译。
0 层和 3 层相较于 2层复杂一些,需要收集用于 4 层 C2 编译的数据, 比如说分支跳转字节码的分支 profile(branch profile),包括跳转次数和不跳转次数,以及非私有实例方法调用指令、强制类型转换 checkcast 指令、类型测试 instanceof 指令,和引用类型的数组存储 aastore 指令的类型 profile(receiver type profile)。上述数据分为两大类:分支 profile 和类型 profile。
根据图片中的编译途径可知,分层编译下,无论何种情况,大概率都要进行分支 profile 和类型 profile 的收集。
分支 profile 和类型 profile 的收集将给应用程序带来不少的性能开销。据统计,正是因为这部分额外的 profiling,使得 3 层 C1 代码的性能比 2 层 C1 代码的低 30%。
那么这些耗费巨大代价收集而来的 profile 具体有什么作用呢?
答案是, C2 可以根据收集得到的数据进行猜测,假设接下来的执行同样会按照所收集的 profile 进行,从而作出比较激进的优化。
基于分支 profile 的优化
举个例子,下面这段代码中包含两个条件判断。第一个条件判断将测试所输入的 boolean 值。
//-XX:+PrintCompilation
public class BranchProfile {
public static void main(String[] args) {
for (int i = 0; i < 20000; i++) {
foo(true);
}
}
public static int foo(boolean flag) {
if (flag) {
return 1;
} else {
return 2;
}
}
}
输出结果为:
.......
204 27 3 java.lang.String::isEmpty (14 bytes)
204 25 3 java.lang.StringBuilder::append (8 bytes)
204 28 3 com.msdn.java.javac.jit.BranchProfile::foo (8 bytes)
204 29 4 com.msdn.java.javac.jit.BranchProfile::foo (8 bytes)
205 28 3 com.msdn.java.javac.jit.BranchProfile::foo (8 bytes) made not entrant
205 2 4 java.lang.Math::min (11 bytes)
看一下编译结果,可以看到 foo 先是走 3层 C1编译,后续又进行 4层 C2编译,这符合通用编译途径。made not entrant 则表示后续不再进入 3层 C1编译的 foo 方法。
对应的 foo 方法的字节码文件如下:
public static int foo(boolean);
descriptor: (Z)I
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=1, args_size=1
0: iload_0
1: ifeq 6
4: iconst_1
5: ireturn
6: iconst_2
7: ireturn
从解释执行的角度来看,foo 方法的执行过程如下:
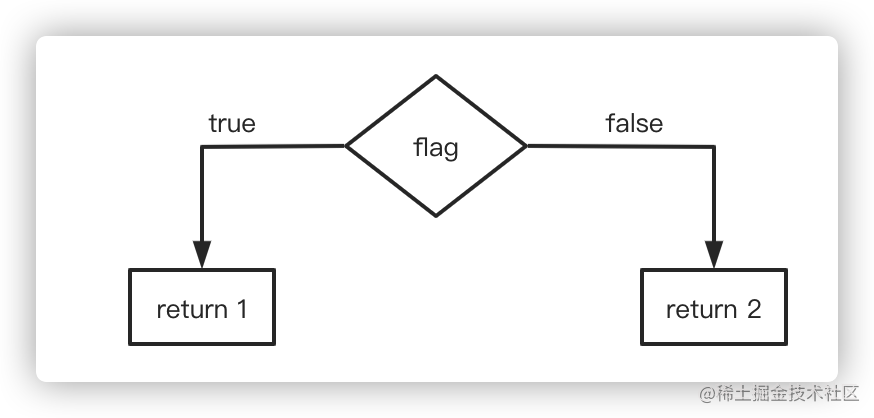
假设应用程序调用 foo 方法时,所传入的 flag 值皆为 true。那么,偏移量为 1 的条件跳转指令所对应的分支 profile 中,跳转的次数都为 0。那么就将 false 的流程分支剪掉,
foo 方法就可以简化为如下代码:
public static int foo(boolean flag) {
return 1;
}
综上所述,根据条件跳转指令的分支 profile,即时编译器可以将从未执行过的分支剪掉,以避免编译这些很有可能不会用到的代码,从而节省编译时间以及部署代码所要消耗的内存空间。此外,“剪枝”将精简程序的数据流,从而触发更多的优化。
当然,在实际应用中,分支 profile 出现仅跳转或者仅不跳转的情况并不多见,不然也不会有分支判断。
总结一下,关于即时编译器对分支 profile 的优化,除了剪枝优化,还会根据分支 profile,计算每一条程序执行路径的概率,以便某些编译器优化优先处理概率较高的路径。
基于类型 profile 的优化
举个例子,下面这段代码中包含对象类型判断。下面这段代码将测试所传入的对象是否为 Exception 的实例,如果是,则返回它的系统哈希值;如果不是,则返回它的哈希值。
public static int hash(Object o) {
if (o instanceof Exception) {
return System.identityHashCode(o);
} else {
return o.hashCode();
}
}
//字节码文件
public static int hash(java.lang.Object);
descriptor: (Ljava/lang/Object;)I
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: instanceof #5 // class java/lang/Exception
4: ifeq 12
7: aload_0
8: invokestatic #6 // Method java/lang/System.identityHashCode:(Ljava/lang/Object;)I
11: ireturn
12: aload_0
13: invokevirtual #7 // Method java/lang/Object.hashCode:()I
16: ireturn
假设应用程序调用该方法时,所传入的 Object 皆为 Integer 实例。那么,偏移量为 1 的 instanceof 指令的类型 profile 仅包含 Integer,偏移量为 4 的分支跳转语句的分支 profile 中不跳转的次数为 0,偏移量为 13 的方法调用指令的类型 profile 仅包含 Integer。
从解释执行的角度来看,hash 方法的执行过程如下:
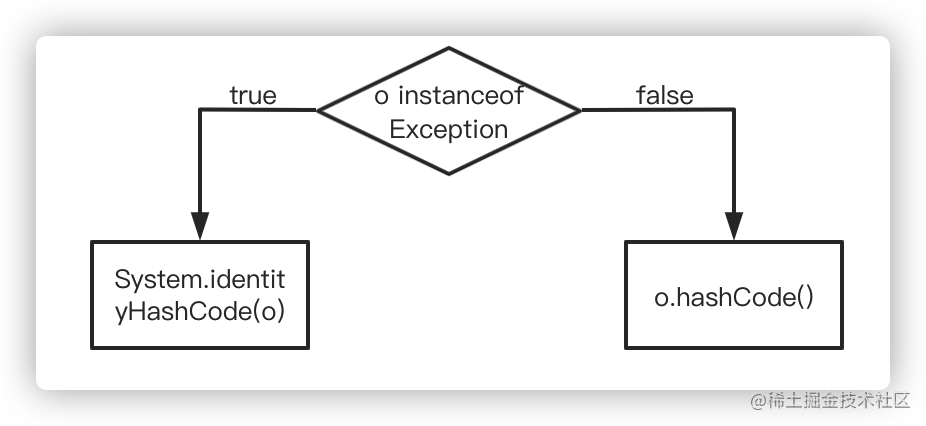
相较于分支 profile 测试代码中的判断条件,o instanceof Exception 明显更复杂一些,尤其是 instanceof 指令,关于该指令的学习可以参考本文,更加深入的内容可以参考 R大的回答。这里我们引入一下总结好的内容:
如果
S是objectref所引用的对象的类,而T是已解析类,数组或接口的类型,则instanceof确定是否objectref是T的一个实例。S s = new A(); s instanceof T
如果S是一个普通的(非数组)类,则:
- 如果T是一个类类型,那么S必须是T的同一个类,或者S必须是T的子类;
- 如果T是接口类型,那么S必须实现接口T。
如果S是接口类型,则:
- 如果T是类类型,那么T必须是Object。
- 如果T是接口类型,那么T一定是与S相同的接口或S的超接口。
如果S是表示数组类型SC的类[],即类型SC的组件数组,则:
如果T是类类型,那么T必须是Object。
如果T是一种接口类型,那么T必须是数组实现的接口之一(JLS§4.10.3)。
如果T是一个类型为TC的数组[],即一个类型为TC的组件数组,那么下列其中一个必须为真:
- TC和SC是相同的原始类型。
- TC和SC是引用类型,类型SC可以通过这些运行时规则转换为TC。
这里举几个例子,以下子类型关系都成立(“<:”符号表示左边是右边的子类型,“=>”符号表示“推导出”):
- String[][][] <: String[][][] (数组子类型关系的自反性)
- String <: CharSequence => String[] <: CharSequence[] (数组的协变)
- String[][][] <: Object (所有数组类型是Object的子类型)
- int[] <: Serializable (原始类型数组实现java.io.Serializable接口)
- Object[] <: Serializable (引用类型数组实现java.io.Serializable接口)
- int[][][] <: Serializable[][] <: Serializable[] <: Serializable (上面几个例子的延伸⋯开始好玩了吧?)
- int[][][] <: Object[][] <: Object[] <: Object
关于 instanceof 判断为 true 的描述,可以结合官网好好研究一下,除此之外,如果目标类型 T 被 final 修饰,那么 JVM 只需要判断 S 是否为 final 类型即可。
在我们的例子中,假设所输入的 Object 对象仍为 Integer 实例,那么判断条件为 false,最后执行 o.hashCode()。我们查看 Integer.hashCode() 方法:
public final class Integer ... {
...
@Override
public int hashCode() {
return Integer.hashCode(value);
}
public static int hashCode(int value) {
return value;
}
...
}
上述代码进行方法内联优化,关于方法内联后续会介绍,这里我们只需要了解有这个优化即可。
//-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining
public static void main(String[] args) {
for (int i = 0; i < 20000; i++) {
hash(new Integer(1));
}
}
查看输出结果如下:
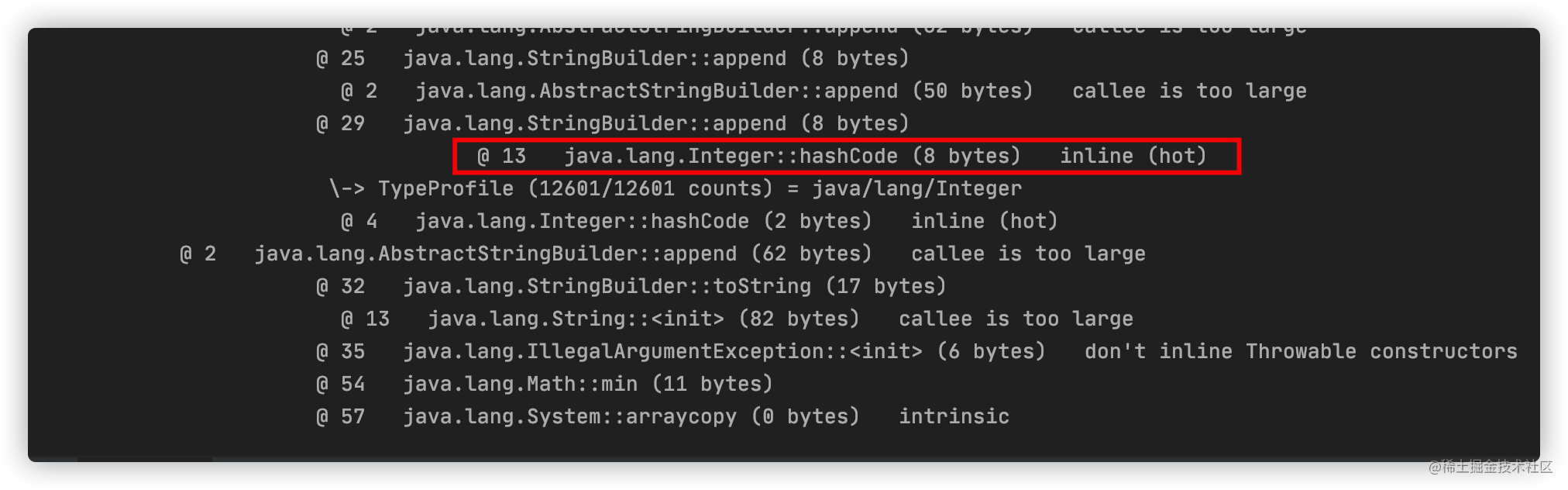
最终关于 hash 方法的执行过程简化如下:
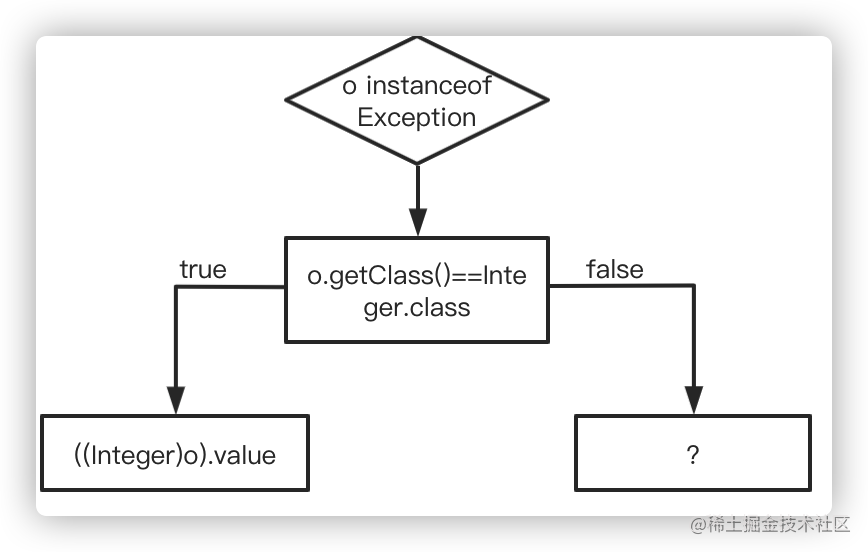
当然上述代码也涉及到了分支 profile 的优化,不管怎样, 两者的优化都是基于假设的。对于分支 profile,即时编译器假设的是仅执行某一分支;对于类型 profile,即时编译器假设的是对象的动态类型仅为类型 profile 中的那几个。
但是,如果假设错了呢,程序又该如何处理?
去优化
Java 虚拟机给出的解决方案便是去优化,即从执行即时编译生成的机器码切换回解释执行,并重新收集相关的 profile。
在前文讲 Codecache 如何回收时提及到了去优化,当发生去优化时,会将之前出现过的编译标记为 “made not entrant"(使用-XX:+PrintCompilation)。它表示该方法不能再被进入。具体去优化的过程比较复杂,暂无能力讲解清楚,只能通过一个案例来侧面验证一下自己的所得。
//-XX:+PrintCompilation
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 40000; i++) {
foo(true);
}
}
public static int foo(boolean flag) {
if (flag) {
return 1;
} else {
return 2;
}
}
截取部分输出结果如下:
184 28 3 com.msdn.java.javac.jit.BranchProfile::foo (8 bytes)
185 29 4 com.msdn.java.javac.jit.BranchProfile::foo (8 bytes)
185 30 3 java.util.Arrays::copyOfRange (63 bytes)
185 28 3 com.msdn.java.javac.jit.BranchProfile::foo (8 bytes) made not entrant
185 31 3 java.lang.System::getSecurityManager (4 bytes)
接着对上述代码进行修改:
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 40000; i++) {
foo(true);
}
foo(false);
}
输出结果为:
179 27 3 com.msdn.java.javac.jit.BranchProfile::foo (8 bytes)
180 28 4 com.msdn.java.javac.jit.BranchProfile::foo (8 bytes)
180 29 4 java.lang.String::hashCode (55 bytes)
180 27 3 com.msdn.java.javac.jit.BranchProfile::foo (8 bytes) made not entrant
180 30 3 java.util.Arrays::copyOfRange (63 bytes)
180 28 4 com.msdn.java.javac.jit.BranchProfile::foo (8 bytes) made not entrant
根据上述三种代码的输出结果,结合 Codecache 的清除策略,可以得到如下结论:
1、根据多次测试结果得到的日志可知,foo 方法首先触发了3层的C1即时编译,然后触发了4层的C2的即时编译,最后 3层的 C1编译被标记为 made not entrant,即 foo 方法发生了去优化。
这里为什么会发生去优化呢?made not entrant 也就是不会再被进入,我们都知道编译途径先经过 C1编译最后到 C2编译,代码达到一定热度后再次执行会直接调用 C2编译的机器码,当程序结束后,因为 C1编译的结果热度不够,所以被标识为 made not entrant,后续会释放在 Codecache 中占用的内存。
2、当分支 profile 优化失败后(foo(false)),因为无法复用 C2编译的机器码,所以只能解释执行,最后 4层的 C2编译也被标记为 made not entrant,即 foo 方法又发生了去优化。
这里又是什么情况呢?因为 C2 编译的激进优化失败,那么就没必要保留这部分机器码,所以被标记为 made not entrant。
上述两点总结为本人拙见,如无错误,请多多指出。
扩展
ClassViewer
ClassViewer 是一个轻量级的 Java 类文件查看器。
官方文档地址:ClassViewer ,国内Github 地址:Glavo/ClassViewer
比如下面这段代码:
public static void main(String[] args) {
for (int i = 0; i < 40000; i++) {
if (i % 2 == 0) {
foo(true);
}else{
foo(false);
}
}
}
//部分字节码文件
0: iconst_0
1: istore_1
2: iload_1
3: sipush 20000
6: if_icmpge 20
9: iconst_1
10: invokestatic #2 // Method foo:(Z)I
13: pop
14: iinc 1, 1
17: goto 2
20: return
启动过程:下载 jar 包,在命令行窗口执行如下命令:
java -jar ClassViewer-3.9.jar
我们通过 ClassViewer 来查看字节码文件,如下图所示:
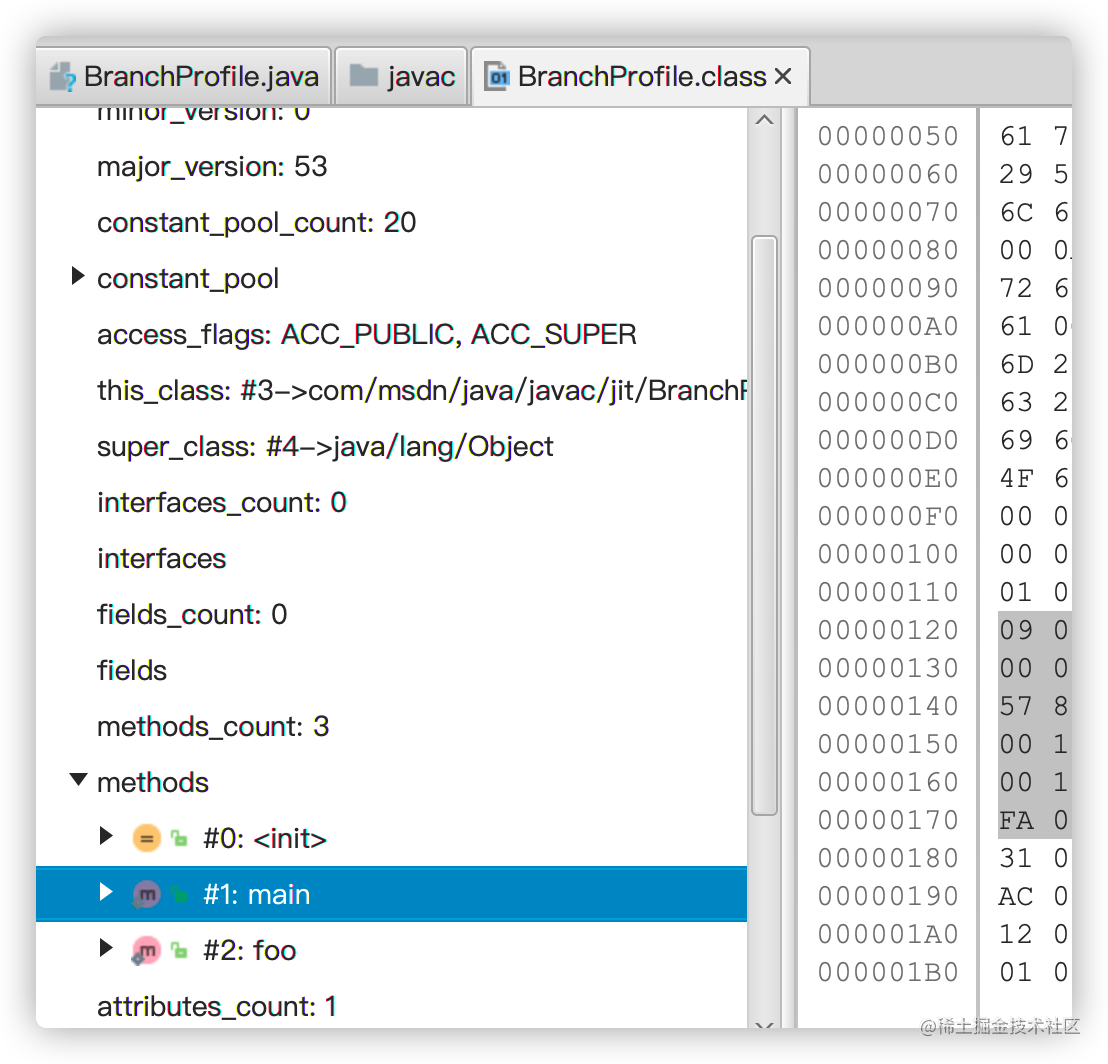
点击 methods 下的 main 方法,查看详细指令,点击偏移量为 17 的指令:goto 2,右侧会显示十六进制内容:
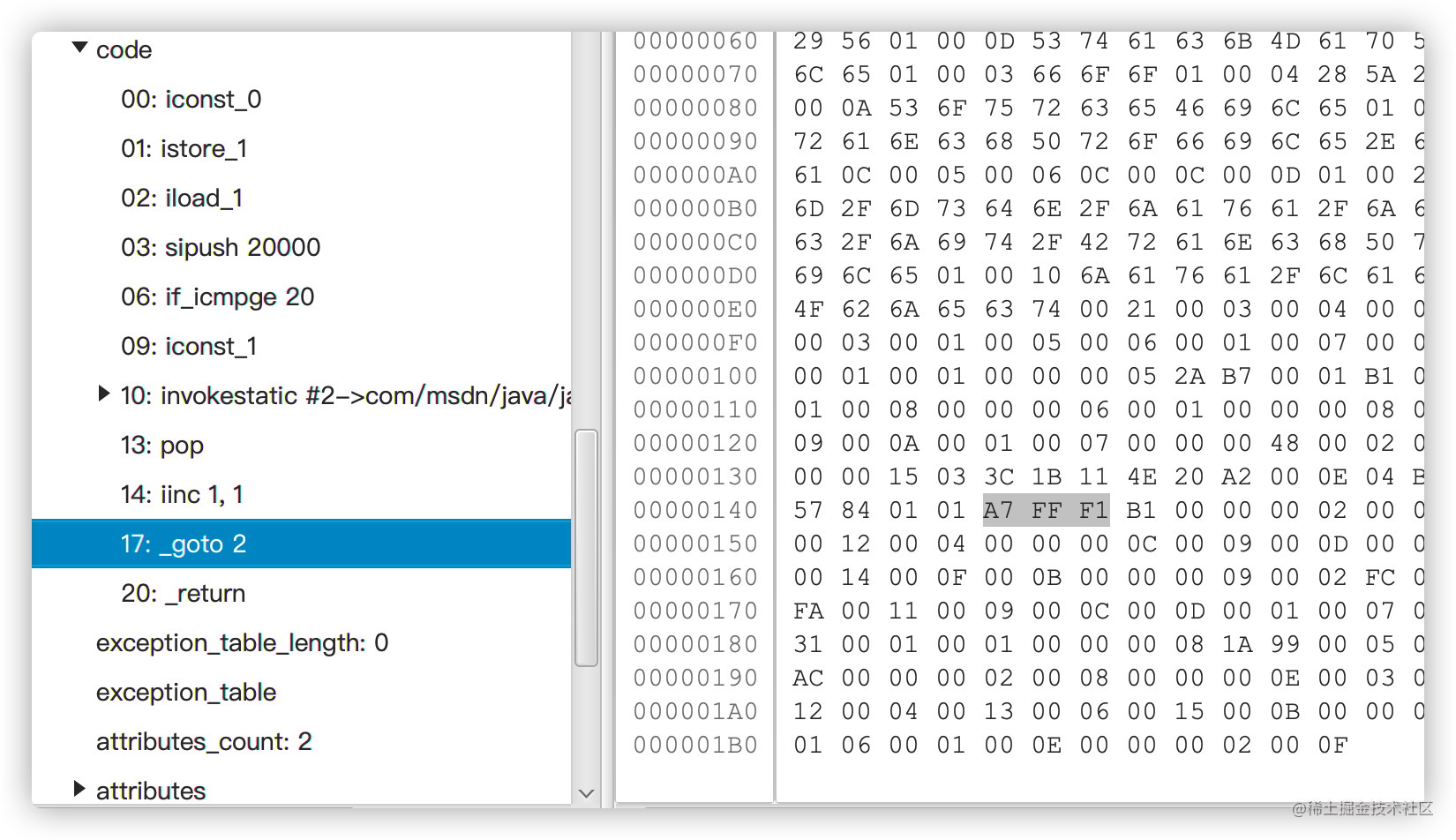
其中 A7 对应 goto,FF F1 表示相对偏移量,FF F1 这里要解读为大端的带符号16位数,值为-15。这条 goto 指令从偏移量 17 的位置开始,而它的跳转目标就是17 + (-15) = 2。
HSDIS生成反汇编代码
下载配置参考本文。
验证 hsdis 是否工作的命令:
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -version
具体使用,比如有这样一段代码:
public class CompilationTest2 {
public static int getHashCode(Object input) {
if (input instanceof Exception) {
return System.identityHashCode(input);
} else {
return input.hashCode();
}
}
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 500000; i++) {
getHashCode(i);
}
Thread.sleep(2000);
}
}
我们想看 getHashCode 的机器码,则可以执行如下命令:
javac CompilationTest2.java
java -XX:CompileCommand='print,CompilationTest2.getHashCode' CompilationTest2
不过暂时看不懂输出的机器码。
如果查看整个文件的机器码,则可以这样:
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly CompilationTest2
参考文献
极客时间《深入拆解Java虚拟机》 郑雨迪